Matrix Profile 与 Stumpy (时间序列挖掘,矩阵画像)
Matrix Profile 矩阵画像 (下文中简称为MP)
是由UCR(加州大学河滨分校)提出的一个时间序列的分析算法
——————————————————————————
目录:
算法简介
算法库
算法应用
其他集成应用
——————————————————————————
算法简介
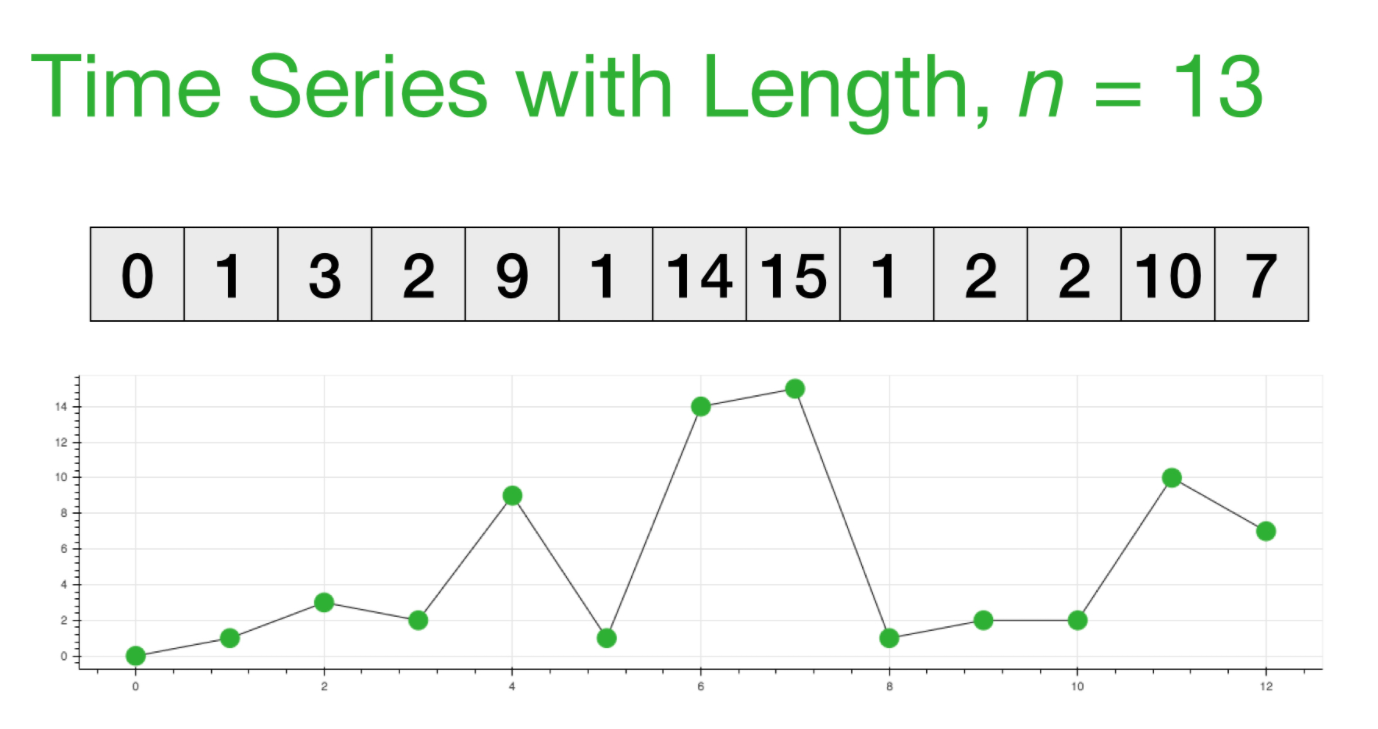
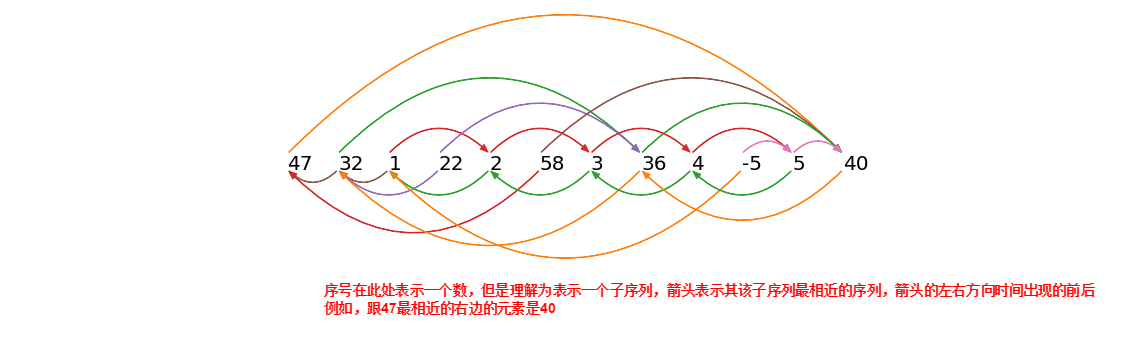
通过一个时间序列,可计算出它的MP,MP也是一个向量(时间序列)
以下面的时间序列为例:[0, 1, 3, 2, 9, 1, 14, 15, 1, 2, 2, 10, 7]
![]()
![]()
比较两个子序列的距离,以欧拉距离为例:

第一个子序列向后滑动逐个计算距离:

逐个计算后,会得到一个n*n的矩阵,取每行的最大值,得到的向量,即为MP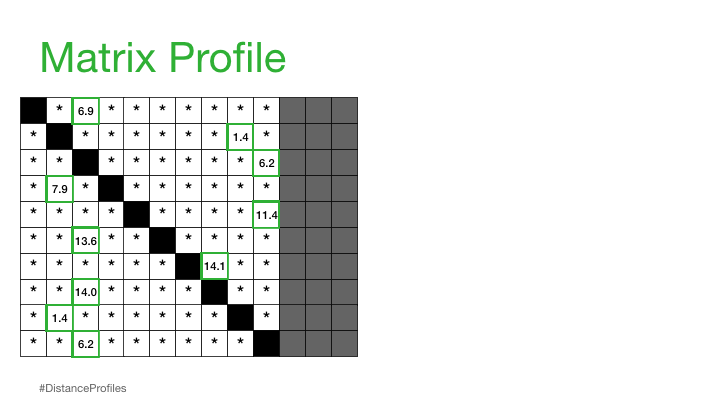
(中文定义摘自论文《基于矩阵画像的金融时序数据预测方法》,但此定义也是翻译自MP的英文论文,此处主要看计算距离的公式,不再是欧拉)




还有一点需要注意的是,计算距离的矩阵,在取最小值时,会考虑exclusion zone,可以避免计算距离的两个子序列是有较大重叠的带来的影响。 exclusion zone 一般取 i ± int(np.ceil(m / 4))

算法库(工具)
1. UCR提供的matrixprofile https://matrixprofile.docs.matrixprofile.org/Quickstart.html
2. STUMPY https://github.com/TDAmeritrade/stumpy 后面的算法应用的例子,主要采用stumpy
算法应用
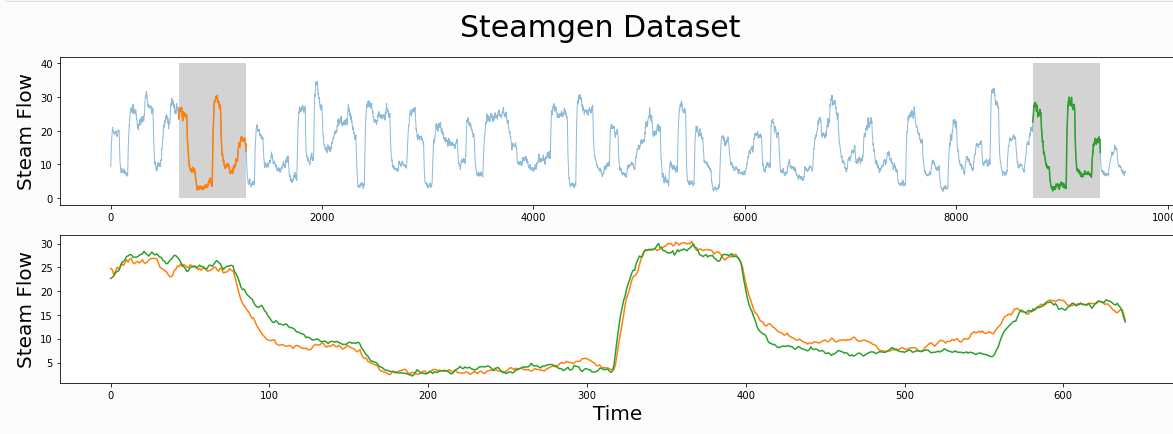
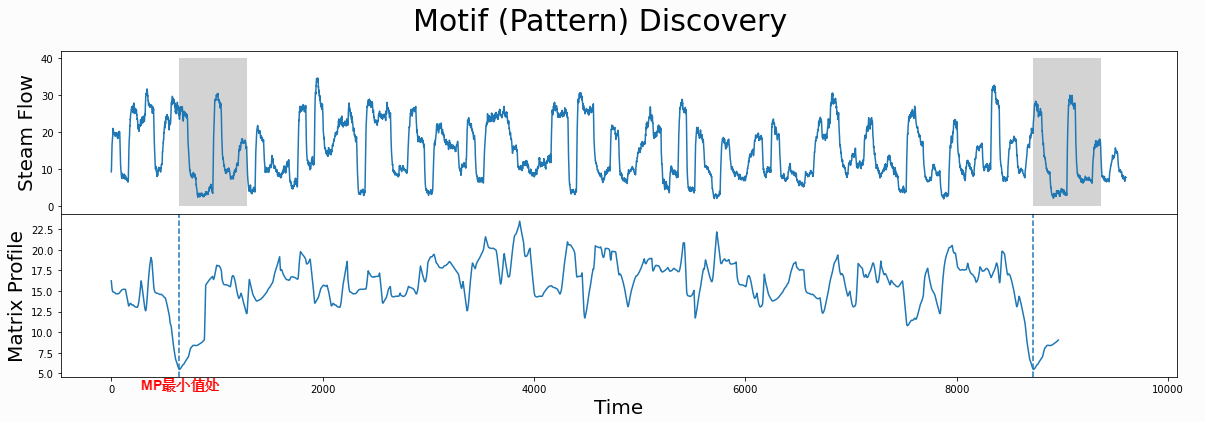
motif挖掘(利用MP的最小值)
异常发现(利用MP的最大值)
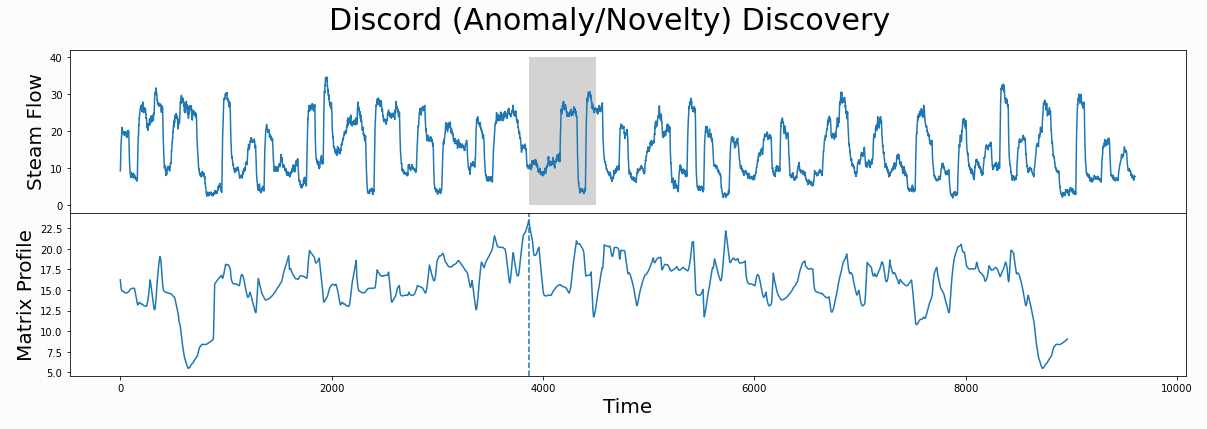
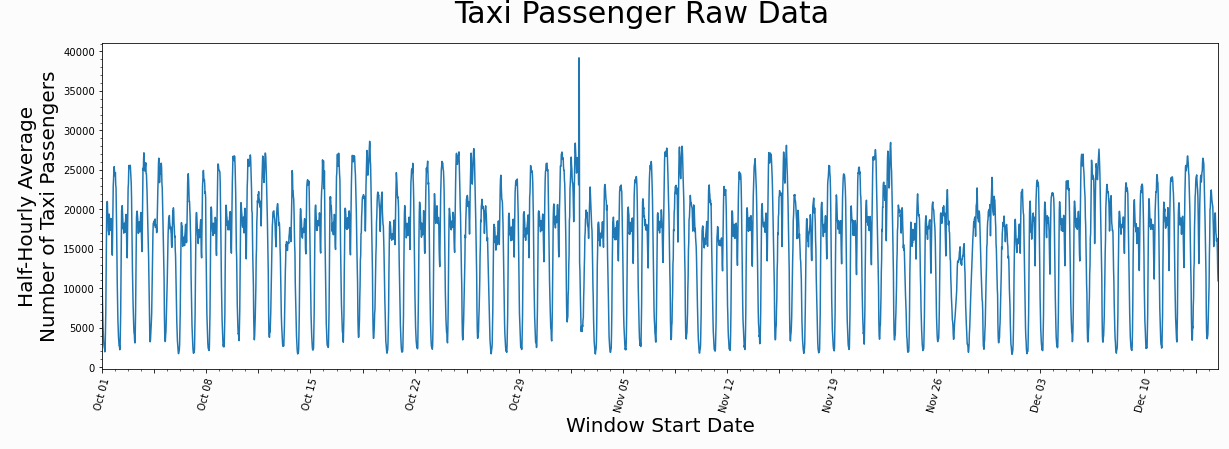
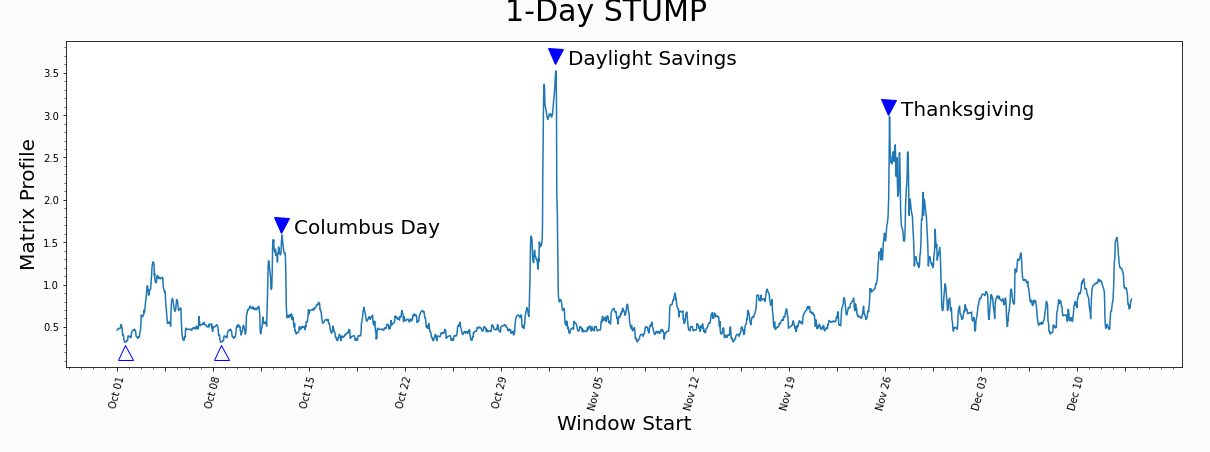
下面是出租车乘客量的例子,与平常不一致的日期是一些节假日
2. 时间链Time Series Chains https://stumpy.readthedocs.io/en/latest/Tutorial_Time_Series_Chains.html
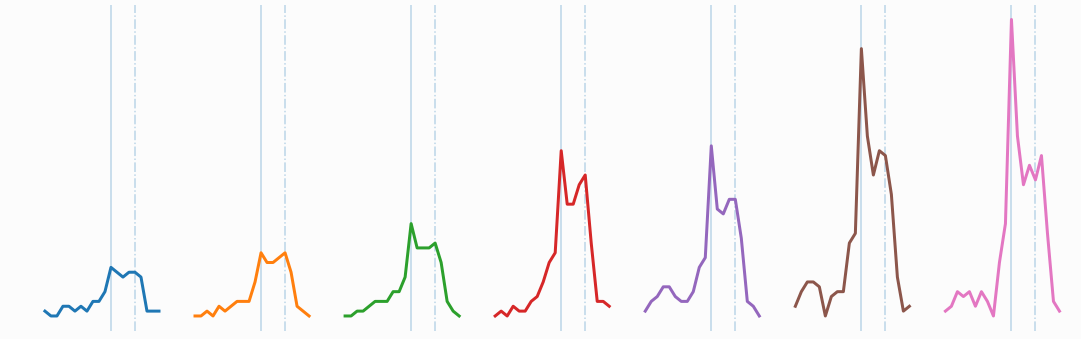
在此处,时间链被认为是 随着时间的推移在某个方向上演化或漂移的motif, 即重复出现的motif
下图是科颜氏在谷歌上的搜索量的统计图,可以看到彩色部分的波峰,具有一定的相似性

此处主要是利用stumpy计算返回后的数组,mp = stumpy.stump(df['volume'], m=m) 会返回一个n*4的矩阵,每一列分布表示:
out : ndarray
The first column consists of the matrix profile, MP值
the second column consists of the matrix profile indices, MP的索引,即第几个子序列
the third column consists of the left matrix profile indices, MP的左索引,即与该子序列最为相似的左边序列的索引
the fourth column consists of the right matrix profile indices. MP的右索引,即与该子序列最为相似的右边序列的索引
all_chain_set, unanchored_chain = stumpy.allc(mp[:, 2], mp[:, 3]) 计算得到的链
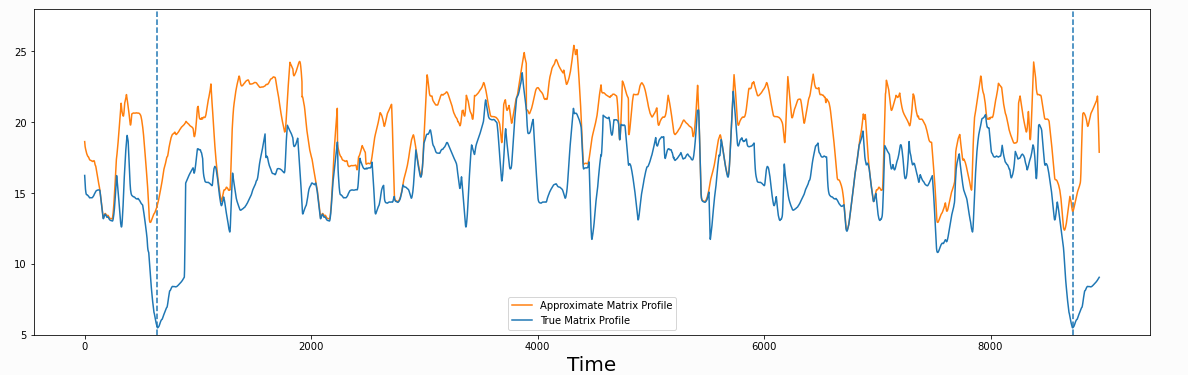
3. 场景分类 Semantic Segmentation https://stumpy.readthedocs.io/en/latest/Tutorial_Semantic_Segmentation.html
找到分界线
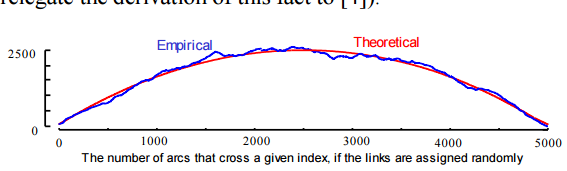
Fast low-cost unipotent semantic segmentation (FLUSS),计算“arc curve” 标识时间序列区域更迭的可能性, ac标识跨过该节点的弧线的数量
Fast low-cost online semantic segmentation (FLOSS) is a variation of FLUSS, 计算的是corrected arc curve (CAC) ,是一个单向的,可以处理实时时间流的数据。
计算CAC,首先需要计算IAC,IAC是指跨过该节点的理想数量
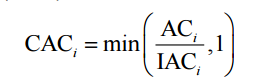
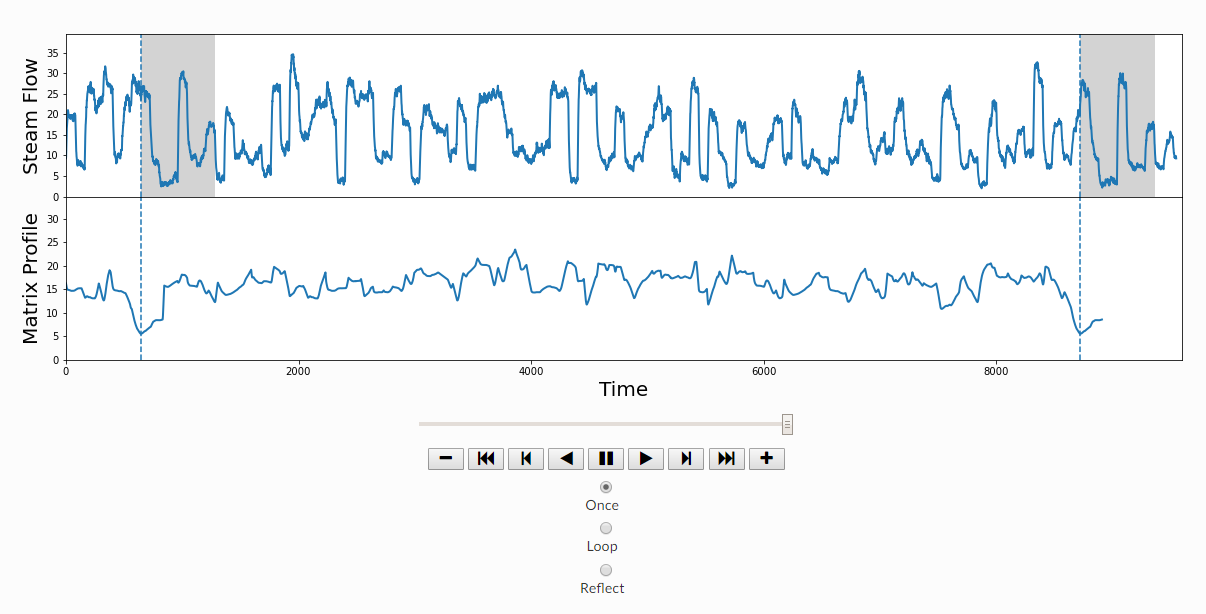
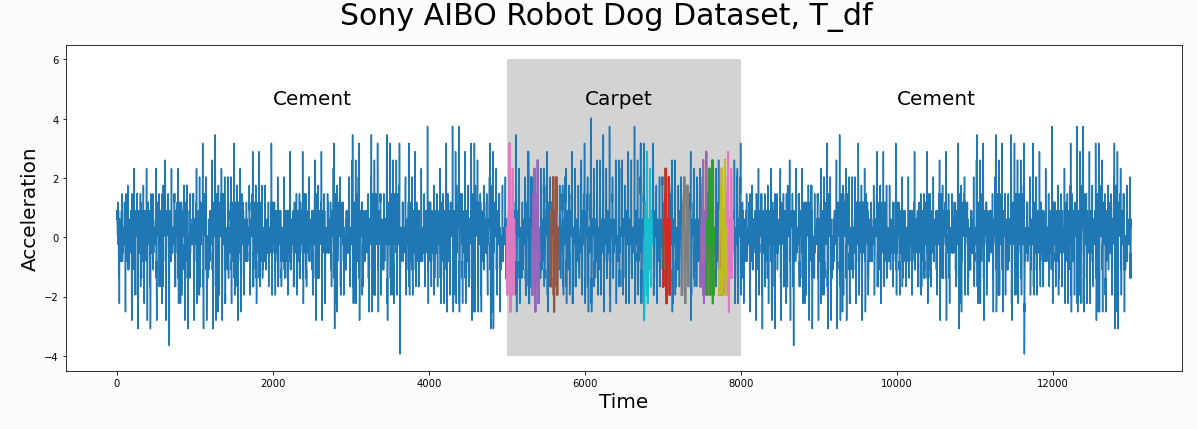
此处使用的是动脉血压的监测数据,阴影处为平放和竖直放的分界
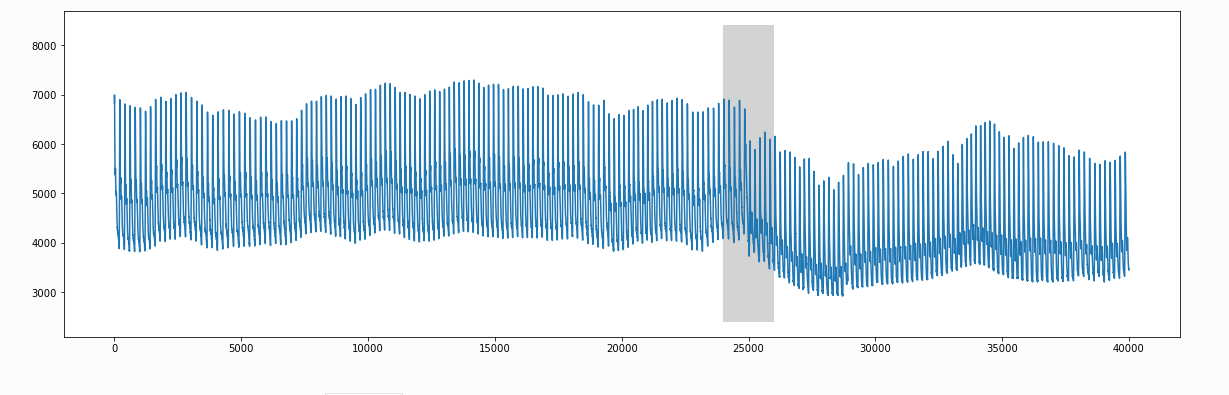
首先,需要计算 arc curve ,使用的是mp的索引列
m = 210 mp = stumpy.stump(abp, m=m)
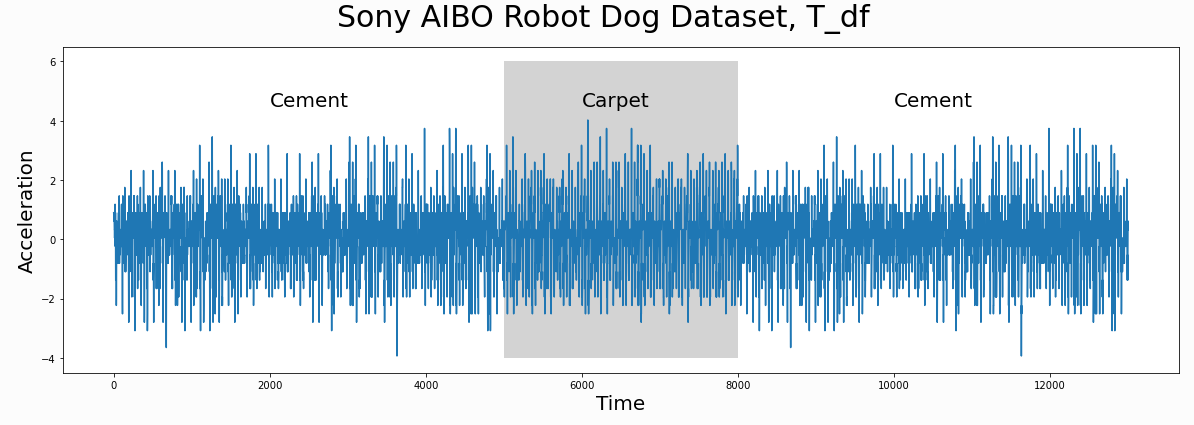
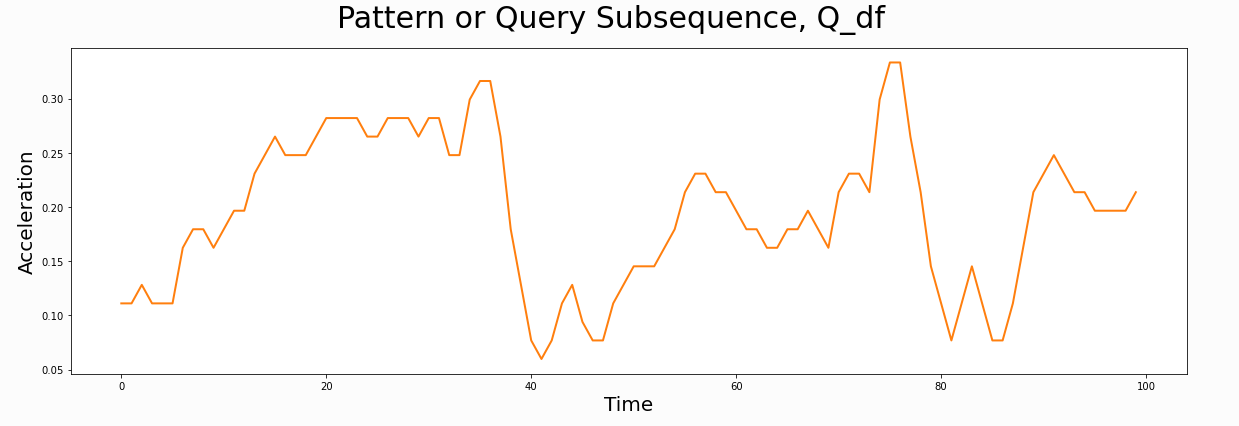
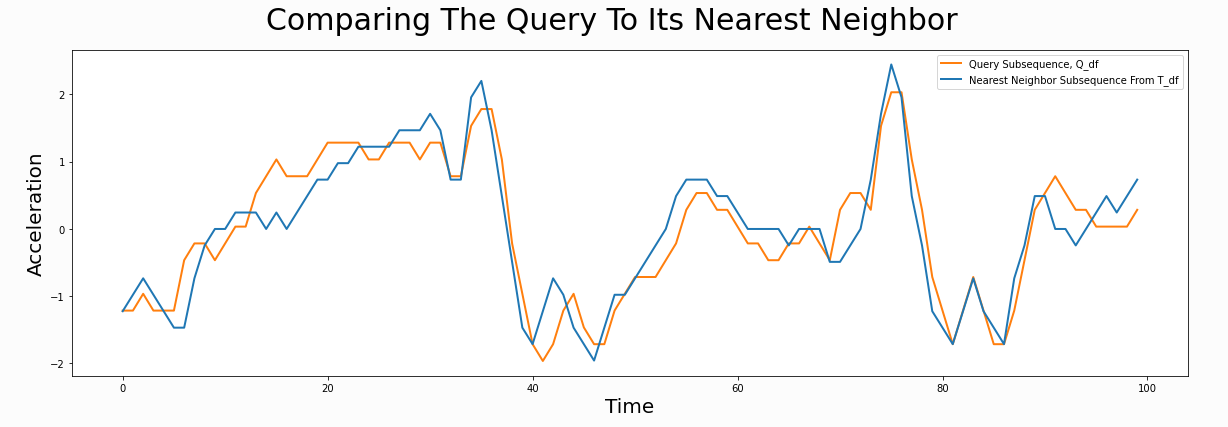
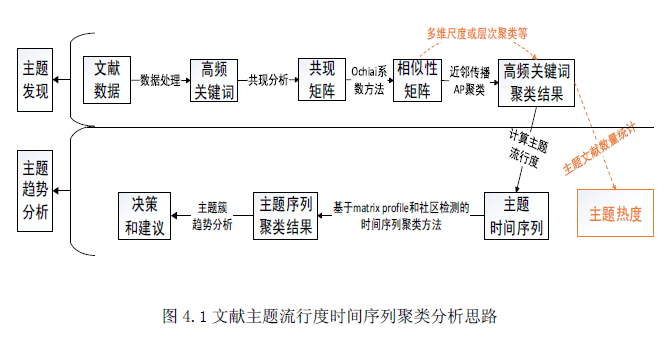
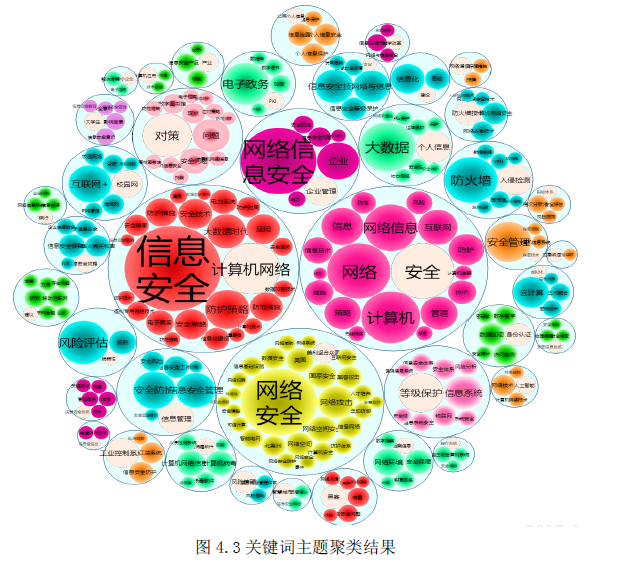
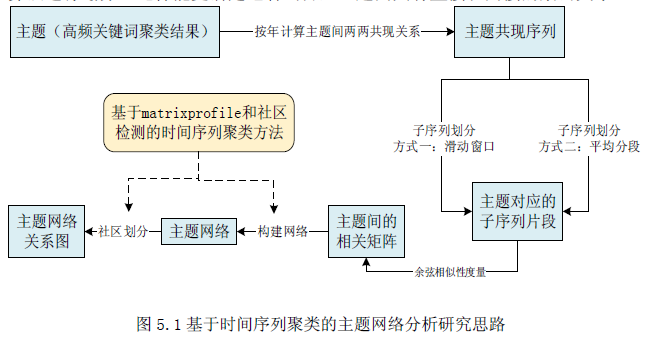
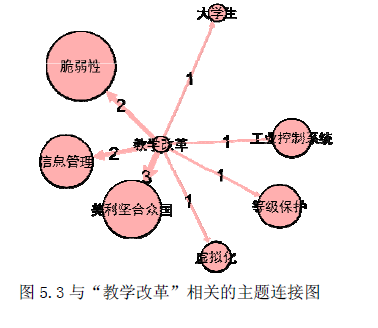
L = 210 cac, regime_locations = stumpy.fluss(mp[:, 1], L=L, n_regimes=2, excl_factor=1) (L--子序列长度,n_regimes-分类数目,excl_factor——使圆弧曲线的起点和终点无效,取值在1-5)使用scrump使用stumpyi输入一个查询序列,与一段时间序列,查询最为相近的时间序列例子中使用的数据为机器狗在不同区域(地毯carpet,水泥cement)走动时的加速器数据需要查询匹配的序列:计算结果:其他集成应用1. 基于矩阵画像的金融时序数据预测方法这篇文章是用于预测股票市场首先是构建主要交易行为的序列知识库(换手率?)进行模式匹配,文章说效果比arima和lstm好2. 基于事件序列聚类的文献主题分析研究通过NLP得到主题词的关联词关联词的时间热度使用MP计算时间热度序列间的关联度,最近邻的作为连接,从而构建词网使用社区挖掘的技术,进行挖掘,得到的团即为聚好的类





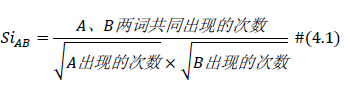


 浙公网安备 33010602011771号
浙公网安备 33010602011771号