Protobuf剖析
简介
Google Protocol Buffer( 简称 Protobuf) 是 Google 公司内部的混合语言数据标准,目前已经正在使用的有超过 48,162 种报文格式定义和超过 12,183 个 .proto 文件。他们用于 RPC 系统和持续数据存储系统。(注:RPC(Remote Procedure Call)是一种基于网络的远程调用技术,它可以让不同的计算机之间通过网络进行通信,从而实现分布式系统的构建。RPC 的基本原理是将本地方法调用转换为远程方法调用。通过序列化和网络传输,将客户端的请求参数传递给远程服务端,服务端处理完请求后将处理结果序列化并返回给客户端,客户端再将结果反序列化为本地对象。RPC详解:https://blog.csdn.net/lonely_baby/article/details/129133785)
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化、或者说序列化。它很适合做数据存储或RPC数据交换格式。可以用于即时通讯、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
使用
在解析消息时,如果已编码的消息不包含特定的奇异元素,则解析对象中相应的字段将被设置为该字段的默认值。这些默认值是特定类型的:
- 对于字符串,默认值是空字符串。
- 对于bytes,默认值为空bytes。
- 对于bool类型,默认值为false。
- 对于数值类型,默认值为零。
- 对于枚举,默认值是第一个定义的枚举值,它必须为0。
编码
编码结构:TLV格式(Tag-Length-Value)
Tag 作为该字段的唯一标识,Length 代表 Value 数据域的长度,最后的 Value 便是数据本身。
每一个 message 进行编码,其结果由一个个字段组成,每个字段可划分为 Tag - [Length] - Value,如下图所示:
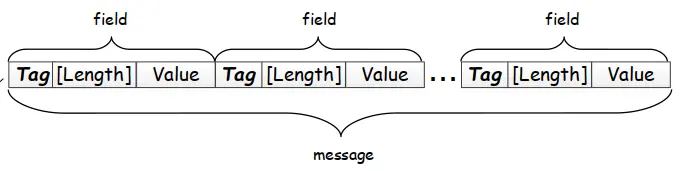
(注: [Length] 是可选的,含义是针对不同类型的数据编码结构可能会变成 Tag - Value 的形式,如果变成这样的形式,直接采用 Varint 编码。)
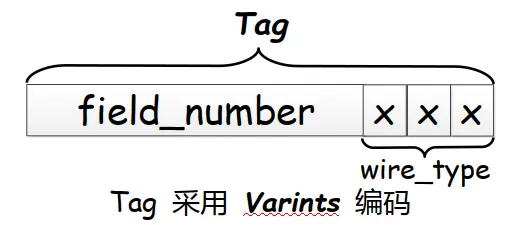
Tag ,Tag 由 field_number 和 wire_type 两个部分组成:
- field_number: message 定义字段时指定的字段编号
- wire_type: ProtoBuf 编码类型,根据这个类型选择不同的 Value 编码方案。
![]()
ProtoBuf 已经定义了 6 种编码类型(注:Start group 和 End group已弃用)
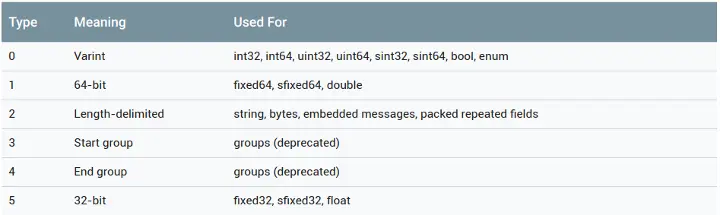
| proto文件消息类型 | C#类型 | 说明 |
|---|---|---|
| double | double | 双精度浮点型 |
| float | float | 单精度浮点型 |
| int32 | int32 | 使用可变长编码方式,负数时不够高效,应该使用sint32 |
| int64 | int64 | 使用可变长编码方式,负数时不够高效,应该使用sint32 |
| uint32 | uint32 | 使用可变长编码方式 |
| uint64 | uint64 | 使用可变长编码方式 |
| sint32 | int32 | 使用可变长编码方式,有符号的整型值,负数编码时比通常的int32高效 |
| sint64 | int64 | 使用可变长编码方式,有符号的整型值,负数编码时比通常的int64 |
| fixed32 | int32 | 总是4个字节,如果数值总是比2^28大的话,这个类型会比uint32高效 |
| fixed64 | int64 | 总是8个字节,如果数值总是比2^56大的话,这个类型会比uint64高效 |
| sfixed32 | int32 | 总是4个字节 |
| sfixed64 | int64 | 总是8个字节 |
| bool | bool | 布尔类型 |
| string | string | 一个字符串必须是utf-8编码或者7-bit的ascii编码的文本 |
| bytes | byte[] | 可能包含任意顺序的字节数据 |
varint编码后数据的字节是按照小端序排列的。
Varints 编码:
规则主要为以下三点:
- 在每个字节开头的 bit 设置了 msb(most significant bit ),标识是否需要继续读取下一个字节
- 存储数字对应的二进制补码
- 补码的低位排在前面
(知识点1:
原码:十进制数据的二进制表现形式就是原码,原码最左边的一个数字就是符号位,0为正,1为负。
补码:正数的补码是其本身,负数的补码等于其反码 +1。
反码:正数的反码是其本身(等于原码),负数的反码是符号位保持不变,其余位取反。)
(知识点2:字节的排列方式有两个通用规则:
大端序(Big-Endian)将数据的低位字节存放在内存的高位地址,高位字节存放在低位地址。这种排列方式与数据用字节表示时的书写顺序一致,符合人类的阅读习惯。
小端序(Little-Endian),将一个多位数的低位放在较小的地址处,高位放在较大的地址处,则称小端序。小端序与人类的阅读习惯相反,但更符合计算机读取内存的方式,因为CPU读取内存中的数据时,是从低地址向高地址方向进行读取的。)
Varints 编码对负数编码效率低,因为负数总是占用最高位标识正负,所以先使用ZigZag编码再用Varints编码(ZigZag 编码:有符号整数映射到无符号整数,然后再使用 Varints 编码)
例:一个message中去设置666
首先 message结构:
syntax = "proto3";
message SetIntValue{
int32 value = 1;
}
import "XXX.proto"
调用接口对程序赋值
SetIntValue setExample;
setExample.set_int32(value);
value = 666 编码结果:00001 000 0x08 10011010 00000101 0x9a 0x05
格式:tag-00001 000 + value-1(msb)0011010 0(msb)0000101 = 0x08 0x9a 0x05
value = -1 编码结果: 0x08 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0x01
格式:tag-00001 000 + value-1(msb)1111111...0(msb)0000001
注:当编码值为空时会自动读取默认值
在 protobuf 中,我们也可以定义枚举,并且使用该枚举类型:
// message 定义
message Example1 {
enum COLOR {
YELLOW = 0;
RED = 1;
BLACK = 2;
WHITE = 3;
BLUE = 4;
}
// 枚举常量必须在 32 位整型值的范围
// 使用 Varints 编码,对负数不够高效,因此不推荐在枚举中使用负数
COLOR colorVal = 1;
}
Length-delimited 类型
Length-delimited 类型的编码结构为 Tag - Length - Value
// message 定义
message Example1 {
string stringVal = 1;
bytes bytesVal = 2;
message EmbeddedMessage {
int32 int32Val = 1;
string stringVal = 2;
}
EmbeddedMessage embeddedExample1 = 3;
repeated int32 repeatedInt32Val = 4;
repeated string repeatedStringVal = 5;
}
example1.set_stringval("hello,world");
example1.set_bytesval("are you ok?");
embeddedExample2->set_int32val(1);
embeddedExample2->set_stringval("embeddedInfo");
example1.set_allocated_embeddedexample1(embeddedExample2);
example1.add_repeatedint32val(2);
example1.add_repeatedint32val(3);
example1.add_repeatedstringval("repeated1");
example1.add_repeatedstringval("repeated2");
编码后:
string : 00001 010 0A 0B 68 65 6C 6C 6F 2C 77 6F 72 6C 64
bytes: 00010 010 12 0B 61 72 65 20 79 6F 75 20 6F 6B 3F
message: 00011010 1A 10 08 01 12 0C 65 6D 62 65 64 64 65 64 49 6E 66 6F
repeted int32: 00100010 22 || 02 02 03
repeted string: 01000010 2A 09 72 65 70 65 61 74 65 64 31 || 2A 09 72 65 70 65 61 74 65 64 32
/// <summary>
///计算varint编码需要多少字节
/// Computes the number of bytes that would be needed to encode a varint.
/// </summary>
public static int ComputeRawVarint32Size(uint value)
{
if ((value & (0xffffffff << 7)) == 0)
{
return 1;
}
if ((value & (0xffffffff << 14)) == 0)
{
return 2;
}
if ((value & (0xffffffff << 21)) == 0)
{
return 3;
}
if ((value & (0xffffffff << 28)) == 0)
{
return 4;
}
return 5;
}
/// <summary>
/// 数据写入
/// Writes a 32 bit value as a varint. The fast route is taken when
/// there's enough buffer space left to whizz through without checking
/// for each byte; otherwise, we resort to calling WriteRawByte each time.
/// </summary>
public static void WriteRawVarint32(ref Span<byte> buffer, ref WriterInternalState state, uint value)
{
// Optimize for the common case of a single byte value
if (value < 128 && state.position < buffer.Length)
{
buffer[state.position++] = (byte)value;
return;
}
// Fast path when capacity is available
while (state.position < buffer.Length)
{
if (value > 127)
{
buffer[state.position++] = (byte)((value & 0x7F) | 0x80);
value >>= 7;
}
else
{
buffer[state.position++] = (byte)value;
return;
}
}
while (value > 127)
{
WriteRawByte(ref buffer, ref state, (byte)((value & 0x7F) | 0x80));
value >>= 7;
}
WriteRawByte(ref buffer, ref state, (byte)value);
}
脚本:WritingPrimitives 各种类型写入
protobuf反射:
反射是一种机制,通过这种机制我们可以知道一个未知类型的类型信息;利用反射机制动态的实例化对象、读写属性、调用方法、构造函数。
原理:获取程序的元信息,使用元信息动态实例化对象;
元信息:即系统自描述信息,用于描述系统本身。举例来讲,即系统有哪些类?类中有哪些字段、哪些方法?字段属于什么类型、方法又有怎样的参数和返回值?
ProtoBuf元信息来源:.proto文件(非.proto文件转换为ProtoBuf Message语法描述的信息)
ProtoBuf实现反射的步骤:
- 提供 .proto (范指 ProtoBuf Message 语法描述的元信息)
- 解析 .proto 构建 FileDescriptor、FieldDescriptor 等,即 .proto 对应的内存模型(对象)
- 之后每创建一个实例,就将其存到相应的实例池中
- 将 Descriptor 和 instance 的映射维护到表中备查
- 通过 Descriptor 可查到相应的 instance,又由于了解 instance 中字段类型(FieldDescriptor),所以知道字段的内存偏移,那么就可以访问或修改字段的值
/* 反射创建实例 */
auto descriptor = google::protobuf::DescriptorPool::generated_pool()->FindMessageTypeByName("Dog");
auto prototype = google::protobuf::MessageFactory::generated_factory()->GetPrototype(descriptor);
auto instance = prototype->New();
/* 反射相关接口 */
auto reflecter = instance.GetReflection();
auto field = descriptor->FindFieldByName("name");
reflecter->SetString(&instance, field, "鸡你太美") ;
// 获取属性的值.
std::cout<<reflecter->GetString(instance , field)<< std::endl ;
return 0 ;
通过 DescriptorPool 的 FindMessageTypeByName 获得了元信息 Descriptor。
DescriptorPool 为元信息池,对外提供了诸如 FindServiceByName、FindMessageTypeByName 等各类接口以便外部查询所需的元信息。当 DescriptorPool 不存在时需要查询的元信息时,将进一步到 DescriptorDatabase 中去查找。
DescriptorDatabase 可从硬编码或磁盘中查询对应名称的 .proto 文件内容,解析后返回查询需要的元信息。
DescriptorPool 相当于缓存了文件的 Descriptor(底层使用 Map),查询时将先到缓存中查询,如果未能找到再进一步到 DB 中(即 DescriptorDatabase)查询,此时可能需要从磁盘中读取文件内容,然后再解析成 Descriptor 返回,这里需要消耗一定的时间。
从上面的描述不难看出,DescriptorPool 和 DescriptorDatabase 通过缓存机制提高了反射运行效率,这是反射工程实现上的一种优化。
反射脚本:DescriptorPool、FileDescriptor
XML、JSON、Protobuf对比
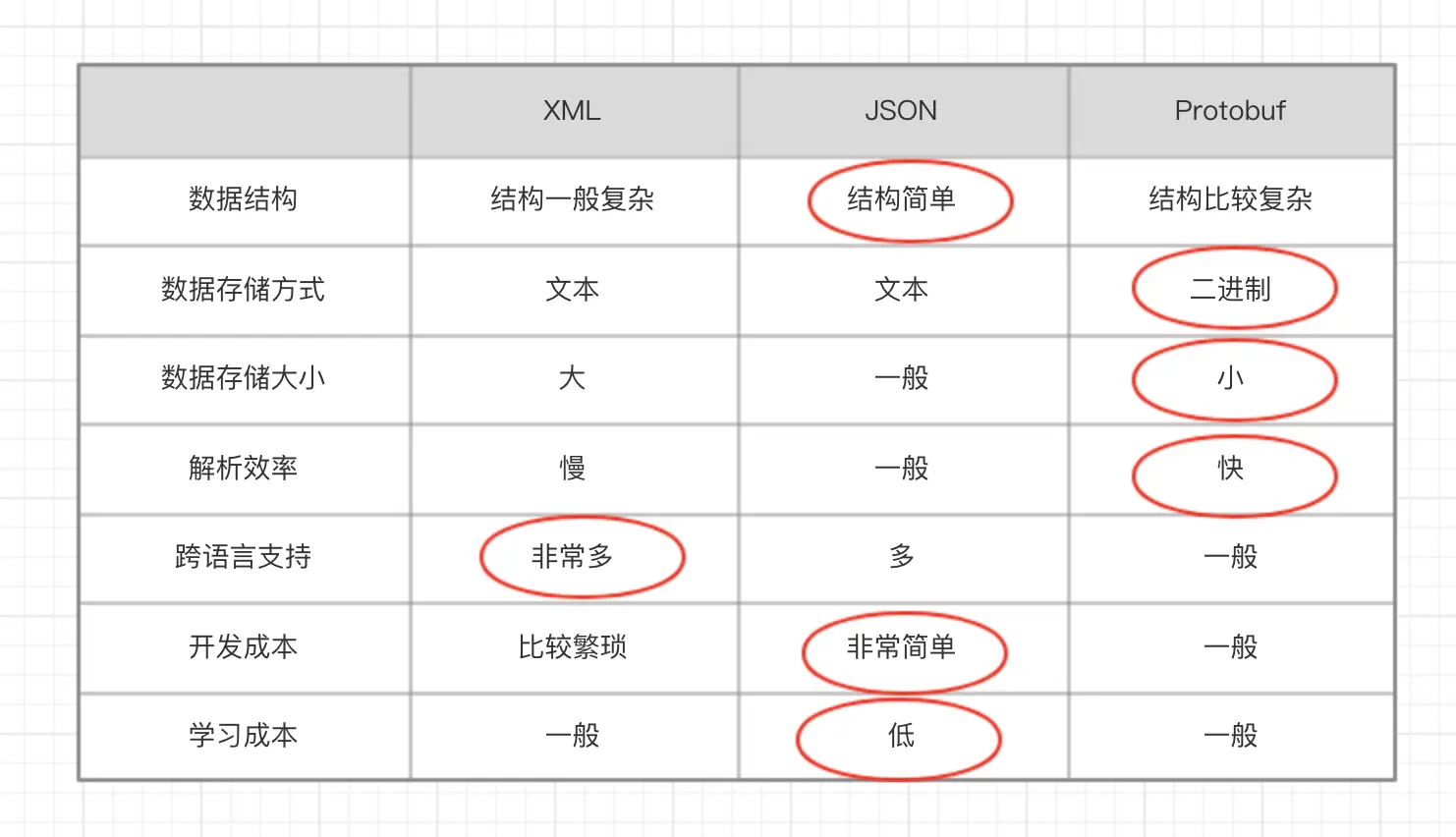
- XML、JSON、Protobuf 都具有数据结构化和数据序列化的能力
- XML、JSON 更注重 数据结构化,关注人类可读性和语义表达能力。Protobuf 更注重 数据序列化,关注效率、空间、速度,人类可读性差,语义表达能力不足
- Protobuf 的应用场景更为明确,XML、JSON 的应用场景更为丰富

 浙公网安备 33010602011771号
浙公网安备 33010602011771号