Linux服务器资源占用率总结
统计内存最高的进程:
ps aux | grep -v PID | sort -rn -k 4 | head
统计CPU使用率最高的进程:
ps aux | grep -v PID | sort -rn -k 3 | head
僵尸进程:
ps aux | grep defunct | grep -v grep
查找进程启动的线程:
ps -eLf PID
查看网络服务状态:
netstat -ntlp --显示正在listening的tcp的数字格式的连接
netstat -nulp --显示正在listening的udp的数字格式的连接
硬件故障分析:
1.检查磁盘使用量:服务器硬盘是否已满。
2.是否开启了swap交换模式(si/so)。
3.CPU使用情况:占用高CPU时间片的是系统进程还是用户进程。
查看CPU和内存信息:
free -m

Mem为物理内存的容量。
Swap为虚拟内存的容量。
total为总容量。
used为已用容量。
free为空闲容量。
shared为共享容量。
buff/cache为缓冲及缓存的容量。
avaiable为真正可用容量。
一般swap used的值最好不要超过20%。
top --CPU和内存使用实际统计
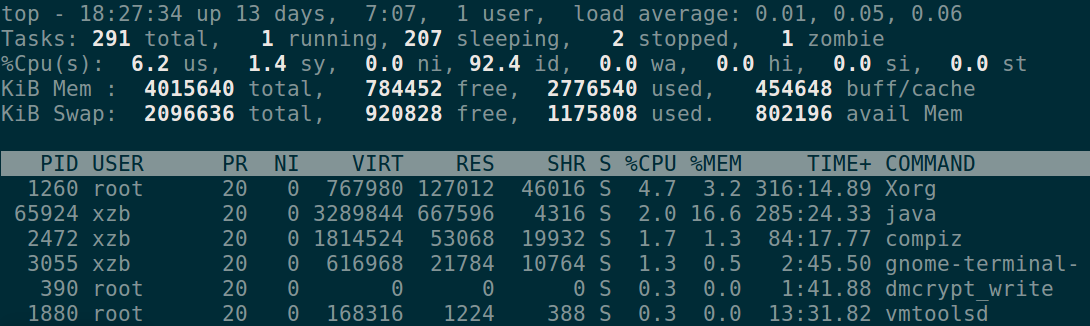
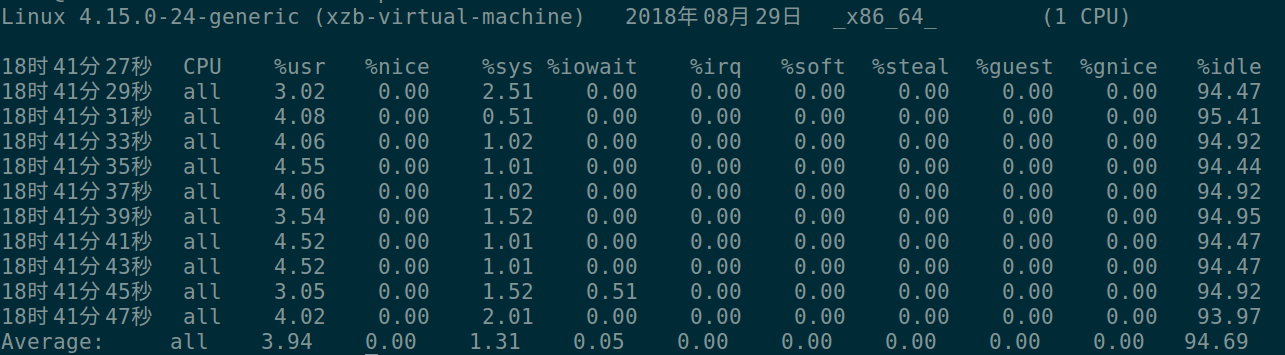
mpstat 2 10 --查看每个CPU的使用统计。
总线设备信息统计:
lspci --显示系统中所有PCI总线设备或连接到该总线的所有设备

使用dmidcode命令查看bios、system、memory、processor等硬件设备的信息
例:dmidecode -t Memory | grep "Maximum Capacity"
查看网卡信息:
ethtool 网卡名
ethtool -i ens33
I/O性能统计
iostat -kx 2
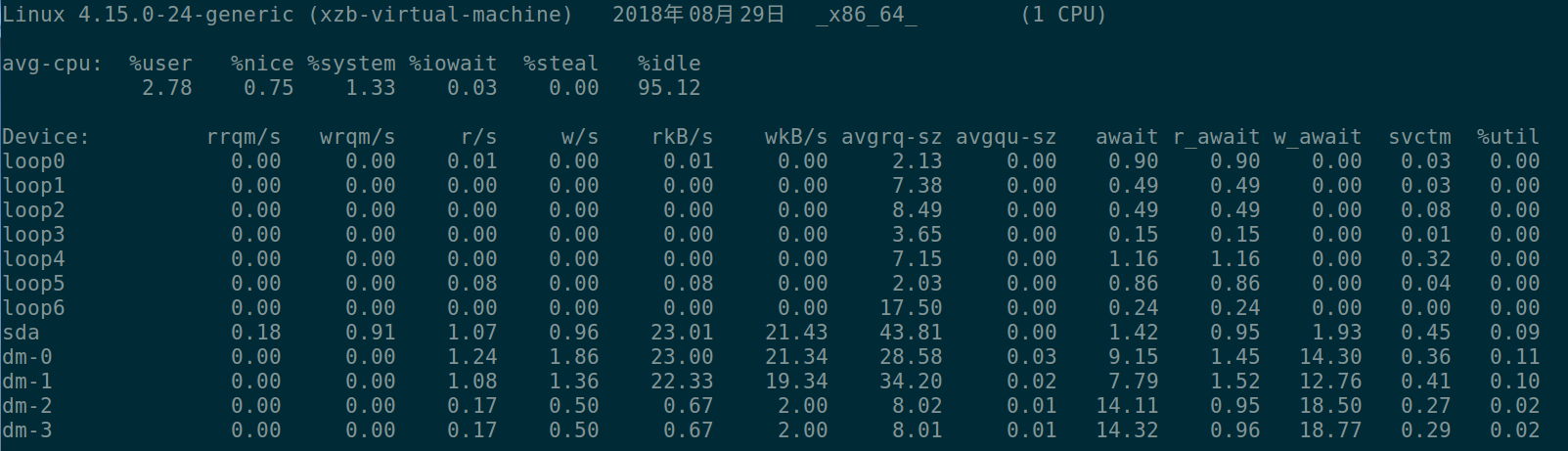
vmstat 2 10
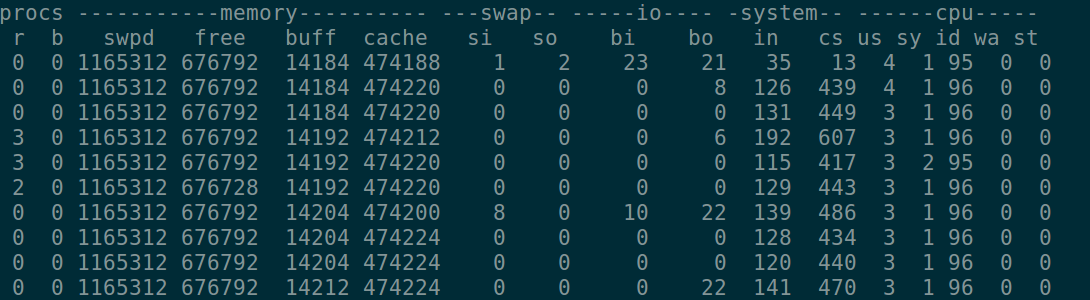
swpd:切换到交换内存上的内存容量(默认以KB为单位),正常情况下swpd的值为0。如果swpd的值比较大,如果查过100M,但是si和so的值长期为0,则这种情况不会影响性能。
free:空闲的物理内存容量。如果free的值很小,但是si和so的值也很小,则系统性能不会受到影响。
buff:做为buffer cache(缓冲区缓存)的内存,对块设备的读写进行缓冲。
cache:做为page cache(页面缓存)的内存,文件系统的缓存,如果缓存值大,则说明缓存的文件数多,如果频繁访问到的文件都能被缓存,name磁盘的读io bi(发送到块设备的块数)会非常小。
si:交换内存使用,由磁盘调入内存。
so:交换内存使用,有内存调入磁盘。
提示:内存够用时,si和so的值都是0,;如果这两个值长期大于0,那么系统性能就会收到影响,磁盘、I/O和CPU资源都会被消耗完。
bi:从块设备读入的数据量(读磁盘),单位为KB/s。
bo:写入到块设备的数据总量(写磁盘),单位为KB/s。
提示:随机磁盘读写的时候,这2个值越大(如超出1M),能看到CPU在I/O等待的值也会越大。
in:每秒产生的终端次数。
cs:每秒产生的上下文切换次数。
提示:in和cs的值越大,有内核消耗的CPU时间会越多。
us:用户进程消耗的CPU时间百分比。如果us的值比较高,则说明用户进程消耗的CPU时间多。但是如果长期超过50%,那么就考虑优化程序算法或者进行加速。
sy:内核进程所消耗的CPU时间百分比。如果sy的值比较高,说明系统内核消耗的CPU资源多,这并不是良性的表现,应该检查原因。
id:CPU处于空闲状态时间的百分比。
wa:I/O等待消耗的CPU时间百分比。如果wa的值比较高,则说明I/O等待比较严重,这可能是磁盘大量做随机访问造成的,也有可能是磁盘的带宽出现瓶颈,如快操作等。
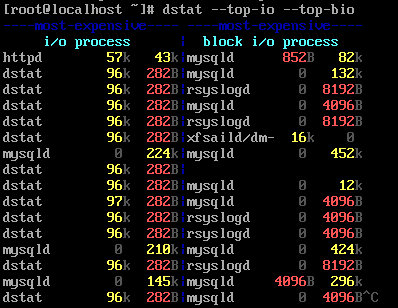
查看当前占用I/O资源最高的进程信息,如下图所示:
dstat --top-bio --top-io
磁盘使用率统计:
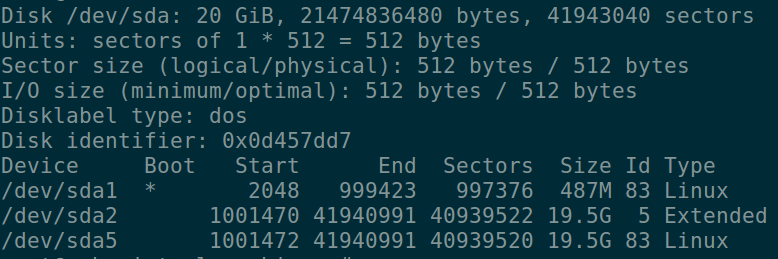
df -h --查看磁盘容量使用情况(检查删除文件后磁盘空间有未释放)
fdisk -l --查看磁盘分区信息
磁盘I/O相关参考:https://www.cnblogs.com/hanson1/p/7102206.html
lsof命令可以列出当前系统打开的文件及目录,其中提供了大量关于这个应用程序本身和操作系统交互的信息。+D参数可以列出对应目录下的所有子目录和文件。
操作系统日志:
查看整体系统日志:/var/log/messages
查看授权和认证信息:/var/log/secure
以上两个日志中需关注:
1)错误和告警信息,是否因为连接数过多所导致的;
2)是否有硬件错误或文件系统错误。
中断异常信息:
/proc/interrupts中中断请求是否均衡分配给了CPU处理,CPU是否会由于大量网络中断请求或RAID请求而过载。
内核信息查询:
dmesg | more

 浙公网安备 33010602011771号
浙公网安备 33010602011771号