


🧬 C# 神经网络计算库和问题求解
Andrew Kirillov 著
Conmajia 译
2019 年 1 月 12 日原文发表于 CodeProject
2006 年 11 月 19 日 ( 已获作者本人授权 ) , 。 本文介绍了一个用于神经网络计算的 C# 库
并展示了如何用这个函数库进行问题求解 , 。
这个库最终命名为 ANNTAForge.Neuro 的组成部分
简介
众所周知
本文介绍了一个用于神经网络计算的 C# 库
- 分类
( ) - 近似
( ) - 时间序列预测
( ) - 颜色聚类
( ) - 旅行商问题
( )
文章开头的源码和演示文件中包含了以上内容和一些没有列出的例子
这篇文章不是讲解神经网络基础理论的入门书籍
使用方法
设计一个函数库
这个库包含了 6 个主要的部分
Neuron
Layer
Network
IActivationFunction
IUnsupervisedLearning
ISupervisedLearning
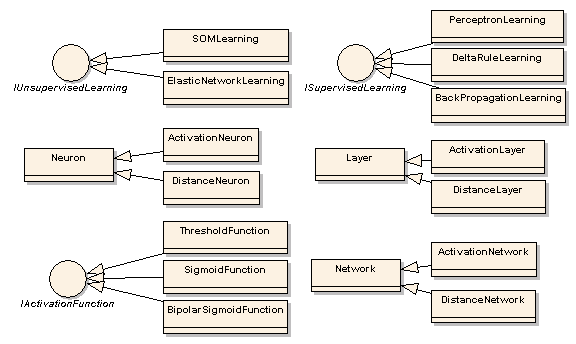
ANNT 提供了以下的神经网络结构
激活网络
一个单层或多层的神经网络
距离网络
每个神经元将输出作为权重值和输入值之间的距离的神经网络
采用了不同的学习算法用于训练不同的神经网络
感知器
可以追述到 1957 年的算法
增量规则
该算法是继感知器学习算法之后的下一步
反向传播
这是最流行的多层神经网络学习算法之一
自组织映射学习
简称 SOM 算法
弹性网络
类似于 SOM 学习算法的思想
更多详细内容AForge.Neuro 部分找到
AForge.Neuro 帮助文档演示
分类 ( )
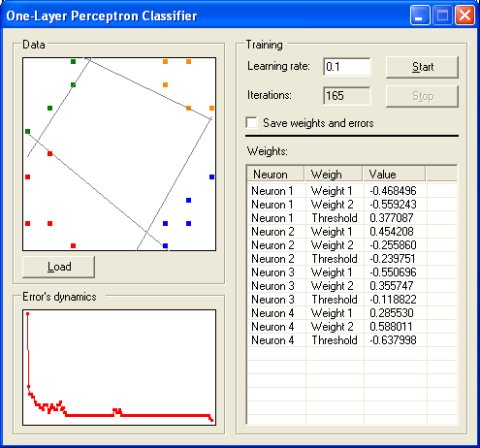
这个例子中使用了一个具有阈值激活函数的单层激活网络和感知器学习算法
// 准备学习数据
double[][] input = new double[samples][];
double[][] output = new double[samples][];
// 生成感知器
ActivationNetwork network = new ActivationNetwork( new ThresholdFunction( ),
2, classesCount );
// 生成训练器
PerceptronLearning teacher = new PerceptronLearning( network );
// 设置学习速率
teacher.LearningRate = learningRate;
// 循环
while ( ... )
{
// 运行学习程序
double error = teacher.RunEpoch( input, output );
...
}
尽管这个网络结构很简单
逼近 ( )
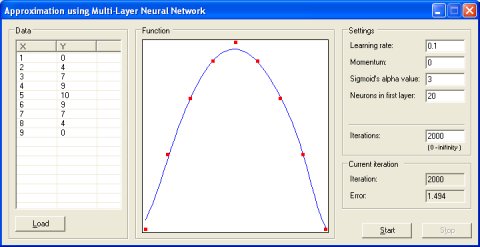
这个例子演示了使用反向传播算法训练的多层神经网络min 和 max X 的范围内
// 准备学习数据
double[][] input = new double[samples][];
double[][] output = new double[samples][];
// 生成多层神经网络
ActivationNetwork network = new ActivationNetwork(
new BipolarSigmoidFunction( sigmoidAlphaValue ),
1, neuronsInFirstLayer, 1 );
// 生成训练器
BackPropagationLearning teacher = new BackPropagationLearning( network );
// 设置学习速率和动量
teacher.LearningRate = learningRate;
teacher.Momentum = momentum;
// 循环
while ( ... )
{
// 运行学习程序
double error = teacher.RunEpoch( input, output ) / samples;
...
}
这种多层神经网络结构不仅可以用于二维函数的逼近
时间序列预测 [7] ( )
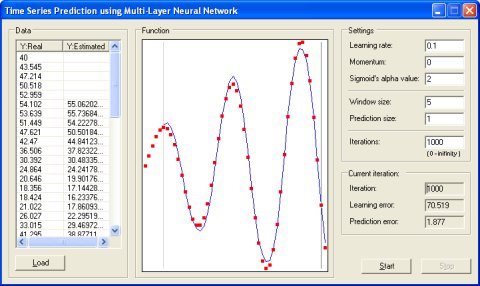
该个例子演示了一种具有反向传播学习算法
演示代码与上一个例子相同
颜色聚类 ( )
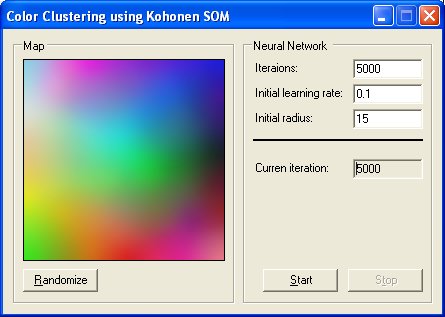
这是一个非常简单的示例RGB 值RGB 调色板
// 设置神经元权重随机范围
Neuron.RandRange = new DoubleRange( 0, 255 );
// 创建网络
DistanceNetwork network = new DistanceNetwork( 3, 100 * 100 );
// 创建学习算法
SOMLearning trainer = new SOMLearning( network );
// 输入
double[] input = new double[3];
// 循环
while ( ... )
{
// 更新学习速率和半径
// ...
// 准备网络输入
input[0] = rand.Next( 256 );
input[1] = rand.Next( 256 );
input[2] = rand.Next( 256 );
// 运行学习迭代
trainer.Run( input );
...
}
这个例子里
你也可以用其他对象来代替颜色
旅行商问题 ( )
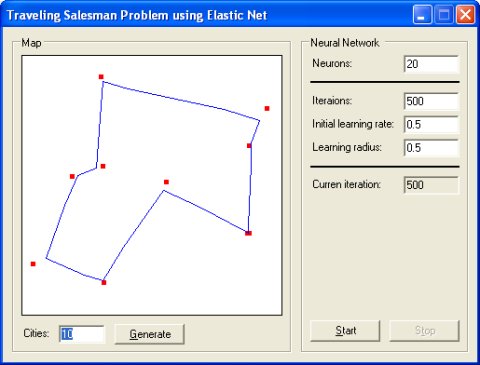
旅行商问题证明了弹性网络的应用(x, y) 坐标
// 设置随机范围
Neuron.RandRange = new DoubleRange( 0, 1000 );
// 生成网络
DistanceNetwork network = new DistanceNetwork( 2, neurons );
// 生成学习算法
ElasticNetworkLearning trainer = new ElasticNetworkLearning( network );
// 输入
double[] input = new double[2];
// 循环
while ( ... )
{
// 设置网络输入
int currentCity = rand.Next( citiesCount );
input[0] = map[currentCity, 0];
input[1] = map[currentCity, 1];
// 运行训练迭代
trainer.Run( input );
...
}
这种方法的缺点是它不能提供精确的解
结论
上面的五个例子表明
历史版本
- [12.01.2019] 译文首次发表
- [19.11.2006] 原文首次发表
许可
本文以及任何相关的源代码和文件都是根据 GNU
关于作者

Andrew Kirillov
Perceptron, Wikipedia ↩︎
Delta Rule, Wikipedia ↩︎
Back Propagation, Wikipedia ↩︎
Self-Organizing Map, Wikipedia ↩︎
Elastic Net Tutorial, Andrei Cimponeriu, Oct. 12, 1999 ↩︎
一种常用的非线性激活函数
, , , 。 时间序列预测法其实是一种回归预测方法
, , , , ; , , , , 。
if(jQuery('#no-reward').text() == 'true') jQuery('.bottom-reward').addClass('hidden');


· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?