
SVM学习总结(一)
前言:
在学习机器学习的过程中,我一直有总结的习惯,只不过是局限于纸张层面的,有利于平时拿过来就能看,还有一个原因是:写博客时,手敲公式实在太麻烦。不过,前几天偶然发现一个写公式的神器(Mathpix Snipping Tool),终于有动力把笔记整理出来。
这篇写SVM的原因是,我对SVM一直理解不太透彻,借助这次机会我又查了一些资料,希望这次完全解释清楚,错误之处欢迎指正,我会尽快修正。
本章节内容主要参考于七月在线机器学习视频课程,七月在线题库,七月在线陈老师课件,以及李航统计学习方法 。
1.如何理解分类
分类的本质就是寻找决策边界,SVM的目的就是找到一个决策边界,分开正负样本,并且样本点到边界的距离越远越好。
我们可以先用Logistic回归来理解。
给定训练数据集,如果用x表示数据点,用y表示类别(y可以取1或者0,分别代表两个不同的类),Logistic回归中就是找到一个决策边界$$\theta^{T} x=0$$,带入x后,得到自由变量,由于自变量的取值范围是负无穷到正无穷。因此,使用logistic函数(或称作sigmoid函数)将自变量映射到(0,1)上:
其中x是n维特征向量,函数g就是logistic函数。
从而,当我们要判别一个新来的特征属于哪个类时,只需求即可,若大于0.5就是y=1的类,反之属于y=0类。
然后,我们对logistic回归做个变形。首先,将使用的结果标签y = 0和y = 1替换为y = -1,y = 1,然后将
(\(\theta^{T} x=\theta_{0}+\theta_{1} x_{1}+\theta_{2} x_{2}+\cdots+\theta_{n} x_{n}\))中的\(\theta_{0}\)替换为b,最后将后面的(\(\theta_{1} x_{1}+\theta_{2} x_{2}+\dots+\theta_{n} x_{n}\))替换为(\(\theta_{1} x_{1}+\theta_{2} x_{2}+\dots+\theta_{n} x_{n}\))(即\(w^{T} x\)),这样就有了\(\theta^{T} x=w^{T} x+b\),这里其实就是决策边界的另一种表达方式。带入到变换中,得到的公式:\(h_{w, b}(\mathrm{x})=g\left(w^{T} x+\mathrm{b}\right)\),将其映射到y上,如下:
2.另一种分类
在SVM中,边界函数就是\(f(x)=w^{T} x+b\)。表示,当f(x) 等于0的时候,x便是位于超平面上的点,而f(x)大于0的点对应 y=1 的数据点,f(x)小于0的点对应y=-1的点。
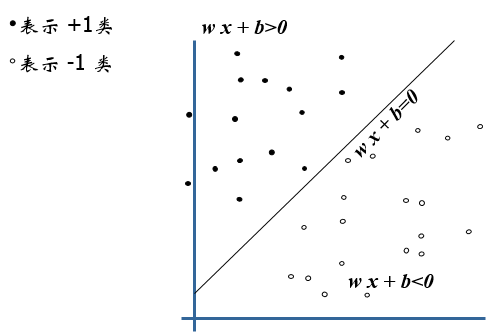
在进行分类的时候,遇到一个新的数据点x,将x代入f(x) 中,如果f(x)小于0则将x的类别赋为0,如果f(x)大于0则将x的类别赋为1。
线性可分支持向量机(硬间隔支持向量机):给定线性可分训练数据集,通过间隔最大化或等价地求解相应地凸二次规划问题学习得到分离超平面为\(f(x)=w^{T} x+b\)
以及相应的分类决策函数
称为线型可分支持向量机。
3.函数间隔和几何间隔
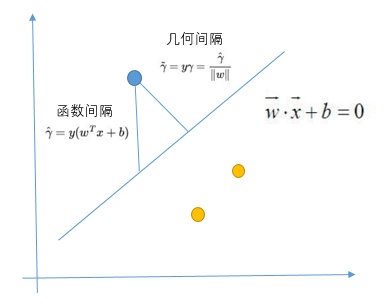
在超平面wx+b=0确定的情况下,\(\left|\mathrm{w}^{\star} x+b\right|\)能够表示点x到距离超平面的远近,而通过观察wx+b的符号与类标记y的符号是否一致可判断分类是否正确,所以,可以用\(\left(y^{*}\left(w^{\star} x+b\right)\right)\)的正负性来判定或表示分类的正确性。
于此,便引出了函数间隔的概念。
函数间隔用\(\hat{\gamma}\)表示,超平面关于样本点的函数间隔为:
超平面(w,b)关于T中所有样本点(xi,yi)的函数间隔最小值(其中,x是特征,y是结果标签,i表示第i个样本),便为超平面(w, b)关于训练数据集T的函数间隔:
即超平面关于训练集𝑇中所有样本点的函数间隔的最小值。
超平面关于样本点的几何间隔为:
超平面关于训练集\(T\)的几何间隔:
即超平面关于训练集\(T\)中所有样本点的几何间隔的最小值。
下面介绍一下几何间隔是怎么来的:
由于这样定义的函数间隔有问题,即如果成比例的改变w和b(如将它们改成2w和2b),则函数间隔的值f(x)却变成了原来的2倍(虽然此时超平面没有改变),所以只有函数间隔还远远不够。
我们可以对法向量w加些约束条件,从而引出真正定义点到超平面的距离--几何间隔(geometrical margin)的概念。
假定对于一个点\(x\) ,令其垂直投影到超平面上的对应点为 \(x_{0}\),\(w\)是垂直于超平面的一个向量,\(\gamma\)为样本\(x\)到超平面的距离,

根据平面几何知识,有
其中\(\frac{w}{\|w\|}\)是单位向量。
又由于\(\boldsymbol{w}^{T} \boldsymbol{x}+\boldsymbol{b}=0\) 是超平面上的点,代入超平面的方程\(w^{T} x_{0}+b=0\),可得\(w^{T} x_{0}+b=0\),即\(w^{T} x_{0}=-b\)。
随即让此式\(x=x_{0}+\gamma \frac{w}{\|w\|}\)的两边同时乘以\(w^{T}\),再根据\(w^{T} x_{0}=-b\)和\(w^{T} w=\|w\|^{2}\),即可算出γ:
为了得到的\(\gamma\)绝对值,令\(\gamma\)乘上对应的类别 y,即可得出几何间隔(用\(\tilde{\gamma}\)表示)的定义:
几何间隔就是函数间隔除以$$||w||$$,而且函数间隔y(wx+b) = yf(x)实际上就是\(|f(x)|\),只是人为定义的一个间隔度量,而几何间隔\(|f(x)|/||w||\)才是直观上的点到超平面的距离。
4.最大间隔分类器
对一个数据点进行分类,当超平面离数据点的“间隔”越大,分类的确信度(confidence)也越大。所以,为了使得分类的确信度尽量高,需要让所选择的超平面能够最大化这个“间隔”值。这个间隔就是下图中的Gap的一半。
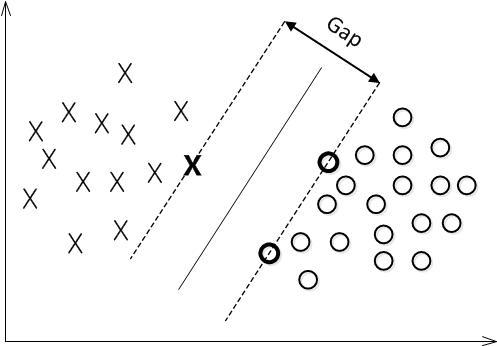
函数间隔不适合用来最大化间隔值,因为在超平面固定以后,可以等比例地缩放w的长度和b的值,这样可以使得\(f(x)=w^{T} x+b\)的值任意大,就是说函数间隔\(\hat{\gamma}\)可以在超平面保持不变的情况下被取得任意大。但几何间隔因为除上了\(\|w\|\),使得在缩放w和b的时候几何间隔的值\(\tilde{\gamma}\)是不会改变的,它只随着超平面的变动而变动,因此,这是更加合适的一个间隔。换言之,这里要找的最大间隔分类超平面中的“间隔”指的是几何间隔。
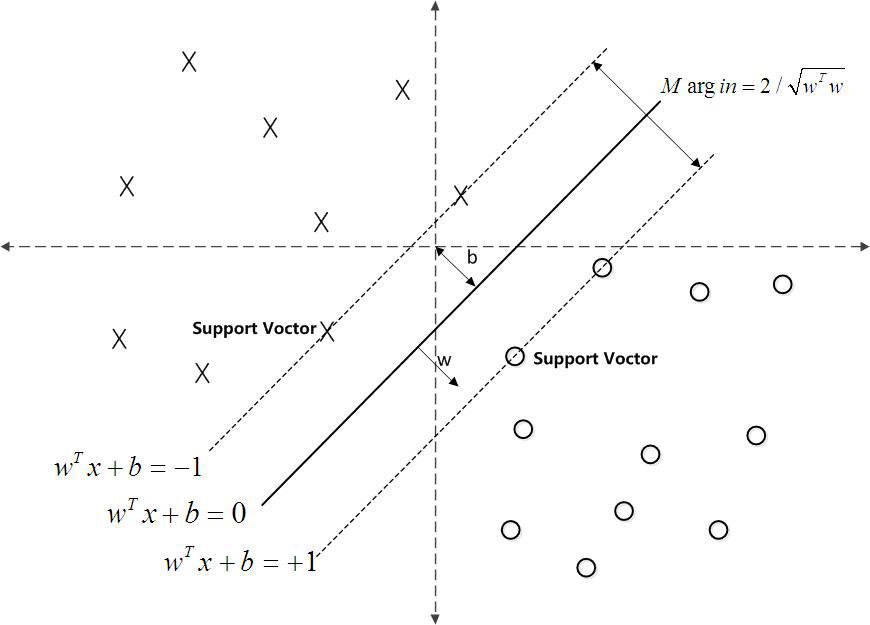
(硬间隔)支持向量:训练数据集的样本点中与分离超平面距离最近的样本点的实例,即使约束条件等号成立的样本点
对\(y_{i} = +1\)的正例点,支持向量在超平面
对\(y_{i} = -1\)的正例点,支持向量在超平面
\(H_{1}\)和\(H_{2}\)称为间隔边界。
\(H_{1}\)和\(H_{2}\)之间的距离称为间隔,且\(|H_{1}H_{2}| = \dfrac{1}{\| w \|} + \dfrac{1}{\| w \|} = \dfrac{2}{\| w \|}\)。
最大间隔分离超平面等价为求解
回顾下几何间隔的定义\(\tilde{\gamma}=y \gamma=\frac{\hat{\gamma}}{\|w\|}\),可知:如果令函数间隔\(\hat{\gamma}\)等于1(这里的\(\hat{\gamma}\)指的是关于训练数据集T的函数间隔\(min\hat{\gamma}_i=1\),之所以令\(\hat{\gamma}\)等于1,是为了方便推导和优化,且这样做对目标函数的优化没有影响),则有几何间隔\(\tilde{\gamma}=1 /\|w\|\)。
从而上述目标函数转化成了\(y_{i}\left(w^{T} x_{i}+b\right) \geq 1, i=1, \dots, n\)
等价的,最大间隔分离超平面转换为:
等价的
如下图所示,中间的实线便是寻找到的最优超平面(Optimal Hyper Plane),其到两条虚线边界的距离相等,这个距离便是几何间隔,两条虚线间隔边界之间的距离等于2,而虚线间隔边界上的点则是支持向量。由于这些支持向量刚好在虚线间隔边界上,所以它们满足\(y\left(w^{T} x+b\right)=1\) ,上节中:为了方便推导和优化的目的,我们可以令\(min\hat{\gamma}_i=1\),而对于所有不是支持向量的点,则显然有\(y\left(w^{T} x+b\right)>1\)。
5.SVM求解思路:
线性可分支持向量机学习算法(最大间隔法):
输入:线性可分训练数据集\(T = \left\{ \left( x_{1}, y_{1} \right), \left( x_{2}, y_{2} \right), \cdots, \left( x_{N}, y_{N} \right) \right\}\),其中\(x_{i} \in \mathcal{X} = R^{n}, y_{i} \in \mathcal{Y} = \left\{ +1, -1 \right\}, i = 1, 2, \cdots, N\)
输出:最大间隔分离超平面和分类决策函数
-
构建并求解约束最优化问题
\[\begin{align*} \\ & \min_{w,b} \quad \dfrac{1}{2} \| w \|^{2} \\ & s.t. \quad y_{i} \left( w \cdot x_{i} + b \right) -1 \geq 0, \quad i=1,2, \cdots, N \end{align*} \]求得最优解\(w^{*}, b^{*}\)。
-
得到分离超平面
\[\begin{align*} \\ & w^{*} \cdot x + b^{*} = 0 \end{align*} \]
以及分类决策函数
\[\begin{align*} \\& f \left( x \right) = sign \left( w^{*} \cdot x + b^{*} \right) \end{align*} \]
6.解SVM
对于目标函数:
因为现在的目标函数是二次的,约束条件是线性的,所以它是一个凸二次规划问题****。这个问题可以用现成的QP (Quadratic Programming) 优化包进行求解。一言以蔽之:在一定的约束条件下,目标最优,损失最小**。
由于这个问题的特殊结构,还可以通过拉格朗日对偶性(Lagrange Duality)变换到对偶变量 (dual variable) 的优化问题,即通过求解与原问题等价的对偶问题(dual problem)得到原始问题的最优解,这就是线性可分条件下支持向量机的对偶算法,这样做的优点在于:一者对偶问题往往更容易求解;二者可以自然的引入核函数,进而推广到非线性分类问题。
那什么是拉格朗日对偶性呢?简单来讲,通过给每一个约束条件加上一个拉格朗日乘子(Lagrange multiplier),定义拉格朗日函数(通过拉格朗日函数将约束条件融合到目标函数里去,从而只用一个函数表达式便能清楚的表达出我们的问题):
最优化问题的求解:
-
引入拉格朗日乘子\(\alpha_{i} \geq 0, i = 1, 2, \cdots, N\)构建拉格朗日函数
\[\begin{align*} \\ & L \left( w, b, \alpha \right) = \dfrac{1}{2} \| w \|^{2} + \sum_{i=1}^{N} \alpha_{i} \left[- y_{i} \left( w \cdot x_{i} + b \right) + 1 \right] \\ & = \dfrac{1}{2} \| w \|^{2} - \sum_{i=1}^{N} \alpha_{i} y_{i} \left( w \cdot x_{i} + b \right) + \sum_{i=1}^{N} \alpha_{i} \end{align*} \]
其中,\(\alpha = \left( \alpha_{1}, \alpha_{2}, \cdots, \alpha_{N} \right)^{T}\)为拉格朗日乘子向量。
-
求\(\min_{w,b}L \left( w, b, \alpha \right)\):
\[\begin{align*} \\ & \nabla _{w} L \left( w, b, \alpha \right) = w - \sum_{i=1}^{N} \alpha_{i} y_{i} x_{i} = 0 \\ & \nabla _{b} L \left( w, b, \alpha \right) = -\sum_{i=1}^{N} \alpha_{i} y_{i} = 0 \end{align*} \]
得
\[\begin{align*} \\ & w = \sum_{i=1}^{N} \alpha_{i} y_{i} x_{i} \\ & \sum_{i=1}^{N} \alpha_{i} y_{i} = 0 \end{align*} \]
代入拉格朗日函数,得
\[\begin{align*} \\ & L \left( w, b, \alpha \right) = \dfrac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j} \left( x_{i} \cdot x_{j} \right) - \sum_{i=1}^{N} \alpha_{i} y_{i} \left[ \left( \sum_{j=1}^{N} \alpha_{j} y_{j} x_{j} \right) \cdot x_{i} + b \right] + \sum_{i=1}^{N} \alpha_{i} \\ & = - \dfrac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j} \left( x_{i} \cdot x_{j} \right) - \sum_{i=1}^{N} \alpha_{i} y_{i} b + \sum_{i=1}^{N} \alpha_{i} \\ & = - \dfrac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j} \left( x_{i} \cdot x_{j} \right) + \sum_{i=1}^{N} \alpha_{i} \end{align*} \]即
\[\begin{align*} \\ & \min_{w,b}L \left( w, b, \alpha \right) = - \dfrac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j} \left( x_{i} \cdot x_{j} \right) + \sum_{i=1}^{N} \alpha_{i} \end{align*} \]
3.求\(\max_{\alpha} \min_{w,b}L \left( w, b, \alpha \right)\):
\[\begin{align*} \\ & \max_{\alpha} - \dfrac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j} \left( x_{i} \cdot x_{j} \right) + \sum_{i=1}^{N} \alpha_{i} \\ & s.t. \sum_{i=1}^{N} \alpha_{i} y_{i} = 0 \\ & \alpha_{i} \geq 0, \quad i=1,2, \cdots, N \end{align*} \]
等价的
\[\begin{align*} \\ & \min_{\alpha} \dfrac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j} \left( x_{i} \cdot x_{j} \right) - \sum_{i=1}^{N} \alpha_{i} \\ & s.t. \sum_{i=1}^{N} \alpha_{i} y_{i} = 0 \\ & \alpha_{i} \geq 0, \quad i=1,2, \cdots, N \end{align*} \]
线性可分支持向量机(硬间隔支持向量机)学习算法:
输入:线性可分训练数据集\(T = \left\{ \left( x_{1}, y_{1} \right), \left( x_{2}, y_{2} \right), \cdots, \left( x_{N}, y_{N} \right) \right\}\),其中\(x_{i} \in \mathcal{X} = R^{n}, y_{i} \in \mathcal{Y} = \left\{ +1, -1 \right\}, i = 1, 2, \cdots, N\)
输出:最大间隔分离超平面和分类决策函数
-
构建并求解约束最优化问题
\[\begin{align*} \\ & \min_{\alpha} \dfrac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j} \left( x_{i} \cdot x_{j} \right) - \sum_{i=1}^{N} \alpha_{i} \\ & s.t. \sum_{i=1}^{N} \alpha_{i} y_{i} = 0 \\ & \alpha_{i} \geq 0, \quad i=1,2, \cdots, N \end{align*} \]
求得最优解$\alpha^{} = \left( \alpha_{1}^{}, \alpha_{1}^{}, \cdots, \alpha_{N}^{} \right) $。
-
计算
\[\begin{align*} \\ & w^{*} = \sum_{i=1}^{N} \alpha_{i}^{*} y_{i} x_{i} \end{align*} \]
并选择\(\alpha^{*}\)的一个正分量\(\alpha_{j}^{*} > 0\),计算
\[\begin{align*} \\ & b^{*} = y_{j} - \sum_{i=1}^{N} \alpha_{i}^{*} y_{i} \left( x_{i} \cdot x_{j} \right) \end{align*} \]
-
得到分离超平面
\[\begin{align*} \\ & w^{*} \cdot x + b^{*} = 0 \end{align*} \]以及分类决策函数
\[\begin{align*} \\& f \left( x \right) = sign \left( w^{*} \cdot x + b^{*} \right) \end{align*} \]
-
7.线性支持向量机(软间隔支持向量机)
以上分析的是硬间隔支持向量机,在间隔空间中没有样本,样本集是线性可分的。但如果给定线性不可分训练数据集,则需要增加松弛因子,再通过求解凸二次规划问题 ,得到分离超平面。
学习得到分离超平面为
以及相应的分类决策函数
称为线型支持向量机。
8.核函数
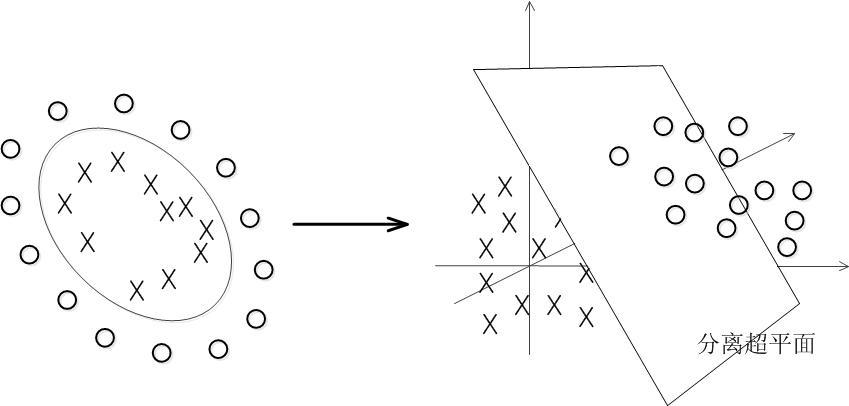
大部分时候数据并不是线性可分的,这个时候满足这样条件的超平面就根本不存在。在上文中,我们已经了解到了SVM处理线性可分的情况,那对于非线性的数据SVM咋处理呢?对于非线性的情况,SVM 的处理方法是选择一个核函数 κ(⋅,⋅) ,通过将数据映射到高维空间,来解决在原始空间中线性不可分的问题 。
具体来说,在线性不可分的情况下,支持向量机首先在低维空间中完成计算,然后通过核函数将输入空间映射到高维特征空间,最终在高维特征空间中构造出最优分离超平面,从而把平面上本身不好分的非线性数据分开。如图所示,一堆数据在二维空间无法划分,从而映射到三维空间里划分:
常用核函数:
-
多项式核函数
\[\begin{align*} \\& K \left( x, z \right) = \left( x \cdot z + 1 \right)^{p} \end{align*} \] -
高斯核函数
\[\begin{align*} \\& K \left( x, z \right) = \exp \left( - \dfrac{\| x - z \|^{2}}{2 \sigma^{2}} \right) \end{align*} \]
非线性支持向量机:从非线性分类训练集,通过核函数与软间隔最大化,学习得到分类决策函数
称为非线性支持向量机,\(K \left( x, z \right)\)是正定核函数。


