Pandas Dataframe merge 后出现重复行
1. 初始化两个dataframe
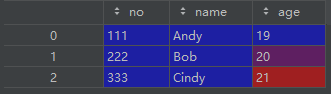
df_left = pd.DataFrame(
columns=['no', 'name', 'age'],
data=[['111', 'Andy', 19], ['222', 'Bob', 20], ['333', 'Cindy', 21]]
)
df_right = pd.DataFrame(
columns=['key_no', 'remark'],
data=[['111', 'a'], ['111', 'b'], ['222', 'c']]
)
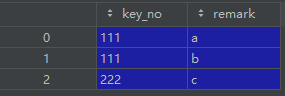
注意到,df_left的no列是唯一的,df_right的key_no列是有重复的
2. 合并两个dataframe
res1 = pd.merge(left=df_left, right=df_right, left_on='no', right_on='key_no', how='left')
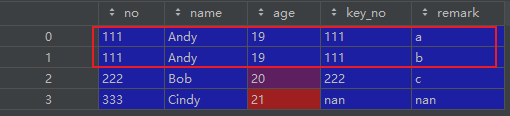
左连接merge两个df时,生成的df出现了重复行,原因是:df_left的no列有一行值为 111, df_right的key_no有两行值为 111,形成一对多的关系,因此出现重复行。
这个问题在官方文档也有提及到:

翻译就是:
对重复键进行连接/合并可能导致返回的帧是行维度的乘法,这可能导致内存溢出。在加入大型 DataFrames 之前,用户有责任管理键中的重复值。
3. 解决方式
3.1 解决方式1:
通过指定 validate='one_to_one'
If specified, checks if merge is of specified type.
- “one_to_one” or “1:1”: check if merge keys are unique in both left and right datasets.
- “one_to_many” or “1:m”: check if merge keys are unique in left dataset.
- “many_to_one” or “m:1”: check if merge keys are unique in right dataset.
- “many_to_many” or “m:m”: allowed, but does not result in checks.
如果抛异常,则说明没有满足一对一关系,则需要进行去重处理,比如drop_duplicates(要确保key重复时取哪个值)
例如:
from pandas.errors import MergeError
try:
res2 = pd.merge(left=df_left, right=df_right, left_on='no', right_on='key_no', how='left', validate='one_to_one')
except MergeError as e:
df_right = df_right.drop_duplicates(subset=['key_no']) # 对 key_no 列去重,保留第一次出现的结果作为值
res2 = pd.merge(left=df_left, right=df_right, left_on='no', right_on='key_no', how='left', validate='one_to_one')
3.2 解决方式2
如果已经确定是一一对应的关系,则可以在 merge前就进行一次去重处理即可,而不需要去处理异常
例如:
df_right = df_right.drop_duplicates(subset=['key_no'])
res2 = pd.merge(left=df_left, right=df_right, left_on='no', right_on='key_no', how='left', validate='one_to_one')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号