深分页问题梳理
深分页问题:
limit offset, size 比 limit size 要慢,且offset的值越大,sql的执行速度越慢。
sql内部执行流程:
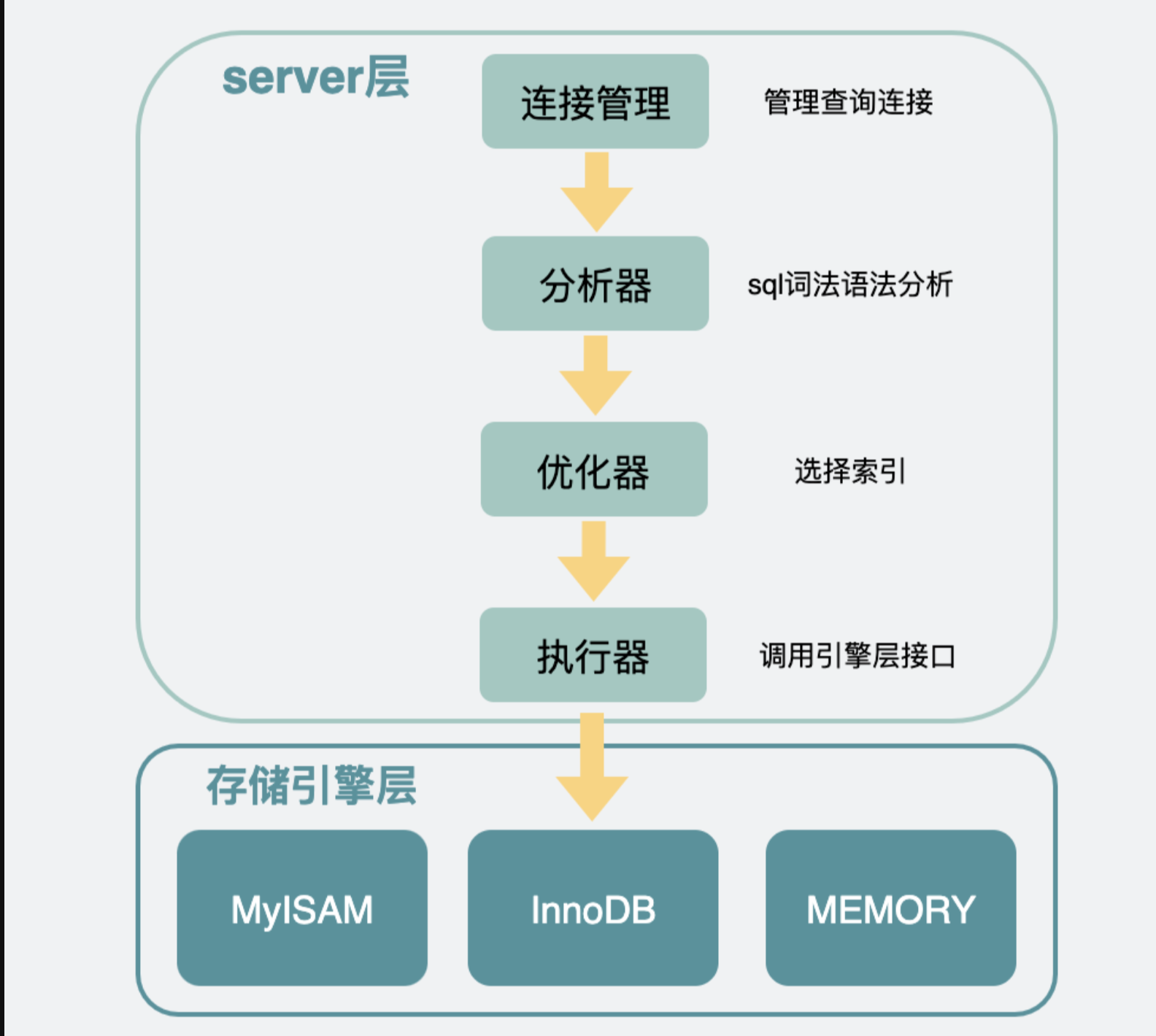
- mysql内部分为server层和存储引擎层。一般情况下存储引擎都用innodb。server层有很多模块,其中需要关注的是执行器是用于跟存储引擎打交道的组件。执行器可以通过调用存储引擎提供的接口,将一行行数据取出,当这些数据完全符合要求(比如满足其它where条件),则会放到结果集中,最后返回给调用mysql的客户端
- limit 是由 server 层过滤的。存储引擎层返回符合条件的所有数据server层会调用innodb的接口,会在innodb里的主键索引中获取到第0到(offset+ size )条完整行数据,返回给server层之后根据offset的值挨个抛弃,最后只留下最后面的size条,条数据,放到server层的结果集中,返回给客户端。可以看出,当offset非0时,server层会从引擎层获取到很多无用的数据,而获取的这些无用数据都是要耗时的。同时,如果走的是非主键索引还多了一个回表的操作,当offset变得非常大时,执行计划中连接类型会变为全表扫描,因为server层的优化器,会在执行器执行sql语句前,判断下哪种执行计划的代价更小。此时回表代价比全表扫描还浪费性能。
深分页问题解决方案:
- 如果主键有序,数据可以根据id主键进行排序,然后分批次取,将当前批次的最大id作为下次筛选的条件进行查询,这个操作,可以通过主键索引,每次定位到id在哪,然后往后遍历size个数据,这样不管是多少万的数据,查询性能都很稳定。此种方式在分页展示界面出现深分页问题时,可以利用这种方法,将页面展示为瀑布流的形式。局限性在于如果数据库中id是无顺序的,那么取出来的这一部分数据(100条)中最大的id作为start_id的话,会引起在数据库中乱取数据的问题
|
|
- 利用子查询,如果id是正序的,可以先查询出 limit 第一个参数offset对应的主键值,再根据这个主键值再去过滤 limit size,(这样可以通过主键索引定位到id在哪,然后往后遍历size个数据)这样效率会更快一些。这种操作,其实也是将在innodb中的主键索引/非主键索引中获取到offset+1条id数据,然后server层会抛弃前offset条,只保留最后一条数据的id。但不同的地方在于,在返回server层的过程中,只会拷贝数据行内的id这一列,而不会拷贝数据行的所有列,当数据量较大时,这部分的耗时还是比较明显的。同时对于非主键索引,通过先查询id的方式可以避免耗时的回表操作,不过,子查询的结果会产生一张新表,会影响性能,实践应该尽量避免大量使用子查询
|
|
- 利用INNER JOIN 进行延迟关联,优化思路也是把条件转移到主键索引树(查询出 limit 第一个参数offset对应的主键值,然后与原表利用id进行连接找到符合条件的数据),然后减少像回表,避免拷贝数据行的所有列的问题。而且延迟关联使用了 INNER JOIN 代替子查询。此外在复杂分页场景中,往往需要通过滤条件,筛选到符合条件的 ID,此时的 ID 是离散且不连续的。这时可以先去获取目标分页的 ID 集合,然后再根据 ID 集合获取内容,此时就可以使用INNER JOIN 进行延迟关联。
|
|
使用Limit Offset来实现分页查询,MySQL计算下推(三)- Limit Offset下推,深分页问题解决
社区MySQL在SQL层来过滤数据,当Limit offset值很大的时候会导致查询性能变的很差,虽然offset的数据不需要返回给客户端,但引擎依然读取每行数据返回给SQL层,由SQL层直接过滤掉。在这个过程中,引擎需要读取每一行数据转换为MySQL数据格式,有些场景访问索引还需要回主表获取所有需要的列数据,导致系统资源开销很大,极为耗时
在PolarDB MySQL中,优化器会识别能够将Limit offset下推到引擎的场景,然后在优化阶段将Limit offset下推到引擎层。执行时,引擎会快速扫描路径上的数据行,过滤掉用户客户端不需要的Offset数据,然后将用户需要的Limit数据返回

 浙公网安备 33010602011771号
浙公网安备 33010602011771号