
排序算法(四)选择排序
基本思想
每一趟从待排序的记录中选出关键字最小的记录,顺序放在已排好序的子文件的最后,直到全部记录排序完毕。
回顾和简介
在介绍选择排序算法前,我们再回顾下冒泡算法。
冒泡算法是通过两两比较,不断交换,逐个推进的方式,来进行排序的。一次遍历,得到一个最值。
冒泡算法最费时的是什么?
一是两两比较
一是两两交换, 交换要比比较费时多了。
冒泡算法两两交换的目的是什么?-------找出最值。
而通过这种方式取得最值得代价是很大的,因为,每次遍历,可能需要很多次交换才能找到最值,而这些交换都是很浪费时间的。
如果能减少交换次数,同时又能取得最值,那么这就是一种改进。
求最值,需要比较,但不一定非得通过不断推进的方式。
那如何能更好的求得最值呢?
很自然的一种想法便是:
每次遍历,只选择最值元素进行交换,这样一次遍历,只需进行一次交换即可,从而避免了其它无价值的交换操作。
如何求得最值元素所在位置呢?
这还得通过遍历比较。
具体方法为:
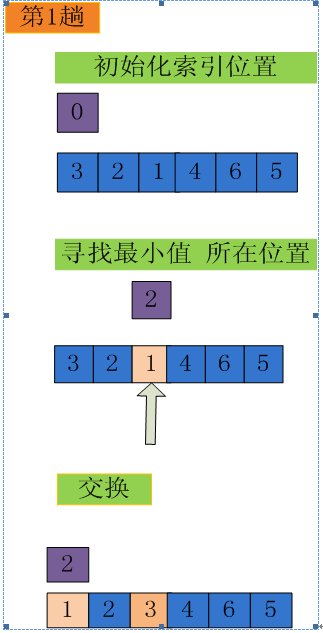
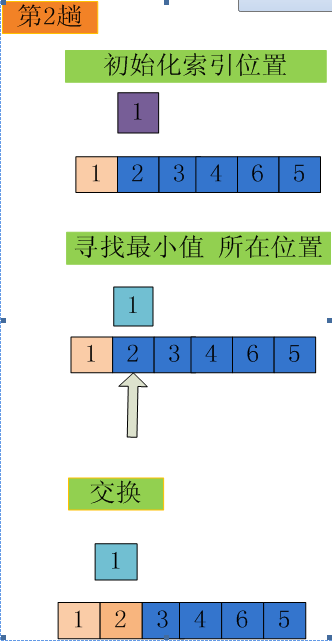
遍历一次,记录下最值元素所在位置,遍历结束后,将此最值元素调整到合适的位置
这样一次遍历,只需一次交换,便可将最值放置到合适位置
这便是 简单选择排序算法。
代码
1 /* 2 @theme:选择排序 3 @author:CodingMengmeng 4 @date:2016-11-10 09:56:52 5 @email:sprint_meng0116@163.com 6 */ 7 #include <iostream> 8 using namespace std; 9 10 template <class T> 11 void selectSort(T data[], int len) 12 { 13 T tmp;//临时变量,用于交换 14 int nIndex = 0;//记录待排序元素最小值的索引 15 16 //len个数排序,只需要进行len-1轮 17 for (int i = 0; i < len - 1; i++) 18 { 19 //第i次排序时,已经进行了i次选择,因此已经排好了i个元素 20 //已排好的元素为0,1,...,i-2,i-1 21 //待排元素为i,i+1,...,len-1 22 23 nIndex = i; 24 for (int j = i + 1; j < len; j++) 25 { 26 //nIndex记录待排元素中值最小的下标 27 if (data[j] < data[nIndex]) 28 nIndex = j; 29 } 30 //交换 31 if (nIndex != i) 32 { 33 tmp = data[i]; 34 data[i] = data[nIndex]; 35 data[nIndex] = tmp; 36 } 37 } 38 39 } 40 41 int main(void) 42 { 43 int len;//要排序数组的长度 44 cout << "要排序数组的长度为:" << endl; 45 cin >> len; 46 int* data = (int*)malloc((len)*(sizeof(int)));//动态分配大小为len的int型数组 47 memset(data, 0, (len)*sizeof(int));//初始化数组的值为0,否则会出错 48 49 //读入数据 50 cout << "请输入" << len << "个数据:" << endl; 51 for (int i = 0; i < len; i++) 52 cin >> data[i]; 53 54 //开始选择排序 55 selectSort(data, len); 56 57 //输出排序后的结果 58 cout << "选择排序后的结果:" << endl; 59 for (int i = 0; i < len; i++) 60 cout << data[i] << " "; 61 62 return 0; 63 }
运行结果:

总结
从选择排序的思想或者上面的代码中,不难看出,算法的时间复杂度为O(n*n),冒泡排序的时间复杂度也是O(n*n),但选择排序相比于冒泡排序,一次遍历只需要进行一次交换,减少了交换次数,因此,选择排序在同等条件下,会略快于冒泡排序。
それでも私の大好きな人

 浙公网安备 33010602011771号
浙公网安备 33010602011771号