他山之石——运维平台哪家强?
DevOps 全链路
下图是我们熟知的软件研发环节,在迭代频率高的研发组织里,一天可能要经历多次如下循环。对于用户群体庞大或者正在经历大幅业务扩张的企业研发组织,除了重点关注应用的快速上线之外,如何保障应用的高可靠、高可用也成为焦点,即服务上线要快,运行要好。

如何让开发更简单,运行更高效,接下来我们从两个角度来探讨这个问题:
- 组织方式
- 研发工具
关于运维人员的组织方式
-
一种方式是组建专门的运维团队,一个运维团队往往会承接多个开发团队的协作。除了 DBA 这类针对某个中间件的运维之外,这种模式的弊端在于不少运维工程师深陷于环境配置、日志收集、业务恢复、现象记录等琐碎事情当中,没有时间阅读项目源码以及提升能力,对较为深入的业务问题分析困难,开发团队又往往无暇分身,运维容易陷入被动的境地。
-
另一种方式,开发人同时负责各自模块的开发与运维。好处自然是由于开发人员熟悉本模块源码,定位问题的效率要高出不少。同时开发者可以直接得到下游用户使用反馈,将其融入到研发当中去。坏处在于,让开发人员陷入到频繁的用户问题定位之后,难以保证代码开发的时间。
近年来,国内也兴起了 SRE 这种高级运维职业,特别是在云计算行业,SRE 的职业要求非常高,需要精通诸如网络、编程、算法、数据结构、操作系统、安全等知识与技能。当云平台出现网络故障、系统故障等问题,这对云租户/用户有时甚至是致命的,所以不少 SRE 是由高级别开发人员转型而来。
在 Google SRE 的服务可靠性层级当中,SRE 通过产品、开发、容量规划、测试、根因分析、事件响应、监控七个层次的实践来确保应用服务的健康状态。从这个层级当中我们可以看出 Google 提倡运维要积极控制服务发展的方向,而不仅仅在事故发生后反应性地灭火。目前来看,SRE 这种精英式的运维在国内还有待探索与实践。

粗暴地将开发运维拆开,或者将开发运维简单合并,都不是特别合适的一种方式。从笔者的研发经验看,一种方式可供大家思考与讨论——根据业务实际情况做分工:比如由团队内的开发者轮流负责整个项目运维。由于各个开发者对项目公共代码都需要熟悉,在理解其它模块代码也相对快速,这种方式基本能消灭大部分的问题,剩下的一小部分可以和指定模块的负责人结对定位。除此之外,为“每个服务团队分派运维联络人”,“邀请运维工程师参加开发团队的会议”都是能够加强运维与开发之间协作的措施。
关于工具的使用
除了恰当的人员组织方式之外,合适的工具也能给研发团队注入能力。
在配置研发环境时,研发组织可以选择通过开源工具自建代码管理和持续构建环境。这种方式的缺点在于需要有专门的 CI 团队来维护持续构建环境,一旦环境被破坏,开发的脚步就会停滞。并且由于各个开源工具数据未打通,开发人员要在多个工具之间切换使用。另外一种方式就可以通过现有的软件研发管理系统,例如 CODING 研发管理系统,来实现一站式的研发流程管理,无需自建、维护众多的研发工具与研发环境,支持在浏览器中完成全套软件开发流程,真正做到了 Coding Anytime Anywhere。
当开发人员通过 CODING 研发管理系统快速开发并部署好应用后,下一步就要让应用在运维工具的辅助监控下可靠运行(并不是所有应用都需要运维工具,需对症下药)。研发组织可以选择自己开发运维工具,也可以选择现有的运维工具。
目前的运维工具逐渐地朝以应用为中心发展,因为应用是直接向用户提供业务能力的,无论是开发还是运维,都是被业务价值驱动的。主流的运维工具主要涵盖基础设施层监控、应用层面监控、业务层面的分析与监控。

接下来我们看看现有的运维工具一般会提供哪些具体能力:
- 基础设施环境的监控:对服务器整体的 CPU、内存、磁盘、文件系统、网络等资源占用情况进行上报。
- 应用性能监控:针对应用使用的中间件,例如持久化数据库、缓存数据库、消息中间件等访问效率进行监控;以及对应用本身请求响应速度进行监控,包括延迟、吞吐量等等。
- 应用调用链路追踪:在分布式系统下,一个请求往往需要经过多个进程处理完毕。当出现用户请求调用失败或者出错时,运维平台支持整个调用链路的分析与故障环节定位。
- 日志数据采集与分析:日志的采集主要是为了辅助应用调用链路分析以及性能监控,运维人员无需进入后台去大量翻找日志。
- 故障自动恢复
- 灵活的告警
- 可视化面板展示监控与告警信息
国外热度较高的运维工具包括 ZIPKIN(分布式追踪),pinpoint(分布式追踪),logstash(数据收集)等等。目前国内各大云厂商也基本都提供了应用运维平台,包括腾讯蓝鲸、阿里 ARMS、华为 APM 等。以下是这几个运维平台能力的简要对比:
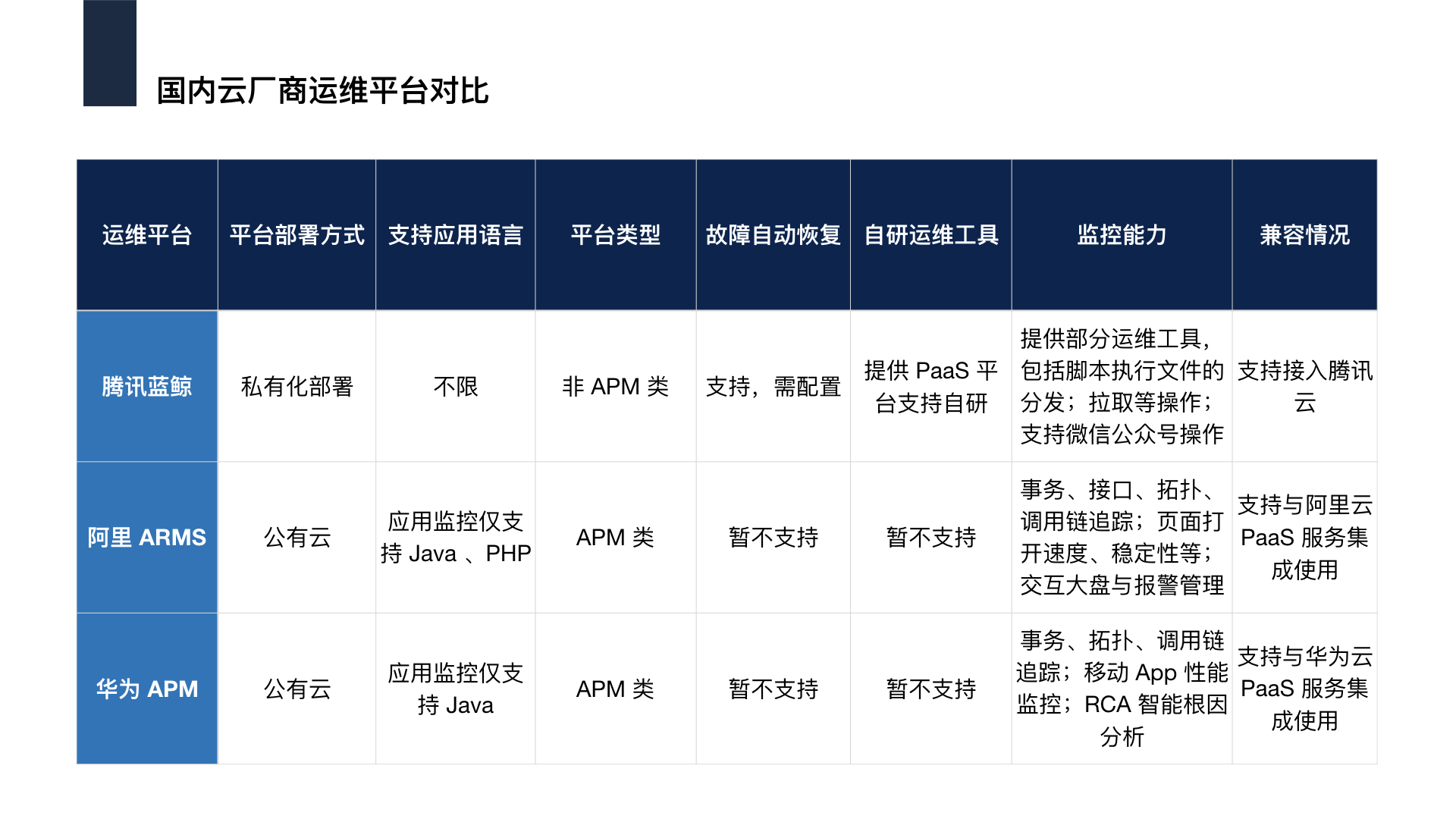
目前大部分的运维平台主要通过 Agent 和探针的方式去采集应用的指标信息,汇总处理后反应在可视化界面上。除上述的工具和平台之外,AIOps 也逐渐成为未来的一个趋势,AIOps 通过 AI 技术的运用来进行智能业务故障诊断,同时自动恢复应用故障,企图让研发组织彻底告别人肉运维时代,笔者也万分期待这天的到来。运维人员不用担心因 AIOps 失业,工具和平台只是提升运维效率,不会取代运维。
在运维阶段发现缺陷后,开发人员可在 CODING 中处理对应的缺陷,记录下每个缺陷的类型、优先级、模块、描述、处理人等信息。软件缺陷是不可避免的,但只有通过对缺陷进行管理和复盘才能知道缺陷产生的原因(人为因素 / 环境因素 / 工具问题等),从而改进,避免类似缺陷的重复。对缺陷的管理也有助于管理人员对软件质量的正确评估。缺陷处理人通过 CODING 实现缺陷的快速修复和部署,可大大缩短故障恢复时间,减少因缺陷产生的业务损失。
在 DevOps 理念的指导下,笔者建议开发人员在开发业务代码时,除了功能之外,也应当思考如何开发可运维的代码,通过适当的日志、错误码、异常等措施来提升运维效率;运维人员也需逐步提升能力,从传统的繁杂运维当中转型,走上敏捷自动化的运维之路。
写在最后
我们可以看到随着 DevOps 工具链自动化显著提升,DevOps 的门槛变得更加地低。拥抱自动化的结果是研发过程会变得越来越安静,顶尖的开源项目里的 committers 在日常仅仅是通过邮件和 issue 将事情说清楚,没有热火朝天、冗长拖沓的会议;也没有花花绿绿,色彩斑斓的工作表格。但这些都是建立在 DevOps 良好实践的基础之上。我们相信在践行 DevOps 的道路上,未来软件的开发会更简单,运行也会更加高效。
参考:
https://www.collab.net
https://landing.google.com/sre/sre-book/chapters/part3/
吉恩·金(Gene Kim);耶斯·亨布尔(Jez Humble);帕特里克·德布瓦(Patrick Debois);约翰·威尔斯(John Willis).《DevOps 实践指南》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号