
ForkJoin之ForkJoinTask框架学习笔记
1.Fork/Join框架:(分治算法思想)
在必要的情况下,将一个大任务,进行拆分(fork) 成若干个子任务(拆到不能再拆,这里就是指我们制定的拆分的临界值),再将一个个小任务的结果进行join汇总。
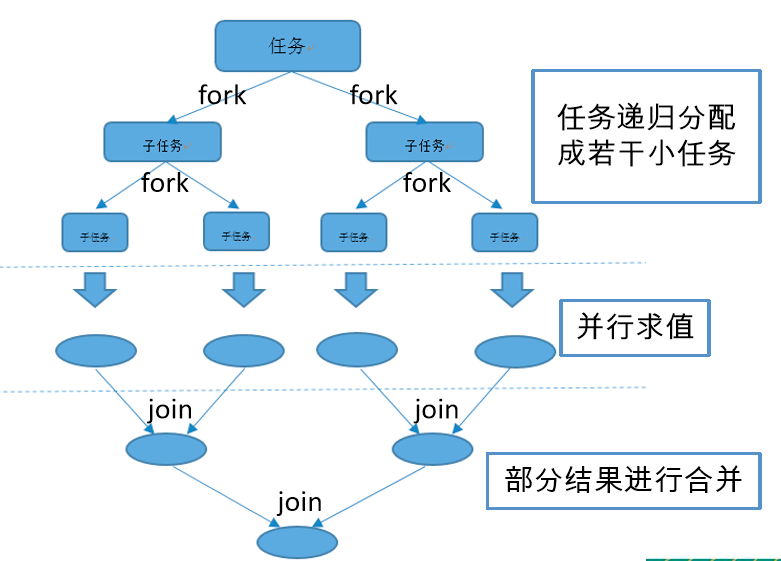
2.Fork/Join工作方式:
ForkJoinTask需要通过ForkJoinPool来执行。
ForkJoinTask可以理解为类线程但比线程轻量的实体, 在ForkJoinPool中运行的少量ForkJoinWorkerThread可以持有大量的ForkJoinTask和它的子任务.
ForkJoinTask同时也是一个轻量的Future,使用时应避免较长阻塞和io.
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成,ForkJoinTask数组负责将存放程序提交给ForkJoinPool,而ForkJoinWorkerThread负责执行这些任务。
任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。
当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务(工作窃取算法)。
也就是说Fork/Join采用“工作窃取模式”,当执行新的任务时他可以将其拆分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随即线程中偷一个并把它加入自己的队列中。
就比如两个CPU上有不同的任务,这时候A已经执行完,B还有任务等待执行,这时候A就会将B队尾的任务偷过来,加入自己的队列中,对于传统的线程,ForkJoin更有效的利用的CPU资源!
ForkJoinWorkerThread线程是一种在Fork/Join框架中运行的特性线程,它除了具有普通线程的特性外,最主要的特点是每一个ForkJoinWorkerThread线程都具有一个独立的任务等待队列(work queue),这个任务队列用于存储在本线程中被拆分的若干子任务。
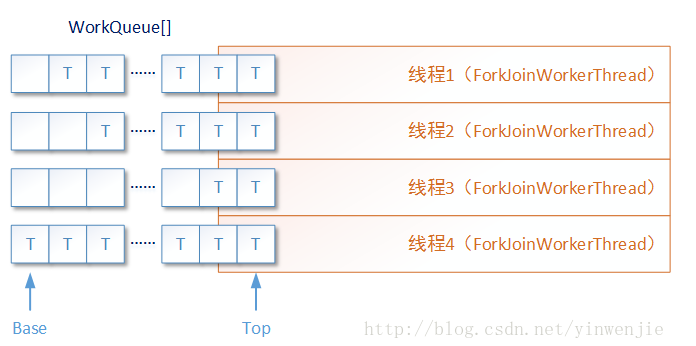
3.Fork/Join框架实现
实现这个框架需要继承RecursiveTask 或者 RecursiveAction ,
RecursiveTask是有返回值的,RecursiveAction 则没有。
下面是计算一个计算数据和的示例:
public class ForkJoinWork extends RecursiveTask<Long> { private Long start;//起始值 private Long end;//结束值 public static final Long critical = 100000L;//临界值 public ForkJoinWork(Long start, Long end) { this.start = start; this.end = end; } @Override protected Long compute() { // return null; //判断是否是拆分完毕 Long lenth = end - start; //起始值差值 if (lenth <= critical) { //如果拆分完毕就相加 Long sum = 0L; for (Long i = start; i <= end; i++) { sum += i; } return sum; } else { //没有拆分完毕就开始拆分 Long middle = (end + start) / 2;//计算的两个值的中间值 ForkJoinWork right = new ForkJoinWork(start, middle); right.fork();//拆分,并压入线程队列 ForkJoinWork left = new ForkJoinWork(middle + 1, end); left.fork();//拆分,并压入线程队列 //合并 return right.join() + left.join(); } } }
测试:
public class ForkJoinWorkTest {
@Test public void test() { //ForkJoin实现 long l = System.currentTimeMillis(); ForkJoinPool forkJoinPool = new ForkJoinPool();//实现ForkJoin 就必须有ForkJoinPool的支持 ForkJoinTask<Long> task = new ForkJoinWork(0L, 10000000000L);//参数为起始值与结束值 Long invoke = forkJoinPool.invoke(task); long l1 = System.currentTimeMillis(); System.out.println("invoke = " + invoke + " time: " + (l1 - l)); //invoke = -5340232216128654848 time: 56418 //ForkJoinWork forkJoinWork = new ForkJoinWork(0L, 10000000000L); } @Test public void test2() { //普通线程实现 Long x = 0L; Long y = 10000000000L; long l = System.currentTimeMillis(); for (Long i = 0L; i <= y; i++) { x += i; } long l1 = System.currentTimeMillis(); System.out.println("invoke = " + x + " time: " + (l1 - l)); //invoke = -5340232216128654848 time: 64069 } @Test public void test3() { //Java 8 并行流的实现 long l = System.currentTimeMillis(); long reduce = LongStream.rangeClosed(0, 10000000000L).parallel().reduce(0, Long::sum); //long reduce = LongStream.rangeClosed(0, 10000000000L).parallel().reduce(0, (a, b) -> a+b); long l1 = System.currentTimeMillis(); System.out.println("invoke = " + reduce + " time: " + (l1 - l)); //invoke = -5340232216128654848 time: 2152 } }
4.分析:
我们观察上面可以看出来执行10000000000L的相加操作各自执行完毕的时间不同。观察到当数据很大的时候ForkJoin比普通线程实现有效的多,但是相比之下ForkJoin的实现实在是有点麻烦,这时候Java 8 就为我们提供了一个并行流来实现ForkJoin实现的功能。可以看到并行流比自己实现ForkJoin还要快。
Java 8 中将并行流进行了优化,我们可以很容易的对数据进行并行流的操作,Stream API可以声明性的通过parallel()与sequential()在并行流与串行流中随意切换!
5.ForkJoinPool
ForkJoinTask需要通过ForkJoinPool来执行。位于java.util.concurrent包下,构造函数:
public ForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory, UncaughtExceptionHandler handler, boolean asyncMode) { this(checkParallelism(parallelism), checkFactory(factory), handler, asyncMode ? FIFO_QUEUE : LIFO_QUEUE, "ForkJoinPool-" + nextPoolId() + "-worker-"); checkPermission(); }
-
parallelism:可并行级别,Fork/Join框架将依据这个并行级别的设定,决定框架内并行执行的线程数量。并行的每一个任务都会有一个线程进行处理,但是千万不要将这个属性理解成Fork/Join框架中最多存在的线程数量,也不要将这个属性和ThreadPoolExecutor线程池中的corePoolSize、maximumPoolSize属性进行比较,因为ForkJoinPool的组织结构和工作方式与后者完全不一样。而后续的讨论中,还可以发现Fork/Join框架中可存在的线程数量和这个参数值的关系并不是绝对的关联(有依据但并不全由它决定)。
-
factory:当Fork/Join框架创建一个新的线程时,同样会用到线程创建工厂。只不过这个线程工厂不再需要实现ThreadFactory接口,而是需要实现ForkJoinWorkerThreadFactory接口。后者是一个函数式接口,只需要实现一个名叫newThread的方法。在Fork/Join框架中有一个默认的ForkJoinWorkerThreadFactory接口实现:DefaultForkJoinWorkerThreadFactory。
-
handler:异常捕获处理器。当执行的任务中出现异常,并从任务中被抛出时,就会被handler捕获。
-
asyncMode:这个参数也非常重要,从字面意思来看是指的异步模式,它并不是说Fork/Join框架是采用同步模式还是采用异步模式工作。Fork/Join框架中为每一个独立工作的线程准备了对应的待执行任务队列,这个任务队列是使用数组进行组合的双向队列。即是说存在于队列中的待执行任务,即可以使用先进先出的工作模式,也可以使用后进先出的工作模式。当asyncMode设置为ture的时候,队列采用先进先出方式工作;反之则是采用后进先出的方式工作,该值默认为false.(WorkQueue)
ForkJoinPool还有另外两个构造函数,一个构造函数只带有parallelism参数,既是可以设定Fork/Join框架的最大并行任务数量;
另一个构造函数则不带有任何参数,对于最大并行任务数量也只是一个默认值——当前操作系统可以使用的CPU内核数量(Runtime.getRuntime().availableProcessors())。
实际上ForkJoinPool还有一个私有的、原生构造函数,之上提到的三个构造函数都是对这个私有的、原生构造函数的调用。
//对于最大并行任务数量也只是一个默认值——当前操作系统可以使用的CPU内核数量 public ForkJoinPool() { this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()), defaultForkJoinWorkerThreadFactory, null, false); } //框架的最大并行任务数量 public ForkJoinPool(int parallelism) { this(parallelism, defaultForkJoinWorkerThreadFactory, null, false); } //私有的、原生构造函数(被上面的构造函数 调用) private ForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory, UncaughtExceptionHandler handler, int mode, String workerNamePrefix) { this.workerNamePrefix = workerNamePrefix; this.factory = factory; this.ueh = handler; this.config = (parallelism & SMASK) | mode; long np = (long)(-parallelism); // offset ctl counts this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK); }
6.fork方法
fork方法用于将新创建的子任务放入当前线程的work queue队列中,Fork/Join框架将根据当前正在并发执行ForkJoinTask任务的ForkJoinWorkerThread线程状态,
决定是让这个任务在队列中等待,还是创建一个新的ForkJoinWorkerThread线程运行它,又或者是唤起其它正在等待任务的ForkJoinWorkerThread线程运行它。
fork方法,将当前任务入池 ; 当我们调用ForkJoinTask的fork方法时,程序会把任务放在ForkJoinWorkerThread的pushTask的workQueue中,异步地执行这个任务,然后立即返回结果。
代码如下:
public final ForkJoinTask<V> fork() { Thread t;
//如果当前线程是ForkJoinWorkerThread,将任务压入该线程的任务队列 if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ((ForkJoinWorkerThread)t).workQueue.push(this); else
//否则调用common池的externalPush方法入队 ForkJoinPool.common.externalPush(this); return this; }
pushTask方法把当前任务存放在ForkJoinTask数组队列里。然后再调用ForkJoinPool的signalWork()方法唤醒或创建一个工作线程来执行任务。代码如下:
final void push(ForkJoinTask<?> task) { ForkJoinTask<?>[] a; ForkJoinPool p; int b = base, s = top, n; if ((a = array) != null) { // ignore if queue removed int m = a.length - 1; // fenced write for task visibility U.putOrderedObject(a, ((m & s) << ASHIFT) + ABASE, task); U.putOrderedInt(this, QTOP, s + 1); if ((n = s - b) <= 1) { if ((p = pool) != null) p.signalWork(p.workQueues, this); } else if (n >= m) growArray(); } }
7.join方法
join方法用于让当前线程阻塞,直到对应的子任务完成运行并返回执行结果。或者,如果这个子任务存在于当前线程的任务等待队列(work queue)中,则取出这个子任务进行“递归”执行。
其目的是尽快得到当前子任务的运行结果,然后继续执行。也就是让子任务先执行的意思。
public final V join() { int s;
//调用doJoin方法阻塞等待的结果不是NORMAL,说明有异常或取消.报告异常 if ((s = doJoin() & DONE_MASK) != NORMAL) reportException(s);
//等于NORMAL,正常执行完毕,返回原始结果 return getRawResult(); }
它首先调用doJoin方法,通过doJoin()方法得到当前任务的状态来判断返回什么结果,任务状态有4种:已完成(NORMAL)、被取消(CANCELLED)、信号(SIGNAL)和出现异常(EXCEPTIONAL)。
如果任务状态是已完成,则直接返回任务结果。
如果任务状态是被取消,则直接抛出CancellationException
如果任务状态是抛出异常,则直接抛出对应的异常
如果没有返回状态,会否则使用当线程池所在的ForkJoinPool的awaitJoin方法等待.
让我们分析一下doJoin方法的实现
private int doJoin() { int s; Thread t; ForkJoinWorkerThread wt; ForkJoinPool.WorkQueue w;
//已完成,返回status,未完成再尝试后续 return (s = status) < 0 ? s :
//未完成,当前线程是ForkJoinWorkerThread,从该线程中取出workQueue,并尝试将当前task出队然后执行,执行的结果是完成则返回状态,否则使用当线程池所在的ForkJoinPool的awaitJoin方法等待 ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ? (w = (wt = (ForkJoinWorkerThread)t).workQueue). tryUnpush(this) && (s = doExec()) < 0 ? s : wt.pool.awaitJoin(w, this, 0L) :
//当前线程不是ForkJoinWorkerThread,调用externalAwaitDone方法. externalAwaitDone(); } final int doExec() { int s; boolean completed; if ((s = status) >= 0) { try { completed = exec(); } catch (Throwable rex) { return setExceptionalCompletion(rex); } if (completed) s = setCompletion(NORMAL); } return s; }
在doJoin()方法里,首先通过查看任务的状态,看任务是否已经执行完成,如果执行完成,则直接返回任务状态;如果没有执行完,则从任务数组里取出任务并执行。
如果任务顺利执行完成,则设置任务状态为NORMAL,如果出现异常,则记录异常,并将任务状态设置为EXCEPTIONAL。
8.invoke方法
public final V invoke() { int s;
//先尝试执行 if ((s = doInvoke() & DONE_MASK) != NORMAL)
//doInvoke方法的结果status只保留完成态位表示非NORMAL,则报告异常 reportException(s);
//正常完成,返回原始结果. return getRawResult(); } //ForkJoinPool::awaitJoin,在该方法中使用循环的方式进行internalWait,满足了每次按截止时间或周期进行等待,同时也顺便解决了虚假唤醒 private int doInvoke() { int s; Thread t; ForkJoinWorkerThread wt; return (s = doExec()) < 0 ? s : ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ? (wt = (ForkJoinWorkerThread)t).pool. awaitJoin(wt.workQueue, this, 0L) : externalAwaitDone(); }
externalAwaitDone函数.它体现了ForkJoin框架的一个核心:外部帮助,
externalAwaitDone的逻辑不复杂,在当前task为ForkJoinPool.common的情况下可以在外部进行等待和尝试帮助完成.
方法会首先根据ForkJoinTask的类型进行尝试帮助,并返回当前的status,若发现未完成,则进入下面的等待唤醒逻辑.该方法的调用者为非worker线程.
//外部线程等待一个common池中的任务完成. private int externalAwaitDone() { int s = ((this instanceof CountedCompleter) ? //当前task是一个CountedCompleter,尝试使用common ForkJoinPool去外部帮助完成,并将完成状态返回. ForkJoinPool.common.externalHelpComplete( (CountedCompleter<?>)this, 0) : //当前task不是CountedCompleter,则调用common pool尝试外部弹出该任务并进行执行, //status赋值doExec函数的结果,若弹出失败(其他线程先行弹出)赋0. ForkJoinPool.common.tryExternalUnpush(this) ? doExec() : 0); if (s >= 0 && (s = status) >= 0) { //检查上一步的结果,即外部使用common池弹出并执行的结果(不是CountedCompleter的情况),或外部尝试帮助CountedCompleter完成的结果 //status大于0表示尝试帮助完成失败. //扰动标识,初值false boolean interrupted = false; do { //循环尝试,先给status标记SIGNAL标识,便于后续唤醒操作. if (U.compareAndSwapInt(this, STATUS, s, s | SIGNAL)) { synchronized (this) { if (status >= 0) { try { //CAS成功,进同步块发现double check未完成,则等待. wait(0L); } catch (InterruptedException ie) { //若在等待过程中发生了扰动,不停止等待,标记扰动. interrupted = true; } } else //进同步块发现已完成,则唤醒所有等待线程. notifyAll(); } } } while ((s = status) >= 0);//循环条件,task未完成. if (interrupted) //循环结束,若循环中间曾有扰动,则中断当前线程. Thread.currentThread().interrupt(); } //返回status return s; }
参考:https://www.cnblogs.com/wzqjy/p/7921063.html
https://blog.csdn.net/tyrroo/article/details/81390202
https://segmentfault.com/a/1190000019549838
https://www.cnblogs.com/senlinyang/p/7885964.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号