
RepLKNet、depthwise conv、Depthwise Separable Conv、
1.RepLKNet
由于ResNet的残差结构会跳过一些网络结果,所以其实resnet的有效深度其实并不深,所以有效感受野并不大。而大kernel模型不但有效感受野更大而且更像人类(shape bias高)。这也可能是传统CNN虽然在ImageNet上跟Transformer差不多,但在下游任务上普遍不如Transformer的原因。
Transformer可能关键在于大kernel而不在于self-attention的具体形式。
上游任务已经饱和,但在下游任务中还有用的。
2.depthwise conv
depthwise conv、MobileNet、Depthwise Separable Conv:这里提到了两种卷积,分别为depthwise conv和Depthwise Separable Conv。
-
depthwise conv:下图是depthwise conv,其中:
每个卷积核(Filter)的channel都为1
输入特征矩阵channel=卷积核个数=输出特征矩阵channel
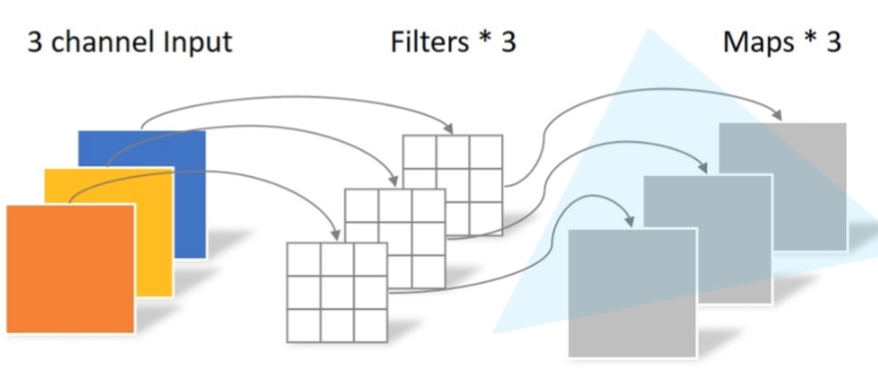
-
Depthwise Separable Conv:就是depthwise conv+1x1的普通卷积

depth-wise卷积的FLOPs更少没错,但是在相同的FLOPs条件下,depth-wise卷积需要的IO读取次数是普通卷积的100倍,因此,由于depth-wise卷积的小尺寸,相同的显存下,我们能放更大的batch来让GPU跑满,但是此时速度的瓶颈已经从计算变成了IO。自然desired小尺寸卷积应该有的快速的特性,也无法实现。(参考:Depth-wise Convolution)
3.InceptionNeXt
ConvNeXt由于访问内存需要的代价比较大,导致训练的时候数据的吞吐量比较小,导致训练速度变慢。
【问题】为什么吞吐量比较大?
加速large-kernelbased CNN models并保留它的性能的方法:受到Inceptions的启发,使用large-kernel depthwise convolution从通道上将大卷积分为small square kernel, two orthogonal band kernels, and an identity mappin四个部分。
depth-wise卷积的FLOPs更少没错,但是在相同的FLOPs条件下,depth-wise卷积需要的IO读取次数是普通卷积的100倍,因此,由于depth-wise卷积的小尺寸,相同的显存下,我们能放更大的batch来让GPU跑满,但是此时速度的瓶颈已经从计算变成了IO。自然desired小尺寸卷积应该有的快速的特性,也无法实现。(参考:Depth-wise Convolution)
一般使用depthwise convolution来使用大的卷积核,并且大的卷积核大小会导致较低的速度。然而,使用较小的内核大小会限制感受野,这可能会导致性能下降。
depthwise convolution并不是对于所有通道的计算都是昂贵的,所以使用Inception中类似的方法。
对于处理通道,1/3的通道以3×3的内核进行,1/3的通道以1×k进行,而其余1/3的通道则以k×1进行。
与其他使用大卷积核的论文不同,我们以效率为目标,以一种简单、速度友好的方式分解大型内核,同时保持相当的性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号