CDH故障解决过程记录(无法找到主机的NTP 服务,或该服务未响应时钟偏差请求)
先说结论吧:集群意外宕机重启后异常,如果以前运行正常没有配置错误的话,优先考虑重新cdh agent服务,很可能是它在作妖。
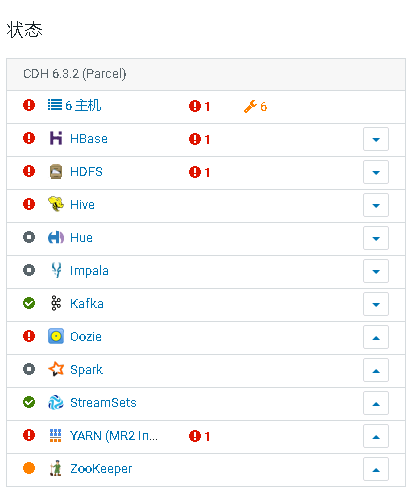
现象:服务器所在机房因意外断电,等待了大半天后恢复。登录CDH一看,发现集群重启后出现了一堆服务状态不良,HBase也没法用了:
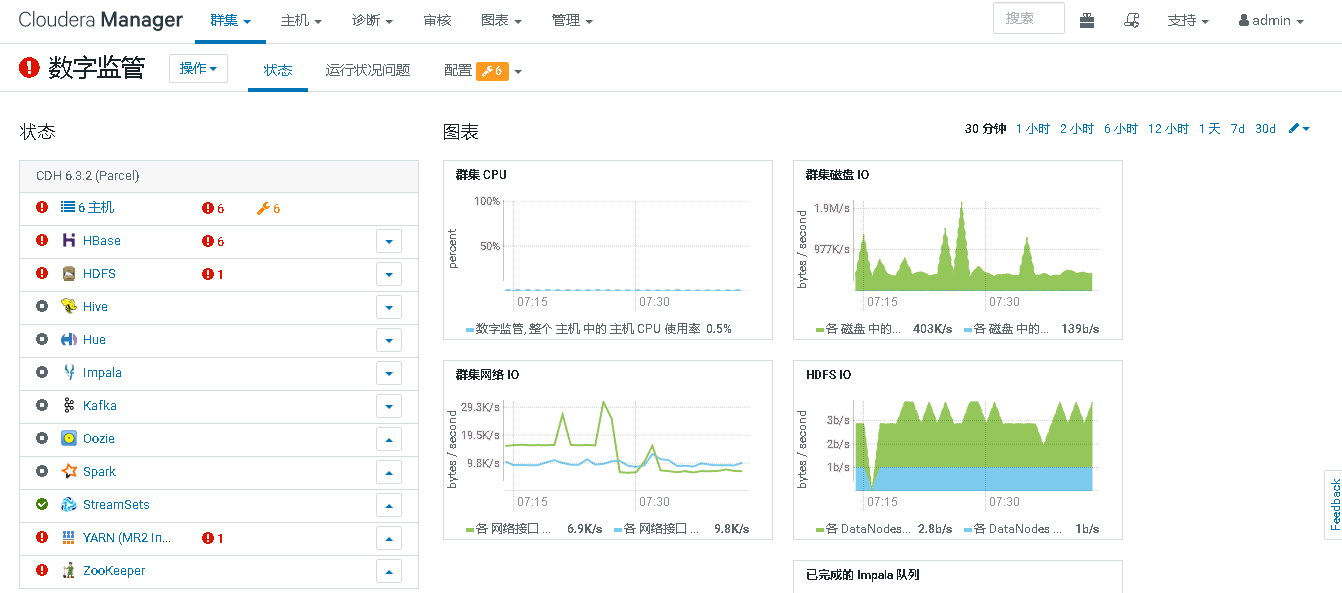
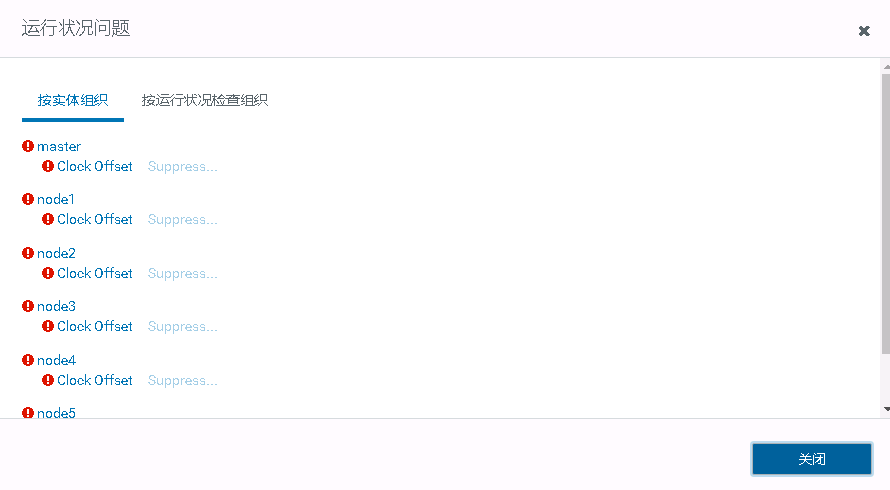
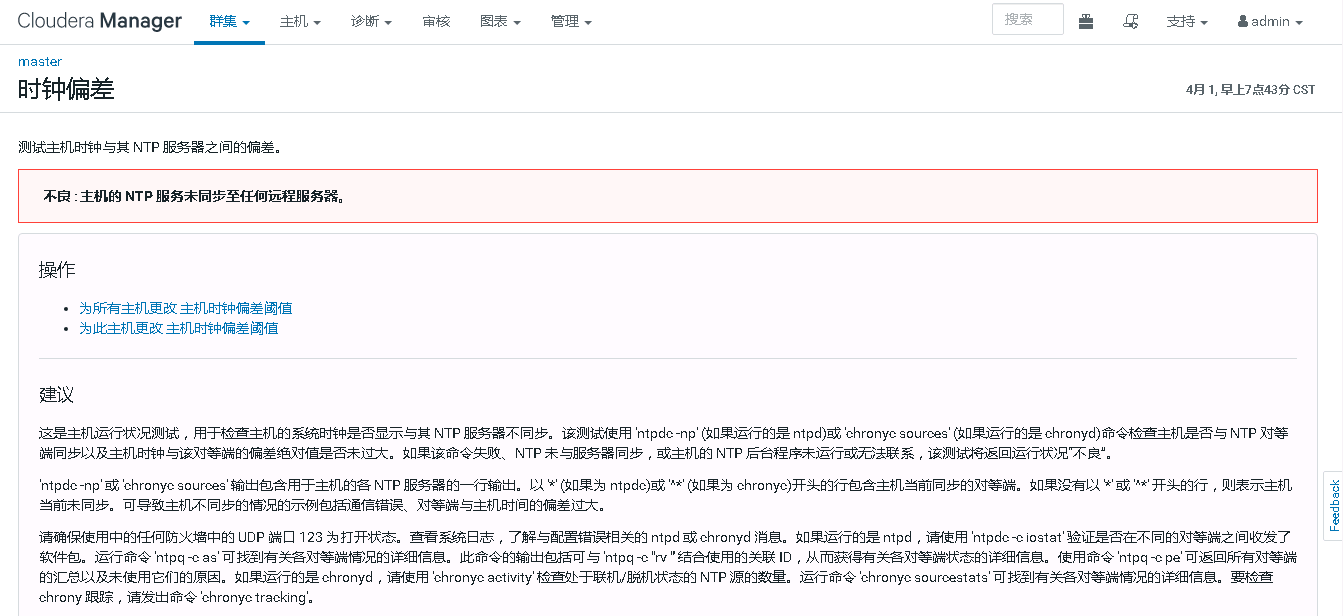
显示状态不良,Clock Offset,提示服务器时间不同步。
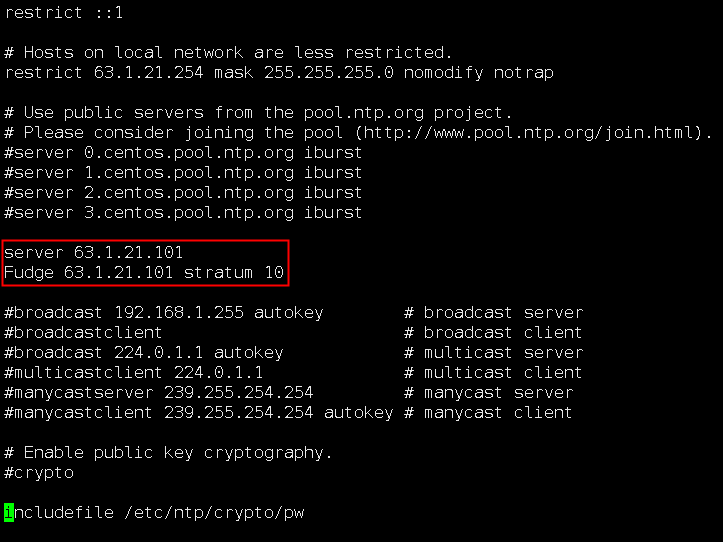
查看ntp的配置文件是否正确:vi /etc/ntp.conf,各节点都指向了master服务器IP,没有发现问题:
接着执行ntpstat命令查看状态,结果发现所有服务器的状态都是未同步状态“unsynchronised”:

百度了一下,猜测是因为ntp服务出问题导致的(如果时间不同步,会导致CDH集群上的各种服务运行都出现异常)。于是重启ntp服务、手动时间同步、再重启服务(全部机器执行):
systemctl stop ntpd
sudo ntpd -gq
systemctl start ntpd
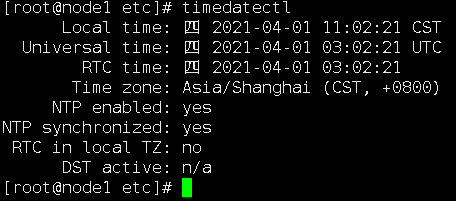
之后再执行tinedatectl查看服务器时间状态,发现NTP synchronized为true,说明时间同步成功了。并且各个节点与master之间的时间都保持一致了:
之后进到CDH管理后台,重启服务,耐心等待服务重启。然而datanode都恢复了,master依然有问题,提示ntp服务依然有问题:
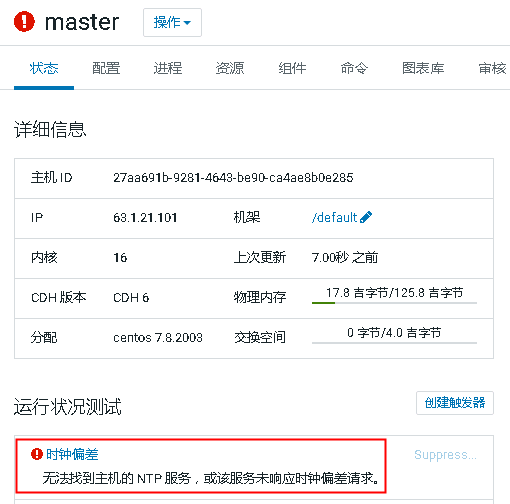
这真是莫名其妙啊,无法找到主机的NTP服务,如果找不到服务,那为啥执行NTP服务停止、重启等操作都不报错呢?无意中在master上执行ntpstat查看状态,居然提示无法与NTP daemon通讯:

打开master的ntp配置文件检查,发现这两行不知道为啥被注释了,查了一下意味着不允许本地访问。估计就是这个原因导致的。于是取消注释、保存配置并重启NTP服务。

运行ntpstat,master的状态好了,但是进入CDH显示问题依据。WTF???
重新百度到一篇帖子:https://blog.csdn.net/weixin_39445556/article/details/103455175,里面有说根本不是NTP的事,是CDH agent的问题。于是在每台机器上挨个执行systemctl restart cloudera-scm-agent,重启cdh,过了一小会果然问题解决了。我也是无语了...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号