
Web vitals
tag-2021-01-30-tag
Introduction
本文列出了评测网页基本性能的一些指标。这些指标包含了一个网页从加载到呈现到可交互的一个完成的周期,在评价整体性能上有较大的参考意义。本文基本上是google vitial系列文章的总结,这些文档还没有中文翻译,但是你可以对照着本文进行查看。另外我也对它们进行了一些额外的其补充,包括一些vitals的不足和个人看法,以及一些特定的vitals的计算方法。这些标准的测量指标对网页性能评估有重要的协助作用,在你对网页进行优化的时你可以将他们考虑进去,进而有针对性的对目标进行改善。有句话叫做:You can't optimize what you can't mesure,我们评估网页的性能也应该仔细的先做准备工作,而不是一上来就毛毛躁躁地答应领导的1s内加载好网页内容之类的话。
Distinction
Field & Lab
网页优化的难题之一就是你并不知道所有设备上的性能得分表现。我们习惯于埋头开发,有经验的程序员也会利用dev tools对部分网页进行性能评估,但是,大多数时候我们忽略了一个事实:网页时运行在千千万万的设备上,你怎么能根据自己环境的好坏来判断你的应用的性能好坏呢?
所以,才有了Lab和Field两种环境之分。首先,Lab是只标准所产生的指定的环境,Filed则与之相对应是在普遍客户端的环境。很多人比较忽视Filed,往往只在自己的电脑上或者特定的测试机型上对产生的数据做结论。这种错误是片面的,互联网用户在设备,网络,地域等客观维度上都是有很多差异的,这些差异会使得即使我们是一个网页,但每个客户端的性能表现和评分完全不一样。因此,我们的最终目的是评估Field的,Lab顾名思义,只是我们在实验室验证理论的地方。
但是有些明显的因为人为造成的因素可以直接从Lab环境中分析,这些错误包括人为的失误,bug,特定场景,算法(如果你真的用得上的话)等可控的技术性的影响网页性能的因素。例如你的应用虽然能够正常的运行,但是由于内存泄露,或者算法差劲,导致了性能的瓶颈。这种人为的失误虽然不影响功能,在却拖慢了所有的运行此应用的程序。
最后我们解决了bug,优化了算法,就应该从另外一个角度来思考性能问题,即从每个客户的机器上收集分析,而不是开发者的那台拥有M4芯片的Mac上。所以,要测量和改善网页加载的速度,第一步就是搭建监控系统用来收集Filed数据。我在每个指标的最后都贴出来两种方法的观察统计工具和方式。关于如何搭建监控系统的一些详情,我在这篇文章中已经提到。
Performace & PerformanceObserver
在我们对指标进行评测是之前,我们需要先弄清楚,我们的评测过程是持续的,还是在固定的时间段一次性获取的。针对不同的指标,我们采用的评估方式也是不一样的。这里我们提到了两个api,分别是Performance和PerformanceObserver,在api的命名上我们其实已经可以看出他们之前的却别,前者是在onload函数之后统计的数据接口,它通过计算,可以得出如下信息:
// onload
this.time = window.performance.toJSON().timing;
// 【重要】页面加载完成的时间
// 【原因】这几乎代表了用户等待页面可用的时间
times.loadPage = t.loadEventEnd - t.navigationStart;
// 【重要】解析 DOM 树结构的时间
// 【原因】反省下你的 DOM 树嵌套是不是太多了!
times.domReady = t.domComplete - t.responseEnd;
// 【重要】重定向的时间
// 【原因】拒绝重定向!比如,http://example.com/ 就不该写成 http://example.com
times.redirect = t.redirectEnd - t.redirectStart;
// 【重要】DNS 查询时间
// 【原因】DNS 预加载做了么?页面内是不是使用了太多不同的域名导致域名查询的时间太长?
// 可使用 HTML5 Prefetch 预查询 DNS ,见:[HTML5 prefetch](http://segmentfault.com/a/1190000000633364)
times.lookupDomain = t.domainLookupEnd - t.domainLookupStart;
// 【重要】读取页面第一个字节的时间
// 【原因】这可以理解为用户拿到你的资源占用的时间,加异地机房了么,加CDN 处理了么?加带宽了么?加 CPU 运算速度了么?
// TTFB 即 Time To First Byte 的意思
// 维基百科:https://en.wikipedia.org/wiki/Time_To_First_Byte
times.ttfb = t.responseStart - t.navigationStart;
// 【重要】内容加载完成的时间
// 【原因】页面内容经过 gzip 压缩了么,静态资源 css/js 等压缩了么?
times.request = t.responseEnd - t.requestStart;
// 【重要】执行 onload 回调函数的时间
// 【原因】是否太多不必要的操作都放到 onload 回调函数里执行了,考虑过延迟加载、按需加载的策略么?
times.loadEvent = t.loadEventEnd - t.loadEventStart;
// DNS 缓存时间
times.appcache = t.domainLookupStart - t.fetchStart;
// 卸载页面的时间
times.unloadEvent = t.unloadEventEnd - t.unloadEventStart;
// TCP 建立连接完成握手的时间
times.connect = t.connectEnd - t.connectStart;
其中的很多信息与HTTP相关的信息,但也是通过计算,也可以计算出来我们的今天要讲的指标。而后者在响应样式方面更具有优势。因为很多指标并非是onload响应之后就能够检测的,这些指标会在界面完全显示之后还未到触发阶段,因此,作为一个相对的过程,我们无法通过前者去衡量,而是需要设置持续地对网页加载的这段时间时间,来达到目的。我个人以为如果你可以结合两者来评估你的网页的性能。而在本篇我们要讲的指标中,我们主要用的是后者来监听各种指标的响应时间。
Web-vitals
First Paint
FP(First Paint),第一个描绘在界面的像素点,该指标指示网络请求之后开始的浏览器绘制的旅程。FP在用户的可视方面不一定是有效的,例如我们有可能先绘制一个空的div,也能算作FP,但是对于用户来说仍旧是空空荡荡的界面。它更多的是用来指示绘制流程的开始,也就是说HTTP加载或者js执行等影响界面绘制的因素都已经完全结束。
标准:
- Good: < 0.5s
- Needs Improvement: 0.5s ~ 1.5s
- Poor: > 1.5s
计算:
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntriesByName('first-paint')) {
console.log('FP candidate:', entry.startTime, entry);
}
}).observe({type: 'paint', buffered: true});
不足:
FP在反应用户预期的作用程度不完全合理,或者说它干脆就是与用户体验无光的测量标准。第一个像素被绘制到屏幕上与用户的对网页的反馈预期基本上没有联系。这种指标只适合给工程师后续结合其他vitals时提供参考意义。
First Contentful Paint
First Contentful Paint (FCP) ,初次有意义的渲染,所谓有意义,即需要包含部分人类能够识别的信息,例如文字,图片,视频以及非空的canvas内容。这个统计对用户的预期评估有部分重要意义。人们在网页上浏览是为了获取信息,而以上元素内容无疑包含了大量预期的信息。
标准:
- Good: < 1.5s
- Needs Improvement: 1.5s ~ 3.0s
- Poor: > 3.0s
示例:
我们可以看到下面这段加载网页的历程,第二帧的时候就是FCP统计的时间。因为它出现了文字,让用户的感觉是我终于看到了一些东西了。后面的网页陆续程序时就不算做是FCP的统计元素了,因为有First定语修饰,规定了初次,第一次。
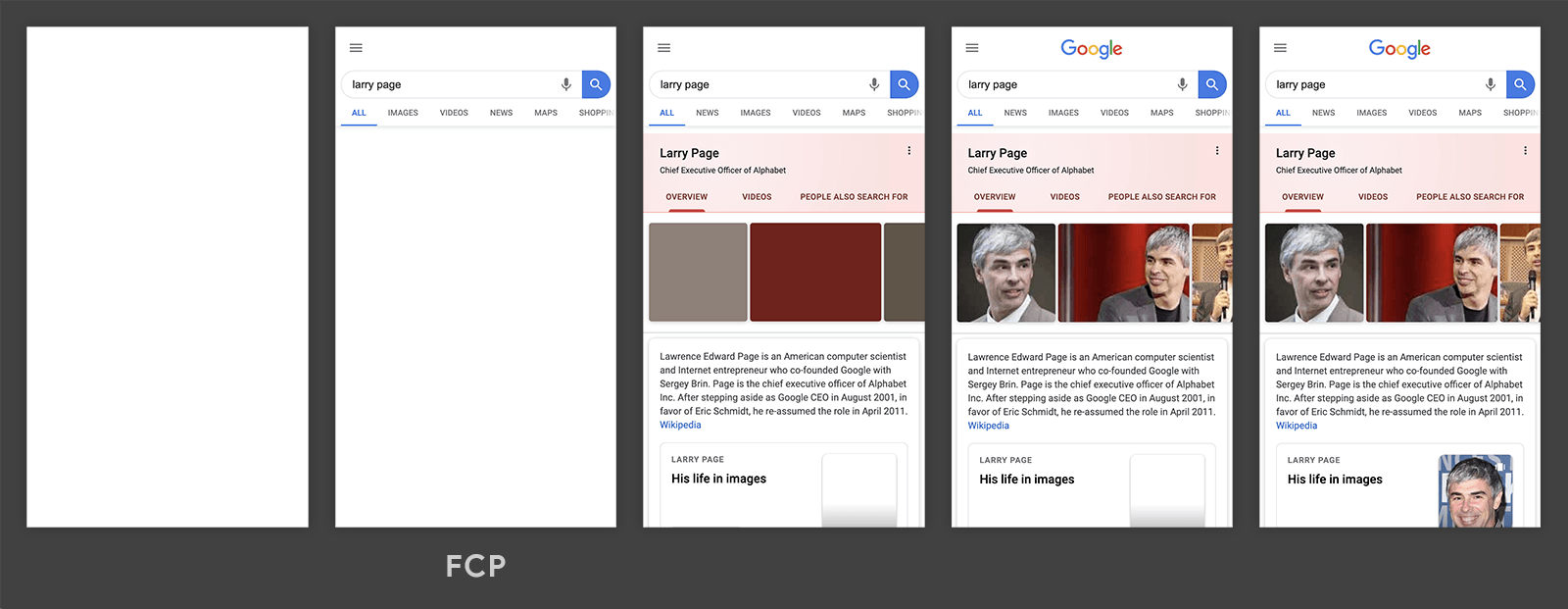
计算:
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntriesByName('first-contentful-paint')) {
console.log('FCP candidate:', entry.startTime, entry);
}
}).observe({type: 'paint', buffered: true});
Tools:
Field tools:
- PageSpeed Insights
- Chrome User Experience Report
- Search Console (Speed Report)
- web-vitals JavaScript library (webvitals npm package)
Lab tools: - Lighthouse
- Chrome DevTools
- PageSpeed Insights
不足:
FCP在评估用户预期有重要意义,但是依旧无法覆盖所有的情况,在文本和广告作为无效的元素首先显示时,它就脱离了本身的评判结果。
Largest Content Paint
Largest Content Paint,LCP该指标衡量的是网页上最大的指定类型的元素节点渲染出来的时间点。谷歌团队基于自己的研究和W3C Web Performance Working Group,得出了最大元素,尤其包含文字和图片的元素更容易吸引读者的目光。因此才把此标准纳入web-vitals。这些元素如下所示:
- img 图片
- svg 元素
- vedio 视频
- 含有背景图片的元素
- 包含其他层级的或者文本的块级元素。
标准:
- Good: < 2.5s
- Needs Improvement: 2.5s ~ 4.0s
- Poor: > 4.0s
示例:
浏览器会自动向你发送某个时间点的最大可见元素,在第二张图片中时上面的文字,后面一直是包含了instagram的LOGO的元素,因此事件会响应两次。这个指标并没有first这个定语修饰,而是用Largest来修饰paint这个行为。因此,我们会在网页的不同阶段接收到这个PerformanceObserver这个推送的值。
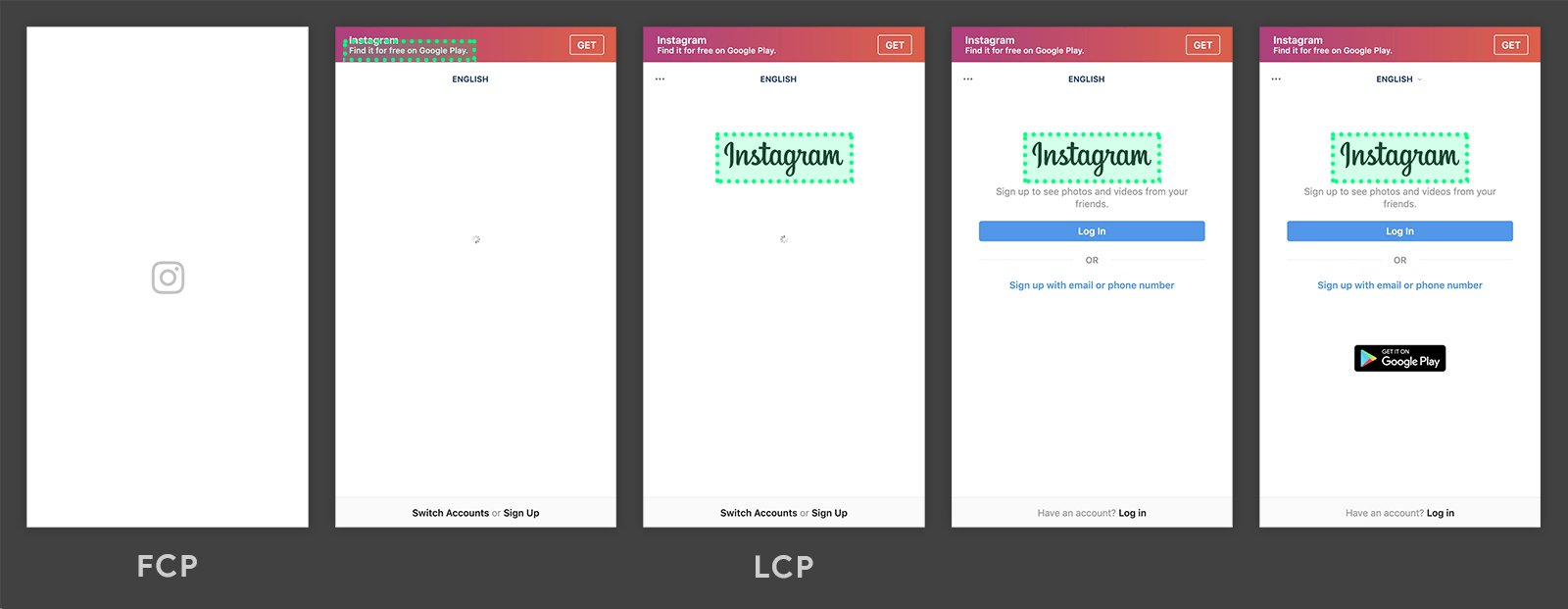
下面这张图则是指标指定的元素不断变化的一个过程,可以看到最大元素从底部的文本框变化到顶部的文字框,最后是中间的图片。在此过程中事件也会被响应多次,需要开发者格外注意。

Tools:
Filed:
- Chrome User Experience Report
- PageSpeed Insights
- Search Console (Core Web Vitals report)
- web-vitals JavaScript library (代码如Code所示)
Lab:
- Chrome DevTools
- Lighthouse
- WebPageTest
Code:
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntries()) {
console.log('LCP candidate:', entry.startTime, entry);
}
}).observe({type: 'largest-contentful-paint', buffered: true});
不足:
正如官方的指出:这些元素会在整个网页加载的过程中逐步呈现出来,为了避免大量的元素计算,浏览器制定了一项策略:只关注在视图窗口内的元素的初始尺寸以及位置。也就是说如果图一开始超出了屏幕,则不统计;同样如果一个元素原始用户有很小的size,后面被代码改变了,则也不再统计到指标当中。因此在考虑一些不规则的元素时变得比较被动。而且最大元素的这个标准并非一定包含了开发者所预想的一样包含了重要的信息,例如很多时候最大的图片是广告而不是其他的。最后,在实际操作过程中,LCP经常性的把loading图标纳入统计,但实际上这时还是处于用户等待预期的阶段,因此也是一个鸡肋之处。
Cumulative Layout Shift
Cumulative Layout Shift,CLS表示从内容加载出来后整体网页的偏移量。大多数通过异步加载出来的网页上的元素会因为http的时间延迟,在结果被渲染出来之时产生界面位置偏移,这种偏移就叫做CLS。CLS确实对于用户的视觉感和体验是非常差的,有一个典型的示例就是对于延迟加载的广告会经常被用户误点到,这种体验非常差。你可以看下面这个短暂的视频,本来用户是打算去点“No, go back”的,结果,“啪”,很快啊,被上面加载的广告图坑了。
计算:
layout shift score = impact fraction * distance fraction 得分 = 被影响的块级元素的大小 * 移动的距离
对于impact的定义,dev上的定义是如此:
The union of the visible areas of all unstable elements for the previous frame and the current frame—as a fraction of the total area of the viewport—is the impact fraction for the current frame.
简单来讲就是上一帧可见的不稳定的元素集合,以及当前帧的可视范围内的所有元素。你可以参考这篇文章来确定更详细的解释。我们在下面会用一个简单的例子来说明。
标准:
- Good: < 0.1
- Needs Improvement: 0.1 ~ 0.25
- Poor: > 0.25
示例:
下面两张图分别是网页在初始显示后的图片,可以看到第二帧显示的整段文字向下偏移了,我们假设文本段落的高度为0.5,第二张移动的距离为0.25,更具定义:impact fraction 就是0.75,因此CLS得分为 。0.75 * 0.25 = 0.19; 这样的结果显然在视觉上是难以接受的,所以需要进行改进。

Code:
addEventListener("load", () => {
let DCLS = 0;
new PerformanceObserver((list) => {
list.getEntries().forEach((entry) => {
if (entry.hadRecentInput)
return; // Ignore shifts after recent input.
DCLS += entry.value;
});
}).observe({type: "layout-shift", buffered: true});
});
不足:
CLS比较好的测量了界面的抖动对用户的感官体验。但是在细节上体现的不够,例如没有评估到弹出广告等形式对界面的变化。另外,如果它的计算帧率是用frame来统计的,但是在一些场景下,变化是非常慢的,但慢的速度又不足以构成渐进的动画,这种情况,CLS就很难判定了。另外CLS并非一个持续的统计的过程,我们无法预料到在网页加载之后,是否还有网页偏移的现象。
First Input Delay
First Input Delay,FID首次输入延迟。检测的是首次开始参与输入的时间点,这段时间表示的是用户对网页的交互程度。FID的快慢影响这用户对用网页操作的预期。
标准:
- Good: < 100ms
- Needs Improvement: 100ms ~ 250ms
- Poor: > 250ms
示例:
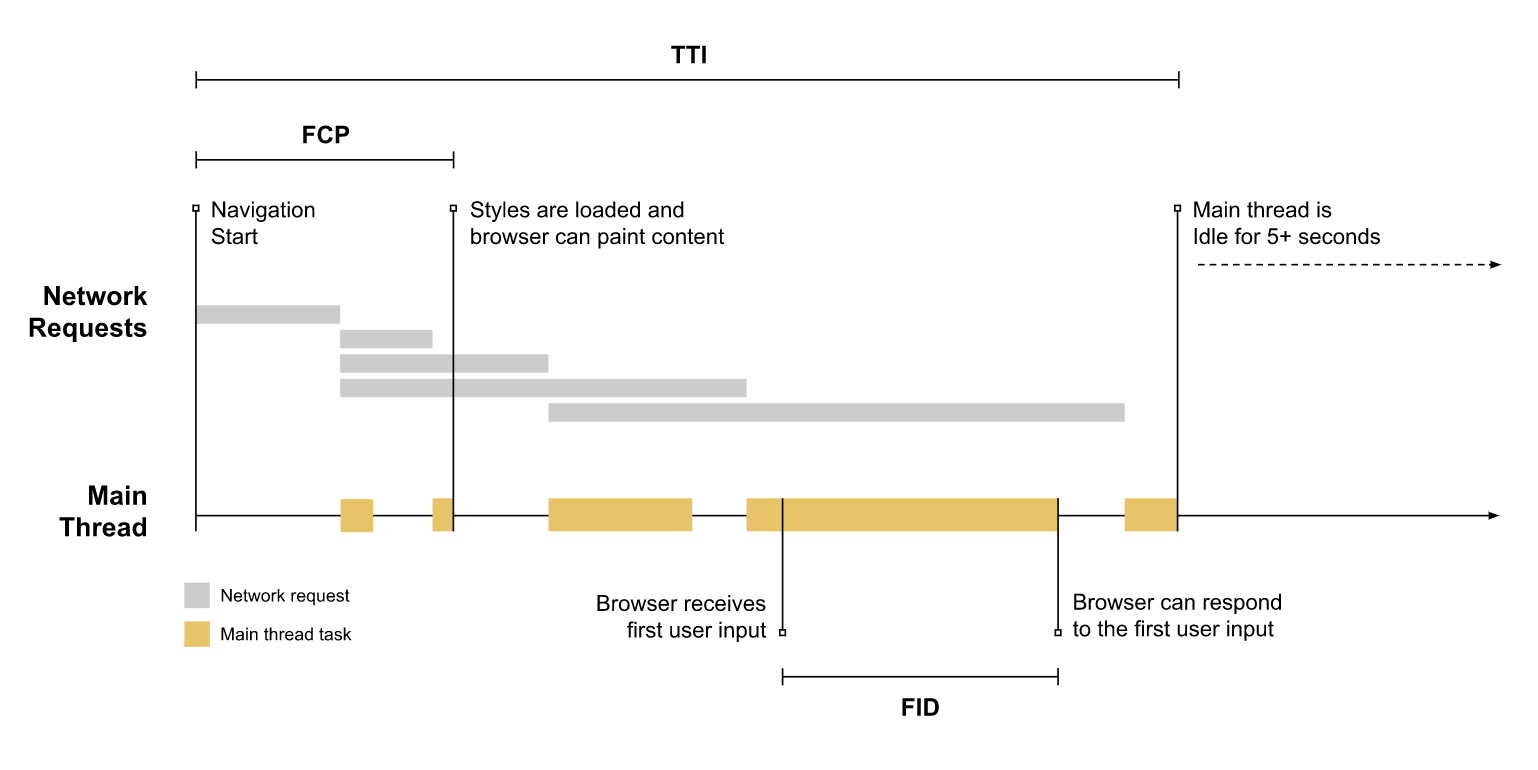
可以看上图,FID定义和TTI以及FCP有诸多系,其中包括network,longtask等时间的定义和等待,并且在网络后续的结果判断上有关联。
Tools:
Lab tools:
- Lighthouse
- Chrome Performace
Field tools: - Chrome User Experience Report
- PageSpeed Insights
- Search Console (Core Web Vitals report)
- web-vitals JavaScript library (npm package)
Code:
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntries()) {
const delay = entry.processingStart - entry.startTime;
console.log('FID candidate:', delay, entry);
}
}).observe({type: 'first-input', buffered: true});
Total Blocking Time
Total Blocking Time,TBT总计被阻断的时间,指的其实是计算FCP到TTI之间的时间段,帮助开发者粗略地,分析相关的代码影响点在哪里。TBT主要是被长任务(long task)的影响阻断,和TTI有很强的关联关系。
示例:

我们来分析一下上面所示的图面这中情况的TBT,按照定义,如果一个任务过长,超过了50ms的任务被执行了,那么我们就可以把这个任务纳入TBT,那么依照定义,我们可以计算出上图中有三个任务纳入计算时长分别是第1,2,5个任务。因此TBT的总时长为 250 + 90 + 155 = 345ms
Lab tools
- Chrome DevTools
- Lighthouse
- WebPageTest
Fields tools
- code 如下所示
Code:
TBT的是完全通过longtask的发生次数计算的。我们可以把长任务的监听作为TBT标准的计算方式。正好,在performanceOberser这个API中提供了这个长任务的获取方法。
const Observer = (type: string, callback: HanderPerformanceFn): PerformanceObserver | undefined => {
try {
//判断是否支持该参数选型的监听
if (PerformanceObserver.supportedEntryTypes.includes(type)) {
const observer: PerformanceObserver = new PerformanceObserver(list => {
list.getEntries().forEach(callback);
});
observer.observe({ entryTypes: [type] });
return observer;
}
}catch (ex) {
return undefined;
}
}
//监听长任务结束事件
Observer('longtask', (longtask: HandlePerformanceLongTask) => {
//计算长任务结束时间
const longtask = longtask.duration + longtask.startTime;
});
不足:
和TTI一样,在用户端很难在Filed里面统计,TBT也和FP意义,在统计用户预期的方面缺少用户,更多的是开发者自己的统计时长。
Time To Interactive
Time To Interactive,TTI可交互时间。指的是用户与网页交互的时间。很多时间,例如长任务,或者进行加载的网络请求会影响用户和网页的交互。
标准:
good:< 5.0s
计算:
TTI 的计算方式较为复杂,我在这篇文章中阐述了详尽的测量方法。有兴趣的可以自行查看。
不足:
TTI在关怀用户的层面做的是不错的,不过定义的标准趋于模糊而且计算方式非常复杂。google没有给出现成的api来供开发者调用,需要较为复杂的算法和设计。
Recap
到此为止我们总结了一些在日常之中经常用到的性能指标,这些指标在评估我们的网页性能方面的作用还是有益处的,但是应该记住,没有银弹。所有指标的评测标准在不同的项目中的意义可能会有很大的区别。例如C端的界面和B端的系统,在用户预期,加载状况,代码复杂程度,图片大小,内容上都存在较大的差异,如果用这种统一的标准去判断,会有失公允。因此,这些指标需要在特定的项目中作为你的一个网页性能的总体判断。而且这些指标面向的是以用户交互和预期为主,不像HTTP那样有一套客观的标准。
Reference
- Google dev Metrics
- Google dev Web Vitals
- Debug web vitals in the field

 浙公网安备 33010602011771号
浙公网安备 33010602011771号