
Elasticsearch是什么?
Elasticsearch 是分布式搜索和分析引擎,其核心是Elastic Stack。
Elasticsearch 为所有类型的数据提供近乎实时的搜索和分析。无论是结构化或非结构化文本、数字数据或地理空间数据,Elasticsearch 可以以支持快速搜索的方式有效地存储和索引它。随着数据和查询量的增长,Elasticsearch 的分布式特性使您的部署能够无缝扩展随之而来。
集群(cluster)
Elasticsearch 集群由一个或多个节点(Node)组成
节点(Node)
一个启动的Elasticsearch实例是一个节点,一个节点的集合就是一个集群(cluster),一个ES集群至少需要有3个节点(主节点角色)构成;
集群中的每个节点都可以处理HTTP和transport请求。transport用于集群内节点间通信;HTTP用于REST客户端通信。
每一个节点都保存集群内其他节点的信息,每一个节点都可以转发请求到正确的数据节点
节点角色(Node Roles)
随着数据增长,我们需要为es集群的节点分配不同的角色,让不同的节点专注于不同的业务,以便最大限度发挥机器性能;默认情况下,每个节点拥有所有的节点角色
节点允许设置以下角色:master、data、data_content、data_hot、data_warm、data_cold、data_frozen、ingest、ml、remote_cluster_client、transform
Master node
一个集群只有一个主节点,主节点主要负责集群范围的轻量级操作,包括创建/删除索引,集群内节点健康监控,分片的分配、恢复、再平衡等;主节点存储了整个集群的元数据:索引名称,索引分片数量等
Master-eligible node
当节点角色中有“master”,这个节点就允许被选为主节点
Voting-only master-eligible node
仅投票节点不会被选为主节点,只允许在主节点选举中投票。相对于可能成功主节点的服务,仅投票节点可以少一些cpu与内存
Data node
数据节点包含索引分片,数据节点负责数据的相关操作,如CRUD,搜索,聚合等。这些动作是cpu密集,I/O密集和内存密集型,主要重点关注这部分数据。
在使用数据分层结构部署集群时,可以给节点分配专门的数据角色:data_content、data_hot、data_warm、data_cold、data_frozen
Ingest node
采集节点可以执行预处理管道,管道由一个或多个摄取处理器(ingest processors)组成
Coordinating node
搜索或者批量索引等需要处理的数据可能会存在不同数据节点中,所以es处理请求分为三个步,1、将请求分发给各数据节点;2、各数据节点在本地处理请求并返回结果给协调节点;3、协调节点将各节点返回结果整理为一个统一结果返回给客户端。
每个节点都是协调节点;当node.roles被配置为[]时,就是一个仅协调节点
Discovery
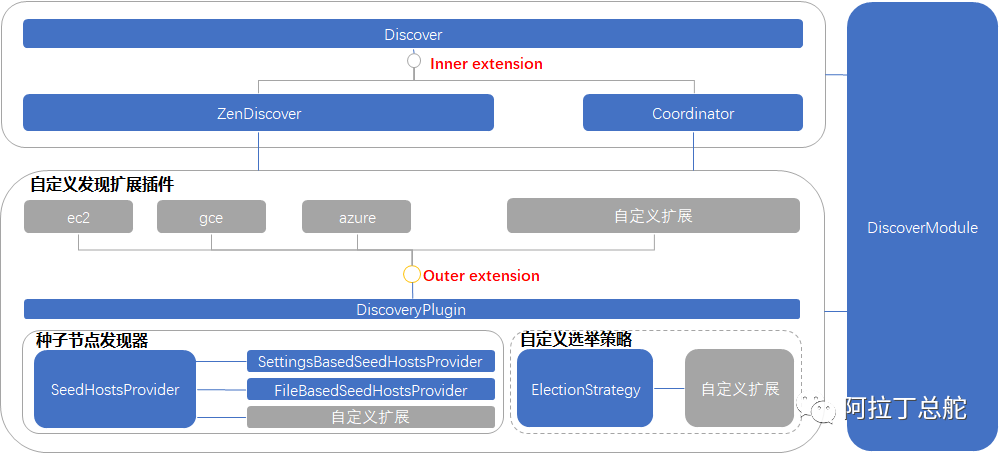
Discovery是在集群主节点未知时,互相发现对方的过程。例如新节点的加入或者主节点宕机后会启动服务发现。
es Discovery模块默认采用Gossip(谣言)协议机制来发现节点,组建集群。Gossip是一个最终一致算法。每个节点通过配置的或者文件中的节点地址,依次发起连接请求,如果连接成功且目标节点是Master-eligible node,则会将本节点的信息(Master-eligible node list)同步给目标节点,目标节点也将继续传播。发现过程最终会找到主节点或者找到足够多的Master-eligible节点进行选举。
elections 选举
在集群首次组成或者主节点宕机后,es集群会开启主节点选举。选举时,集群内具有投票资格的节点(master角色,包含仅投票节点)通过投票选择主节点,当一个节点获得了大多数投票(超过quonum,quonum由es自动维护),当投票节点为偶数时,为了避免脑裂,es会选择取消某个节点的投票权,保证节点为奇数。
当主节点发现自己能连接到的节点少于quonum,会自动降级;当发现其他主节点,且对方的cluster_state的version更大,则也会自动降级。
选主算法
数据存储结构

Shard
Shard 实际上是一个 Lucene 的一个实例(Lucene Index),但往往一个 Elastic Index 都是由多个 Shards (primary & replica)构成的。
特别注意,在单个 Lucene 实例里最多包含2,147,483,519 (= Integer.MAX_VALUE - 128) 个 Documents。
Lucene Index
一个 Lucene Index 在文件系统的表现上来看就是存储了一系列文件的一个目录。一个 Lucene Index 由许多独立的 segments 组成,而 segments 包含了文档中的词汇字典、词汇字典的倒排索引以及 Document 的字段数据(设置为Stored.YES的字段),所有的 segments 数据存储于 _<segment_name>.cfs的文件中。
Segments

Segment 直接提供了搜索功能的,ES 的一个 Shard (Lucene Index)中是由大量的 Segment 文件组成的,且每一次 fresh 都会产生一个新的 Segment 文件,这样一来 Segment 文件有大有小,相当碎片化。ES 内部则会开启一个线程将小的 Segment 合并(Merge)成大的 Segment,减少碎片化,降低文件打开数,提升 I/O 性能。
一个 Segment 包含映射到文档里的所有术语(terms)及 一个倒排索引 (inverted index)。
倒排索引
- 倒排索引是实现“单词-文档矩阵”的一种具体存储形式,
- 通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。
- 倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
倒排索引的结构
Elasticsearch通过lucene为每个field创建一个倒排索引。Lucene把用于存储Term的索引文件叫Terms Index,它的后缀是.tip;把Postings信息分别存储在.doc、.pay、.pox,分别记录Postings的DocId信息和Term的词频、Payload信息、pox是记录位置信息。Terms Dictionary的文件后缀称为.tim,它是Term与Postings的关系纽带,存储了Term和其对应的Postings文件指针。
总体来说,通过Terms Index(.tip)能够快速地在Terms Dictionary(.tim)中找到你的想要的Term,以及它对应的Postings文件指针与Term在Segment作用域上的统计信息。

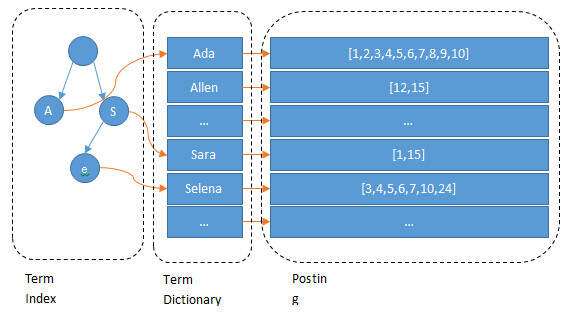
Posting List
Posting List 存储了符合某一个term的文档 id、词频、位置等信息,这些数据之间本身是相对独立的,因此 Lucene 将 Postings List 被拆成三个文件存储:
- .doc后缀文件:记录 Postings 的 docId 信息和 Term 的词频
- .pay后缀文件:记录 Payload 信息和偏移量信息
- .pos后缀文件:记录位置信息
基本所有的查询都会用 .doc 文件获取文档 id,且一般的查询仅需要用到 .doc 文件就足够了,只有对于近似查询等位置相关的查询则需要用位置相关数据。
.doc 文件存储的是每个 Term 对应的文档 Id 和词频。每个 Term 都包含一对 TermFreqs 和 SkipData 结构。
其中 TermFreqs 存放 docId 和词频信息,SkipData 为跳表信息,用于实现 TermFreqs 内部的快速跳转。
SkipData
在搜索中存在将每个 Term 对应的 DocId 集合进行取交集的操作,即判断某个 Term 的 DocId 在另一个 Term 的 TermFreqs 中是否存在。TermFreqs 中每个 Block 中的 DocId 是有序的,可以采用顺序扫描的方式来查询,但是如果 Term 对应的 doc 特别多时搜索效率就会很低,同时由于 Block 的大小是不固定的,我们无法使用二分的方式来进行查询。因此 Lucene 为了减少扫描和比较的次数,采用了 SkipData 这个跳表结构来实现快速跳转。
Term Dictionary
Terms Dictionary(索引表)存储所有的 Term 数据,同时它也是 Term 与 Postings 的关系纽带,存储了每个 Term 和其对应的 Postings 文件位置指针。
Terms Dictionary 通过 .tim 后缀文件存储,其内部采用 NodeBlock 对 Term 进行压缩前缀存储,处理过程会将相同前缀的的 Term 压缩为一个 NodeBlock,NodeBlock 会存储公共前缀,然后将每个 Term 的后缀以及对应 Term 的 Posting 关联信息处理为一个 Entry 保存到 Block。
在上图中可以看到 Block 中还包含了 Block,这里是为了处理包含相同前缀的 Term 集合内部部分 Term 又包含了相同前缀。
举个例子,在下图中为公共前缀为 a 的 Term 集合,内部部分 Term 的又包含了相同前缀 ab,这时这部分 Term 就会处理为一个嵌套的 Block。
Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样。Lucene 采用了 FST 这个数据结构来实现这个索引。
FST
FST, 全称 Finite State Transducer(有限状态转换器)。
它具备以下特点:
- 给定一个 Input 可以得到一个 output,相当于 HashMap
- 共享前缀、后缀节省空间,FST 的内存消耗要比 HashMap 少很多
- 词查找复杂度为 O(len(str))
- 构建后不可变更
倒排查询逻辑
在介绍了索引表和记录表的结构后,就可以得到 Lucene 倒排索引的查询步骤:
- 通过 Term Index 数据(.tip文件)中的 StartFP 获取指定字段的 FST
- 通过 FST 找到指定 Term 在 Term Dictionary(.tim 文件)可能存在的 Block
- 将对应 Block 加载内存,遍历 Block 中的 Entry,通过后缀(Suffix)判断是否存在指定 Term
- 存在则通过 Entry 的 TermStat 数据中各个文件的 FP 获取 Posting 数据
- 如果需要获取 Term 对应的所有 DocId 则直接遍历 TermFreqs,如果获取指定 DocId 数据则通过 SkipData快速跳转
分词算法
良好的分词,是增加搜索效率和搜索结果的重要因素,同理,分词也是一个搜索引擎的重要部分
分词的基本问题
简单的讲,汉语自动分词就是让计算机在汉语文本中的词与词之间自动加上空格或其他边界标记。分词中涉及到三个基本问题:分词规范、歧义切分和未登录词的识别。
分词规范
我们从小学习汉语开始,基本顺序就是汉字->词语->句子->段落->篇章,而其中词是什么,什么是词语,这个问题看似有些莫名其妙,但是如何界定一个词语却是分词中一个很重要的话题。有关专家的调查表明,在母语为汉语的被试者之间,对汉语文本中出现的词语的认同率只有大约70%,从计算的严格意义上说,自动分词是一个没有明确定义的问题[黄昌宁等,2003]。举个简单的例子:
“小明看到湖岸上的花草,一株不知名的小花引起了他的注意”
对于这句话中的“湖岸”、“花草”、“不知名”等,不同的词语界定方式就会出现不一样的分词结果,如我们可以切分成以下几种形式:
- “小明/看到/湖岸/上/的/花草/,一株/不知名/的/小花/引起/了/他的/注意”
- “小明/看到/湖/岸/上/的/花/草,一株/不/知名/的/小花/引起了/他的/注意”
- “小明/看到/湖岸/上的/花/草,一株/不知名的/小花/引起了/他的/注意”
我们可以看出不同的词语界定方式,可以组合出很多种分词结果,所以说分词可以看做是找寻一个没有明确定义问题的答案。所以当我们在衡量一个分词模型的好坏时,我们首先需要确定一个统一的标准,即所谓Golden Data,大家所有的模型都在统一的数据集上进行训练和评测,这样比较才会具有可参考性。
歧义切分
歧义字段在汉语中是普遍存在的,而歧义字段是汉语切分的一个重要难点。梁南元最早对歧义字段进行了两种基本的定义:
- 交集型切分歧义:汉字串AJB称作交集型切分歧义,如果满足AJ、JB同时为词(A、J、B分别为汉字串)。此时汉字串J称作交集串。如,大学生(大学/学生)、研究生物(研究生/生物)、结合成(结合/合成).
- 组合型切分歧义:汉字串AB称作多义组合型切分歧义,如果满足A、B、AB同时为词。如,起身(他|站|起|身|来/明天|起身|去北京)、学生会(我在|学生会|帮忙/我的|
学生|会来|帮忙)
我们可以看出歧义字段给我们的分词问题带来了极大的困扰,所以想要正确的做出切分判断,一定要结合上下文语境,甚至韵律、语气、重音、停顿等。
未登录词识别
未登录词,一种是指已有的词表中没有收录的词,另一种是指训练语料中未曾出现过的词。而后一种含义也可以被称作集外词,OOV(out of vocabulary),即训练集以外的词。通常情况下未登录词和OOV是一回事,我们这里不加以区分。
未登录词大体可以分为如下几个类型:
- 新出现的普通词汇,如网络用语当中层出不穷的新词,这在我们的分词系统这种也是一大挑战,一般对于大规模数据的分词系统,会专门集成一个新词发现模块,用于对新词进行挖掘发现,经过验证后加入到词典当中。
- 专有名词,在分词系统中我们有一个专门的模块,命名体识别(NER name entity recognize),用于对人名、地名以及组织机构名等单独进行识别。
- 专业名词和研究领域名称,这个在通用分词领域出现的情况比较少,如果出现特殊的新领域,专业,就会随之产生一批新的词汇。
- 其他专用名词,包含其他新产生的产品名、电影、书籍等等。
经过统计汉语分词出现问题更多是由于未登录词造成的,那么分词模型对于未登录词的处理将是衡量一个系统好坏的重要指标。
常用的汉语分词方法
基于词典的分词方法
基于词典的方法是经典的传统分词方法,这种方式很直观,我们从大规模的训练语料中提取分词词库,并同时将词语的词频统计出来,我们可以通过逆向最大匹配、N-最短路径以及N-Gram模型等分词方法对句子进行切分。基于词典的分词方法非常直观,我们可以很容易的通过增减词典来调整最终的分词效果,比如当我们发现某个新出现的名词无法被正确切分的时候,我们可以直接在词典当中进行添加,以达到正确切分的目的;同样的过于依赖于词典也导致这种方法对于未登录词的处理不是很好,并且当词典当中的词出现公共子串的时候,就会出现歧义切分的问题,这需要语料库足够的丰富,从而能够对每个词的频率有一个很好的设置。
浅谈分词算法(2)基于词典的分词方法 - xlturing - 博客园
基于字的分词方法
不同于基于词典的分词方法,需要依赖于一个事先编制好的词典,通过查词典的方式作出最后的切分决策;基于字的分词方法将分词过程看作是字的分类问题,其认为每个字在构造一个特定词语时都占据着一个确定的构词位置(词位)[1]。这种方法最早由薛念文等人于2002年提出,并在各种分词大赛上取得了不错的成绩,尤其是对未登录词问题的处理,召回率一直很高。
一般情况下,我们认为每个字的词位有4种情况:B(Begin)、E(End)、M(Middle)、S(Single),那么我们对于一个句子的切分就可以转为对句子中每个字打标签的过程,举个例子:
- 自然语言处理/可以/应用/在/诸多/领域。
- 自B 然M 语M 言M 处M 理E 可B 以E 应B 用E 在S 诸B 多E 领B 域E。
我们对句子中的每个字赋予了一个词位,即BEMS中的一个标签,这样我们就完成了分词的目的。
基于字的方法将传统的语言学问题转换为了一个更加容易建模的序列标注问题,我们可以用最大熵模型为每个字进行标签分类;也可以利用HMM将其看作一个解码问题;或者考虑句子间的时序关系,利用判别模型CRF来建模;同样时下火热的深度学习中的LSTM也可以用在这里进行建模。
浅谈分词算法(3)基于字的分词方法(HMM) - xlturing - 博客园
浅谈分词算法(4)基于字的分词方法(CRF) - xlturing - 博客园
浅谈分词算法(5)基于字的分词方法(bi-LSTM) - xlturing - 博客园
其他
乐观锁
elasticsearch新版增加了基于_version、_seq_no、_primary_term字段,三个字段做乐观锁并发控制。
_version:标识文档的版本号,只有当前文档的更新,该字段才会累加;以文档为维度。
_seq_no:标识整个Index中的文档的版本号,只要Index中的文档有更新,就会累加该字段值;以Index为维度记录文档的操作顺序。
_primary_term:针对故障导致的主分片重启或主分片切换,每发生一次自增1;以分片为维度。
在 Elasticsearch中,并发更新时保证_version字段的原子性是通过内部的版本控制机制和分布式锁来实现的。Elasticsearch使用分布式锁来确保在更新文档时‘_version字段的原子性。当多个客户端同时更新同一文档时,只有一个客户端能够获得分布式锁,并且其他客户端会被阻塞,直到获得锁的客户端完成更新操作。下面是Elasticsearch在并发更新时保证‘_version丶字段原子性的工作流程:
1.获取分布式锁:当一个客户端请求更新文档时,Elasticsearch会尝试获取分布式锁。只有成功获取锁的客户端才能进行更新操作。
2.检查版本号冲突:获取锁后,Elasticsearch会检查客户端提供的版本号与实际文档的版本号是否一致。如果一致,表示没有冲突,操作可以继续进行。如果不一致,表示发生了版本冲突,更新操作会被拒绝。
3.原子性更新版本号:如果没有发生版本冲突,Elasticsearch会原子性地递增文档的版本号,并在后续的更新操作中使用新的版本号。
4.更新文档内容:在版本号更新完成后,Elasticsearch会执行实际的文档更新操作,包括更新字段的值、添加或删除字段等。
5.释放分布式锁:更新操作完成后,Elasticsearch会释放分布式锁,允许其他等待的客户端获取锁并进行更新操作。
数据索引过程
索引是一个相对简单的高级过程,包括:
- 通过 API 到达数据
- 路由到正确的索引、分片和节点
- 映射、规范化和分析
- 存储在内存和磁盘上
- 使其可供搜索
写入磁盘
1、写入节点内存中
2、通过refresh动作写入内存段与translog中,此时可以搜索,通常每秒执行一次
3、通过frush动作写入磁盘,当translog文件达到上限或者每30分钟
4、合并段

 浙公网安备 33010602011771号
浙公网安备 33010602011771号