
结对第二次—文献摘要热词统计及进阶需求
作业格式
| 这个作业属于哪个课程 | 软件工程1916-W(福州大学) |
|---|---|
| 这个作业要求在哪里 | 结对第二次—文献摘要热词统计及进阶需求 |
| 结对学号 | 221600414、221600417 |
| Github项目地址 | PairProject1-Java 、PairProject2-Java |
| 这个作业的目标 | 根据需求进行模块化编码,并进行完善和单元测试,熟悉项目开发流程 |
| 其他参考文献 | [1]邹欣.构建之法[M] |
Github代码签入记录
PairProject1-Java:
PairProject2-Java:
具体分工
黄乐兴:
- 基本需求项目和进阶项目的编写;代码调优;
冯凯:
- 需求分析;附加题编写;单元测试;文档书写;
解题思路描述
1.WordCount:
- 初期:当我看到这个题目信息时,就发现这次的需求并不简单,甚至很难理解。因此,我花了数天的时间不断和同学一起探讨需求,理解思路,明白每一点需求中的具体含义。因为, 如果需求无法正确地解读,写出的程序代码也会有N多个坑,而填坑的过程花费的时间将会远远超过挖坑的时间。
- 中期:对于一些功能点的实现,例如:文件的读写,由于使用的频率较低,API使用早已忘记。采用面向搜索引擎编程,Google + StackOverFlow 提问式搜索,短时间最大效率学习相关API。 而对于一些隐约在脑海记得的API,直接鼠标点击相关类查看其中的源码,配合源码的注释,进而再次掌握这个API。
2.论文信息爬取:
- 工具:Jsoup
- 思路:通过 Jsoup 请求指定url(http://openaccess.thecvf.com/CVPR2018.py),获取返回 Document 对象。接着定位在 dl 标签(论文信息所在位置),使用一个循环,获取每一个篇论文信息。其中,每一篇的论文信息的标题位于第一个 a 标签的文本信息中,而摘要信息url位于这个标签的 href 属性中。继续通过访问这个摘要信息url,并爬取 id 为 abstract 的标签的文本信息即摘要信息。
设计实现过程
1.代码组织:
主要分为两个类,Lib类和Main。其中,Lib类作为一个程序的功能库,向上提供基础的API;而Main类主要为一个程序的入口,通过调用Lib类的API完成程序功能。函数细分至每个功能点的定义,例如,判断字符为分隔符封装为一个函数;并对于几大独立功能封装其相应的函数。对于一些较为复杂关键的函数,画出了相应的流程图,以便日后的维护以及纠错。
2.单元测试:
为了方便我们的”测试工程师“有一个良好的测试体验,我在不影响结果的情况下修改Lib类的相关函数,并打包成一个 Jar包;除此之外,编写了一个基于JUnit的单元测试模板类。”测试工程师“只需通过CV大法导入 JAR 包 和测试模板类,将Jar包添加至项目依赖中,安装IDEA的JUnit插件,三步操作即可上手测试。
当然,简单的单元测试还是不够的。每一个小功能的正确并不能反映全局的正确性,兴许哪一个的逻辑在某种关联的情况下引发出不一样的效果。这时我们就要上集成测试了,但由于时间的关系,没有采用框架进行集成测试,而是直接人工执行+人工校验结果。
3.关键算法及流程图
命令行参数处理:
一种方式是遍历 String[] args,每次获取两个字符串,并通过值来进行相应的处理。但这种方式需要写大量的if else 分支判断条件,每次增加新的参数,还必须修改原有的代码,不符合开闭原则。经过分析之后,我们得出第二个更为合理的方法,使用一个Map对命令行参数进行封装。后续对于命令行的查找只需通过Map.get(),且新增参数后也不必修改之前的代码。
单词计数:
定义两个辅助变量,letterCheck 默认为-4,letterCheckAble 默认为 true。第一个变量用于判断前缀字母数是否大于等于4,第二个变量用于是否需要进行单词检测。逐个字符遍历字符串,当检测到非字母时,判断letterCheck是否为0,如果为0则将 letterCheckAble 赋值为 false,关闭单词检测,直到遇到一个分隔符则再次打开检测开关;当检测到字母时,将 letterCheck 自增直至为0;当检测到分隔符时,判断单词检测是否为打开状态且letterCheck 为0,如果是的话则把单词数自增。
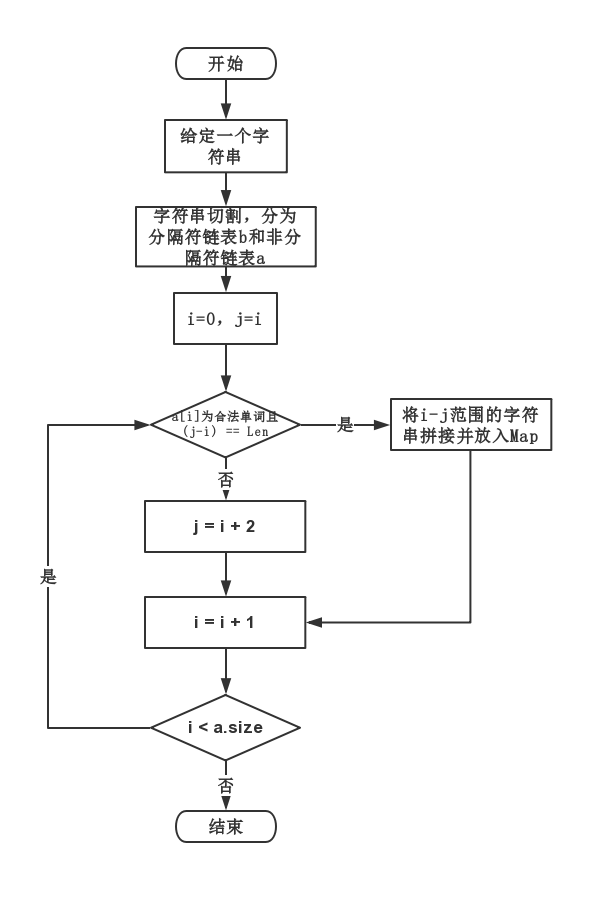
长度为N词组的提取处理:
第一步:对字符串进行切割,分为两类,一类为分隔符字符串,另一个为非分隔符字符串。具体操作为,使用Matcher 正则表达式,不断匹配相应的字符串,并放在一个字符串链表中。切割完之后,可以得到一个分隔符字符串链表和非分隔符字符串链表。
第二步:使用双指针L和R,R从0开始到非分隔符字符串链表 list 的尾部,不断遍历。在每次的遍历中,判断 list.get(R) 是否为单词。如果为单词并且 R-L+1 == N,则已经找到一个合法词组的坐标范围(L-R),进而合并这些单词作为词组,放置在Map中;如果不为单词,则将L赋值为R+1,使得下一次R遍历的时候指针L和R再次重叠在一个地方。
性能分析与改进
性能分析图以及消耗最大的函数:
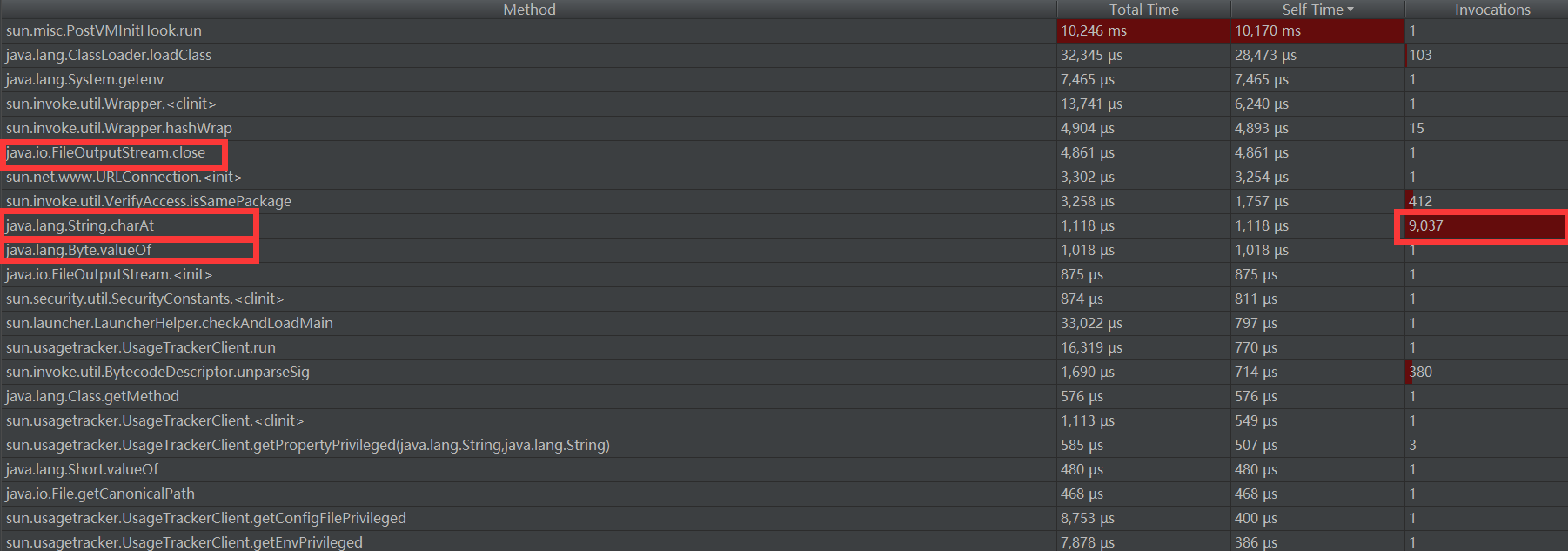
此图为通过 JProfiler 调优工具获取。占用时间较长的大部分为系统库函数,前几个函数中只有三个出现在代码中。消耗最大的函数应该为 FileOutputStream.close() ,目前尚不清楚为啥占用时间较长。而执行次数最多的为 String.charAt()
改进的思路:
代码优化:
初始化 BufferedReader 的默认大小为文件长度,这样只需一次IO即可将整个文件读取进内存,而之前的默认大小是固定的。但在几次尝试之后,并没有时间上的增进,可能是文件不够大的原因。
算法优化:
1.多个字符串寻找连续的长度N的合法词组。使用双指针进行搜索,可以减少判断的次数。
2.单词计数。使用一个正则表达式进行全文匹配,搜索效率较高。
关键代码展示与说明
1.MAP 自定义排序 + 分割 + 输出
对于这个需求,可以联想到 JAVA8 的一个新特性,流处理。将集合看做为一个流,流在管道运输中加入各种处理,例如排序,限制,循环等,即可在较少的代码量中完成一个复杂的功能。
// 排序Map并输出
static void sortMapAndOut(Map<String, Integer> map, StringBuilder builder) {
map.entrySet()
.stream()
.sorted((e1, e2) -> {
int cmp = e2.getValue().compareTo(e1.getValue());
if (cmp == 0) return e1.getKey().compareTo(e2.getKey());
else return cmp;
})
.limit(10)
.forEach(o -> builder.append("<").append(o.getKey()).append(">").append(": ").append(o.getValue()).append("\n"));
}
2.长度为N词组的提取处理:
主要的思路已经在上面的关键算法中进行展示,下面给出具体的代码以及一些辅助函数的思路。
// 提取词组,获取单词数
static int countWord(String s, int w, int len, Map<String, Integer> map) {
int wordNum = 0;
boolean isDivBegin = isDivision(s.charAt(0));
List<String> titles = cutStr(s, DIV_RE);
List<String> titles2 = cutStr(s, NOT_DIV_RE);
for (int i = 0, j = i; i < titles.size(); i++) {
if (isWord(titles.get(i))) {
wordNum++;
if ((i - j + 1) == len) {
String word = getWord(isDivBegin, titles, titles2, j, i).toLowerCase();
map.merge(word, w, (a, b) -> a + b);
j++;
}
} else {
j = i + 1;
}
}
return wordNum;
}
此辅助函数为拼接i-j范围的合法单词以及分割符字符串。
这里存在两个链表,其中s为合法单词链表,而s2为分割字符串链表。通过下标之间的关系我们可以得出一个结论,当未切割字符串的第一个字符为字母时,拼接过程中切割字符串的下标等于j,而当第一个字符为非字母时,切割字符串的小标等于j+1。由此,我们可以通过这个规律对拼接这两个链表。
// 拼接字符串
private static String getWord(boolean isDivBegin, List<String> s, List<String> s2, int j, int i) {
StringBuilder builder = new StringBuilder();
int offset = isDivBegin ? 1 : 0;
while (j <= i) {
builder.append(s.get(j));
if (j != i) builder.append(s2.get(j + offset));
j++;
}
return builder.toString();
}
部分测试代码展示与说明
1.基础需求单元测试
分别针对文件中的字符数、有效单词书以及字典序的单词频数做不同的单元测试。每个测试方面都带有5个以上的测试点,覆盖大多数可能出现的情况。
/***********部分单元测试代码****************/
private void newFile(String s) throws IOException {
BufferedOutputStream bf = new BufferedOutputStream(new FileOutputStream(TEST_FILE_NAME));
bf.write(s.getBytes());
bf.flush();
}
/*
* **测试文件中字符的个数**
* 主要测试点:转义字符、字母、数字及其他字符任意组合的个数
* 例:\\\"123abc!@#
* */
@Test
void testCharNum2() throws IOException {
newFile("\"\'\\26384 hfJFD *-.@!");
int charNum = CountUtil.getCharNum(TEST_FILE_NAME);
Assertions.assertEquals(20, charNum);
}
/*
* **测试文件中单词的个数**
* 主要测试点:不能以数字开头,字母(4个开头)和数字的任意组合,以特殊字符分割,不区分大小写
* 例:file12desk%losses225
* */
@Test
void testWordNum3() throws IOException {
newFile("c2ools DisCount23-hayerS SELLER*CANcels#GAY9220^ 89NAVY!!)(SwingS=flying290");
int letterNum = CountUtil.getLetteryNum(TEST_FILE_NAME);
Assertions.assertEquals(6, letterNum);
}
/*
* **测试文件中各单词出现的次数**
* 主要测试点:至少以4个字母开头,不区分大小写,后跟字母和数字的任意组合,以特殊字符分割
* */
@Test
void testMaxWord4() throws IOException {
newFile("sex23 gold89&numbers&&&&90byes (cLicks009(clicks009)gold89 sexx )) shopping-NUMBERS265clicls");
LinkedHashMap<String, Integer> result = CountUtil.getMaxLetter(TEST_FILE_NAME);
System.out.println(result);
Assertions.assertEquals(1, 0);
}
初期测试过程中出现了一些BUG,测试失败。
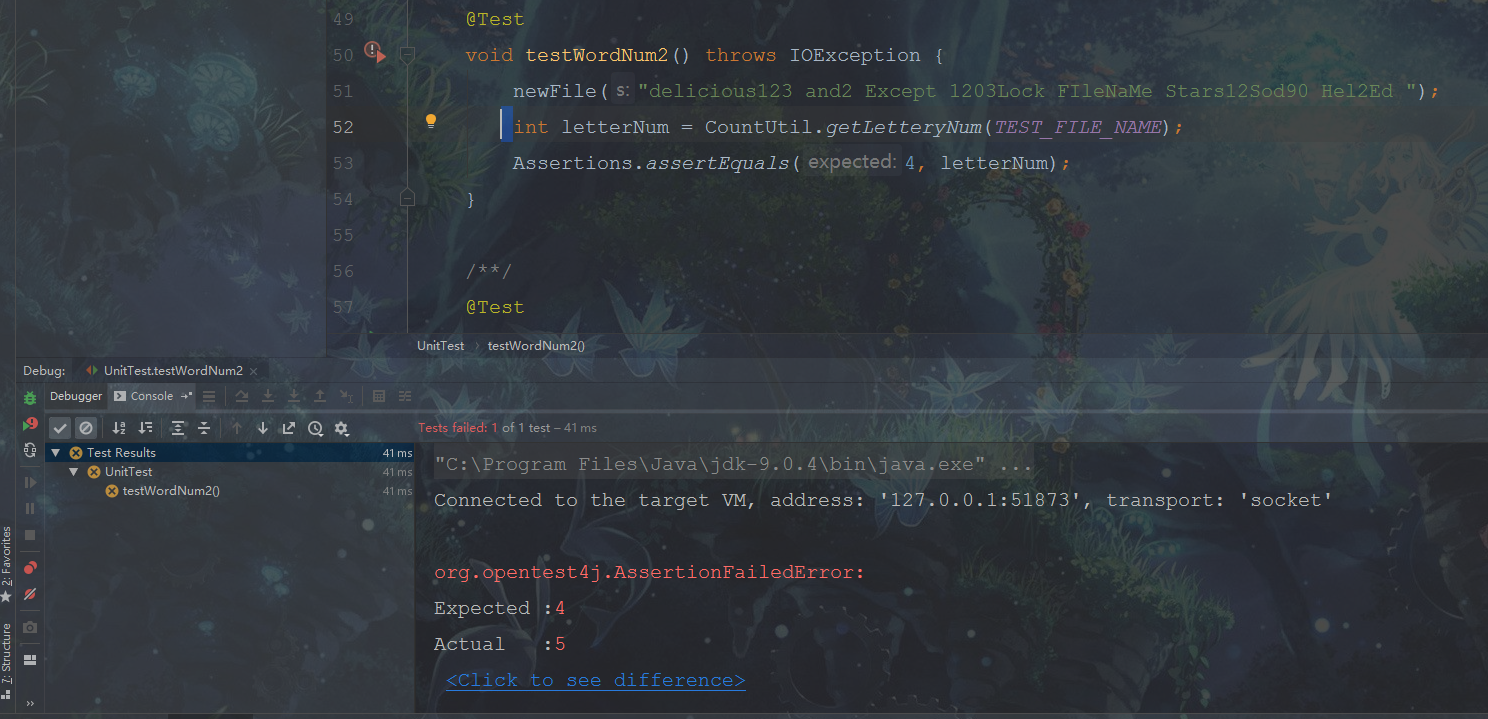
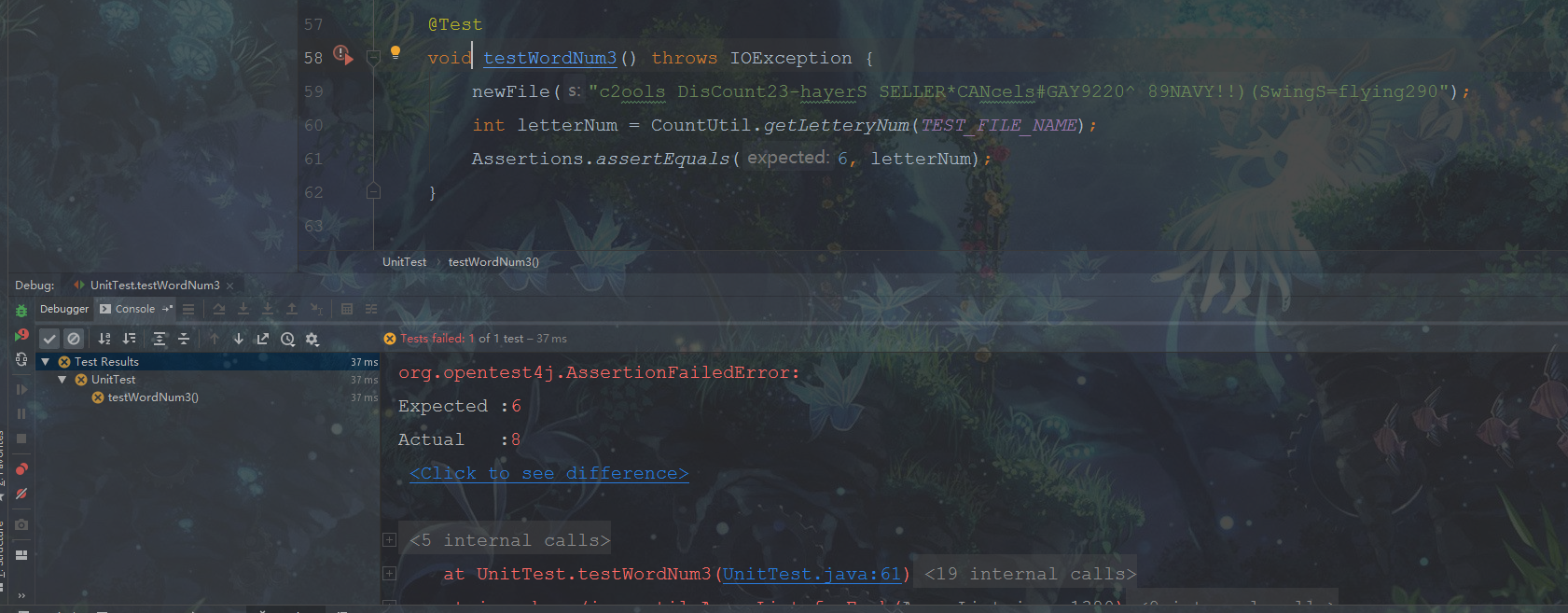
在经过几次的调试和修改之后,终于全部通过测试,哈哈。
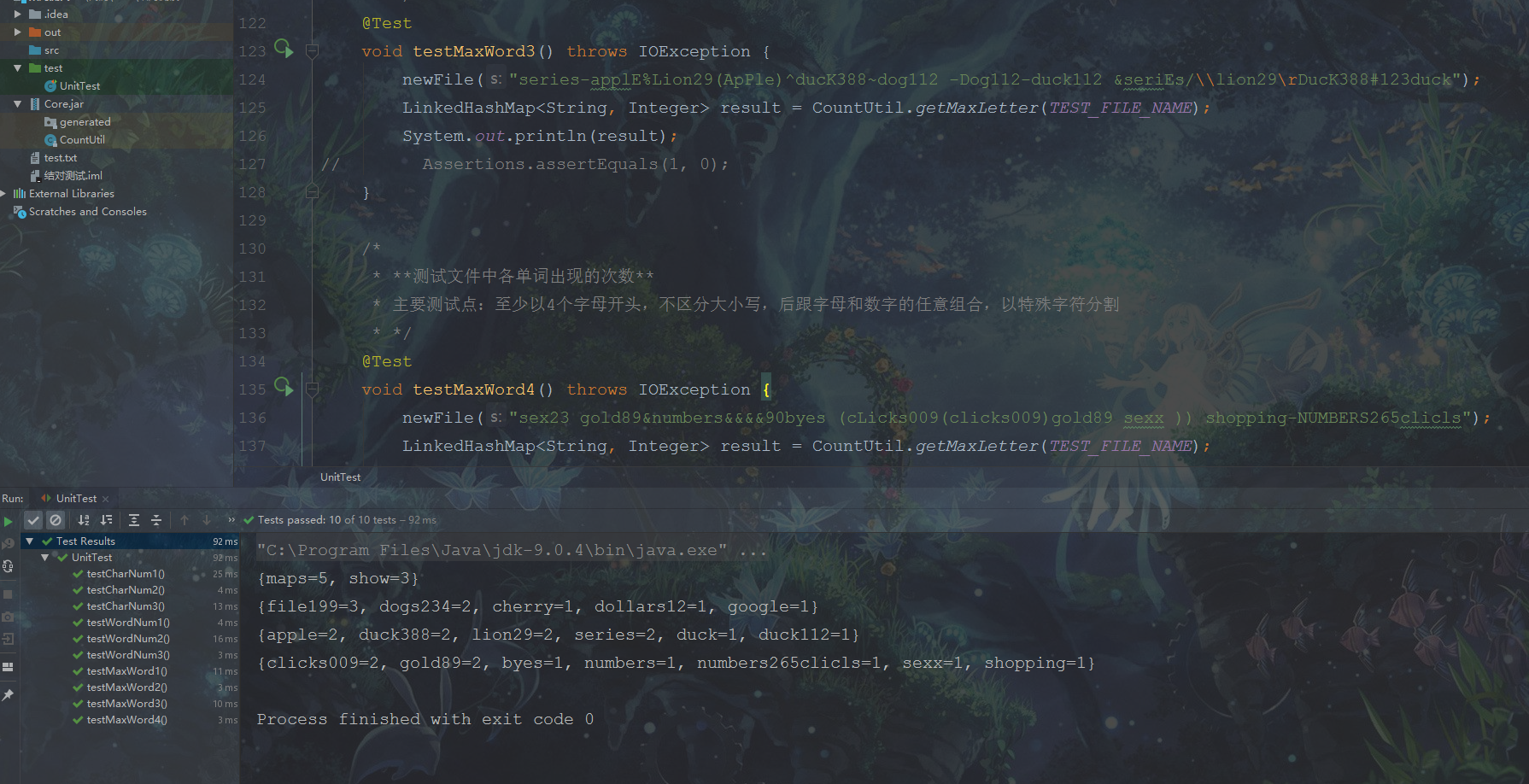
2.进阶需求测试
在初步完成了进阶需求之后,我们根据课程作业的要求,自己手动编写了十余个测试文件,从最基础的字符、单词到复杂的长篇文章,使用命令行一一去测试,然后将测试的结果保存在result。txt中,最后将测试结果和正确答案作对比,然后再进一步去做优化和调试,保证结果的一致性。
遇到的困难及解决方法
HLXING:
- 需求不明,迟迟无法理解。通过微信提问的方式+同学之间交流解决。
- 爬虫获取的数据少了一半。Google 提问,发现是这个爬虫库的 API 存在设计上的缺陷,反人类的默认响应数据包大小1MB的设定,只需加个
maxBodySize(0)即可解决这个问题。 - 测试结果与其它同学不符合。通过折半纠错法,不断删减输入文件的内容,最后确定问题出现在一个非ASCII字符(中文下的上引号)
KAI:
- 在搞测试的时候,刚开始设计的测试样例都比较普通,没有针对性,因此很难测出程序中存在的问题。在看了一些别的组的测试样例之后,有了灵感,写出了好多针对字符、单词、字典序排序的样例,这些样例针对最可能出现问题的地方进行测试,果然,发现了不少的BUG,最终得以解决完善。
- 爬取数据进行数据挖掘分析的时候,将爬取的数据存放在文件中。面对杂乱无章的数据,不知道如何从它们中抽取有用信息。在经过一番思考之后,将不同类型的数据进行结构化存储,然后按照不同的类别,从它们中提取有用信息,去除无用信息,最后加以可视化处理,将它们之间的关系很清晰的展示出来。
附加题设计与展示
1.设计思路:
2.代码展示:
"""**************爬取CVPR首页源码************"""
import requests
BASE_URL = "http://openaccess.thecvf.com/CVPR2018.py"
try:
html = requests.get(BASE_URL)
with open("index.html", "wt", errors="ignore") as f:
f.write(html.text)
except Exception as e:
print(str(e))
将论文标题加以切词处理,然后根据其出现的频率,绘制热点研究方向的词云图

"""***********部分绘图代码***********"""
with open("titles.txt", encoding="utf-8")as file:
text = file.read()
words = chinese_jieba(text)
wordcloud = WordCloud(font_path="C:/Windows/Fonts/simhei.ttf",
background_color="white", width=800,
height=400, max_words=50, min_font_size=8).generate(words)
image = wordcloud.to_image()
image.show()
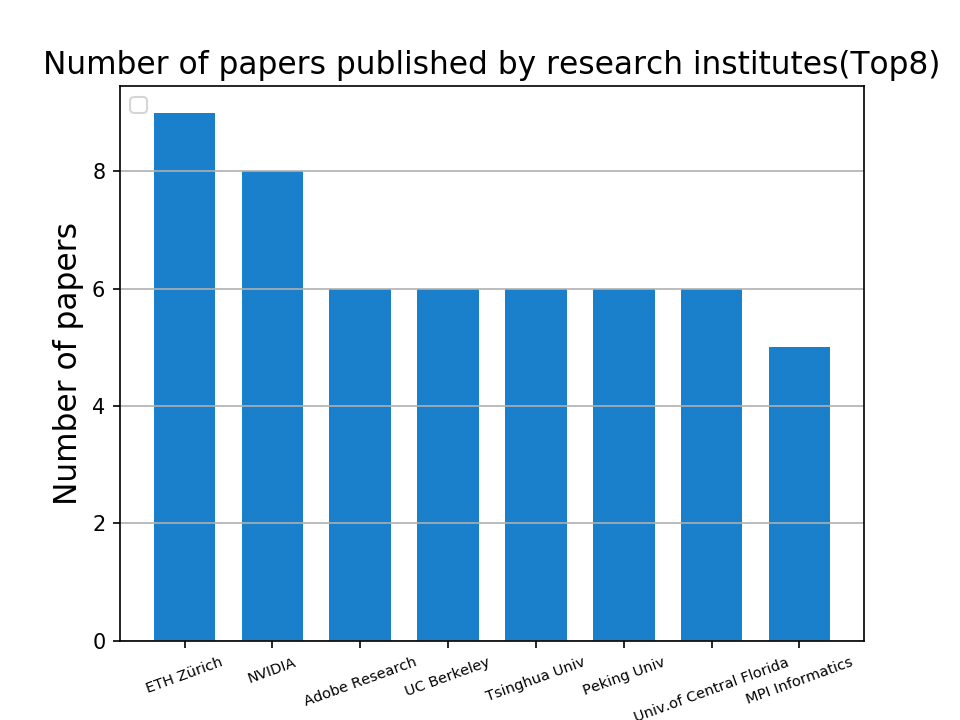
利用数据挖掘技术,将论文发表所在的学术机构(高校、研究院、实验室)所发表的论文数量加以统计,绘制柱状图,从一方面展示展示这些学术机构的研究能力。
"""***********部分绘图代码***********"""
def collect_univ():
univ_count = {}
with open("university_count.txt", "rt", encoding='utf-8') as f:
word = f.readline()
while word:
count = univ_count.get(word.strip(), None)
if count:
univ_count[word.strip()] += 1
else:
univ_count.setdefault(word.strip(), 1)
word = f.readline()
return sorted(univ_count.items(), key=lambda x: x[1], reverse=True)
def draw_graph():
univ_list = dict(collect_univ())
x = list(univ_list.keys())[:8]
y = list(univ_list.values())[:8]
plt.bar(x, y, alpha=1.0, width=0.7, color=(0.1, 0.5, 0.8), label=None)
plt.xlabel("Research Institute", fontsize=15)
plt.xticks(x, rotation=20)
plt.ylabel("Number of papers", fontsize=15)
plt.tick_params(axis='x', labelsize=7)
通过所有论文的作者之间的关系,将各个作者参与发表的论文数量加以统计,展示出科研能力比较强的一些作者。
def load_author():
soup = BeautifulSoup(open("../CVPR_Spider/index.html"), "html.parser")
authors = soup.find_all('a', href="#")
f = open("authors.txt", "wt", encoding='utf-8')
for author in authors:
filtered_author = author.text.replace(' ', '').replace('\n', ' ')
f.write(filtered_author + '\n')
f.close()
def analyse_authors():
author_count = {}
f = open("authors.txt", "rt", encoding='utf-8')
author = f.readline()
while author:
count = author_count.get(author.strip(), None)
if count:
author_count[author.strip()] += 1
else:
author_count.setdefault(author.strip(), 1)
author = f.readline()
return sorted(author_count.items(), key=lambda x: x[1],reverse=True)


通过爬取往年的CVPR论文发表数量,可以看出在计算机视觉和模式识别方面的研究投入呈逐年增长的趋势。

3.相关附件:源码和图表
PSP表格
| PSP 2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 1000 | 1800 |
| Estimate | 估计这个任务需要多少时间 | 600 | 750 |
| Development | 开发 | 600 | 700 |
| Analysis | 需求分析 (包括学习新技术) | 500 | 600 |
| Design Spec | 生成设计文档 | 50 | 60 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 70 |
| Design | 具体设计 | 200 | 250 |
| Coding | 具体编码 | 400 | 600 |
| Code Review | 代码复审 | 50 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 90 | 90 |
| Test Report | 测试报告 | 50 | 60 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 10 |
| 合计 | 1500 | 1800 |
评价你的队友
1.值得学习的地方
- 编程能力很强,作业的需求是在他的带领下完成分析,在编程过程中出现了不少BUG,他能够认真分析代码中出现的问题,帮助我们解决其中的问题。
- 善于分析问题,在作业需求不明确的情况下,能够针对其中的需求,加以分析,使需求变得明确。
- 解题思路清晰,动手能力很强,能够有条不紊地去完成工作。
2.需要改进的地方
- 细心程度需要提高。
项目总结
HLXING:
在这次的项目中,我获得了性能改进以及单元测试的能力。JProfiler是一个易用的 Java 性能分析工具,通过 CPU 占用时长以此得出函数执行的时间,找出性能瓶颈地方,且加以改进。而 JUnit 是一个实用的单元测试库,可以编写代码进行测试,代替以往的人工测试,省时省力。除此之外,项目的难度也提高了我问题分析能力,逻辑推理能力,能够对一个问题加以拆解,最终解决。相比于上次的结对编程,我和队友的配合能力也逐渐提高,不再是以往的无头苍蝇式地工作,而是对任务的分配有了更好地把握,能够发挥出两个人所擅长的地方,以此提高整个项目的工作效率。
KAI:
这次作业相比上次作业,无论是在工作量还是代码量都比上次多了不少。虽然花费了一周时间(每天三个小时以上)去完成这次作业,欣慰的是,在这个过程中我学习到了很多东西,使我受益匪浅。首先,在写作业的初期,由于需求的不明确,前前后后出现了许多问题,不断去问助教关于需求的问题,因为我明白,搞懂需求,永远是软件开发的第一步,也是最重要的一步,迈出了这一步,其余的工作才能顺利的进行。其次,在编码过程中,我学会了去主动使用单元测试来进行代码功能的测试,在以前的编码过程中,都是边写代码边测试,没有养成做完整体系的单元测试的习惯,这可能会导致后期代码出现一些预料之外的BUG,因此这个好习惯要保持下去,带到以后的工作岗位上去。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号