
ocr识别开源软件tesseract试用记录
针对公司系统现场查验场景中,需要用到拍照识别并查验证件信息的需求。对其中关键的ocr开源软件tesseract技术进行了简单试用记录。
1、新建一个winform测试项目,通过nuget搜索安装tesseract的sdk。
2、去github下载语言包:https://github.com/tesseract-ocr/tessdata,分各种语言,下载英文(eng.traineddata)以及中文(chi_sim.traineddata)的,下载完成后放到测试项目的\debug\tessdata目录下,注意只能是tessdata目录,名字不能错。
3、代码如下:
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
using Tesseract;
namespace TestOCR
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
/// <summary>
/// 加载图片显示到picturebox
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void button1_Click(object sender, EventArgs e)
{
if (openFileDialog1.ShowDialog() == DialogResult.OK && (openFileDialog1.FileName != ""))
{
pictureBox1.ImageLocation = openFileDialog1.FileName;
}
}
/// <summary>
/// 调用tesseract对所选图片文字进行识别
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void button2_Click(object sender, EventArgs e)
{
using (TesseractEngine te = new TesseractEngine(Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "tessdata"), "chi_sim+eng", EngineMode.Default))
{
using (var pix = PixConverter.ToPix(new Bitmap(pictureBox1.ImageLocation)))
{
var page = te.Process(pix);
string text = page.GetText();
this.textBox1.Text = text;
}
}
}
}
}
a、运行,选择一个字少的,识别结果如下,可以发现清晰的字大的地方,识别率还可以,但是最下面一行就完全变乱码了:

b、换一张图,从业资格证,格式比较复杂的,图片清晰度已经很可以了,但是识别结果基本不可用。
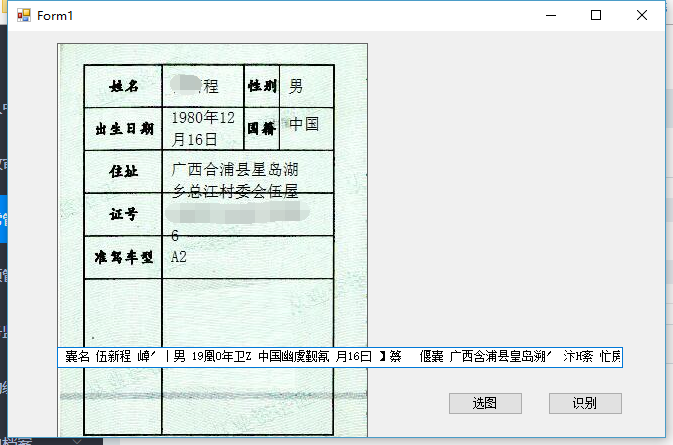
4、因为手上其他要跟的事情太多,没有再进一步研究,基本结论如下:
a、这个东西要想达到实用的效果,还有很多事情要做,远不是写个demo那么简单。
b、我们的场景过程:现场手机拍证件或者拍车牌—>上传拍摄图片,调用ocr服务识别—>针对识别出的特征信息(证件号或者车牌号),调用对应的查验接口—>返回相关信息。
c、分析:现场拍摄的图片质量,会比测试使用图片质量差很多(主要是清晰度、角度)。因此,实际我们在识别之前,还需要对图片进行很多的预处理来提高识别率,例如对图片进行形状校正、对图片进行去噪点、包括针对特定证件的特定位置进行识别排除干扰项、对识别语言包进行针对性的训练等工作,有大量的工作要做。目前决定暂时不再推进研究工作。建议直接使用市场中成熟大厂的产品。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号