

elk是一个日志集中式日志收集处理解决方案;能够完成日志的收集,数据清洗,存储与索引,分析等;发展至今已有不少优化替换方案
-
收集:Logstash,FileBeats,Elastic Agent
-
数据清洗:Logstash(filter),FileBeats(Beats processors),Ingest pipelines
-
存储与索引:Elasticsearch
-
分析:Kibana
各组件简单介绍
Logstash
Logstash 是一款基于插件的数据收集和处理引擎。Logstash 配有大量的插件,以便人们能够轻松进行配置以在多种不同的架构中收集、处理并转发数据。
处理过程可分为一个或多个管道。在每个管道中,会有一个或多个输入插件接收或收集数据,然后这些数据会加入内部队列。默认情况下,这些数据很少并且会存储于内存中,但是为了提高可靠性和弹性,也可进行配置以扩大规模并长期存储在磁盘上。
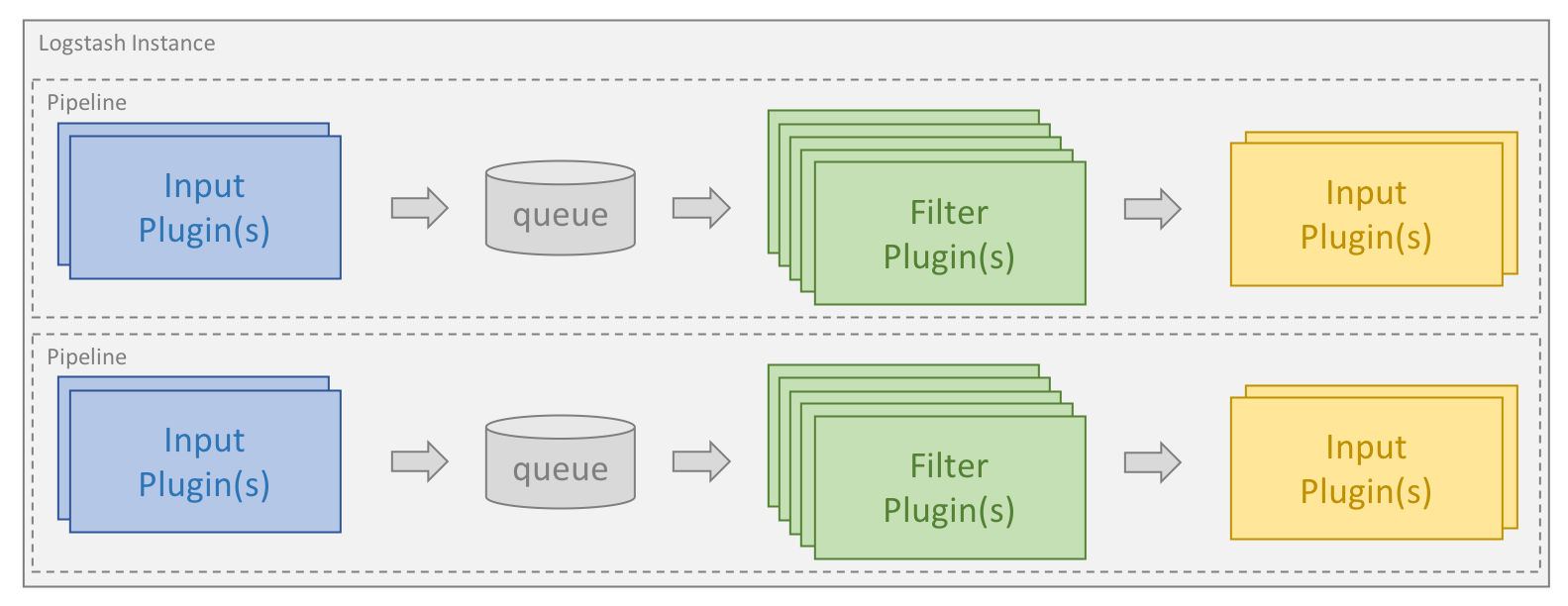
处理线程会以小批量的形式从队列中读取数据,并通过任何配置的过滤插件按顺序进行处理。Logstash 自带大量的插件,能够满足特定类型的操作需要,也就是解析、处理并丰富数据的过程。
处理完数据之后,处理线程会将数据发送到对应的输出插件,这些输出插件负责对数据进行格式化并进一步发送数据(例如发送到 Elasticsearch)。
输入和输出插件也可以配置 codec 插件。这样便可以在将数据添加到内部队列或发送到输出插件之前对数据进行解析和/或格式化。
输入
常用插件有file,beats,redis,kafka,Logstash等
Input plugins | Logstash Reference [8.12] | Elastic
过滤器
常用插件有grok、date、mutate、mutiline等
Filter plugins | Logstash Reference [8.12] | Elastic
输出
常用插件为elasticsearch,redis,kafka,Logstash等
Output plugins | Logstash Reference [8.12] | Elastic
Persistent Queue
PQ介绍
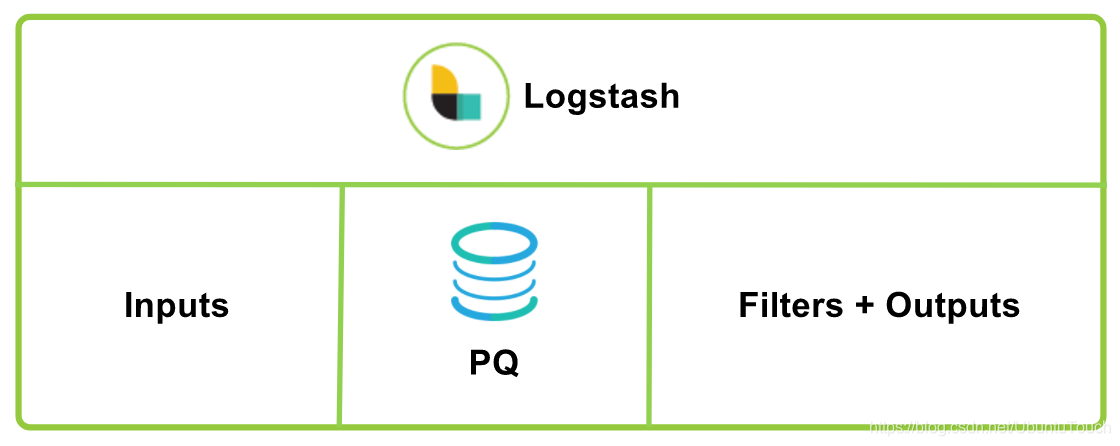
PQ,也即永久队列。默认情况下,Logstash 在input和 filter + output 管道阶段之间使用内存中排队。 这使它可以吸收负载中的小峰值,而无需保持将事件推入 Logstash 的连接,但是缓冲区仅限于内存容量。 如果 Logstash 发生故障,则正在处理的运行中和内存中数据将丢失。
为了提供不限于内存容量的缓冲区,并防止异常终止期间的数据丢失,Logstash 引入了持久队列功能。 它将输入数据作为自适应缓冲区存储在磁盘上,并在处理完成后将流水线确认送回到持久队列。 重新启动 Logstash 时,将重播任何未确认的数据(未完全处理和输出)。
总而言之,启用持久队列的好处如下:
-
无需大量的外部缓冲机制(例如Redis或Apache Kafka)即可吸收突发事件。
-
提供一次至少一次传递保证,以防止在正常关闭以及Logstash异常终止时丢失消息。 如果在发生事件时重新启动Logstash,则Logstash将尝试传递存储在持久队列中的消息,直到传递至少成功一次。
初步设计目标
至少一次交付:PQ设计的主要目标是在出现异常故障时避免数据丢失,并旨在提供至少一次交付的保证。至少一次交付意味着发生故障时,重新启动 Logstash 时将重播所有未确认的数据。根据故障情况,“至少一次” 还意味着可以重播已处理但未确认的数据,并导致重复处理。这是至少一次的权衡;以无故障的情况下避免数据丢失为代价,可能会有重复数据的代价;重复数据可以文件的fingerprint与其他数据信息生成es的doc _id来处理,参见重复数据处理
Spooling:PQ 还可在磁盘上增大大小,并在不对输入施加反压的情况下帮助处理数据摄取峰值或输出减慢。在这两种情况下,输入或摄取端的处理速度都比 Logstash 的过滤和输出端更快。使用 PQ,传入的数据将在磁盘上本地缓冲,直到过滤和输出阶段能够赶上。对于使用外部排队层处理吞吐量峰值和减轻背压的现有用户,PQ 现在能够自然满足这些要求。因此,用户可以选择删除此外部队列,以简化总体摄取架构。
弹性和耐久性
有3种类型的故障会影响Logstash:
-
应用程序/进程级别崩溃/中断的关机。这是 PQ 帮助解决潜在数据丢失的最常见原因。当 Logstash 异常崩溃或在进程级别被杀死或通常以防止安全关闭的方式被中断时,会发生这种情况。使用内存队列时,这通常会导致数据丢失。使用 PQ,无论持久性设置如何(请参阅 queue.checkpoint.writes 设置),都不会丢失任何数据,并且在重新启动 Logstash 时将重播任何未确认的数据。
-
操作系统级崩溃:内核崩溃或计算机重新启动。使用 PQ 默认设置,可能会丢失在上一次 fsync 和 OS 级崩溃之间没有安全地写入磁盘(fsync)的数据。可以更改此行为并将 PQ 配置为具有最大持久性,其中每个传入事件都将被强制写入磁盘(fsync)。请参阅 “Durability” 部分和queue.checkpoint.writes设置。
-
存储硬件故障。 PQ 不提供复制来帮助解决存储硬件故障。防止磁盘故障时数据丢失的唯一方法是在云环境中使用 RAID 等外部复制技术或等效的冗余磁盘选件。
PQ 使用大小为 queue.page_capacity(默认为250mb)的页面文件来写入输入数据。 最新页面称为首页,是仅以追加方式写入数据的页面。 当首页到达 queue.page_capacity 时,它变成不可变的尾页,并创建一个新的首页以写入新数据。首页的持久性特征是使用 queue.checkpoint.writes 设置控制的。 默认情况下,PQ 将在每 1024 个收到的输入事件时强制将数据写入磁盘,以减少 OS 级崩溃时潜在的数据丢失。 请注意,无论 queue.checkpoint.writes 设置如何,应用程序和进程级别的崩溃或中断的关闭都绝不会导致数据丢失。 如果要防止操作系统级别崩溃的潜在数据丢失,可以使用 queue.checkpoint.writes:1 设置将 PQ 设置为最大持久性,但是请注意,这将导致 IO 性能显着降低。
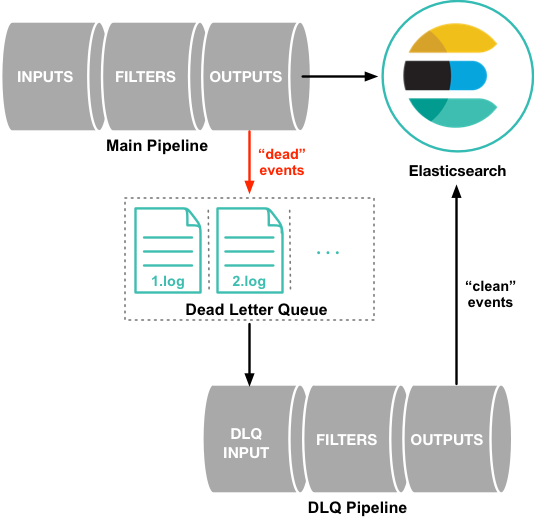
dead letter queue (DLQ)
logstash原生支持死信队列处理异常数据,这只是一个 Dead_letter_queue input plugin 处理这部分异常数据,
Beats
Beats 是轻量级(资源高效,无依赖性,小型)和开放源代码日志发送程序的集合,这些日志发送程序充当安装在基础结构中不同服务器上的代理,用于收集日志或指标(metrics)。这些可以是日志文件(Filebeat),网络数据(Packetbeat),服务器指标(Metricbeat)或 Elastic 和社区开发的越来越多的 Beats 可以收集的任何其他类型的数据。 收集后,数据将直接发送到 Elasticsearch 或 Logstash 中进行其他处理。Beats 建立在名为 libbeat 的 Go 框架之上,该框架用于数据转发。
Beats与Logstash对比
作为数据采集工具,Beats相对Logstash更为轻量级;Beats 是基于 Lumberjack 协议用 Go 语言编写的,旨在实现内存占用少,处理大量数据,支持加密以及有效处理背压。Logstash由java开发,需要运行jvm,消耗资源大
在数据清洗方面,Beats processors仅支持简单处理;Logstash有丰富的过滤插件来解析、处理并丰富数据
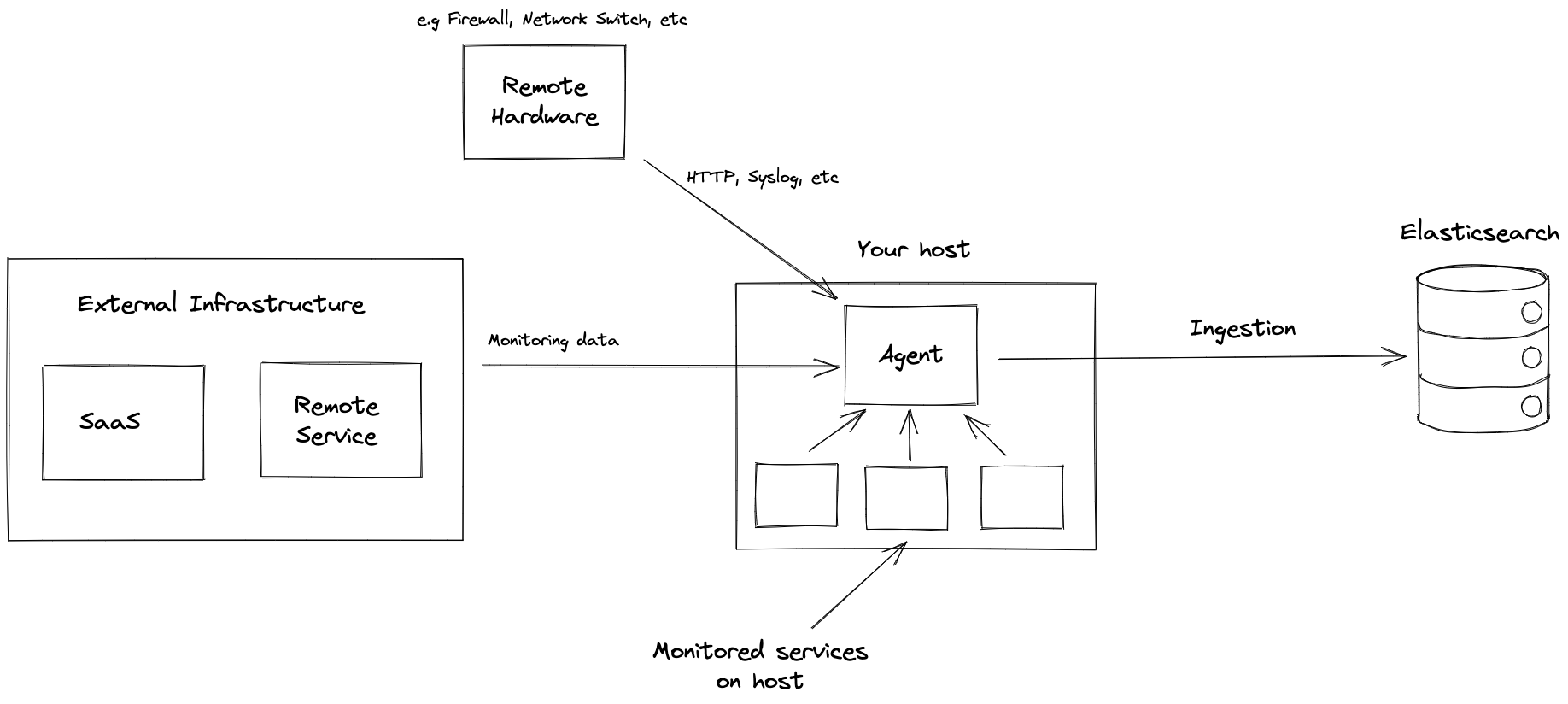
Elastic Agent
Elastic Agent与Beats的定位比较类似,是收集日志或指标(metrics)的一个工具,不同的是Elastic Agent能够以统一分方式从各个服务中收集数据,与fleet配合能够实现集中式管理,更为便捷
主要功能
-
数据采集:Elastic Agent支持多种数据采集,包括指标采集、日志采集、安全事件采集等。 它可以从系统指标、日志、网络流量、安全事件和其他来源收集数据。
-
集成Beats:Elastic Agent 包含多个内置Beats,借助 Elastic Agent,可以轻松配置和管理 Beats 功能,无需单独安装。
-
Elastic Fleet:Elastic Fleet 是 Elastic Agent 的集中管理系统。 Elastic Fleet 提供了一个统一的界面,用于管理多个主机上的代理配置、策略和更新,从而更轻松地扩展和维护大型部署。
-
安全与合规:Elastic Agent 支持传输加密和身份验证等安全功能,以确保代理与 Elasticsearch 之间的安全通信。 它还通过促进安全相关数据的收集和监控来帮助合规性。
-
监控和故障排除:Elastic Agent 可以监控远程硬件状态和运行状况。
与Beats比较
Elastic Agent与Beats都是es提供的收集数据的工具。Elastic Agent可以同时收集多种不同类型的日志,指标(metrics);而通过Beats,则需要部署多个不同Beat。Elastic Agent还可以通过Feelt进行批量管理,大大降低大型集群服务的管理复杂度
输出方式比较
| 输出 | Beats | 由 Fleet 管理的 Elastic Agent | Standalone Elastic Agent |
|---|---|---|---|
| Elasticsearch Service | yes | yes | yes |
| Elasticsearch | yes | yes | yes |
| Logstash | yes | yes | yes |
| Kafka | yes | yes (beta) | yes (beta) |
| Redis | yes | no | no |
| File | yes | no | no |
| Console | yes | no | no |
在8.12版本中的能力比较
以下表格内容由谷歌机器翻译,原文参考:Beats and Elastic Agent capabilities | Fleet and Elastic Agent Guide [8.12] | Elastic
| 能力 | Beats | Fleet-managed Elastic Agent | Standalone Elastic Agent | 描述 |
|---|---|---|---|---|
| 适用于所有用例的单一代理 | no | yes | yes | Elastic Agent 提供日志、指标等。 你需要为这些用例安装多个 Beats。 |
| 从 Web UI 或 API 安装集成 | no | yes | yes | Elastic Agent 集成使用方便的 Web UI 或 API 安装,但 Beats 模块使用 CLI 安装。 这将安装 Elasticsearch 资产(例如索引模板和摄取管道)以及 Kibana 资产(例如仪表板)。 |
| 从 Web UI 或 API 配置 | no | yes | yes(可选) | 可以在 Web UI 或 API 中配置 Fleet-managed Elastic Agent 集成。 独立 Elastic Agent 可以使用 Web UI、API 或 YAML。 Beats 只能通过 YAML 文件进行配置。 |
| 中央、远程代理策略管理 | no | yes | no | Elastic Agent 策略可以通过 Fleet 集中管理。Beats必须自己或使用第三方解决方案管理配置。 |
| 中央、远程代理二进制升级 | no | yes | no | 可以通过 Fleet 远程升级 Elastic Agent。 Beats必须自己升级或使用第三方解决方案。 |
| 为单个集成或模块添加 Kibana 和 Elasticsearch 资产 | no | yes | yes | Elastic Agent 集成允许为单个集成添加 Kibana 和 Elasticsearch 资产。 Beats 一次为所有模块安装数百个资产。 |
| 自动生成的 Elasticsearch API 密钥 | no | yes | no | Fleet 可以为每个 Elastic Agent 自动生成具有有限权限的 API 密钥,这些密钥可以单独撤销。 独立的 Elastic Agent 和 Beats 需要你创建和管理凭据,并且用户通常会跨主机共享它们。 |
| 自动生成最小 Elasticsearch 权限 | no | yes | no | Fleet 可以根据正在运行的输入自动为 Elastic Agent 提供最小的输出权限。 使用独立的 Elastic Agent 和 Beats,用户通常会授予过于广泛的权限,因为这样更方便。 |
| 数据流支持 | yes | yes | yes | Beats(从 8.0 版开始默认)和 Elastic Agents 使用数据流,索引生命周期管理和数据流命名方案更容易。 |
| 变量和输入条件 | no | yes (有限) | no | Elastic Agent 提供变量和输入条件以根据本地主机环境动态调整。 用户可以直接在 YAML 中为独立的 Elastic Agent 配置这些,或者使用 Fleet API 为 Fleet-managed Elastic Agent 配置这些。 Integrations 应用程序允许用户输入变量,我们正在考虑使用UI 来编辑条件。 Beats 仅提供静态配置。 |
| 允许非超级用户管理资产和代理 | yes | yes | yes (可选) | 从版本 8.1.0 开始,不再需要超级用户角色即可使用 Fleet 和 Integrations 应用程序以及相应的 API。 这些应用程序对于独立的 Elastic Agent 是可选的。 Beats 提供更细粒度的角色。 |
| 气隙网络支持 | yes | yes (有限) | yes | Integrations 和 Fleet 应用程序可以部署在 Elastic Package Registry 的气隙环境自我管理部署中。Fleet 管理的Elastic Agents 需要连接到我们的工件存储库以进行代理二进制升级。 但是,可以修改策略以使代理指向本地服务器以获取代理二进制文件。 |
| 在主机上使用 root 运行 | yes | no | no | Fleet-managed Elastic Agents 需要 root 权限,特别是对于 Elastic Defend。 独立的 Elastic Agents 和 Beats 则没有。 |
| 多个输出 | yes | yes | yes | 单个 Fleet 管理的 Elastic Agent 的策略可以指定多个输出。 |
| 独立监控集群 | yes | yes | yes | Fleet 管理的 Elastic Agent 仅向运行 Fleet 的同一 Elasticsearch 集群提供单个全局输出。 我们正在考虑支持远程监控集群。 独立的 Elastic Agent 和 Beats 可以发送到远程监控集群。 |
| 秘钥管理 | yes | no | no | Elastic Agent 将凭据存储在代理策略中。 我们正在考虑添加 keystore 支持。 Beats 允许用户访问本地 keystore 中的凭据。 |
| 渐进式或金丝雀部署 | yes | no | yes | Fleet 没有逐步部署 Elastic Agent 策略更新的功能,但我们正在考虑改进支持。 借助独立的 Elastic Agent 和 Beats,你可以使用第三方解决方案逐步部署配置文件。 |
| 每个主机的多个配置 | yes | no(改用输入条件) | no(改用输入条件 | Elastic Agent 使用单个 Elastic Agent 策略进行配置,并使用变量和输入条件根据每个主机进行调整。 Beats 支持每个主机有多个配置文件,使第三方解决方案能够分层或在多个组中部署文件,并对这些文件实现更细粒度的访问控制。 |
| 兼容版本控制和基础架构即代码解决方案 | yes | no(仅通过api) | yes | Fleet 将代理策略存储在 Elasticsearch 中。 它不作为代码解决方案与外部版本控制或基础架构集成,但我们正在考虑改进支持。 但是,独立模式下的 Beats 和 Elastic Agent 使用与这些解决方案兼容的 YAML 文件。 |
| 将数据刷到本地磁盘 | yes | no | no | 正在考虑开发 |
Ingest pipelines
摄取管道(Ingest pipelines)管道由一组处理器(processors)组成,按顺序对数据进行处理(格式化,提取,丰富等),然后将数据输出到数据流(data stream)或者索引(index)。
摄取管道(Ingest pipelines)只运行在摄取节点(Ingest node)中。协调节点(Coordinating node)将原始数据转发到摄取节点中,摄取管道处理后再转发数据节点(Data node)
方案介绍
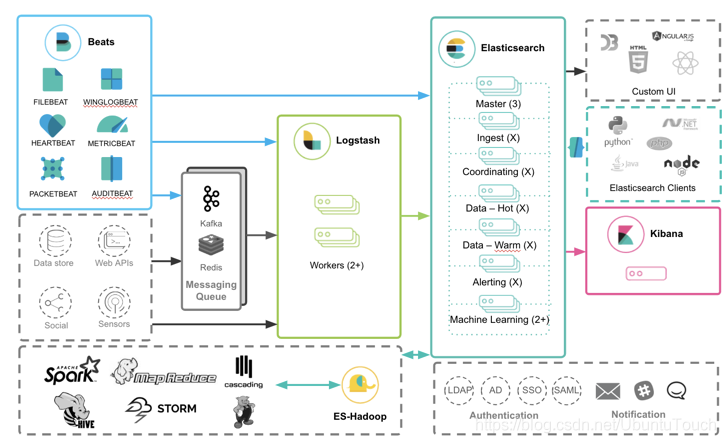
ELK原始方案
Logstash => Elasticsearch => Kibana
Logstash => Queue(Kafka,redis) => Logstash => Elasticsearch => Kibana
与Beats结合衍生方案
Beats相较Logstash,优势在于作为数据收集工具,它很轻
Beats => Elasticsearch => Kibana
Beats => Logstash => Elasticsearch => Kibana
Beats => Ingest pipelines => Elasticsearch => Kibana
Beats => Queue(Kafka,redis) => Logstash => Elasticsearch => Kibana
使用Elastic Agent替换Beats衍生方案
上述枚举的Beats方案,Beats所在位置都可以由Elastic Agent替换;
Elastic Agent相较于Beats,优势有:1、可以由fleet集中管理与部署升级;2、在一台主机中可以监控多种数据(日志,指标等),Beats需要部署多个不同用户的Beat。劣势在于需要另外部署一个fleet服务,另外支持的功能不如Beats
索引生命周期管理(ILM)与数据分层
索引生命周期管理 (ILM) 是在 Elasticsearch 6.6(公测版)首次引入并在 6.7 版正式推出的一项功能。ILM 是 Elasticsearch 的一部分,主要用来帮助管理索引,随着时间推移进行自动化管理。
我们可以根据性能,索引文档数量、大小等弹性要求,文档的保留需求等方面来自定义索引生命周期管理策略,我们可以使用ILM实现如下需求
-
当索引达到一定的大小或者一定的文档数量时生成一个新的索引
-
每天、每周或者每个月创建一个新索引、并把之前的索引归档
-
删除历史索引、按照数据保留标准执行是否保留索引
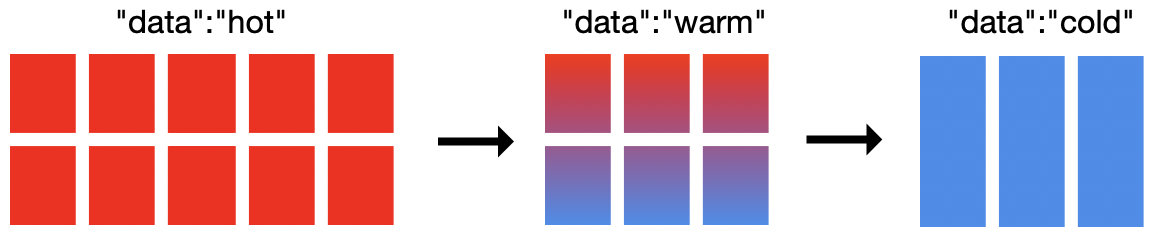
一般我们通过es的数据分层(Data Tiers)进行对时序数据(日志等)进行索引生命周期管理,通过配置,我们可以将es集群的节点分层:hot(索引与频繁查询),warm(仅查询,较频繁),cold(查询频率低)
-
hot:hot节点会频繁索引数据与查询数据,希望是使用高性能节点,es推荐内存:磁盘是1:30
-
Warm:warm节点仅支持查询,可以使用次一级节点,es推荐内存:磁盘是1:100;当索引进入warm阶段时,ILM会将索引收缩到1个分片,索引数据也将强制合并为1个段(segment),并迁移到warm节点
-
Cold:到cold阶段,查询频率一般不高,且不允许更新,机器性能要求再次降低。在这个阶段,数据可以通过完全挂载的可搜索快照恢复主分片数据,不再需要副本分片,磁盘占用将再降低50%,
-
Frozen:Frozen阶段,几乎不再查询,Frozen存储的将是部分挂载的可搜索快照,这将进一步释放存储
可搜索快照
快照:es可以通过命令执行生成索引快照,并存储到远程对象存储中(S3,HDFS)Snapshot and restore | Elasticsearch Guide [8.12] | Elastic
可搜索快照顾名思义,就是字面意思
工作原理
从快照挂载索引时,Elasticsearch 会将其分片分配给集群中的节点。然后,数据节点会自动检索将相关分片数据从存储库到本地存储 。如果数据在本地,Elasticsearch 从快照存储库下载所需的数据。
如果其中一个分片的节点发生故障,Elasticsearch 会自动在另一个节点上创建一个有效分片,该节点会从快照存储库中恢复相关的分片数据
挂载方式
要搜索快照,必须先将其作为索引挂载到本地。通常ILM 将自动执行快照挂载
-
完全挂载: 完全挂载会将快照的索引全部缓存在节点本地。完全挂载索引的搜索性能通常与常规索引相当,因为很少需要访问快照存储库。当正在恢复/挂载时,搜索性能可能比常规索引慢,因为可能需要访问快照存储库,获取一些没有在本地的数据。节点重新启动时,会直接从节点本地磁盘恢复快照索引
-
部分挂载: 部分挂载仅会在本地缓存部分数据,缓存有固定大小。如果缓存中没有需要的数据,es会从远程快照中获取,并存在本地缓存中。es会正对缓存管理,清除不常用的缓存数据。es针对远程快照库的数据布局进行了优化,虽然部分挂载的检索性能不如普通索引,但还是很快的
Data streams
时序性数据
时间序列数据( time series data )是在不同时间上收集到的数据,用于所描述现象随时间变化的情况。这类数据反映了某一事物、现象等,随时间的变化状态或程度。
对于 Elastisearch 处理时序性数据,主要有以下特点:
- 由时间戳 + 数据组成。基于时间的事件,可以是服务器日志或者社交媒体流。
- 通常搜索最近事件,旧文件变得不太重要。
- 索引的使用主要基于时间,但是数据并不一定随着时间均衡分布。
- 时序性数据一旦存入后很少修改。
- 时序性数据随着时间的增加,数据量会很大。
Data streams介绍
Data stream (数据流)是 Elastic Stack 7.9 的开始推出的一个功能。Data stream 使你可以跨多个索引存储只追加数据的时间序列数据,同时为请求提供唯一的一个命名资源。 data stream 非常适合日志,事件,指标以及其他持续生成的数据。
简单来说,Data stream 根据模板生成存储数据的后备索引,然后自动将搜索或者索引请求路由到存储流数据的后备索引。而这些后备索引则根据索引生命周期管理( ILM )来自动管理。
Data stream的组成
数据流在 Elasticsearch 集群中由一个或多个隐藏的、自动生成的后备索引组成。
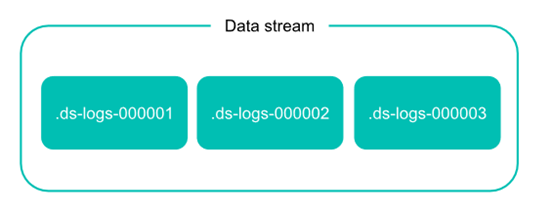
在实际的 Elasticsearch 操作中,数据流依靠索引模板来设定数据流实体的后备索引。
- 模板包含用于配置流的后备索引的映射和设置。
- 同一个索引模板可用于多个数据流。
- 不能删除数据流正在使用的索引模板。
每个索引到数据流的文档,必须包含一个 @timestamp 字段,映射为 date 或 date_nanos 字段类型。如果索引模板没有为 @timestamp 字段指定映射,Elasticsearch 将 @timestamp 映射为带有默认选项的日期字段。
Data stream 的特性
生成
每个 Data stream 的后备索引都有一个 generation 数,一个六位数,零填充的整数,从 000001 开始,用作该流的 rollover 的计数。
后备索引名主要依照以下格式:
.ds—
Generation 越大,后备索引包含的数据越新。 例如,web-server-logs 数据流最新的 generation 为 34。该流的最新后备索引名为 .ds-web-server-logs-000034。
注意:某些操作(例如 shrink 或 restore )可以更改后备索引的名称。 这些名称更改不会从其数据流中删除后备索引。
Rollover
在 Data stream 的使用中,rollover 是必不可少的条件。
创建数据流时,Elasticsearch 会自动为该 Data stream 根据 template 创建一个后备索引。 该索引还充当流的第一个写入索引。当满足一定条件时, rollover 会创建一个新的后备索引,该后备索引将成为 Data stream 的新写入索引。
当然 rollover 的条件设置主要依靠 ILM。 如果需要,你还可以手动将数据 rollover 。
追加
由于时序性数据的特征,Data stream 的设计场景中,数据是只追加的,极少需要修改删除。如果实际需要修改删除,则可以考虑以下操作:
- 对于数据流只能通过 update by query 或者 delete by query 操作,不能进行 update 或者 delete 文档。
- 需要 delete 或者 update 文档,则直接对后备索引操作。
- 需要经常删除或者修改文档的,请使用索引别名或者索引模板,不要对 Data stream 操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号