MySQL
1、初识MySQL
JavaEE:企业级Java开发
前端(页面:展示,数据)
后台(连接点:连接数据库JDBC,链接前端(控制,控制视图跳转和给前端传递数据))
数据库(存数据)
1.1、什么是数据库
数据库 DB DataBase
概念:数据仓库,安装在操作系统上的软件
作用:存储管理数据
1.2、数据库分类
关系型数据库:(SQL)
-
MySQL、Oracle、Sql Server、DB2、SQLlite
-
通过表和表之间、行和列之间的关系进行数据的存储
非关系型数据库:(NoSQL)
-
Redis,MongDB
-
存储对象,通过对象自身的属性来决定
DBMS(数据库管理系统)
-
数据库的管理软件,科学有效的管理数据,维护和获取数据
-
MySQL
1.3、MySQL
MySQL是一个关系型数据库管理系统
数据库中最基本的单元是表
任何一张表都有行和列,行被称为数据/记录,列被称为字段
1.4、安装MySQL
教程:
不需要手动创建data目录、日志存放目录处存在问题
卸载MySQL:第一步点安装程序进行卸载,第二步删除系统中的所有mysql文件夹
登陆MySQL:
1.5、SQL语句分类(要记)
-
DQL(Data Query Language):数据查询语言(带
select关键字的都是查询语句) -
DML(Data Manipulation Language):数据操作语言(增
insert,删delete,改update) -
DDL(Data Definition Language):数据定义语言(新建
create,删除drop,修改alter等操作表的结构的语句) -
TCL(Transactional Control Language):事务控制语言(事务提交
commit;,事务回滚rollback;) -
DCL(Data Control Language):数据控制语言(授权
grant,撤销权限revoke)
2.1、登陆退出
mysql中;表示语句结束
2.2、基本操作
2.3、简单查询
所有数据库中,字符串统一使用单引号,双引号在Oracle数据库中无法使用。
2.4、条件查询
查询出符合条件的数据
2.5、模糊查询
2.6、排序
排序总是在最后执行
2.7、DBA命令



3、函数
3.1、单行处理函数
数据处理函数也被称为单行处理函数,一个输入对应一个输出
多行处理函数也叫分组函数:多个输入对应一个输出
3.2、常见的单行处理函数
3.3、多行处理函数
多行处理函数也叫分组函数,输入多行,输出一行
分组函数在使用的时候必须先进行分组,然后才能使用
如果没有分组,整张表默认为一组
分组函数的使用注意事项:
-
分组函数自动忽略
NULL -
count(*)统计所有记录条数,count(字段)统计某个字段下不为NULL的值 -
分组函数不能直接在
where子句中使用 -
分组函数可以组合使用
3.4、分组查询(重要‼️)
先分组,再对每一组的数据进行操作
关键字的执行顺序(要记🌟):
from
where
group by
having
select
order by
从某张表中查询数据,先经过where条件筛选出有价值的数据,对这些数据进行group by分组,分组之后可以用having继续筛选,然后用select查询出来,最后order by排序输出
where执行的时候还没有分组,所以分组函数不能直接在where中使用
select后只能跟group by的类和分组函数
优化策略:选择where而不是having,即先选出所有sal>3000的,然后再分组,而不是先分组再选 (having在group by后执行);where实在完成不了再选择having。
3.5、连接查询(重要‼️)
跨表,多张表连接起来查询数据
连接查询根据语法年代分类可以分为SQL92和SQL99
根据表的连接方式分类可以分为:
-
内连接:等值连接、非等值连接、自连接
-
外连接:左(外)连接,右(外)连接
-
全连接
笛卡尔积:表连接查询通常的查询方法是用一张表的记录去和另一张表的所有记录进行配对比较,当连接查询没有任何查询条件限制时,会输出的记录数=两张表记录数的乘积。(记录数为n,m的两张表,连接查询的匹配次数为n*m)
减小表的连接次数也是提高效率优化的重要手段。
-
不同的连接查询语法(推荐使用SQL99)
-
内连接(只显示满足连接条件的数据)
-
外连接(除了满足条件的数据之外还显示其他数据)
-
连接多张表(以一张表为基础)
3.6、子查询
子查询:select语句中嵌套select语句,被嵌套的select称为子查询
3.7、union合并查询结果
union:合并查询结果集
使用union效率更高,用于表连接可以减少匹配的次数(将笛卡尔积变为加法运算)
要求结果合并时列数和列的数据类型相同
3.8、limit分页显示
取出查询结果集的一部分,通常用在分页查询中,提高用户体验
-
分页显示
-
DQL语句的执行顺序
-
from
-
where
-
group by
-
having
-
select
-
order by
-
limit
-
3.9、插入、删除、修改数据
-
插入数据
-
字段名和值的数量、数据类型都要对应
-
insert语句执行成功后必然会多一条记录 -
如果没有给其他字段指定值,默认为
null -
省略字段名相当于包括所有字段
-
一次可以插入多条记录
-
数据库的命名规范:所有标识符都使用小写,单词之间下划线连接
-
修改数据
-
不设置字段名表示更新整张表
-
-
删除数据
-
不设置条件会删除整张表!
-
delete语句删除效率低,删除后硬盘上的真实存储空间不会被释放,可以通过rollback恢复,属于DML语句 -
truncate语句能快速删除表的所有数据,但无法恢复,属于DDL操作
-
大数据的SQL执行优化时,可以尝试使用 merge into 代替 update 和 insert,对于已存在(符合on中的条件)的数据执⾏更新操作,不存在的数据执⾏插⼊操作。
4、表
4.1、创建表
表名建议以t_或tbl_开始,可读性强
-
MySql常见数据类型
-
varchar(最长255):可变长度字符串,根据传入数据动态分配空间,速度慢
-
char(最长11):定长字符串,分配固定长度的空间,速度快,可能会浪费空间,例如:性别字段
-
int:整数型(-2^31 (-2,147,483,648) 到 2^31 - 1 (2,147,483,647))
-
bigint:长整型(20位 9223372036854775807)
-
float:单精度浮点
-
double:双精度浮点
-
date:短日期(年月日),默认为
%Y-%m-%d -
datetime:长日期(年月日时分秒),默认为
%Y-%m-%d %h:%i:%s -
clob:字符大对象,最多可存储4G的字符串
-
blob:二进制大对象,存储图片声音视频等流媒体数据,插入数据要使用IO流
-
4.2、增加、删除、修改表结构
操作比较少,并且可以使用工具完成,不是重点
4.3、约束
约束是对表中的字段的限制,为了保证数据有效
-
约束包括:
-
非空约束:
not null字段值不能为空 -
唯一性约束:
unique字段值不能重复,但可以为null -
主键约束:
primary key(PK) (重要‼️)-
主键值是每一行记录的唯一标识
-
添加了主键约束的字段是主键字段,主键字段
not null且unique -
任何一张表都应该有且只有一个主键约束,没有主键的表无效
-
可以将多个字段联合起来做主键,称为复合主键(实际开发不建议使用)
-
-
外键约束:
foreign key(FK)(重要‼️)-
建立两张表之间的约束联系,例如限制cno只能为classno中的值(建立两张表是为了减少占用的空间)
-

foreign key(cno) references t_calss(classno),班级表为父表,学生表为子表,进行增删改时要考虑对父子表分别操作的先后顺序 -
外键值可以为null,被引用的父表中的字段至少应为unique
-
-
检查约束:
check(只有oracle支持)
-
如果一个字段同时被not null和unique约束,该字段主动变成主键字段
xxx.sql文件称为sql脚本文件,可以保存大量sql语句,通过source xxx/xxx/xxx.sql执行
5、存储引擎
5.1、什么是存储引擎
Mysql特有的术语,是表存储/组织数据的方式
5.2、常用存储引擎
-
MyISAM:
-
MyISAM 存储引擎是 MySQL 最常用的引擎。
-
它管理的表具有以下特征:
-
使用三个文件表示每个表:
-
格式文件 — 存储表结构的定义(mytable.frm)
-
数据文件 — 存储表行的内容(mytable.MYD)
-
索引文件 — 存储表上索引(mytable.MYI)
-
-
灵活的 AUTO_INCREMENT 字段处理
-
可被转换为压缩、只读表来节省空间(MyISAM的优势)
-
对一张表来说,只要是主键或有unique约束的字段会自动创建索引
-
不支持事务机制,安全性低
-
-
-
InnoDB:
-
mysql默认存储引擎,支持事务,支持数据库崩溃后自动恢复,非常安全
-
InnoDB 存储引擎是 MySQL 的缺省引擎。它管理的表具有下列主要特征:
-
每个 InnoDB 表在数据库目录中以.frm 格式文件表示
-
InnoDB 表空间 tablespace 被用于存储表的内容
-
提供一组用来记录事务性活动的日志文件
-
用 COMMIT(提交)、SAVEPOINT 及 ROLLBACK(回滚)支持事务处理(InnoDB的最大特点)
-
提供全 ACID 兼容
-
在 MySQL 服务器崩溃后提供自动恢复
-
多版本(MVCC)和行级锁定
-
支持外键及引用的完整性,包括级联删除和更新
-
-
-
MEMORY:
-
使用 MEMORY 存储引擎的表,其数据存储在内存中,且行的长度固定,这两个特点使得 MEMORY 存储引擎非常快。
-
MEMORY 存储引擎管理的表具有下列特征:
-
在数据库目录内,每个表均以.frm 格式的文件表示
-
表数据及索引被存储在内存中(查询速度快,但不安全,关机后消失)
-
表级锁机制
-
不能包含 TEXT 或 BLOB 字段
-
-
MEMORY 存储引擎以前被称为 HEAP 引擎
-
6、事务
6.1、什么是事务
一个事务transaction就是一个完整的业务逻辑,是最小的工作单元。
只有DML语句insert, delete, update与事务有关
有些操作需要多条DML语句共同联合起来才能完成,例如银行转账,多条DML语句需要同时成功或同时失败,所以需要事务
6.2、事务如何实现
InnoDB存储引擎提供了一组用来记录事务性活动的日志文件
事务执行过程中,每一条DML操作都会记录到事务性活动的日志文件中
提交事务:表示事务的(成功)结束,清空事务性活动的日志文件,将数据全部彻底持久化到数据库表中
回滚事务:表示事务的(失败)结束,撤销之前所有的DML操作,清空事务性活动的日志文件
mysql在默认情况下支持自动提交事务
-
事务的特性:
-
ACID(原子性、一致性、隔离性、持久性)
-
一致性:要求在同一个事务中所有操作必须同时成功或同时失败
-
隔离性:不同事务之间具有一定的隔离
-
持久性:事务提交就相当于将没有保存的数据进行保存
-
6.3、数据库的并发问题
-
数据库并发的三种并发问题:
-
脏读:对于两个事务 T1、T2,T1读取了已经被T2更新但还没有被提交的字段。之后,若 T2 回滚,T1读取的内容就是临时且无效的。
-
不可重复读:对于两个事务T1、T2,T1读取了一个字段,然后 T2 更新了该字段。之后,T1再次读取同一个字段,值就不同了。
-
幻读:对于两个事务T1、T2,T1从一个表中读取了一个字段,然后T2在该表中插入了一些新的行。之后,如果T1再次读取同一个表,就会多出几行。
-
6.4、事务隔离
-
事务隔离的级别(由低到高):
-
读未提交:read uncommitted (未提交就能读到)
-
事务A可以读取到事务B未提交的数据
-
存在脏读现象dirty read,即读到脏数据
-
-
读已提交:read committed (提交之后才能读到)
-
事务A只能读取到事务B提交之后的数据
-
解决了脏读的问题,但不可重复读取数据(多次读到的数据可能不同,因为中间经历了数据提交)
-
-
可重复读:repeatable read (提交之后也读不到,读取的永远都是开启事务时的数据)
-
事务A开启后,不管多久,每一次在事务A读取到的数据都是一致的,即使事务B已经将数据修改并提交。即事务A开启时创建一个副本。
-
mysql中默认的事物隔离级别
-
-
序列化/串行化:serializable
-
最高隔离级别,事务排队,不能并发
-
效率最低但都是真实数据
-
-
7、索引
7.1、索引原理
索引是在数据库表的字段上添加的,是为了提高查询效率的一种机制,一个字段或多个字段联合可以添加一个索引,索引缩小了查找的范围
任何数据库中主键上会自动添加索引对象

(以B-Tree形式存储
mysql中主键和unique字段都会自动添加索引(通过主键或unique字段查询效率最高)
需要添加索引的情况:1、数据量庞大;2、字段经常出现在where后面,总是被扫描;3、该字段很少DML操作,因为每次DML操作后索引都需要重新排序
7.2、索引的应用
-
创建删除索引
-
查看索引
-
索引失效
-
like %T以百分号开头的模糊查询不会使用索引,所以应该尽量避免 -
使用
or时会失效,除非两边的条件都有索引 -
使用复合索引时,没有使用左侧的列查找,索引失效
-
在where中索引列参加了运算,索引失效
-
在where中索引列使用了函数
-
优化思路:尽量不使用索引失效的情况,索引是数据库优化的重要手段,优化时应优先考虑索引
-
索引的分类
-
单一索引
-
复合索引
-
主键索引
-
唯一性索引(在唯一性比较弱的字段上添加索引用处不大,越唯一索引效率越高)
-
8、视图
8.1、什么是视图
view:从不同的角度看待同一份数据
只有DQL(即select)语句才能以view的形式创建
创建的视图对象可以当作表来使用
可以对视图对象进行增删改查,对视图的操作会影响到原表数据
8.2、视图的应用
创建视图可以临时保存多张表的查询结果

-
使用视图的优点:方便、简化开发、便于维护
-
将重复使用的,特别长的sql查询语句保存为视图对象,简化操作
-
有利于后期维护,修改时只需要修改映射的sql语句即可
-
视图可以当作table一样使用,存储在硬盘上,不会消失
-
9、数据库设计三范式
9.1、什么是数据库设计范式
设计范式:数据库表的设计依据
-
数据库设计范式共有三个:
-
要求任何一个表必须有主键,每一个字段有原子性,不可再分;
-
建立在第一范式基础上,要求所有非主键字段完全依赖主键,不要产生部分依赖;
-
建立在第二范式基础上,要求所有非主键字段直接依赖主键,不要产生传递依赖
-
按照范式进行设计,可以避免表中数据的冗余和空间的浪费
9.2、第一范式
“任何一个表必须有主键,每一个字段有原子性,不可再分”
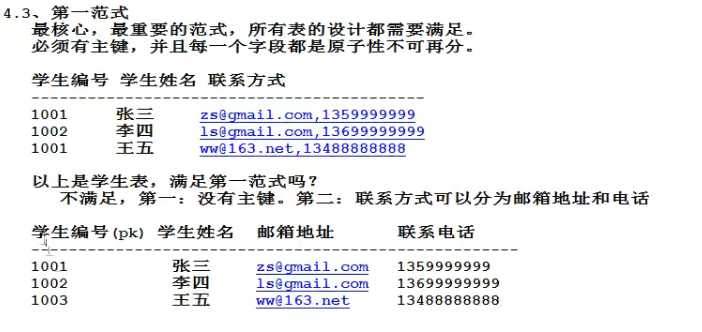
最核心最重要的范式,所有表的设计都需要满足。
9.3、第二范式
“建立在第一范式基础上,要求所有非主键字段完全依赖主键,不要产生部分依赖”

产生部分依赖的缺点:数据冗余,空间浪费(如张三这个数据出现了两次)
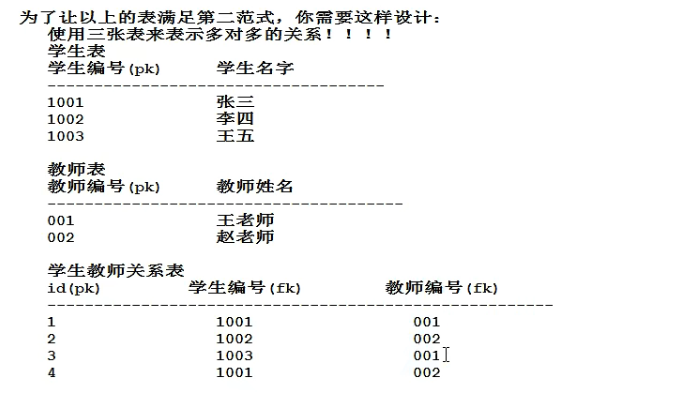
多对多关系设计数据库:三张表,关系表两个外键
9.4、第三范式
“建立在第二范式基础上,要求所有非主键字段直接依赖主键,不要产生传递依赖”


一对多关系设计数据库:两张表,多的表加外键
9.5、总结
-
一对一:外键唯一
-
通常用一张表,但如果字段太多表太庞大,建议拆分成多张表
-
拆分表很少使用主键共享策略,一般是添加一个unique的外键
-
-
一对多:两张表,多的表加外键
-
多对多:三张表,关系表两个外键

实际设计数据库要根据客户需求
表和表的连接次数越多效率越低,有的时候为了减少表的连接次数,可以允许一定程度的冗余存在,对开发人员来说这样也会使sql语句的编写难度降低
__EOF__

本文链接:https://www.cnblogs.com/colinpersonalblog/p/16641530.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异