JAVA经典集合框架学习笔记——HashMap的底层实现原理
最近做的几个项目都是用Map来存储的数据 ,虽然用得挺顺手,但是对HashMap的底层原理却只知甚少,今天便来简单学习和整理一下。
数据结构中有数组和链表这两个结构来存储数据。
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难;
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。
综合这两者的优点,摒弃缺点,哈希表就诞生了,既满足了数据查找方面的特点,占用的空间也不大。
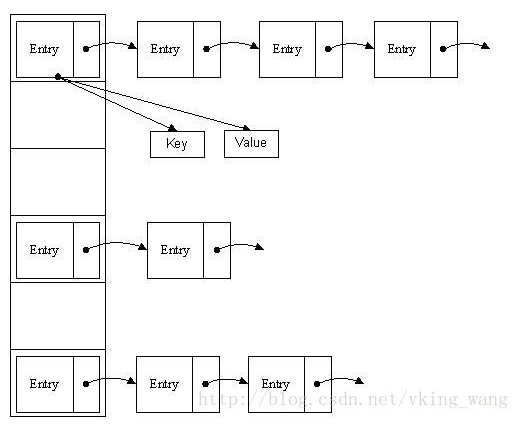
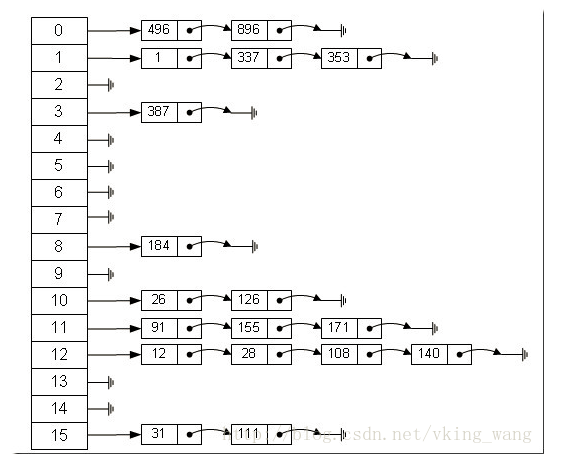
哈希表可以说就是数组链表,底层还是数组但是这个数组每一项就是一个链表。
在这个数组中,每个元素存储的其实是一个链表的头,元素的存储位置一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap的构造函数
HashMap实现了Map接口,继承AbstractMap。其中Map接口定义了键映射到值的规则,而AbstractMap类提供 Map 接口的骨干实现。
HashMap提供了三个构造函数:
HashMap():构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。
HashMap(int initialCapacity):构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。
HashMap(int initialCapacity, float loadFactor):构造一个带指定初始容量和加载因子的空 HashMap。
public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; threshold = initialCapacity; init();
每次初始化HashMap都会构造一个table数组,而table数组的元素为Entry节点。
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash; }
HashMap也可以说是一个数组链表,HashMap里面有一个非常重要的内部静态类——Entry,这个Entry非常重要,它里面包含了键key,值value,下一个节点next,以及hash值,Entry是HashMap非常重要的一个基础Bean,因为所有的内容都存在Entry里面,HashMap的本质可以理解为 Entry[ ] 数组。
HashMap.put(key,value)
public V put(K key, V value) { //当key为null,调用putForNullKey方法,保存null与table第一个` 位置中,这是HashMap允许为null的原因 if (key == null) return putForNullKey(value); //计算key的hash值 int hash = hash(key.hashCode()); ------(1) //计算key hash 值在 table 数组中的位置 int i = indexFor(hash, table.length); ------(2) //从i出开始迭代 e,找到 key 保存的位置 for (Entry<K, V> e = table[i]; e != null; e = e.next) { Object k; //判断该条链上是否有hash值相同的(key相同) //若存在相同,则直接覆盖value,返回旧value if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; //旧值 = 新值 e.value = value; e.recordAccess(this); return oldValue; //返回旧值 } } //修改次数增加1 modCount++; //将key、value添加至i位置处 addEntry(hash, key, value, i); return null; }
我简单的理解一下,当执行put操作的时候,HashMap会先判断一下要存储内容的key值是否为null,如果为null,如果为null,则执行putForNullKey方法,这个方法的作用就是将内容存储到Entry[]数组的第一个位置,如果key不为null,则去计算key的hash值,然后对数组长度取模,得到要存储位置的下标,再迭代该数组元素上的链表,看该链表上是否有hash值相同的,如果有hash值相同的,就直接覆盖value的值,如果没有hash值相同的情况,就将该内容存储到链表的表头,最先储存的内容会放在链表的表尾,其实这带代码也顺道解释了HashMap没有Key值相同的情况。这里还有一个情况也要说明一下,会不会出现链表过长的情况?随着要存储的内容越来越多,HashMap里面的东西也越来越多,相同下标的情况也增多,那么迭代链表的也无疑增加了,这会影响数据的查询效率,HashMap对此也做了优化,当HashMap中存储的内容超过数组长度 *loadFactor时,数组就会进行扩容,默认的数组长度是16,loadFactor为加载因子,默认的值为0.75。对于扩容需要说明的一点就是,扩容是一个非常“消耗”的过程,需要重新计算数据在新数组中的位置,并且将内容复制到新数组中,如果我们预先知道HashMap中的元素个数,预设元素的个数,能有效的提高HashMap的存储效率。
HashMap.get(key)
public V get(Object key) { if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); } final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } int hash = (key == null) ? 0 : hash(key); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }
get(key)方法的代码比较好理解,根据key的hash值找到对应的Entry即链表,然后在返回该key值对应的value。
HashMap的遍历
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("1", "value1");
map.put("2", "value2");
map.put("3", "value3");
//第一种:普遍使用,二次取值
System.out.println("通过Map.keySet遍历key和value:");
for (String key : map.keySet()) {
System.out.println("key= "+ key + " and value= " + map.get(key));
}
//第二种
System.out.println("通过Map.entrySet使用iterator遍历key和value:");
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第三种:推荐,尤其是容量大时
System.out.println("通过Map.entrySet遍历key和value");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第四种
System.out.println("通过Map.values()遍历所有的value,但不能遍历key");
for (String v : map.values()) {
System.out.println("value= " + v);
}
}
使用HashMap的匿名内部类Entry遍历比使用keySet()效率要高很多,使用forEach循环时要注意不要在循环的过程中改变键值对的任何一方的值,否则出现哈希表的值没有随着键值的改变而改变,到时候在删除的时候会出现问题。 此外,entrySet比keySet快些。对于keySet其实是遍历了2次,一次是转为iterator,一次就从hashmap中取出key所对于的value。而entrySet只是遍历了第一次,他把key和value都放到了entry中,所以就快了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号