SQL的事务
一、基本概念
- 事务是数据库区别于文件系统的重要特性之一,当有了事务,就可以让数据库始终保持
一致性,同时可以通过事务的机制恢复到某个时间点,保证了提交到数据库的修改不会因为系统崩溃而丢失; - 事务只是一个改变,是一些操作的集合,用专业术语说,就是一组
逻辑操作单元。事务本身不具备四个特性,而是通过某些手段尽可能让执行单元满足四个特性,那么此时称之为一个完整的事务。
经常在网络上、现实中一提到事务就绑死ACID四个特性,但实际ACID不仅在事务中有体现,还可以涵盖各个领域。
二、事务处理的原则
所有的事务都是作为一组逻辑操作单元来执行,即使出现故障,都不能改变这种方式。当在一个事务中执行多个操作时,要么事务提交(commit),所有修改都会永久地保存下来;要么事务回滚(rollback),所有修改都放弃,一切回归最初状态。
常见例子:
A给B转账,A余额减少,B余额增加,这是一套必须同时完成的操作,如果其中一个失败了,则所有操作都会失败。
在SQL中体现为:
UPDATE account SET money = money - 100 WHERE name = 'A';
UPDATE account SET money = money + 100 WHERE name = 'B';
这两句SQL语句就必须同时完成,或同时失败。
三、ACID
-
原子性(atomicity):
指事务是不可分割的工作单位,要么全部提交,要么全部回滚。原子就是物理世界中最小的单位了,无法在继续分下去了,表达的是一个整体性的概念。
-
一致性(consistency):
在事务执行前后,数据从一个合法性状态转换到另一个合法性状态,这种状态是语义上的,不同的业务场景,对于合法性状态有不同的定义。可以理解为
满足预定结果的状态称为合法的状态,这种状态由自己定义,比如现实世界中的约束。如果满足这种状态,那就是满足一致性,如果不满足,这操作失败,事务回滚。比如余额字段设置为无符号数值,即钱是不允许负数的,如果此时SQL语句修改余额小于0,此时就不满足定义的语义,所以SQL会执行失败(显示出来就是报错),事务就会回滚。
-
隔离性(isolation):
指事务的执行
不能被其它事务干扰,即一个事务内部的操作及使用的数据对并发的其它事务都是隔离的、独立的,并发执行的各个事务之间不能互相干扰。比如事务A把余额从0改成100了,此时事务A还没有commit,而事务B进来读取余额了,此时结果是0还是100?这个时候就引出
隔离级别这个概念了。 -
持久性(durability):
指事务一旦提交(commit),对数据的改变就是永久性的,之后的其它操作丢不会对其有任何影响。
比如A给B转账100,A减去100,B增加100,然后事务提交,A与B的余额就都是修改后的了,如果此时A反悔不转钱了,是无法做到的,只能再开个事务让B给A转回去。
持久性是通过
事务日志来保证的,日志包括重做日志(redo)、回滚日志(undo)。当通过事务对数据进行修改时,首先会将数据库的变化信息记录到redo日志中,然后再对数据库对应的行进行修改,这样的话即使数据库崩溃,重启后也能找到没有更新到数据库系统的redo日志重新执行,从而使事务具有持久性。
总结:在ACID中,原子性是基础,隔离性是手段,一致性是约束条件,持久性是最终的目的。
如果要一句话回答事务是什么?那就是保证原子性、一致性、隔离性,持久性的一个或多个数据库操作称为一个事务。
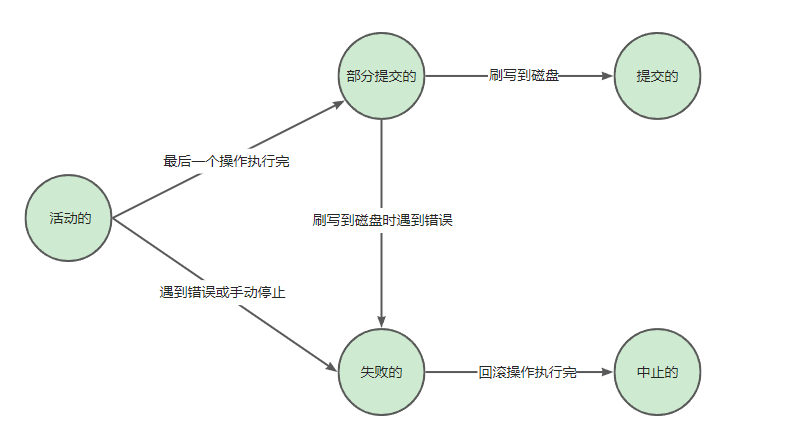
四、事务的状态
-
活动的(active):
事务对应的数据库操作正在执行的过程中,称为事务处在
活动的状态。 -
部分提交的(partially committed):
当事务的
最后一个操作执行完成,改动的数据的还处在内存中,并没有刷写到磁盘,此时称为事务处在部分提交的状态。 -
失败的(failed):
当事务处于
活动的或者部分提交的状态时,可能遇到某些错误(数据库自身错误、操作系统错误、断电等)而无法继续执行,或人为的停止事务的执行,称为事务处于失败的状态。 -
中止的(aborted):
如果事务执行了一部分而变为
失败的状态,那么就需要将修改过的事务的操作还原(就是回滚操作),还原完成后,事务就出在了中止的状态。 -
提交的(committed):
处于
部分提交的状态的事务将修改过的数据刷写到磁盘后,称为事务处在提交的状态。
五、事务的隔离级别
事务的隔离级别的出现,就是为了解决ACID中的 I(isolation 隔离性)在并发环境下,同时被操作的数据的隔离问题,同前面所述例子:
比如事务A把余额从0改成100了,此时事务A还没有commit,而事务B进来读取余额了,此时结果是0还是100?
以MySQL为例,MySQL是一个客户端/服务端架构的软件,对于同一个服务器来说,可以由若干个客户端与之连接,每个客户端与服务端连接上之后,称为一个会话(Session)。每个客户端都可以在自己的会话中向服务器发出请求语句,而请求语句可以是某个事务的一部分。对于服务器来说可以同时处理多个事务,但又要满足隔离性的特性,理论上在某个事务对某个数据进行访问时,其它事务应该进行排队,直到该事务提交之后,其它事务才能继续访问这个数据(类比Java多线程锁机制),但这样性能影响太大。如果既要保持事务的隔离性,又想让服务器在处理访问同一数据的多个事务的性能尽可能高,这时候就看二者如何权衡取舍了。
5.1 准备数据
创建一张表及数据
CREATE TABLE student (
no INT,
name VARCHAR(20),
age INT,
PRIMARY KEY (no)
) Engine=InnoDB;
INSERT INTO student VALUES(1, '小明', 18);
确认数据正常:
mysql> SELECT * FROM student;
+----+--------+------+
| no | name | age |
+----+--------+------+
| 1 | 小明 | 18 |
+----+--------+------+
1 row in set (0.00 sec)
5.2 数据并发问题
在并发情况下,如果不保证串行执行(就是一个接一个执行),那么会出现以下几种问题:
1. 脏写(Dirty Write)
对于两个事务 Session A、Session B,如果 Session A修改了 Session B 修改过但还未提交的数据,就意味着发生了脏写。
| 发生时间编号 | Session A | Session B |
|---|---|---|
| ① | BEGIN; | |
| ② | BEGIN; | |
| ③ | UPDATE student SET name = '李四' WHERE no = 1; |
|
| ④ | UPDATE student SET name = '张三' WHERE no = 1; |
|
| ⑤ | COMMIT; | |
| ⑥ | ROLLBACK; |
已知表中仅有一条no为1、name为小明的记录。
Session A 与 Session B 各自开启自己的事务,Session B 的事务先将no为1的记录修改name列的值为李四,然后这条记录紧接着又 Session A 给改成了张三,并且Session A 还 COMMIT 了,按理来说此时张三就应该永久刷写到磁盘了,但接着Session B 将它的事务回滚了,对于这记录的修改全部撤回,即no为1的记录的name列的值为小明。那对于 Session A 来说就有问题了,明明update且commit了,最后一看什么变化都没有,这是无法被容忍的问题,所以在标准SQL中的四种隔离级别中都解决了脏写的问题(就是没法复现了)。
2. 脏读(Dirty Read)
对于两个事务 Session A、Session B,如果 Session A读取了 Session B 修改过但还未提交的数据,之后 Session B 回滚,则 Session A 读到的数据就是临时且无效的。
| 发生时间编号 | Session A | Session B |
|---|---|---|
| ① | BEGIN; | |
| ② | BEGIN; | |
| ③ | UPDATE student SET name = '李四' WHERE no = 1; |
|
| ④ | SELECR * FROM student WHERE no = 1; (如果此时读出来是 李四,而不是小明,则发生了脏读) |
|
| ⑤ | COMMIT; | |
| ⑥ | ROLLBACK; |
已知表中仅有一条no为1、name为小明的记录。
Session A 与 Session B 各自开启自己的事务,Session B 的事务先将no为1的记录修改name列的值为李四,然后紧接着 Session A 查询这条记录,如果发现读到的数据为李四,即读到了Session B 中还没有提交的数据,之后 Session B 进行了回滚,数据还原回小明,那么 Session A 读到的李四就是一个不存在的数据,这种现象称为脏读。
在某些场合下,返回不存在的数据、假的数据给客户,是可能会出大问题的。
3. 不可重复度(Non-Repeatable Read)
对于两个事务 Session A、Session B,Session A 读取了一条记录的一个字段,然后 Session B 修改了这条记录的同个字段,接着 Session A 再重复上一次查询,两次结果不同了,这就发生了不可重复读。
| 发生时间编号 | Session A | Session B |
|---|---|---|
| ① | BEGIN; | |
| ② | SELECR * FROM student WHERE no = 1; (此时读出来是 小明) |
|
| ③ | BEGIN; UPDATE student SET name = '李四' WHERE no = 1; COMMIT; |
|
| ④ | SELECR * FROM student WHERE no = 1; (读出来是 李四,跟上次不同,则发生了不可重复读) |
|
| ⑤ | BEGIN; UPDATE student SET name = '王五' WHERE no = 1; COMMIT; |
|
| ⑥ | SELECR * FROM student WHERE no = 1; (读出来是 王五,又跟上次不同,则发生了不可重复读) |
已知表中仅有一条no为1、name为小明的记录。
Session A 第一次查询该记录为小明(注意还没有COMMIT),接着 Session B 修改该记录为李四,然后 Session A 再次查询发现变成李四了,跟上一次查询结果不同,这种现象称为不可重复读。同理 Session B 又修改值为王五,紧接着Session A 又再次查询发现结果又变了,变成了王五,因为发生了不可重复读。
对于这种现象,在现实中很多场景下中我们会认为这是合理的、可以接受的,每次查询就应该查出当前最新的数据,但处于并发事务内的角度来看这属于一种问题。
4. 幻读(Phantom Read)
对于两个事务 Session A、Session B,Session A 读取了一条记录的一个字段,然后 Session B 往表插入一些新的记录,之后 Session A 再次读取发现多出了新的记录,这就算幻读。
| 发生时间编号 | Session A | Session B |
|---|---|---|
| ① | BEGIN; | |
| ② | SELECR * FROM student WHERE no > 0; (此时读出来只有 小明一条记录) |
|
| ③ | BEGIN; INSERT INTO student VALUES(2, '李四', 19); COMMIT; |
|
| ④ | SELECR * FROM student WHERE no > 0; (此时读出来有 小明、李四两条记录,发生了幻读) |
已知表中仅有一条no为1、name为小明的记录。
Session A 第一次查询限定条件为 no > 0,查出来一条记录为小明(注意还没有COMMIT),接着 Session B 插入了一条记录李四,然后 Session A 再次查询结果为小明、李四两条记录了,多了一条,这种现象称为幻读,而多出来的记录称为幻影记录。
对于这种现象,还是那句话,在现实中很多场景下中我们会认为这是合理的、可以接受的,但处于并发事务内的角度来看这属于一种问题。
对于幻读的注意点:
幻读强调的是多出来的记录。按照示意图,如果 Session B 不是插入记录,而是删除记录,那 Session A 再次查询发现记录数量变少了,这种现象不属于幻读。由于第二次查变少了,严格归类的话,这种现象属于不可重复读。
5.3 SQL标准的四种隔离级别
按照并发问题严重程度高到低排序:脏写 > 脏读 > 不可重复读 > 幻读
由于脏写问题是无法接受的,所以现在市面主流数据库都不会出现这个问题,那还剩下后面3个问题。如果能把所有问题都解决那肯定最好,但也就意味着并发性能最差,如果要最高的并发性能,又会出现数据并发的问题......因此回到前面说的权衡取舍问题了,看不同的场景是要数据绝对准确性,还是要最高的并发性能,亦或牺牲部分并发性能以换取数据的相对准确。
在SQL官方标准中,设立了以下四个隔离级别:
1. 读未提交(Read Uncommitted)
在该隔离级别中,所有事务都可以看到其它未提交事务的执行结果,意味着会发生脏读、不可重复读,幻读。
2. 读已提交(Read Committed)
读已提交满足了隔离的基本定义:一个事务只能看见已经提交的事务的执行结果。这是大部分数据库系统的默认隔离级别,比如Oracle、SQL Server,可以避免脏读,但仍会发生不可重复读,幻读。
3. 可重复读(Repeatable Read)
事务A在读到一条数据之后,此时事务还没提交或回滚,接着事务B对该数据进行了修改并提交,那么事务A再次读取该数据,读到的还是原来的内容。可以避免脏读、不可重复读,但仍会发生幻读,这是MySQL默认的隔离级别。
4. 可串行化(Serializable)
确保事务可以从一个表中读取相同的行,在整个事务持续期间,禁止其它事务对该表相同行进行插入、更新,删除操作。所有的问题都可以解决,但性能最为低下。
| 脏写 | 脏读 | 不可重复读 | 幻读 | 加锁读 | |
|---|---|---|---|---|---|
| Read Uncommitted | × | √ | √ | √ | × |
| Read Committed | × | × | √ | √ | × |
| Repeatable Read | × | × | × | √ | × |
| Serializable | × | × | × | × | √ |
5.4 不同数据库的隔离级别
SQL标准虽然有4种隔离级别,但不同的数据库的支持程度不一样。
| Oracle | MySQL | SQL Server | |
|---|---|---|---|
| Read Uncommitted | × | √ | √ |
| Read Committed | √(默认) | √ | √(默认) |
| Repeatable Read | × | √(默认) | √ |
| Serializable | √ | √ | √ |
| Snapshot | √ | ||
| Read Committed Snapshot | √ |
值得注意的是:
- MySQL 的实现 Repeatable Read 在一定程度上也可以解决幻读的问题(快照读+MVCC机制),与SQL官方标准略有区别;
- SQL Server 支持的隔离级别比SQL标准的还要多出两种。
5.5 其它
MySQL中查看隔离级别:
# 5.7.20之前
SHOW VARIABLES LIKE 'tx_isolation';
# 5.7.20及之后
SHOW VARIABLES LIKE 'transaction_isolation';
# 所有版本均可用
SELECT @@transaction_isolation;
MySQL中设置隔离级别:
SET [GLOBAL|SESSION] TRANSACTION_ISOLATION = '隔离级别';
隔离级别可选项:
> READ-UNCOMMITTED
> READ-COMMITTED
> REPEATABLE-READ
> SERIALIZABLE
或者:
SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL '隔离级别';
隔离级别可选项:
> READ UNCOMMITTED
> READ COMMITTED
> REPEATABLE READ
> SERIALIZABLE
GLOBAL:对后续所有新开会话有效
SESSION:只对当前会话有效
无论设置什么级别,数据库一旦重启都以配置文件为准

 浙公网安备 33010602011771号
浙公网安备 33010602011771号