spark源码阅读---Utils.getCallSite
1 作用
当该方法在spark内部代码中调用时,会返回当前调用spark代码的用户类的名称,以及其所调用的spark方法。所谓用户类,就是我们这些用户使用spark api的类。
2 内部实现
2.1 涉及到的java或scala知识
(1)Thread.currentThread.getStackTrace():返回一个表示该线程堆栈转储的堆栈跟踪元素数组。如果该线程尚未启动或已经终止,则该方法将返回一个零长度数组。如果返回的数组不是零长度的,则其第一个元素代表堆栈顶,它是该序列中最新的方法调用。最后一个元素代表堆栈底,是该序列中最旧的方法调用。返回数组的每个元素是一个StackTraceElement对象,存储了该方法由哪个类声明,方法名,以及文件名,文件第几行。如下:

(2)System.getProperty():返回一个系统属性值,其实就是一个配置参数值。
(3)case class:是scala中一种特殊的class。
2.2 spark源码部分
(1)该方法传入一个参数skipClass函数,用来判断哪些类名需要跳过,默认的判断函数也在Utils文件内部,如下:
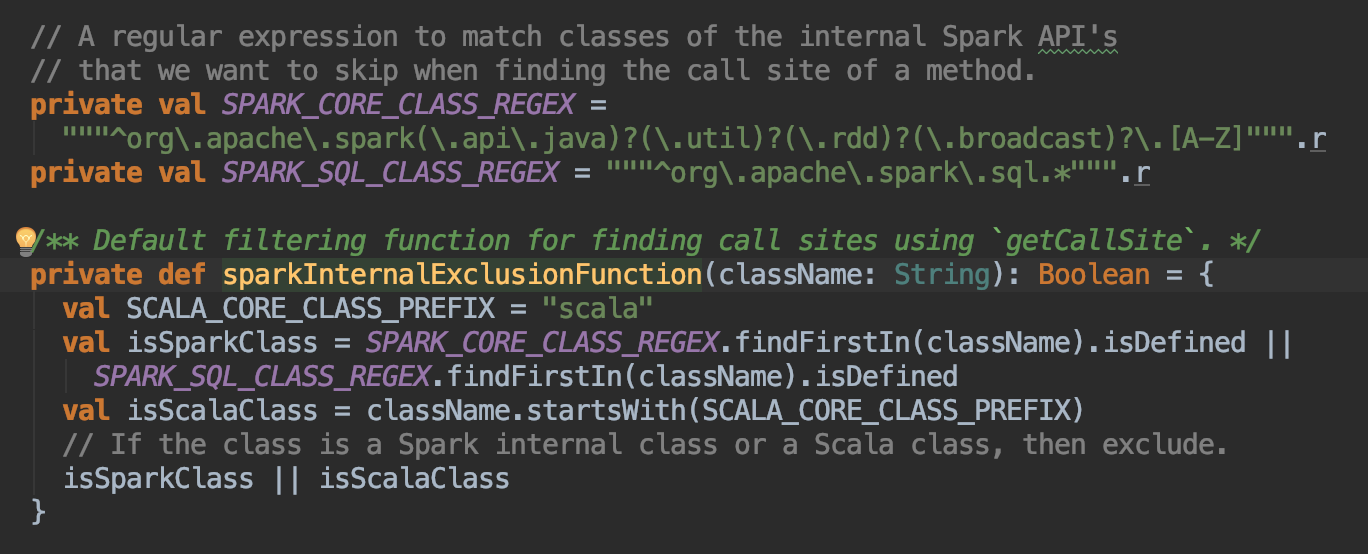
可见,默认的判断函数是通过正则表达式来判断的,其将会过滤出spark和scala的原生类。
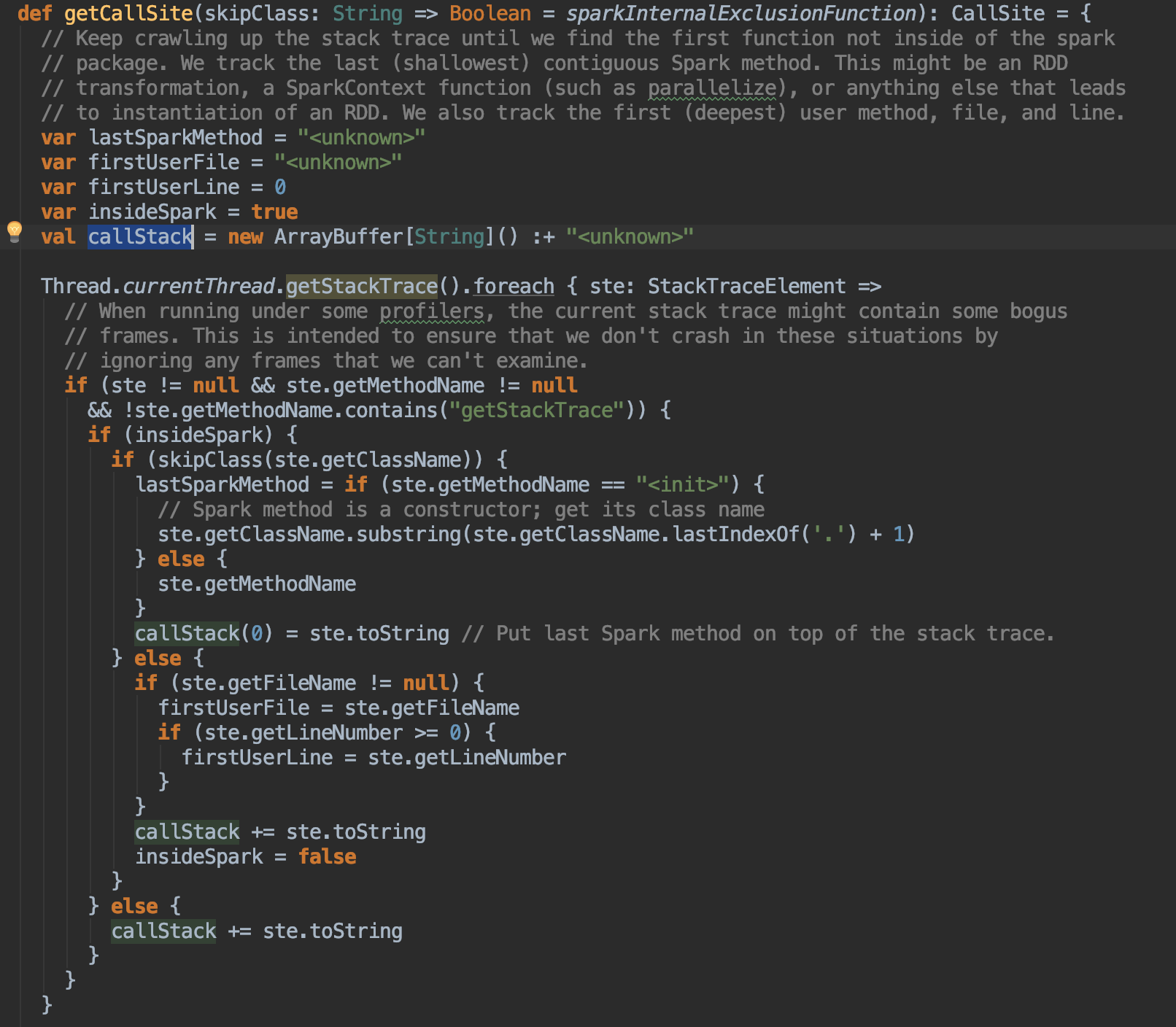
(2)该方法维护了lastSparkMethod以及firstUserFile,firstUserLine,callStack。其中lastSparkMethod是表示直接被用户api调用的spark方法,firstUserFile是最深的(直接调用spark api的)用户方法的文件名,callStack存储了调用栈信息,callStack[0]就是lastSparkMethod,其后为所有的用户方法。源码如下:
(3)该方法的最后工作,是根据上面得到的信息封装一个CallSite类:

CallSite类是一个case class:
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号