Nacos-数据一致性原理
一、数据一致性服务执行流程
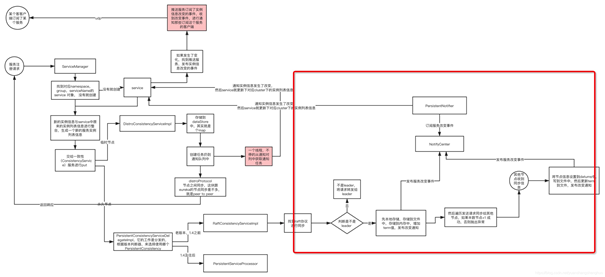
1.1 (临时/永久客户端注册)流程图
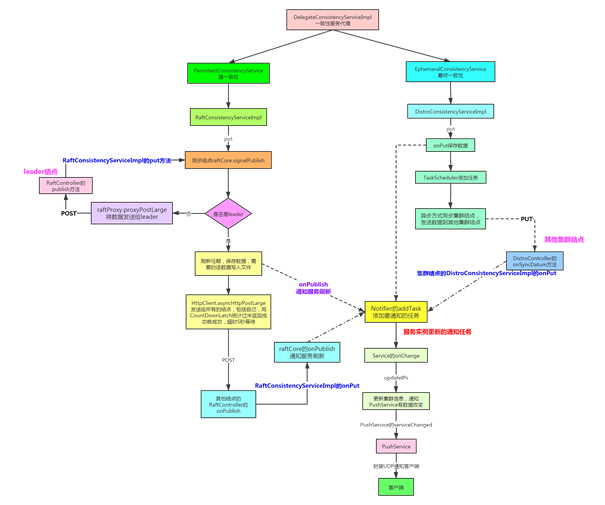
图片来源: https://blog.csdn.net/wangwei19871103/article/details/105836960
1.2 数据一致性
nacos内部提供两种数据同步方案AP和CP,而且是混用的,实例是临时的默认用AP,如果是永久的要就用CP。两个数据一致性服务的处理器类结构:
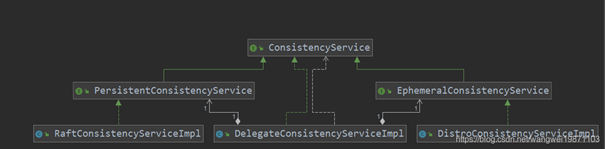
左边的RaftConsistencyServiceImpl就是CP的实现类,右边的DistroConsistencyServiceImpl就是AP的实现类;
注册实例的时候通常是DelegateConsistencyServiceImpl判断该用临时的还是永久的服务,其实他内部就是代理这两个:

DelegateConsistencyServiceImpl是一个一致性策略选择的类,根据不同的策略触发条件(在nacos中,CP与AP切换的条件是注册的服务实例是否是临时实例),选择PersistentConsistencyService策略或者EphemeralConsistencyService策略,
而EphemeralConsistencyService对应的是DistroConsistencyServiceImpl,采用的协议是阿里自研的Distro;PersistentConsistencyService对应的是RaftConsistencyServiceImpl,其底层采用的是Raft协议;
这两种一致性策略下的数据存储互不影响,所以nacos实现了AP模式与CP模式在一个组件中同时存在 ;
1.3 永久实例和临时实例区别
Nacos 在 1.0.0版本 instance级别增加了一个ephemeral字段,该字段表示注册的实例是否是临时实例还是持久化实例。
如果是临时实例,则不会在 Nacos 服务端持久化存储,需要通过上报心跳的方式进行包活,如果一段时间内没有上报心跳,则会被 Nacos 服务端摘除。在被摘除后如果又开始上报心跳,则会重新将这个实例注册。
持久化实例则会持久化被 Nacos 服务端,此时即使注册实例的客户端进程不在,这个实例也不会从服务端删除,只会将健康状态设为不健康。
二、永久实例数据同步(Raft协议)
客户端注册配置 ephemeral: false 客户端(永久)实例时候,会调用到
InstanceController 的 register() ----->
ServiceManager 中consistencyService.put(key, instances);----->
RaftConsistencyServiceImpl.put() ;
2.1 RaftConsistencyServiceImpl的put方法
@Override
public void put(String key, Record value) throws NacosException {
checkIsStopWork();//检查是否停止工作
raftCore.signalPublish(key, value); //发布信号
}
2.1.1 RaftCore.signalPublish()
public void signalPublish(String key, Record value) throws Exception {
//如果不是leader,raftProxy调用proxyPostLarge方法发送数据给leader
if (!isLeader()) {
final RaftPeer leader = getLeader();
// http调用 raft/datum 接口,发数据给leader
raftProxy.proxyPostLarge(leader.ip, API_PUB, params.toString(), parameters);
return;
}
//leader进行则处理, 将包发送给所有的 follower
OPERATE_LOCK.lock();
try {
final long start = System.currentTimeMillis();
final Datum datum = new Datum();
//组装datum和请求参数...(省略)
// leader 本地 onPublish 方法用来处理持久化逻辑,
onPublish(datum, peers.local());
final String content = json.toString();
// 计数器: majorityCount=peers.size() / 2 + 1
final CountDownLatch latch = new CountDownLatch(peers.majorityCount());
//循环包括leader的所有 参与者,进行更新信息
for (final String server : peers.allServersIncludeMyself()) {
if (isLeader(server)) {
latch.countDown(); //减少锁存器的计数,如果计数达到零,则释放所有等待线程。
continue;
}
// 异步调用接口为 /raft/datum/commit , 也是调用到 raftCore.onPublish() 方法
final String url = buildUrl(server, API_ON_PUB);
HttpClient.asyncHttpPostLarge(url, Arrays.asList("key", key), content, new Callback<String>() {
@Override
public void onReceive(RestResult<String> result) {
if (!result.ok()) { log.warn(....)
return;
}
latch.countDown(); //响应成功的话,计数器-1
}
});
}
//计数器,等5秒中,直到为0或者被打断
if (!latch.await(UtilsAndCommons.RAFT_PUBLISH_TIMEOUT, TimeUnit.MILLISECONDS)) {
失败抛异常...//只有多数节点成功才能算成功
}
} finally {
OPERATE_LOCK.unlock();
}
}
2.1.2 RaftProxy.proxyPostLarge()
代理post请求 携带大body;
public void proxyPostLarge(String server, String api, String content, Map<String, String> headers){
if (!server.contains(UtilsAndCommons.IP_PORT_SPLITER)) { // do proxy
server = server + UtilsAndCommons.IP_PORT_SPLITER + ApplicationUtils.getPort();
}
String url = "http://" + server + ApplicationUtils.getContextPath() + api;
RestResult<String> result = HttpClient.httpPostLarge(url, headers, content);
}
2.1.3 RaftCore.onPublish()
leader本地 onPublish 方法用来处理持久化逻辑 ;
public void onPublish(Datum datum, RaftPeer source) throws Exception {
RaftPeer local = peers.local();
if (datum.value == null) { 抛异常... }
if (!peers.isLeader(source.ip)) { 不是leader发布的抛异常 }
if (source.term.get() < local.term.get()) { / 来源 term 小于本地当前 term,抛异常 }
local.resetLeaderDue(); // 更新选举超时时间
// 添加到缓存file
if (KeyBuilder.matchPersistentKey(datum.key)) {
raftStore.write(datum);
}
//添加到缓存.
datums.put(datum.key, datum);
//计算本地term或 leader term ...(省略).
raftStore.updateTerm(local.term.get()); //更新任期到file中
//发布 ValueChangeEvent 事件
NotifyCenter.publishEvent(ValueChangeEvent.builder().key(datum.key).action(DataOperation.CHANGE).build());
}
2.2 ValueChangeEvent事件
@Override
public void onEvent(ValueChangeEvent event) {
notify(event.getKey(), event.getAction(), find.apply(event.getKey()));
}
2.2.1PersistentNotifier.notify() 通知
public <T extends Record> void notify(final String key, final DataOperation action, final T value) {
//关键代码是这里 监听到 数据改变的事件
if (action == DataOperation.CHANGE) {
listener.onChange(key, value);
continue;
}
}
2.2.2 Service.onChange()
@Override
public void onChange(String key, Instances value) throws Exception {
//用到这里,..表示 实例改变了
//更新实例, 发布ServiceChangeEvent事件,通知PushService有数据改变
updateIPs(value.getInstanceList(), KeyBuilder.matchEphemeralInstanceListKey(key));
//重新计算校验和(用编码字符集计算MD5十六进制字符串)
recalculateChecksum();
}
2.2.3Service.updateIPs()
这里面主要是,更新集群信息,通知 PushService有数据改变:
PushService.serviceChanged() 发布ServiceChangeEvent事件 ;
封装UDP通知客户端;
三、临时实例数据同步(Distro协议)
客户端注册配置 ephemeral: true(默认) 客户端(永久)实例时候,会调用到
InstanceController 的 register() ----->
ServiceManager 中 consistencyService.put(key, instances); ----->
DistroConsistencyServiceImpl.put() ;
3.1 DistroConsistencyServiceImpl.put()
public void put(String key, Record value) throws NacosException {
onPut(key, value); //放进一个队列里,然后同步任务从队列中获取要同步的服务key
distroProtocol.sync(new DistroKey(key, KeyBuilder.INSTANCE_LIST_KEY_PREFIX), DataOperation.CHANGE,
globalConfig.getTaskDispatchPeriod() / 2);
}
3.1.1 DistroConsistencyServiceImpl.onPut() 保存数据
public void onPut(String key, Record value) {
//匹配临时实例列表 key
if (KeyBuilder.matchEphemeralInstanceListKey(key)) {
Datum<Instances> datum = new Datum<>();
datum.value = (Instances) value;
datum.key = key;
datum.timestamp.incrementAndGet(); //时间戳自增
dataStore.put(key, datum); //放入dataStore内部的并发map中 (不持久化)
}
notifier.addTask(key, DataOperation.CHANGE); //添加一个任务记录 ,表示数据改变操作
}
3.1.2 Notifier.addTask()
public void addTask(String datumKey, DataOperation action) {
if (action == DataOperation.CHANGE) {
services.put(datumKey, StringUtils.EMPTY); //放入并发map中
}
tasks.offer(Pair.with(datumKey, action)); //将新的通知任务添加到队列 , tasks是BlockingQueue
}
Notifier :
private volatileNotifier notifier = new Notifier(); //对所有线程可见
@PostConstruct
public void init() {
GlobalExecutor.submitDistroNotifyTask(notifier);
}
服务启动后初始化,启动notifier任务,执行run方法,
@Override
public void run() {
Loggers.DISTRO.info("distro notifier started");
for (; ; ) {
//这里获取不到任务会等待,take方法
Pair<String, DataOperation> pair = tasks.take();
handle(pair);
}
}
private void handle(Pair<String, DataOperation> pair) {
String datumKey = pair.getValue0();
DataOperation action = pair.getValue1();
services.remove(datumKey);
for (RecordListener listener : listeners.get(datumKey)) {
if (action == DataOperation.CHANGE) {
listener.onChange(datumKey, dataStore.get(datumKey).value);
continue;
}
}
}
直接调用到了Service.Onchange()方法,前面已经介绍过了;
3.2 DistroProtocol.sync() 增量同步数据
onPut() 执行完后,还有一个方法,DistroProtocol节点之间同步, peer to peer ;
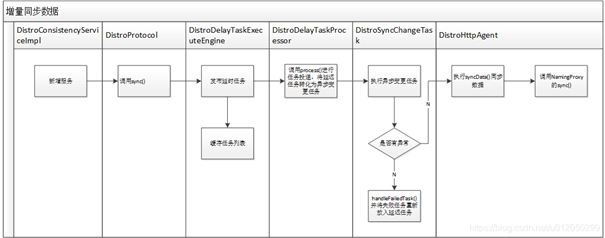
图片来源: https://blog.csdn.net/u012050299/article/details/110946637
3.2.1 主要步骤
新增数据使用异步广播同步:
- DistroProtocol 使用 sync() 方法接收增量数据;
- 调用 distroTaskEngineHolder 发布延迟任务;
- 调用 DistroDelayTaskProcessor.process() 方法进行任务投递,将延迟任务转换为异步变更任务;
- 执行变更任务 DistroSyncChangeTask.run() 方法向指定节点发送消息
- 调用 DistroHttpAgent.syncData() 方法发送数据,其内部调用 NamingProxy.syncData() 方法;
- 异常任务调用 handleFailedTask() 方法进行处理,如果失败则会调用 DistroHttpCombinedKeyTaskFailedHandler 将失败任务重新投递成延迟任务;
3.2.2 sync() 将数据同步到所有远程服务器
public void sync(DistroKey distroKey, DataOperation action, long delay) {
for (Member each : memberManager.allMembersWithoutSelf()) { //遍历除了自己之外的集群其他节点
DistroDelayTask distroDelayTask = new DistroDelayTask(distroKeyWithTarget, action, delay); //添加延迟任务
distroTaskEngineHolder.getDelayTaskExecuteEngine().addTask(distroKeyWithTarget, distroDelayTask);
}
}
3.2.3 NacosDelayTaskExecuteEngine 执行任务
NacosDelayTaskExecuteEngine在初始化时候,会启动线程固定周期执行任务ProcessRunnable,
private class ProcessRunnable implements Runnable {
@Override
public void run() { processTasks(); }
}
后面调用到DistroDelayTaskProcessor.process()方法 ;
@Override
public boolean process(NacosTask task) {
if (DataOperation.CHANGE.equals(distroDelayTask.getAction())) {
DistroSyncChangeTask syncChangeTask = new DistroSyncChangeTask(distroKey, distroComponentHolder); //将延迟任务转换为异步变更任务
distroTaskEngineHolder.getExecuteWorkersManager().addTask(distroKey, syncChangeTask);
return true;
}
return false;
}
3.2.4 DistroSyncChangeTask.run() 执行任务发送数据
@Override
public void run() {
//调用HTTP请求同步数据到目标服务器
boolean result = distroComponentHolder.findTransportAgent(type).syncData(distroData, getDistroKey().getTargetServer());
//没有成功或者异常情况则重试
handleFailedTask(); // 重新投递成延迟任务
}
3.2.5 DistroHttpAgent.syncData() 发送数据
@Override
public boolean syncData(DistroData data, String targetServer) {
byte[] dataContent = data.getContent(); //http调用
// 将datum同步到目标服务器 ,接口: xxx/distro/datum
return NamingProxy.syncData(dataContent, data.getDistroKey().getTargetServer());
}
四、Server节点启动(Raft协议)
4.1 启动加载数据
Nacos server在启动时,会调用RaftCore.init()方法。
4.1.1 RaftCore.init()
@PostConstruct //bean加载完后会被执行
public void init() throws Exception {
final long start = System.currentTimeMillis();
// 从磁盘加载Datum进行数据恢复
raftStore.loadDatums(notifier, datums);
// 从缓存文件加载元数据。并获取term 设置期限
setTerm(NumberUtils.toLong(raftStore.loadMeta().getProperty("term"), 0L));
initialized = true;
// 注册选举定时任务和心跳任务 (用于复制数据和探活等)
masterTask = GlobalExecutor.registerMasterElection(new MasterElection());
heartbeatTask = GlobalExecutor.registerHeartbeat(new HeartBeat());
NotifyCenter.registerSubscriber(notifier);
}
4.1.2 RaftStore.loadDatums()
public synchronized void loadDatums(PersistentNotifier notifier, Map<String, Datum> datums) {
Datum datum;
//listCaches 表示存在磁盘中文件,注册的永久客户端实例信息,比如: {nacos}\data\naming\data\public
for (File cache : listCaches()) {
for (File datumFile : cache.listFiles()) {
datum = readDatum(datumFile, cache.getName()); //读取客户端实例信息
if (datum != null) {
datums.put(datum.key, datum);
if (notifier != null) { // 发布一个 数据改变的事件,也就是说需要通知,这些实例发生改变了
NotifyCenter.publishEvent(
ValueChangeEvent.builder().key(datum.key).action(DataOperation.CHANGE).build());
}
}
}
continue;
}
datum = readDatum(cache, StringUtils.EMPTY);
if (datum != null) {
datums.put(datum.key, datum);
}
}
//到这里就完成所有datums加载
}
ValueChangeEvent事件监听者会调用onChange()方法;
4.1.3 RaftStore.setTerm()
优先读取 data\naming\meta.properties的配置, 如果没有则为0 ,term,越大说明状态越新 ;
setTerm(NumberUtils.toLong(raftStore.loadMeta().getProperty("term"), 0L));
4.1.4 MasterElection选举任务
raft选举流程,后面章节单独会分析。
4.2 HeartBeat心跳任务
RaftCore.init()方法除了上面的选举操作之外,紧跟着进行了集群心跳机制的逻辑;同样调用了一个定时任务,每个5s执行一个发送心跳的操作---new HeartBeat():
4.2.1 大致的过程
首先判断本机节点是否是Leader节点,如果不是则直接返回;
如果是Leader节点,则将RaftPeer和时间戳等信息封装并通过httpClient远程发送到其他nacos集群follower节点中;
请求会发送到RaftController.beat()方法;
beat方法中调用了RaftCore.receivedBeat()方法;
并将远程nacos节点RaftPeer返回到本机节点中;
然后更新RaftPeerSet集合信息,保持nacos集群数据节点的一致性。
4.2.2 HeartBeat.run()
该方法中,首先会获取本机节点的RaftPeer信息,并重置心跳信息;同时调用sendBeat()方法发送心跳:
@Override
public void run() {
if (stopWork) { return; }
if (!peers.isReady()) {return; } // 程序是否已准备完毕
RaftPeer local = peers.local();
local.heartbeatDueMs -= GlobalExecutor.TICK_PERIOD_MS;
if (local.heartbeatDueMs > 0) { return; } // 心跳周期判断
local.resetHeartbeatDue(); // 重置心跳发送周期
sendBeat(); // 发送心跳信息
}
4.2.2 HeartBeat.sendBeat()
private void sendBeat() throws IOException, InterruptedException {
RaftPeer local = peers.local();
if (ApplicationUtils.getStandaloneMode() || local.state != RaftPeer.State.LEADER) {
return; // 如果自己不是Leader节点或者处于单机模式下,则直接返回
}
local.resetLeaderDue(); // 重置Leader任期时间
// build data
ObjectNode packet = JacksonUtils.createEmptyJsonNode();
packet.replace("peer", JacksonUtils.transferToJsonNode(local));
ArrayNode array = JacksonUtils.createEmptyArrayNode();
// 如果开启了在心跳包中携带Leader存储的数据进行发送,则对数据进行打包操作
if (!switchDomain.isSendBeatOnly()) {
for (Datum datum : datums.values()) { //遍历datums中的数据
ObjectNode element = JacksonUtils.createEmptyJsonNode();
if (KeyBuilder.matchServiceMetaKey(datum.key)) {
element.put("key", KeyBuilder.briefServiceMetaKey(datum.key));
} else if (KeyBuilder.matchInstanceListKey(datum.key)) {
element.put("key", KeyBuilder.briefInstanceListkey(datum.key));
}
element.put("timestamp", datum.timestamp.get());
array.add(element);
}
}
packet.replace("datums", array);
// 广播
Map<String, String> params = new HashMap<String, String>(1);
params.put("beat", JacksonUtils.toJson(packet));
// 将参数信息进行 Gzip算法压缩,降低网络消耗
String content = JacksonUtils.toJson(params);
ByteArrayOutputStream out = new ByteArrayOutputStream();
GZIPOutputStream gzip = new GZIPOutputStream(out);
gzip.write(content.getBytes(StandardCharsets.UTF_8));
gzip.close();
byte[] compressedBytes = out.toByteArray();
String compressedContent = new String(compressedBytes, StandardCharsets.UTF_8);
// 遍历所有的Follower节点进行发送心跳数据包
for (final String server : peers.allServersWithoutMySelf()) {
final String url = buildUrl(server, API_BEAT); // "/raft/beat" 接口
// 采用异步HTTP请求进行心跳数据发送
HttpClient.asyncHttpPostLarge(url, null, compressedBytes, new Callback<String>() {
@Override
public void onReceive(RestResult<String> result) {
//不成功则异常
// 成功后接收Follower节点的心跳回复(Follower节点的当前信息)进行节点更新到peers
peers.update(JacksonUtils.toObj(result.getData(), RaftPeer.class));
}
});
}
}
4.2.2 RaftCore.receivedBeat()-Follower节点接收心跳
nacos中则是通过心跳来保证datum的一致性的。
逻辑功能: 比较哪些datum是需要更新的,如果需要更新,就异步发请求到leader,获取最新的datum并更新本地datums。
比较方法: 通过比较timestamp,之前也提到了,publish的时候,timestamp是会进行+1操作的,作为逻辑时钟,timestamp很好的区分了datum的版本。判断时只需要找到比传参来的时间戳小的datum就可以了。
代码还是比较长的,这里简化:
public RaftPeer receivedBeat(JsonNode beat) throws Exception {
final RaftPeer local = peers.local();
final RaftPeer remote = new RaftPeer();//远程参与者
JsonNode peer = beat.get("peer");
//如果不是leader发出心跳包 抛出异常(...省略))
//任期小于本地任期 抛出异常(...省略))
//本地服务状态不是follower 则设置为follower,选票设置为leader的ip
if (local.state != RaftPeer.State.FOLLOWER) {
local.state = RaftPeer.State.FOLLOWER;
local.voteFor = remote.ip;
}
//获取心跳的数据
final JsonNode beatDatums = beat.get("datums");
local.resetLeaderDue(); // 重置Leader任期时间
local.resetHeartbeatDue(); // 重置心跳时间
peers.makeLeader(remote); //更新leader以及peers信息
//如果不仅仅只是发送心跳 (可能在心跳的时候也会携带需要更新的数据过来)
if (!switchDomain.isSendBeatOnly()) {
Map<String, Integer> receivedKeysMap = new HashMap<>(datums.size());
for (Map.Entry<String, Datum> entry : datums.entrySet()) {
receivedKeysMap.put(entry.getKey(), 0);
}
// now check datums
List<String> batch = new ArrayList<>();
int processedCount = 0;
for (Object object : beatDatums) {
processedCount = processedCount + 1;
JsonNode entry = (JsonNode) object;
String key = entry.get("key").asText();
final String datumKey;
//判断是元数据信息还是服务实例数据
if (KeyBuilder.matchServiceMetaKey(key)) {
datumKey = KeyBuilder.detailServiceMetaKey(key);
} else if (KeyBuilder.matchInstanceListKey(key)) {
datumKey = KeyBuilder.detailInstanceListkey(key);
} else {
continue; //其他的忽略
}
long timestamp = entry.get("timestamp").asLong(); // 逻辑时间钟
receivedKeysMap.put(datumKey, 1);
//如果本地存在一样的键的数据,时间戳本地的大于远程更新的 说明数据过期,直接忽略
if (datums.containsKey(datumKey) && datums.get(datumKey).timestamp.get() >= timestamp
&& processedCount < beatDatums.size()) {
continue;
}
//如果本地没有的键的数据或者时间戳大于本地的数据的时间戳,添加到list等待批量更新
if (!(datums.containsKey(datumKey) && datums.get(datumKey).timestamp.get() >= timestamp)) {
batch.add(datumKey);
}
//尽量攒够50一起更新
if (batch.size() < 50 && processedCount < beatDatums.size()) {
continue;
}
String keys = StringUtils.join(batch, ",");
// 构建http请求根据数据的key获取leader中的数据来更新数据
String url = buildUrl(remote.ip, API_GET);
Map<String, String> queryParam = new HashMap<>(1);
queryParam.put("keys", URLEncoder.encode(keys, "UTF-8"));
HttpClient.asyncHttpGet(url, null, queryParam, new Callback<String>() {
@Override
public void onReceive(RestResult<String> result) {
//失败直接return
//解析http结果数据
List<JsonNode> datumList = JacksonUtils
.toObj(result.getData(), new TypeReference<List<JsonNode>>() { });
for (JsonNode datumJson : datumList) {
Datum newDatum = null;
OPERATE_LOCK.lock();
Datum oldDatum = getDatum(datumJson.get("key").asText());
//旧数据不为空,而且远程的时间戳小于等于本地的时间戳,直接忽略
if (oldDatum != null && datumJson.get("timestamp").asLong() <= oldDatum.timestamp
.get()) { continue; }
//根据不同的数据类型进行处理
if (KeyBuilder.matchServiceMetaKey(datumJson.get("key").asText())) {
Datum<Service> serviceDatum = new Datum<>();
serviceDatum.key = datumJson.get("key").asText();
serviceDatum.timestamp.set(datumJson.get("timestamp").asLong());
serviceDatum.value = JacksonUtils
.toObj(datumJson.get("value").toString(), Service.class);
newDatum = serviceDatum;
}
if (KeyBuilder.matchInstanceListKey(datumJson.get("key").asText())) {
Datum<Instances> instancesDatum = new Datum<>();
instancesDatum.key = datumJson.get("key").asText();
instancesDatum.timestamp.set(datumJson.get("timestamp").asLong());
instancesDatum.value = JacksonUtils
.toObj(datumJson.get("value").toString(), Instances.class);
newDatum = instancesDatum;
}
raftStore.write(newDatum); //本地磁盘写入新数据
datums.put(newDatum.key, newDatum); //新数据放入本地内存中
//添加数据修改的事件
notifier.notify(newDatum.key, DataOperation.CHANGE, newDatum.value);
local.resetLeaderDue();
//更新本地leader和本机的term,数据每次变动,term+100
if (local.term.get() + 100 > remote.term.get()) {
getLeader().term.set(remote.term.get());
local.term.set(getLeader().term.get());
} else {
local.term.addAndGet(100);
}
raftStore.updateTerm(local.term.get()); //更新磁盘的term
} finally {
OPERATE_LOCK.unlock();
}
}
return;
}
});
}
//如果是远程没有的key 那么证明本地的key是脏数据 需要删除
List<String> deadKeys = new ArrayList<>();
for (Map.Entry<String, Integer> entry : receivedKeysMap.entrySet()) {
if (entry.getValue() == 0) {
deadKeys.add(entry.getKey());
}
}
for (String deadKey : deadKeys) {
deleteDatum(deadKey);
}
}
return local;
}
五、Server节点启动(Distro协议)
初始数据全量同步,Distro协议节点启动时会从其他节点全量同步数据;
5.1 启动加载数据流程(全量同步)
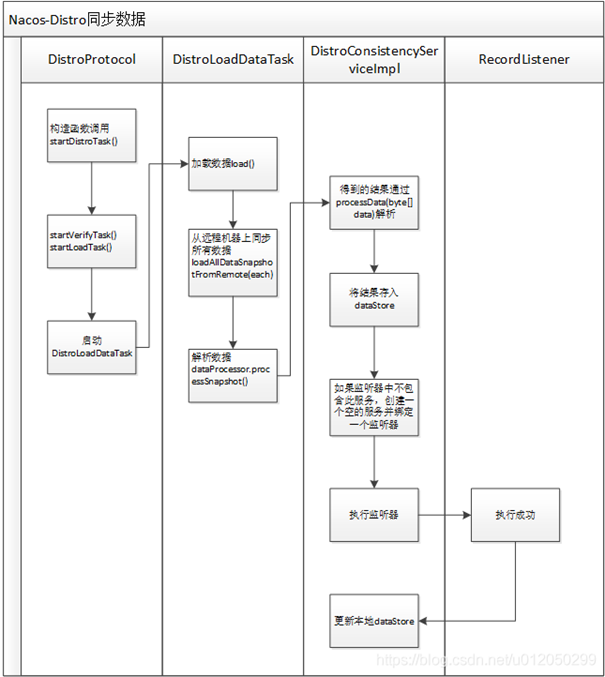
图片来源: https://blog.csdn.net/u012050299/article/details/110946637
5.1.1 主要步骤
- 启动一个定时任务线程DistroLoadDataTask加载数据,调用load()方法加载数据;
- 调用loadAllDataSnapshotFromRemote()方法从远程机器同步所有的数据;
- 从namingProxy代理获取所有的数据data,从获取的结果result中获取数据bytes;
- 处理数据processData从data反序列化出datumMap;
- 把数据存储到dataStore,也就是本地缓存dataMap
- 如果监听器不包括key,就创建一个空的service,并且绑定监听器
- 监听器listener执行成功后,就更新dataStore
5.2 代码流程
5.2.1 DistroProtocol构造函数启动任务
public DistroProtocol(ServerMemberManager memberManager, DistroComponentHolder distroComponentHolder,
DistroTaskEngineHolder distroTaskEngineHolder, DistroConfig distroConfig) {
this.memberManager = memberManager;
this.distroComponentHolder = distroComponentHolder;
this.distroTaskEngineHolder = distroTaskEngineHolder;
this.distroConfig = distroConfig;
startDistroTask();
}
private void startDistroTask() {
if (ApplicationUtils.getStandaloneMode()) { //单机启动的返回.
isInitialized = true;
return;
}
startVerifyTask(); //验证任务,调用http接口, "/distro/checksum";
startLoadTask();//开启启动任务
}
5.2.2 DistroLoadDataTask.run() 执行任务
@Override
public void run() {
load(); //加载
// 加载没完成 再提交一下任务, 出现异常则设置初始化标识失败 ...
}
private void load() throws Exception {
for (String each : distroComponentHolder.getDataStorageTypes()) {
if (!loadCompletedMap.containsKey(each) || !loadCompletedMap.get(each)) {
loadCompletedMap.put(each, loadAllDataSnapshotFromRemote(each));
}
}
}
5.2.3 loadAllDataSnapshotFromRemote()从远程机器同步所有的数据
//从远程加载所有数据快照
private boolean loadAllDataSnapshotFromRemote(String resourceType) {
DistroTransportAgent transportAgent = distroComponentHolder.findTransportAgent(resourceType);
DistroDataProcessor dataProcessor = distroComponentHolder.findDataProcessor(resourceType);
//遍历集群成员节点,不包括自己
for (Member each : memberManager.allMembersWithoutSelf()) {
//从远程节点加载数据,返回只要有一个返回成功,
//调用http请求接口: distro/datums;
DistroData distroData = transportAgent.getDatumSnapshot(each.getAddress());
boolean result = dataProcessor.processSnapshot(distroData); //处理数据
if (result) { return true; }
}
return false;
}
5.2.4 DistroHttpAgent.getDatumSnapshot()请求获取数据
@Override
public DistroData getDatumSnapshot(String targetServer) {
//从namingProxy代理获取所有的数据data,从获取的结果result中获取数据bytes
byte[] allDatum = NamingProxy.getAllData(targetServer);
return new DistroData(new DistroKey("snapshot", KeyBuilder.INSTANCE_LIST_KEY_PREFIX), allDatum);
}
5.2.5 DistroHttpAgent.processSnapshot()解析数据
@Override
public boolean processSnapshot(DistroData distroData) {
return processData(distroData.getContent());
}
private boolean processData(byte[] data) throws Exception {
//从data反序列化出datumMap
Map<String, Datum<Instances>> datumMap = serializer.deserializeMap(data, Instances.class);
// 把数据存储到dataStore,也就是本地缓存dataMap
for (Map.Entry<String, Datum<Instances>> entry : datumMap.entrySet()) {
dataStore.put(entry.getKey(), entry.getValue());
//监听器不包括key,就创建一个空的service,并且绑定监听器
if (!listeners.containsKey(entry.getKey())) {
// pretty sure the service not exist:
if (switchDomain.isDefaultInstanceEphemeral()) {
Service service = new Service();
... 省略部分代码
// 与键值对应的监听器不能为空,这里的监听器类型是 ServiceManager
RecordListener listener = listeners.get(KeyBuilder.SERVICE_META_KEY_PREFIX).peek();
// service 绑定监听器 , 调用 ServiceManager.onChange方法 ,
listener.onChange(KeyBuilder.buildServiceMetaKey(namespaceId, serviceName), service);
}
}
}
for (Map.Entry<String, Datum<Instances>> entry : datumMap.entrySet()) {
for (RecordListener listener : listeners.get(entry.getKey())) {
listener.onChange(entry.getKey(), entry.getValue().value);
}
// 监听器listener执行成功后,就更新dataStore
dataStore.put(entry.getKey(), entry.getValue());
}
}
return true;
}
六、Distro协议总结
6.1 简单介绍
这个为临时数据的一致性协议: 不需要把数据存储到磁盘或者数据库;因为临时数据通常和服务器保持一个session会话;这个会话只要存在,数据就不会丢失。
写必须永远是成功的,即使可能会发生网络分区。当网络恢复时,每个数据分片都合并到一个set中,所以集群就是恢复成一致性的状态。
6.2 关键点
- distro协议是为了注册中心而创造出的协议;
- 客户端与服务端有两个重要的交互,服务注册与心跳发送;
- 客户端以服务为维度向服务端注册,注册后每隔一段时间向服务端发送一次心跳,心跳包需要带上注册服务的全部信息,在客户端看来,服务端节点对等,所以请求的节点是随机的;
- 客户端请求失败则换一个节点重新发送请求;
- 服务端节点都存储所有数据,但每个节点只负责其中一部分服务,在接收到客户端的"写"(注册、心跳、下线等)请求后,服务端节点判断请求的服务是否为自己负责,如果是,则处理,否则交由负责的节点处理;
- 每个服务端节点主动发送健康检查到其他节点,响应的节点被该节点视为健康节点;
- 服务端在接收到客户端的服务心跳后,如果该服务不存在,则将该心跳请求当做注册请求来处理;
- 服务端如果长时间未收到客户端心跳,则下线该服务;
- 负责的节点在接收到服务注册、服务心跳等写请求后将数据写入后即返回,后台异步地将数据同步给其他节点;
- 节点在收到读请求后直接从本机获取后返回,无论数据是否为最新。
七、Raft协议总结
7.1 简单介绍
Raft通过当选的领导者达成共识。集群中的服务器是leader或folower,并且在选举的精确情况下可以是候选者(领导者不可用)。
leader负责将日志复制到关注者。它通过发送心跳消息定期通知folower它的存在。
每个folower都有一个超时(通常在150到300毫秒之间),接收心跳时重置超时。
如果没有收到心跳,则关注者将其状态更改为候选人并开始leader选举。
7.2 关键点
7.2.1 Raft 的选举过程
Raft 协议在集群初始状态下是没有 Leader 的, 集群中所有成员均是 Follower,在选举开始期间所有 Follower 均可参与选举,这时所有 Follower 的角色均转变为 Condidate, Leader 由集群中所有的 Condidate 投票选出,最后获得投票最多的 Condidate 获胜,其角色转变为 Leader 并开始其任期,其余落败的 Condidate 角色转变为 Follower 开始服从 Leader 领导。
这里有一种意外的情况会选不出 Leader 就是所有 Condidate 均投票给自己,这样无法决出票数多的一方,Raft 算法 选不出 Leader 不罢休,直到选出为止,一轮选不出 Leader,便令所有 Condidate 随机时间 sleap(Raft 论文称为 timeout)一段时间,然后马上开始新一轮的选举,这里的随机 sleep 就起了很关键的因素,第一个从 sleap 状态恢复过来的 Condidate 会向所有 Condidate 发出投票给我的申请,这时还没有苏醒的 Condidate 就只能投票给已经苏醒的 Condidate ,因此可以有效解决 Condiadte 均投票给自己的故障,便可快速的决出 Leader。
选举出 Leader 后 Leader 会定期向所有 Follower 发送 heartbeat 来维护其 Leader 地位,如果 Follower 一段时间后未收到 Leader 的心跳则认为 Leader 已经挂掉,便转变自身角色为 Condidate,同时发起新一轮的选举,产生新的 Leader。
7.2.2 Raft 的数据一致性策略
Raft 协议强依赖 Leader 节点来确保集群数据一致性。即 client 发送过来的数据均先到达 Leader 节点,Leader 接收到数据后,先将数据标记为 uncommitted 状态,随后 Leader 开始向所有 Follower 复制数据并等待响应,在获得集群中大于 N/2 个 Follower 的已成功接收数据完毕的响应后,Leader 将数据的状态标记为 committed,随后向 client 发送数据已接收确认,在向 client 发送出已数据接收后,再向所有 Follower 节点发送通知表明该数据状态为committed。
7.2.3 Raft 如何处理 Leader 意外
1. client 发送数据到达 Leader 之前 Leader 就挂了,因为数据还没有到达集群内部,所以对集群内部数据的一致性没有影响,Leader 挂了之后,集群会进行新的选举产生新的 Leader,之前挂掉的 Leader 重启后作为 Follower 加入集群,并同步 Leader 上的数据。这里最好要求 client 有重试机制在一定时间没有收到 Leader 的数据已接收确认后进行一定次数的重试,并再次向新的 Leader 发送数据来确保业务的流畅性。
2. client 发送数据到 Leader,数据到达 Leader 后,Leader 还没有开始向 Folloers 复制数据,Leader就挂了,此时数据仍被标记为 uncommited 状态,这时集群会进行新的选举产生新的 Leader,之前挂掉的 Leader 重启后作为 Follower 加入集群,并同步 Leader 上的数据,来保证数据一致性,之前接收到 client 的数据由于是 uncommited 状态所以可能会被丢弃。这里同样最好要求 client 有重试机制通过在一定时间在没有收到 Leader 的数据已接收确认后进行一定次数的重试,再次向新的 Leader 发送数据来确保业务的流畅性。
3. client 发送数据到 Leader, Leader 接收数据完毕后标记为 uncommited,开始向 Follower复制数据,在复制完毕一小部分 Follower 后 Leader 挂了,此时数据在所有已接收到数据的 Follower 上仍被标记为 uncommitted,此时集群将进行新的选举,而拥有最新数据的 Follower 变换角色为 Condidate,也就意味着 Leader 将在拥有最新数据的 Follower 中产生,新的 Leader 产生后所有节点开始从新 Leader 上同步数据确保数据的一致性,包括之前挂掉后恢复了状态的 老Leader,这时也以 Follower 的身份同步新 Leader 上的数据。
4. client 发送数据到 Leader,Leader 接收数据完毕后标记为 uncommitted,开始向 Follower 复制数据,在复制完毕所有 Follower 节点或者大部分节点(大于 N/2),并接收到大部分节点接收完毕的响应后,Leader 节点将数据标记为 committed,这时 Leader 挂了,此时已接收到数据的所有 Follower 节点上的数据状态由于还没有接收到 Leader 的 commited 通知,均处于 uncommited 状态。这时集群进行了新的选举,新的 Leader 将在拥有最新数据的节点中产生,新的 Leader 产生后,由于 client 端因老 Leader 挂掉前没有通知其数据已接收,所以会向新的 Leader 发送重试请求,而新的 Leader 上已经存在了这个之前从老 Leader 上同步过来的数据,因此 Raft 集群要求各节点自身实现去重的机制,保证数据的一致性。
5. 集群脑裂的一致性处理,多发于双机房的跨机房模式的集群。(网络分区导致两边选了2个leader), 假设一个 5 节点的 Raft 集群,其中三个节点在 A 机房,Leader 节点也在 A 机房,两个节点在 B 机房。突然 A、B 两个机房之间因其他故障无法通讯,那么此时 B 机房中的 2 个Follower 因为失去与 Leader 的联系,均转变自身角色为 Condidate。根据 Leader 选举机制,B 机房中产生了一个新的 Leader,这就发生了脑裂即存在 A 机房中的老 Leader 的集群与B机房新 Leader 的集群。Raft 针对这种情况的处理方式是老的 Leader 集群虽然剩下三个节点,但是 Leader 对数据的处理过程还是在按原来 5 个节点进行处理,所以老的 Leader 接收到的数据,在向其他 4 个节点复制数据,由于无法获取超过 N/2 个 Follower 节点的复制完毕数据响应(因为无法连接到 B 机房中的 2个节点),所以 client 在向老 Leader 发送的数据请求均无法成功写入,而 client 向B机房新 Leader 发送的数据,因为是新成立的集群,所以可以成功写入数据,在A、B两个机房恢复网络通讯后,A 机房中的所有节点包括老 Leader 再以 Follower 角色接入这个集群,并同步新 Leader 中的数据,完成数据一致性处理。
(两边的节点合并时候会判断任期)
参考:
https://www.liaochuntao.cn/2019/06/01/java-web-41 ,
https://blog.csdn.net/u012050299/article/details/110946637,
https://blog.csdn.net/kuaipao19950507/article/details/105980892 ,
https://blog.csdn.net/liyanan21/article/details/89320872 ,
https://blog.csdn.net/liaohonghb/article/details/105683239,
https://blog.csdn.net/wangwei19871103/article/details/105836960,
https://blog.csdn.net/xiaohanzuofengzhou/article/details/102544721

 浙公网安备 33010602011771号
浙公网安备 33010602011771号