
聚类算法性能评估
如何评价聚类算法的性能呢?特别是应用在没有类别标注的数据集上。针对不同的数据特点,有以下两种方式:
1、如果被用来评估的数据本身带有正确的类别信息,可以使用ARI(Adjusted Rand Index)
ARI指标与分类问题中计算准确性的方法类似,同时也兼顾到了类簇无法和分类一一对应的问题
用法:
1 from sklearn import metrics #导入metrics包 2 print(metrics.adjusted_rand_score(y_test,y_pred))
2、如果被用于评估的数据没有所属类别,那么我们习惯使用轮廓系数(Silhouette Coefficient)来度量聚类结果的质量。
- 轮廓系数同时兼顾了聚类的凝聚度Cohesion和分离度Separation,用于评估聚类的效果并且取值范围为[-1,1]。
- 轮廓系数越大,表示聚类的效果越好
- 具体计算步骤如下:
- (1)对于已聚类数据中第i个样本xi ,计算样本xi与其同一个簇内的所有其他样本距离的平均值ai,用于量化簇内的凝聚度
- (2)选取xi外的一个簇b,计算xi与簇b中所有样本的平均距离,遍历所有其他簇,找到最近的这个平均距离bi,用于量化簇之间的分离度
- (3)对于样本xi,轮廓系数为sci=(bi-ai)/max(bi,ai)
- (4)最后对所有样本x求取平均值即为当前聚类结果的整体轮廓系数
用法:
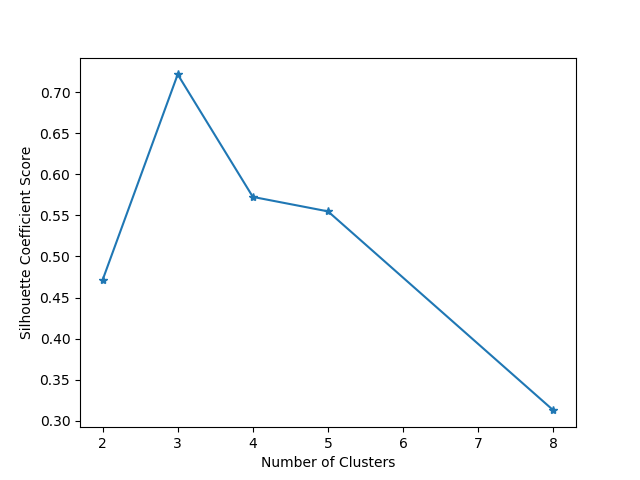
import numpy as np from sklearn.cluster import KMeans from sklearn.metrics import silhouette_score import matplotlib.pyplot as plt #分割出3*2=6个子图 并在子图1上作图 plt.subplot(3,2,1) #初始化原始数据点 x1 = np.array([1,2,3,1,5,6,5,5,6,7,8,9,7,9]) x2 = np.array([1,3,2,2,8,6,7,6,7,1,2,1,1,3]) X=np.array(zip(x1,x2)).reshape(len(x1),2) #在1号子图上作出原始数据点阵的分布 plt.xlim([0,10]) plt.ylim([0,10]) plt.title('Instances') plt.scatter(x1,x2) colors = ['b','g','r','c','m','y','k','b'] markers = ['o','s','D','v','^','p','*','+'] clusters = [2,3,4,5,8] subplot_counter = 1 sc_scores = [] for t in clusters: subplot_counter += 1 plt.subplot(3,2,,subplot_counter) kmeans_model = KMeans(n_clusters=t).fit(X) for i,l in enumerate(kmeans_model.labels_): plt.plot(x1[i],x2[i],color=colors[l],marker=markers[l],ls='None') plt.xlim([0,10]) plt.ylim([0,10]) sc_score = silhouette_score(X,kmeans_model.labels_,metric='euclidean') sc_scores.append(sc_score) #绘制轮廓系数与不同类簇数量的直观显示图 plt.title('K=%s,silhouette coefficient=%0.03f'%(t,sc_score)) #绘制轮廓系数与不同类簇数量关系曲线 plt.figure() plt.plot(clusters,sc_scores,'*-') plt.xlabel('Number of Cluster') plt.ylabel('Sihouette Coefficient Score') plt.show()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号