
Java数据结构和算法总结-数组、二分查找
前言:在平时开发中数组几乎是最基本也是最常用的数据类型,相比链表、二叉树等又简单很多,所以在学习数据和算法时用数组来作为一个起点再合适不过了。本篇博文的所有代码已上传 github ,对应工程的 array 模块,下载地址:https://github.com/lgliuwei/DataStructureStudy,项目工程为 IntelliJ IDEA 环境,童鞋不妨下载下来,参照着代码看博文岂不是效果更好~
首先介绍一下工程的目录结构和作用,本工程的各个模块之间以 Module 形式划分,每个 Module 大致对应一个专题(例如:链表对应工程中的 link),其中 libuitils 作为工具模块为其他的模块提供基础的工具类,例如输出语句的打印、字符串处理等等。

一、数组
俗话说磨刀不误砍柴工,为了后续的方便,先做一些准备工作,首先创建一个抽象类 BaseArray,包含的几个关键方法如下:
·initArrayByRandom(int size) :使用随机数生成一个数组。
·initArrayByRandomNoRepeat(int size):不重复的随机数生成一个数组。
·swap(int aIndex, int bIndex):交换数组中两个下标的值。
详细代码如下:
1 /** 2 * 数组基类 3 * Created by liuwei on 17/7/21. 4 */ 5 public abstract class BaseArray { 6 protected int[] mArray; 7 protected int mSize; 8 protected int mMaxSize; 9 public BaseArray(int maxSize){ 10 mMaxSize = maxSize; 11 mArray = new int[mMaxSize]; 12 mSize = 0; 13 } 14 public abstract int insert(int e) throws ArrayIndexOutOfBoundsException; 15 public abstract int delete(int e); 16 /** 17 * 随机数创建数组 18 * @param size 19 * @return 20 */ 21 public void initArrayByRandom(int size) throws ArrayIndexOutOfBoundsException { 22 if (size > mMaxSize) { 23 throw new ArrayIndexOutOfBoundsException("size不能大于数组的maxSize"); 24 } else { 25 mSize = size; 26 for (int i = 0; i < size; i++) { 27 mArray[i] = getRandomInt(size); 28 } 29 } 30 } 31 /** 32 * 随机数创建数组(无重复) 33 * @param size 34 * @return 35 */ 36 public void initArrayByRandomNoRepeat(int size) throws ArrayIndexOutOfBoundsException { 37 if (size > mMaxSize) { 38 throw new ArrayIndexOutOfBoundsException("size不能大于数组的maxSize"); 39 } else { 40 mSize = size; 41 int n = 0; 42 boolean noRepeat; 43 while (n < mSize) { 44 noRepeat = true; 45 int temp = getRandomInt(mSize * 10); 46 for (int i = 0; i < n; i++) { 47 if (temp == mArray[i]) { 48 noRepeat = false; 49 break; 50 } 51 } 52 if (noRepeat) { 53 mArray[n] = temp; 54 n++; 55 } 56 } 57 58 } 59 } 60 public void initArray(int[] array) { 61 mSize = array.length; 62 for (int i = 0; i < mSize; i++) { 63 mArray[i] = array[i]; 64 } 65 } 66 public int size(){ 67 return mSize; 68 } 69 /** 70 * 获取一个随机整数 71 * @return 72 */ 73 public int getRandomInt(int bounder){ 74 return new Random().nextInt(bounder); 75 } 76 public void display(){ 77 for (int i = 0; i < mSize; i++) { 78 print(mArray[i] + ", "); 79 } 80 println(""); 81 } 82 protected void swap(int aIndex, int bIndex) { 83 int temp = mArray[aIndex]; 84 mArray[aIndex] = mArray[bIndex]; 85 mArray[bIndex] = temp; 86 } 87 protected void print(Object o){ 88 Logger.print(o); 89 } 90 protected void println(Object o){ 91 Logger.println(o); 92 } 93 }
看到这个类比较长也不要害怕,它里面只是包含一些工具性质的方法,目的是为我们提供方便,使我们在后续的二分查找和排序中可以更加专注于算法之中。
接着通过继承 BaseArray 创建一个有序数组类 OrderedArray ,普通的插入对于数组来说再简单不过了,直接往对应的下标中赋值即可,就不多说了,这里为创建的实体数组添加一个有序插入(正序)的方法,初步想了一下有序插入大致需要三步:
1、从数组的0下标开始往后找,直到发现大于带插入的值时停下,记录下标。
2、从数组的最后一个下标开始依次后移一位,直到第一步中记录的下标。
3、将带插入的值赋给第一步中纪律的下标。
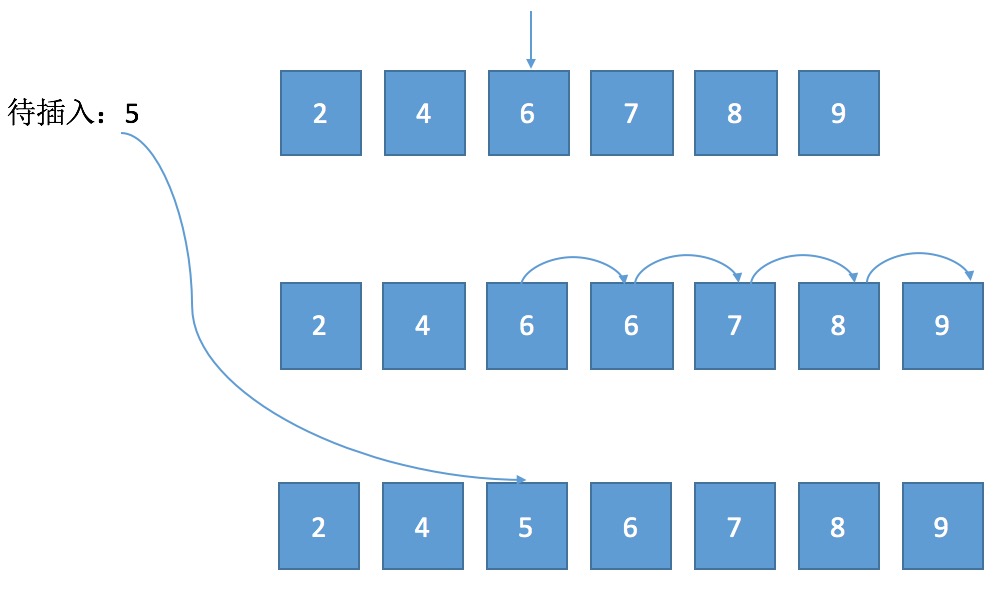
详细代码如下:
1 /** 2 * 有序插入 3 */ 4 @Override 5 public int insert(int e) throws ArrayIndexOutOfBoundsException { 6 if (mSize == mMaxSize) { 7 throw new ArrayIndexOutOfBoundsException("数组已经满了"); 8 } 9 int i; 10 for (i = 0; i < mSize; i++) { 11 if (e < mArray[i]) break; 12 } 13 for (int j = mSize; j > i; j--) { 14 mArray[j] = mArray[j-1]; 15 } 16 mArray[i] = e; 17 mSize++; 18 return i; 19 }
二、线性查找
如果我们想从一个有序数组中查找一个元素有两种方法,线性查找和二分查找,线性查找就是最最常规的方法,从数组的0下标开始依次往后查找,直到找到要查找的元素,则查找成功,如果在数组中不存在带查找的元素,因为是有序数组,我们只需找到比待查元素大时即可退出。
线性查找详细代码如下:
1 /** 2 * 线性查找 3 * @param e 4 * @return 5 */ 6 public int findByLiner(int e) { 7 for(int i = 0; i < mSize; i++) { 8 if (e == mArray[i]) { 9 return i; 10 } else if (mSize > (i + 1) &&e > mArray[i] && e < mArray[i + 1]) { 11 return -1; 12 } 13 } 14 return -1; 15 }
线性查找比较简单,这里不过过多分析,很容易我们就能看出来线性查找的平均比较次数是数组元素个数的一半,所花费的时间与元素个数(假设是N)的一半成正比,在算法中描述时间复杂度是我们通常忽略常数,习惯性用大O表示法,所以线性查找的时间复杂度表示为:O(N)。
三、二分查找
二分查找类似于我们朋友聚会喝酒时玩的猜字游戏,游戏中,通常会给出一个范围例如0-100,然后由一方从中默默挑出一个字让你来猜,你猜的时候他会告诉你是否猜中,或者比他挑的字大或小。为了尽快的猜中,我们会选择首先从中间开始猜,根据对方的提示我们来选择偏大的一半还是偏小的一半然后再从新范围的一半开始猜,这样很快就能猜中答案。
具体的算法思路如下(假设数组下标范围是0-N):
1、首先定义两个下标边界变量lowBounder=0,highBounder=N-1
2、让当前下标为lowBounder和highBounder的中间与待查找的元素比较:
·如果相等,则查找成功。
·如果小于待查找元素,则将lowBounder赋值为当前下标+1。
·如果大于带查找元素,则将hightBounder赋值为当前下标-1。
·如果此过程发现lowBounder大于highBounder,则表示未找到。
3、循环执行第二步。
详细代码如下:
1 /** 2 * 二分查找 3 * @param e 4 * @return 5 */ 6 public int findByHalf(int e) { 7 int lowIndex = 0; 8 int highIndex = mSize - 1; 9 int currentIndex; 10 while(true){ 11 currentIndex = (lowIndex + highIndex) / 2; 12 if (e == mArray[currentIndex]) { 13 return currentIndex; 14 } else if (lowIndex >= highIndex) { 15 return -1; 16 } else if (e > mArray[currentIndex]) { 17 lowIndex = currentIndex + 1; 18 } else { 19 highIndex = currentIndex - 1; 20 } 21 } 22 }
单从思路我们就可以分析出二分查找的平均查找时间要比线性查找快的多。
它的时间复杂度为:O(logN)。
作者:CodingBlock
出处:http://www.cnblogs.com/codingblock/
本文版权归作者和共博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
如果文中有什么错误,欢迎指出。以免更多的人被误导。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号