Redis
1、NoSQL数据库简介
1.1、技术发展
技术的分类:
-
解决功能性的问题:Java、Jsp、RDBMS、Tomcat、HTML、Linux、JDBC、SVN
-
解决扩展性的问题:Struts、Spring、SpringMVC、Hibernate、Mybatis
-
解决性能的问题:NoSQL、Java线程、Hadoop、Nginx、MQ、ElasticSearch
NoSQL的优点:
-
直接存储在内存中,减少CPU和存储的压力
-
能直接作为缓存使用,减少IO操作次数
1.2、NoSQL数据库
1.2.1、NoSQL数据库的特点
非关系型数据库,以简单的 key-value 模式存储
不遵循SQL标准,不支持ACID,性能远超SQL
1.2.2、NoSQL数据库的适用场景
高并发、海量数据、高可扩展性
NoSQL不适用的场景:需要事务支持的情况,或需要处理复杂关系的情况
(不需要用sql或用sql处理不了的情况,都可以考虑用nosql)
1.2.3、常见的NoSQL数据库
MemCache:不持久化,支持类型单一,一般作为sql数据库的辅助
Redis:覆盖了MemCache的绝大部分功能,支持持久化,支持多种数据结构存储
MongoDB:文档型数据库,类似json
2、Redis6概述和安装
Redis是一个开源的key-value存储系统。
和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。
这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。
在此基础上,Redis支持各种不同方式的排序。
与memcached一样,为了保证效率,数据都是缓存在内存中。
区别的是Redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件。
并且在此基础上实现了master-slave(主从)同步。
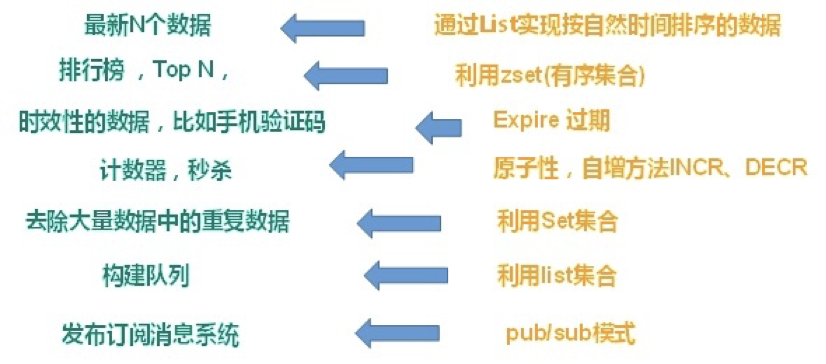
2.1、应用场景
-
配合关系型数据库做高速缓存
-
处理高频次,热门的访问数据,从而降低数据库IO
-
分布式架构,做session共享
-
-
多样的数据结构存储持久化数据
2.2、安装Redis
Redis在linux系统下使用,需要先安装gcc
2.2.1、使用Docker配置
# 获取镜像
docker pull redis:latest
# 运行容器(将容器命名为docker-redis,公开6379端口,开启AOF)
docker run -d -p 6379:6379 --name docker-redis redis --appendonly yes
# 在运行中的容器中用 -it 选项来启动一个新的交互式会话
docker exec -it docker-redis /bin/bash
# 运行redis-cli(使redis在后台运行)
redis-cli
redis默认是没有配置的,需要手动添加配置 redis.conf (官网有提供下载)
http://www.zzvips.com/article/175222.html
redis.conf 的主要配置如下:
bind 127.0.0.1 #注释掉这部分,使redis可以外部访问
daemonize no #用守护线程的方式启动
requirepass xxx #给redis设置密码
appendonly yes #redis持久化,默认是no
tcp-keepalive 300 #防止出现远程主机强迫关闭了一个现有的连接的错误 默认是300
2.2.2、查看安装目录
redis-benchmark:性能测试工具
redis-check-aof:修复有问题的AOF文件,rdb和aof后面讲
redis-check-dump:修复有问题的dump.rdb文件
redis-sentinel:Redis集群使用
redis-server:Redis服务器启动命令
redis-cli:客户端,操作入口
2.2.3、前台启动
redis-server
2.2.4、后台启动(推荐)
首先备份配置文件 redis.conf ,然后将 redis.conf 中的 daemonize no 改为 daemonize yes 允许后台启动(在docker容器中运行redis可以省略这一步)
# 启动redis
redis-server /myredis/redis.conf
# 使用客户端访问
redis-cli
# 测试(返回PONG说明连接正常)
ping
# 退出客户端
quit
2.2.5、关闭redis
单实例关闭:redis-cli shutdown
多实例关闭,指定端口关闭:redis-cli -p 6379 shutdown
2.3、Redis相关知识介绍
2.3.1、6379端口
默认有16个数据库,类似数组下标从0开始,初始默认使用0号库
使用命令 select <dbid> 来切换数据库。如: select 8
统一密码管理,所有库同样密码。
dbsize查看当前数据库的key的数量
flushdb清空当前库
flushall通杀全部库
2.3.2、单线程+多路IO复用技术
多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)
Memcache使用的是多线程+锁机制
3、常用五大数据类型
http://www.redis.cn/commands.html
3.0、数据库操作
# 切换数据库
select 1
# 查看当前数据库的key的数量
dbsize
# 清空当前数据库
flushdb
# 清空所有数据库
flushall
3.1、键 key
# keys 查询
# 查询当前库中所有的key
keys *
# 判断某个key是否存在,存在返回1,不存在返回0
exists key1
# 查看键的类型
type key1
# 删除指定的键对应的键值对
del key1
# 非阻塞删除(仅将keys从keyspace元数据中删除,真正的删除在后续异步操作中)
unlink key1
# 设置key的过期时间(单位是秒)
expire key1 10
# 查看key还有多久过期(-1表示永不过期,-2表示已过期)
ttl key1
3.2、字符串 String
3.2.1、简介
String类型是二进制安全的。意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
String类型是Redis最基本的数据类型,一个Redis中字符串value最多可以是512M
3.2.2、常用命令
# set 设置键值对
# set <key> <value> [EX seconds|PX milliseconds|KEEPTTL] [NX|XX]
# 如果key不存在,则向数据库中添加key-value键值对
# 如果key存在,则重新设置其value
set key1 value1
# setnx 只有key不存在时才设置key的值
# setnx <key> <value>
setnx key2 value2
# setex 设置值的同时设置过期时间
# setex <key><过期时间><value>
# getset 获取旧值的同时设置新值
# getset <key><value>
参数说明:
*NX:当数据库中key不存在时,可以将key-value添加数据库
*XX:当数据库中key存在时,可以将key-value添加数据库,与NX参数互斥
*EX:key的超时秒数
*PX:key的超时毫秒数,与EX互斥
# get 获取value
# get <key>
get key1
# append 将value1添加到value的末尾
# append <key> <value>
append key1 value1
# strlen 获取值的长度
# strlen <key>
strlen key1
# incr 使数字值+1(如果值为空则设置为1)
incr k3
# decr 使数字值-1(如果值为空则设置为-1)
decr k3
# incrby / decrby 使数字值+n
incrby k3 100
decrby k3 50
Redis是单线程的,所有操作都具有原子性,所以以下命令msetnx中,只要有一个失败,这条命令就会失败
# mset 同时设置多个key-value
# mset <key1><value1> <key2><value2>
mset k4 1 k5 2
# mget 同时获取多个key的value
# mget <key1><key2>
mget k4 k5
# msetnx 同时设置多个新的key-value(如果key存在则失败)
# msetnx <key1> <value1> <key2> <value2>
msetnx k6 6 k7 7
# getrange 获取一定范围内的值(类似substring)
# getrange <key><起始位置><结束位置>
# setrange 设置一定范围内的值
# setrange <key><起始位置><value>
3.2.3、数据结构
String的数据结构为简单动态字符串(Simple Dynamic String,缩写SDS)。是可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配.

如图中所示,内部为当前字符串实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M。
3.3、列表 list
3.3.1、简介
单键多值
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差
3.3.2、常用命令
# lpush/rpush 从左边/右边插入多个值
# lpush <key> <value1> <value2>
lpush k1 v1 v2 v3
# lpop/rpop 从左边/右边弹出一个值(当键中所有值被弹出后,键被删除)
lpop k1
# rpoplpush 从list1右边弹出一个值,添加到list2左边
# rpoplpush <key1> <key2>
rpoplpush k1 k2
# lrange 按照下标获取元素(左边第一个为0,右边第一个为-1)
# lrange <key> <start> <stop>
lrange k1 0 -1
# lindex 根据下标获取元素
# lindex <key> <index>
lindex k1 2
# llen 获取列表长度
# llen <key>
llen k1
# linsert 向列表中插入值
# linsert <key> before <value> <newvalue> (在value后面插入new value)
linsert k1 before 2 4
# lrem 从左边删除
# lrem <key> <n> <value> 从左边开始删除n个值为value的元素
lrem k1 2 2
# lset 替换列表中指定下标的值
# lset <key> <index> <value>
lset k1 2 6
3.3.3、数据结构
List的数据结构为快速链表quickList。
在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。
当数据量比较多的时候才会改成quicklist,将多个ziplist组成一个链。因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。

Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
3.4、集合 set
3.4.1、简介
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口。
Redis的Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)。
3.4.2、常用命令
# sadd 添加元素到集合set中(已存在的元素会被自动忽略)
# sadd <key> <value1> <value2>
sadd s1 1 2 3 4 1
# smembers 取出集合所有的值
# smembers <key>
smembers s1
# sismember 判断集合中是否有value值(有返回1,无返回0)
# sismember <key> <value>
sismember s1 2
# scard 返回集合的元素个数
# scard <key>
scard s1
# srem 删除集合中的某个元素
# srem <key> <value1> <value2>
srem s1 1 2
# spop 随机弹出集合中的一个值
# spop <key>
spop s1
# srandmember 随机取出集合中的n个值,但不删除
# srandmember <key> <n>
srandmember s1 2
# smove 将集合中的一个值value移动到另一个集合(如果目标集合不存在则自动创建)
# smove <source> <destination> <value>
smove s1 s2 1
# sinter 返回两个集合的交集元素
# sinter <key1> <key2>
sinter s1 s2
# sunion 返回两个集合的并集元素
# sunion <key1> <key2>
sunion s1 s2
# sdiff 返回两个集合的差集元素(key1中存在,key2中不存在的元素)
# sdiff <key1> <key2>
sdiff s1 s2
3.4.3、数据结构
Set数据结构是dict字典,字典是用哈希表实现的。
Java中HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
3.5、哈希 Hash
3.5.1、简介
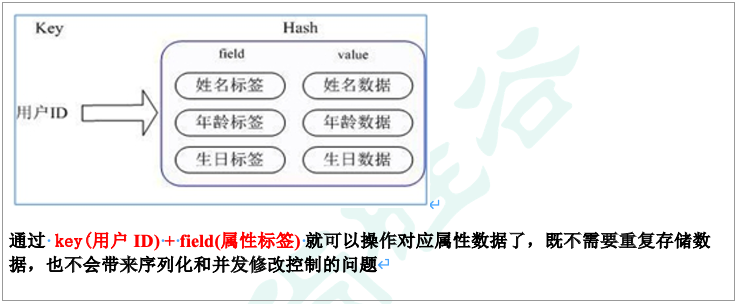
Redis hash 是一个键值对集合。
Redis hash 中的 value 是一个 string 类型的 field 和 value 的映射表,hash特别适合用于存储对象。
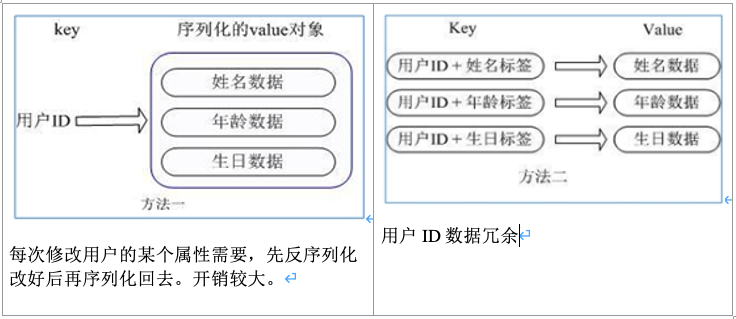
例如:用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息
普通存储方式:
Redis hash 的存储方式:
3.5.2、常用命令
# hset 对集合中的field赋值value
# hset <key> <field> <value>
hset user1 age 22
# hget 从集合的field取出value
# hget <key> <field>
hget user1 age
# hmset 批量设置hash的值field和value
# hmset <key> <field1> <value1> <field2> <value2>
hmset user1 name zhangsan age 22
# hexists 查看哈希表的key中是否存在特定的field
# hexists <key> <field>
hexists user1 age
# hkeys 列出该hash集合key所有的field
# hkeys <key>
hkeys user1
# hvals 列出该hash集合key所有的value
# hvals <key>
hvals user1
# hincrby 为hash集合中某个key的某个field加上增量
# hincrby <key> <field> <increment>
hincrby user1 age 1
# hsetnx 仅当field不存在时,将hash集合中field的值设置为value
# hsetnx <key> <field> <value>
hsetnx user1 birth 19980101
3.5.3、数据结构
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable。
3.6、有序集合 Zset
3.6.1、简介
有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。
不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复的。
因为元素是有序的, 所以可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
3.6.2、常用命令
# zadd 将一个或多个key-value及其score加入到有序集合中
# zadd <key><score1><value1> <score2><value2>
zadd k1 1 1 2 2
# zrange 返回有序集合中下标在start和stop之间的值(加上withscore可以同时返回分数和值)
# zrange <key> <start> <stop> [withscores]
zrange k1 0 -1
zrange k1 0 -1 withscore
# zrangebyscore 返回有序集合中score在min和max之间的值(从小到大排列)
# zrevrangebyscore 返回有序集合中score在min和max之间的值(从大到小排列)
# zrangebyscore <key> <min> <max> [withscore]
zrangebyscore k1 1 3
# zincrby 为值对应的score加上增量
# zincrby <key> <increment> <value>
zincrby k1 2 1
# zrem 删除集合中的指定值
# zrem <key> <value>
zrem k1 1
# zcount 统计集合中分数在min和max区间的值的个数
# zcount <key> <min> <max>
zcount k1 0 1
# zrank 返回某个值在集合中的排名(从0开始)
# zrank <key> <value>
zrank k1 2
zset的一个应用案例:文章访问量排行榜
3.6.3、数据结构
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map<String, Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层使用了两个数据结构: (1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。 (2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
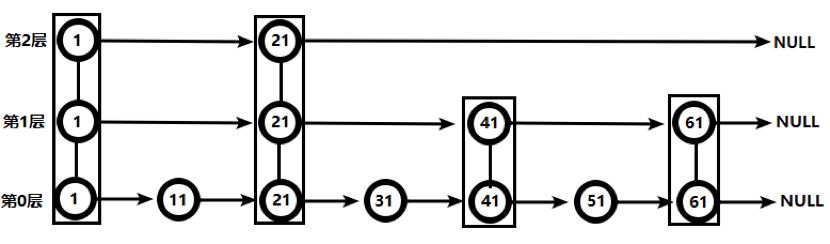
3.6.4、跳跃表
平衡树或红黑树虽然效率高但结构复杂;链表查询需要遍历所有效率低。Redis采用的是跳跃表。跳跃表效率堪比红黑树,实现远比红黑树简单。
以寻找51这个值为例:
有序链表(共比较6次)

跳跃表(共比较4次)
4、Redis6配置文件详解
直接安装的redis配置文件路径为/opt/redis-3.2.5/redis.conf
使用docker的方式安装的redis默认没有配置文件,因此,需要去redis的官方网站下载对应版本的redis,使用里面的配置文件即可
4.1、Units
配置大小单位,只支持bytes不支持bit
对大小写不敏感
# Redis configuration file example.
#
# Note that in order to read the configuration file, Redis must be
# started with the file path as first argument:
#
# ./redis-server /path/to/redis.conf
# Note on units: when memory size is needed, it is possible to specify
# it in the usual form of 1k 5GB 4M and so forth:
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
#
# units are case insensitive so 1GB 1Gb 1gB are all the same.
4.2、include
包含公用部分
多实例的情况可以把公用的配置文件提取出来
################################## INCLUDES ###################################
# Include one or more other config files here. This is useful if you
# have a standard template that goes to all Redis servers but also need
# to customize a few per-server settings. Include files can include
# other files, so use this wisely.
#
# Notice option "include" won't be rewritten by command "CONFIG REWRITE"
# from admin or Redis Sentinel. Since Redis always uses the last processed
# line as value of a configuration directive, you'd better put includes
# at the beginning of this file to avoid overwriting config change at runtime.
#
# If instead you are interested in using includes to override configuration
# options, it is better to use include as the last line.
#
# include /path/to/local.conf
# include /path/to/other.conf
4.3、modules
################################## MODULES #####################################
# Load modules at startup. If the server is not able to load modules
# it will abort. It is possible to use multiple loadmodule directives.
#
# loadmodule /path/to/my_module.so
# loadmodule /path/to/other_module.so
4.4、network
################################## NETWORK #####################################
# By default, if no "bind" configuration directive is specified, Redis listens
# for connections from all the network interfaces available on the server.
# It is possible to listen to just one or multiple selected interfaces using
# the "bind" configuration directive, followed by one or more IP addresses.
#
# Examples:
#
# bind 192.168.1.100 10.0.0.1
# bind 127.0.0.1 ::1
#
# ~~~ WARNING ~~~ If the computer running Redis is directly exposed to the
# internet, binding to all the interfaces is dangerous and will expose the
# instance to everybody on the internet. So by default we uncomment the
# following bind directive, that will force Redis to listen only into
# the IPv4 loopback interface address (this means Redis will be able to
# accept connections only from clients running into the same computer it
# is running).
#
# IF YOU ARE SURE YOU WANT YOUR INSTANCE TO LISTEN TO ALL THE INTERFACES
# JUST COMMENT THE FOLLOWING LINE.
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# =============================================
# 默认情况bind=127.0.0.1表示只能接受本机的访问请求
# 不说明bind则表示无限制接受任何ip地址的访问
bind 127.0.0.1
# Protected mode is a layer of security protection, in order to avoid that
# Redis instances left open on the internet are accessed and exploited.
#
# When protected mode is on and if:
#
# 1) The server is not binding explicitly to a set of addresses using the
# "bind" directive.
# 2) No password is configured.
#
# The server only accepts connections from clients connecting from the
# IPv4 and IPv6 loopback addresses 127.0.0.1 and ::1, and from Unix domain
# sockets.
#
# By default protected mode is enabled. You should disable it only if
# you are sure you want clients from other hosts to connect to Redis
# even if no authentication is configured, nor a specific set of interfaces
# are explicitly listed using the "bind" directive.
# =============================================
# 保护模式,如果开启了protected-mode,那么在没有设定bind ip且没有设密码的情况下,Redis只允许接受本机的响应
protected-mode yes
# Accept connections on the specified port, default is 6379 (IANA #815344).
# If port 0 is specified Redis will not listen on a TCP socket.
# =============================================
# 端口号,默认6379不需要改变
port 6379
# TCP listen() backlog.
#
# In high requests-per-second environments you need an high backlog in order
# to avoid slow clients connections issues. Note that the Linux kernel
# will silently truncate it to the value of /proc/sys/net/core/somaxconn so
# make sure to raise both the value of somaxconn and tcp_max_syn_backlog
# in order to get the desired effect.
# =============================================
# 设置tcp的backlog,backlog其实是一个连接队列,backlog队列总和=未完成三次握手队列 + 已经完成三次握手队列。
# 在高并发环境下需要一个高backlog值来避免慢客户端连接问题。
# 注意Linux内核会将这个值减小到/proc/sys/net/core/somaxconn的值(128),所以需要确认增大/proc/sys/net/core/somaxconn和/proc/sys/net/ipv4/tcp_max_syn_backlog(128)两个值来达到想要的效果
tcp-backlog 511
# Unix socket.
#
# Specify the path for the Unix socket that will be used to listen for
# incoming connections. There is no default, so Redis will not listen
# on a unix socket when not specified.
#
# unixsocket /tmp/redis.sock
# unixsocketperm 700
# Close the connection after a client is idle for N seconds (0 to disable)
# =============================================
# 一个空闲的客户端维持多少秒会关闭,0表示关闭该功能。即永不关闭。
timeout 0
# TCP keepalive.
#
# If non-zero, use SO_KEEPALIVE to send TCP ACKs to clients in absence
# of communication. This is useful for two reasons:
#
# 1) Detect dead peers.
# 2) Take the connection alive from the point of view of network
# equipment in the middle.
#
# On Linux, the specified value (in seconds) is the period used to send ACKs.
# Note that to close the connection the double of the time is needed.
# On other kernels the period depends on the kernel configuration.
#
# A reasonable value for this option is 300 seconds, which is the new
# Redis default starting with Redis 3.2.1.
# =============================================
# 对访问客户端的一种心跳检测,每个n秒检测一次。单位为秒,如果设置为0,则不会进行Keepalive检测,建议设置成60
tcp-keepalive 300
4.6、general
# By default Redis does not run as a daemon. Use 'yes' if you need it.
# Note that Redis will write a pid file in /var/run/redis.pid when daemonized.
# =============================================
# 是否为后台进程,应更改为yes
daemonize no
# If you run Redis from upstart or systemd, Redis can interact with your
# supervision tree. Options:
# supervised no - no supervision interaction
# supervised upstart - signal upstart by putting Redis into SIGSTOP mode
# supervised systemd - signal systemd by writing READY=1 to $NOTIFY_SOCKET
# supervised auto - detect upstart or systemd method based on
# UPSTART_JOB or NOTIFY_SOCKET environment variables
# Note: these supervision methods only signal "process is ready."
# They do not enable continuous liveness pings back to your supervisor.
supervised no
# If a pid file is specified, Redis writes it where specified at startup
# and removes it at exit.
#
# When the server runs non daemonized, no pid file is created if none is
# specified in the configuration. When the server is daemonized, the pid file
# is used even if not specified, defaulting to "/var/run/redis.pid".
#
# Creating a pid file is best effort: if Redis is not able to create it
# nothing bad happens, the server will start and run normally.
# =============================================
# 存放pid文件的位置,每个实例会产生一个不同的pid文件
pidfile /var/run/redis_6379.pid
# Specify the server verbosity level.
# This can be one of:
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably)
# warning (only very important / critical messages are logged)
# =============================================
# 指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为notice,四个级别根据使用阶段来选择,生产环境选择notice 或者warning
loglevel notice
# Specify the log file name. Also the empty string can be used to force
# Redis to log on the standard output. Note that if you use standard
# output for logging but daemonize, logs will be sent to /dev/null
# =============================================
# 日志文件路径和名称
logfile ""
# To enable logging to the system logger, just set 'syslog-enabled' to yes,
# and optionally update the other syslog parameters to suit your needs.
# syslog-enabled no
# Specify the syslog identity.
# syslog-ident redis
# Specify the syslog facility. Must be USER or between LOCAL0-LOCAL7.
# syslog-facility local0
# Set the number of databases. The default database is DB 0, you can select
# a different one on a per-connection basis using SELECT <dbid> where
# dbid is a number between 0 and 'databases'-1
# =============================================
# 设定库的数量,默认16,默认数据库为0,可以使用SELECT <dbid>命令在连接上指定数据库id
databases 16
# By default Redis shows an ASCII art logo only when started to log to the
# standard output and if the standard output is a TTY. Basically this means
# that normally a logo is displayed only in interactive sessions.
#
# However it is possible to force the pre-4.0 behavior and always show a
# ASCII art logo in startup logs by setting the following option to yes.
always-show-logo yes
4.7、SNAPSHOTTING
4.8、REPLICATION
4.9、KEYS TRACKING
4.10、SECURITY
# Warning: since Redis is pretty fast an outside user can try up to
# 1 million passwords per second against a modern box. This means that you
# should use very strong passwords, otherwise they will be very easy to break.
# Note that because the password is really a shared secret between the client
# and the server, and should not be memorized by any human, the password
# can be easily a long string from /dev/urandom or whatever, so by using a
# long and unguessable password no brute force attack will be possible.
# Redis ACL users are defined in the following format:
#
# user <username> ... acl rules ...
#
# For example:
#
# user worker +@list +@connection ~jobs:* on >ffa9203c493aa99
#
# The special username "default" is used for new connections. If this user
# has the "nopass" rule, then new connections will be immediately authenticated
# as the "default" user without the need of any password provided via the
# AUTH command. Otherwise if the "default" user is not flagged with "nopass"
# the connections will start in not authenticated state, and will require
# AUTH (or the HELLO command AUTH option) in order to be authenticated and
# start to work.
#
# The ACL rules that describe what an user can do are the following:
#
# on Enable the user: it is possible to authenticate as this user.
# off Disable the user: it's no longer possible to authenticate
# with this user, however the already authenticated connections
# will still work.
# +<command> Allow the execution of that command
# -<command> Disallow the execution of that command
# +@<category> Allow the execution of all the commands in such category
# with valid categories are like @admin, @set, @sortedset, ...
# and so forth, see the full list in the server.c file where
# the Redis command table is described and defined.
# The special category @all means all the commands, but currently
# present in the server, and that will be loaded in the future
# via modules.
# +<command>|subcommand Allow a specific subcommand of an otherwise
# disabled command. Note that this form is not
# allowed as negative like -DEBUG|SEGFAULT, but
# only additive starting with "+".
# allcommands Alias for +@all. Note that it implies the ability to execute
# all the future commands loaded via the modules system.
# nocommands Alias for -@all.
# ~<pattern> Add a pattern of keys that can be mentioned as part of
# commands. For instance ~* allows all the keys. The pattern
# is a glob-style pattern like the one of KEYS.
# It is possible to specify multiple patterns.
# allkeys Alias for ~*
# resetkeys Flush the list of allowed keys patterns.
# ><password> Add this passowrd to the list of valid password for the user.
# For example >mypass will add "mypass" to the list.
# This directive clears the "nopass" flag (see later).
# <<password> Remove this password from the list of valid passwords.
# nopass All the set passwords of the user are removed, and the user
# is flagged as requiring no password: it means that every
# password will work against this user. If this directive is
# used for the default user, every new connection will be
# immediately authenticated with the default user without
# any explicit AUTH command required. Note that the "resetpass"
# directive will clear this condition.
# resetpass Flush the list of allowed passwords. Moreover removes the
# "nopass" status. After "resetpass" the user has no associated
# passwords and there is no way to authenticate without adding
# some password (or setting it as "nopass" later).
# reset Performs the following actions: resetpass, resetkeys, off,
# -@all. The user returns to the same state it has immediately
# after its creation.
#
# ACL rules can be specified in any order: for instance you can start with
# passwords, then flags, or key patterns. However note that the additive
# and subtractive rules will CHANGE MEANING depending on the ordering.
# For instance see the following example:
#
# user alice on +@all -DEBUG ~* >somepassword
#
# This will allow "alice" to use all the commands with the exception of the
# DEBUG command, since +@all added all the commands to the set of the commands
# alice can use, and later DEBUG was removed. However if we invert the order
# of two ACL rules the result will be different:
#
# user alice on -DEBUG +@all ~* >somepassword
#
# Now DEBUG was removed when alice had yet no commands in the set of allowed
# commands, later all the commands are added, so the user will be able to
# execute everything.
#
# Basically ACL rules are processed left-to-right.
#
# For more information about ACL configuration please refer to
# the Redis web site at https://redis.io/topics/acl
# ACL LOG
#
# The ACL Log tracks failed commands and authentication events associated
# with ACLs. The ACL Log is useful to troubleshoot failed commands blocked
# by ACLs. The ACL Log is stored in memory. You can reclaim memory with
# ACL LOG RESET. Define the maximum entry length of the ACL Log below.
acllog-max-len 128
# Using an external ACL file
#
# Instead of configuring users here in this file, it is possible to use
# a stand-alone file just listing users. The two methods cannot be mixed:
# if you configure users here and at the same time you activate the exteranl
# ACL file, the server will refuse to start.
#
# The format of the external ACL user file is exactly the same as the
# format that is used inside redis.conf to describe users.
#
# aclfile /etc/redis/users.acl
# IMPORTANT NOTE: starting with Redis 6 "requirepass" is just a compatiblity
# layer on top of the new ACL system. The option effect will be just setting
# the password for the default user. Clients will still authenticate using
# AUTH <password> as usually, or more explicitly with AUTH default <password>
# if they follow the new protocol: both will work.
#
# requirepass foobared
# =============================================