
[转载]如何清晰的理解算法中的时间复杂度?
链接:https://www.zhihu.com/question/20196775/answer/154922935
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
算法时间复杂度用来度量算法执行时间的多少,用大O阶表示,即T(n)=O(f(n)),其中n为问题规模,也就是问题的大小。
既然要理解时间复杂度,我们首先理解术语中的两个关键词——“算法”和“时间”,理解了它俩就成功一半了。
首先看“算法”,算法是解决特定问题的方法,在计算机领域里需要将算法用计算机能听懂的语言描述给它听,明白之后它才能使用运算能力解决问题。计算机能听懂的语言,当然是程序代码了(还需编译器将代码翻译成2进制流),也就是一系列的指令。
再看“时间”,此处的时间指执行算法消耗的时间,也就是计算机执行前面所说的一系列指令的时间。这个时间受
- 计算机执行每条指令的速度->硬件层面
- 编译产生的代码质量->软件层面
- 算法的好坏(算法使用的策略)
- 问题规模
的影响。在给定软硬件环境下,其实就是你在自己电脑上写算法的时候,算法执行时间只受算法本身的好坏和要处理的问题的规模影响。这样就将4个影响因素减少为2个,简化了问题。
既然执行时间受算法好坏和问题规模n的影响,那么执行时间就是它俩的函数。
那这个函数到是啥样的呢?
我们继续分析,给定问题规模n之后,优秀的算法可能哐哐哐执行几次就搞定了,一般的算法可能吭哧吭哧执行很多很多次才搞定;当给定算法时,问题规模n很小时,可能执行几次就搞定,而n很大时,就得执行很多次了。所以算法优劣和问题规模n改变时,执行次数(基本操作数)将改变,所以执行次数就是算法优劣和问题规模n的函数。
到此为止,我们得出一个简单的结论:算法执行时间可以用执行次数表示。
世界丰富多彩,同一个问题有不同的解决办法,比如饿了,可以吃米粉也可以吃包子,可以一个人吃也可以一个人吃(hh)。对应算法领域,同一个问题也可以用不同的算法解决,既然这样,那不同的算法之间肯定有优劣之分,如何评价呢?
最简单的评价方法是把两个算法拉过来比谁解决问题的速度快,谁的执行时间短,谁的执行次数少。
给定算法时,执行次数变为问题规模n的函数。比如一个算法是a,一个算法是b,问题规模为n,那么执行次数分别为Ca=f(n),Cb=g(n)。现在将比较两个算法的执行次数的问题转换为比较两个函数f(n),g(n)的问题。那比较两个函数的什么性质呢?当然是比较随着问题规模n增大,执行次数的增加情况,也就是f(n),g(n)的增长情况。好比让两个人吃一百个包子,一个人一小时吃完,一个人一分钟吃完,明显一分钟吃完的那个人能力强,效率高,吃法(算法)更先进(hh)。
要比较两个函数的增长情况,最好的办法是比较函数的一阶导,这样最精确,但是考虑到很多时候只需要大体了解算法的优劣就可以了,所以我们就直接考察对增长速度影响最大的一项,这一项就是函数的最高阶数。为了说明最高阶数对函数增长影响最明显,我们看两幅图。
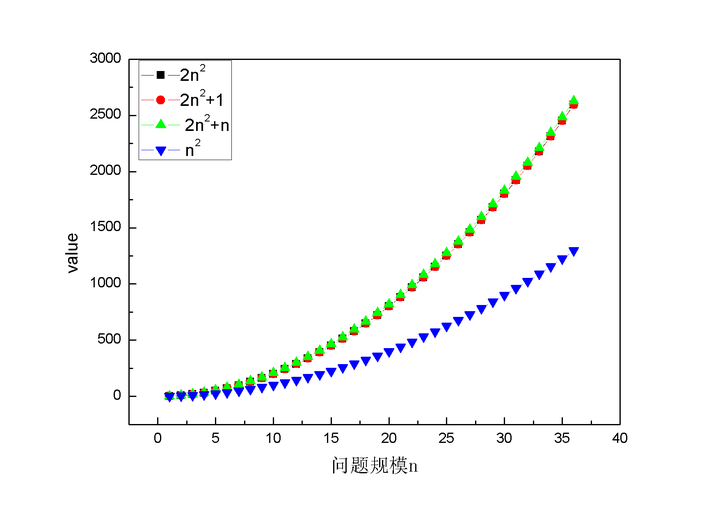
图中4条曲线分别表示4种不同的执行次数表达式,从图中可以看出,只要最高项的阶数相同,4种表达式值受其他项的影响很小,随着n增大,几乎可以忽略不计,甚至可以忽略与最高项相乘的常数。
既然可以只考虑最高项的阶数,以简化问题,达到估算的目的,为何不这样做呢?
那总得给这种情况一个恰当的表示方式吧?和其他领域一样,还得用符号来表示,这个符号就是大名鼎鼎的大O。
T(n)=O(f(n))
其中,T(n)就是算法的时间复杂度;
f(n)表示执行与算法优劣和问题规模有关的执行数;
O()表示一种运算符号,和+-*/类似。作用就是去除其他项,包括与最高项相乘的常数,只保留最高项,比如f(n)=2n^2+1,O(f(n))=O(n^2)
好了,我们已经推导出了时间复杂度的大O表示,应该对算法时间复杂度有个不错的认识了吧。
最后回顾一下推导过程:
算法执行时间->4种因素影响->去除软硬件因素,考虑算法优劣和问题规模n两种因素->算法执行次数->简化:忽略其他项->大O表示法表示算法时间复杂度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号