
装机教程、深度学习 GPU(显卡)选购
装机教程
深度学习 GPU(显卡)选购
显卡的涡轮散热不一定比风扇散热差,就是吵一点。涡轮主要用于服务器中,单方向散热。多风扇散热会将热量向四周扩散
服务器中一般用涡轮显卡,涡轮显卡贵一点
显卡
下面是4090、4080、3090、3080的参数对比:
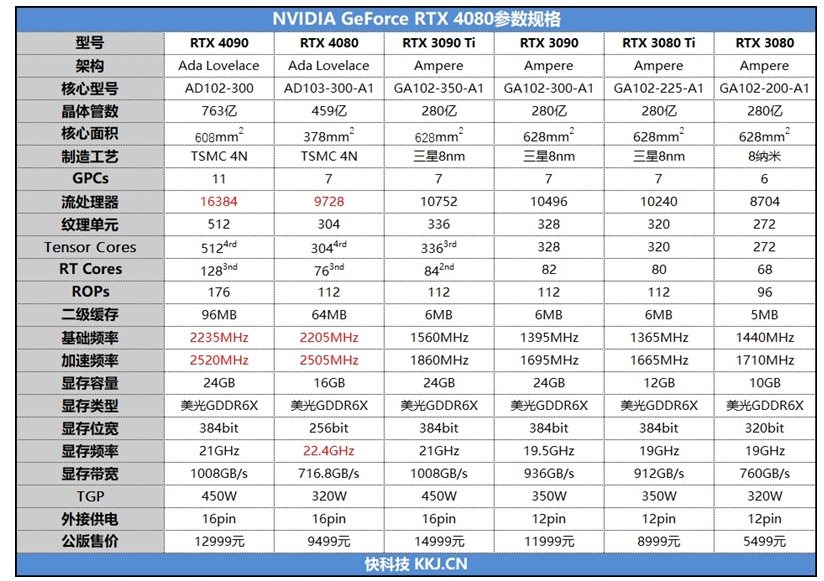
上图来自:4090与4080、3080与3090。
显卡对比:
- 4090与4080相比,肯定是4090性能好得多。
- 4080与3090相比:从深度学习比较关注的流处理数量和显存来说,3090比4080性能更好。4080的16G的显存对于深度学习的实验来说实在有点小。
- 4090与3090相比:从性价比角度,直接入手4090(参考自:NVIDIA RTX 4090 与 RTX 3090 深度学习基准测试)。
- 3080的显存太小,这里就不关注了。
价格说明:上述价格为公版价格,如果买非公版的,那么价格会高于公版价格,价格可能高个一千左右。
【注】公版与非公版:一般来说,非公版显卡会在公版显卡的基础上做一些改造,甚至增加一些实用功能,甚至比公版更好用。这就类似于把谷歌的安卓做了自己的定制化改造。缺点就是各家厂商生产的显卡质量层次不齐,有的价格甚至比公版还贵。但是,如果公版显卡太抢手,非公版显卡也是一个很好的替代项。
重要参数说明:(参考:炼丹志 | 2021显卡挑选指南)
- 显卡架构:不同级别的显卡采用的架构不同,不同架构的显卡不能直接比较CUDA核心数量,比如GTX960采用的是麦克斯架构,GTX 1050Ti采用帕斯卡架构。1024个CUDA的960性能不如768个CUDA的1050Ti。可以这样理解,架构越新,画师实力越强。
- 流处理器数量:流处理器数量也就是CUDA核心数量,流处理器可以理解为显卡中的画师,图均由画师一张张绘制而成。比如3090就有10496个画师,3080就有8704个画师。一般情况下,画师越多,效率越高,游戏帧数也越高。
- 核心频率(基础频率、加速频率):核心频率可以理解为显卡画师画画的速度,赶稿的时候和松懈的时候效率明显不一样。同架构同CUDA数量频率越高,效率越高。
- 纹理单元:纹理单元越多,性能越强。
- 显存容量/显存位宽/显存频率:画师画完画后还需要将画放到指定的房间供CPU调用,将画送给房间也是由专用的货车来完成。
显存容量可以理解为房间大小,画面越精细,需要的画越多,需要的房间也越大,对显存容量要求越高。
显存位宽可以理解为货车大小,显存位宽越大,每一次运输的数据更多,一般分为128bit、192bit、256bit、384bit。
显存频率指货车运行速度,频率越高,运行效率越高。
【注意】并不是显存位宽越大,性能越高,显存容量并不是显卡性能决定性因素,显卡性能最重要的是显卡架构以及流处理器数量,很多商家就喜欢用XXX GB高性能显卡忽悠人。
补充说明
显卡性能排行榜:
公版显卡和非公版显卡有啥区别?
【公版显卡和非公版显卡有啥区别?】
请大家说说自己深度学习用的显卡是公版还是非公的?:最重要的是如何防尘和控温,只要满足条件,公版非公都一样。
英伟达三大系列显卡
英伟达旗下的显卡产品大致有三大系列:GeForce、Quadro与Tesla。这三大系列产品功能侧重有所不同,价格差距也很大,GeForce性价比最高,主要用于游戏画面处理;Quadro性价比居中,主要用于作图,Tesla主要用于搭建GPU服务器。
GeForce系列
因为GeForce系列性价比相对较高,也是大家用来跑深度学习程序的首选。
GeForce系列前缀一共有4种,性能由高到低排列为:GTX > GTS > GT > GF。常见的一般就是GTX和GT,GTS和GF显卡一般较老,已经不多见了。
在GTX系列下,还有泰坦子系列,也就是GTX****Ti。这个系列属于GeForce系列中的豪华版,性能方面代表了当时代单芯显卡的最高水平。在深度学习中应用也最广。我们熟悉的GTX1080Ti、GTX3080Ti都出自这个系列。
字母后边的数字代表显卡的型号,其中前两位数字代表产品是第几代,10之后就是每次进10了,比如GTX1080、GTX2080等等。之后的两位数字代表它的小版本,一般来说同代显卡这个数字越大性能就越强。
例如GTX3080Ti就是一块第30代游戏级显卡,就是比GTX3060Ti性能更强。
除了泰坦的加强版Ti系列外,还有,SE(阉割版),M(移动版),MX(移动加强版),同型号的显卡性能比较:Ti>无后缀>SE>MX>M。(10代显卡之后,m和mx的命名方式也几乎绝版)
当然,原厂生产的GTX泰坦系列显卡通常被称为公版显卡,除了原厂生产的GTX系列显卡之外,我们还可以看到国内的厂商购买英伟达的芯片设计专利,自行设计PCB、散热方案并生产的显卡,这种显卡成为非公版。
一般来说,非公版显卡会在公版显卡的基础上做一些改造,甚至增加一些实用功能,甚至比公版更好用。这就类似于把谷歌的安卓做了自己的定制化改造。缺点就是各家厂商生产的显卡质量层次不齐,有的价格甚至比公版还贵。但是,如果公版显卡太抢手,非公版显卡也是一个很好的替代项。
Quadro系列
另一种我们深度学习可能会用到的就是Quadro系列,这个系列一般用P***来表示,比如P400、P1000等。这个系列相同配置价格要比GF系列贵些,常常被公司买来部署云计算服务器,如果线上租用显卡,也可能会选到这个系列。
显卡还有个参数就是显存,跟内存是一个道理,显存越大,可以缓存的内容就越多。对于非常吃显存的图像类深度学习程序来说,显存太小的显卡批处理就不能调太大,否则会程序会报错。
gtx和rtx有什么区别?:
简单理解就是,GTX是高端旗舰级别的独立显卡,RTX是采用图灵架构且拥有光线追踪技术的高端旗舰级独立显卡,rtx无论创作还是游戏,能够带来更爽的体验。
先说结论,RTX图灵架构支持光线追踪技术,而gtx可以说就是上一代显卡了。实际上目前市面上只有一款游戏实际支持光线追踪就是战地5。性能上RTX2070往上对上一代10系列并没有全面吊打但是性能提升还是非常大的。(记忆中是有百分之45左右?对标的是1080ti跟2070印象中这里不准确实际游戏应该是达不到)(参考:gtx和rtx有什么区别?)
装机
电脑是一个整体,是要遵循木桶效应的,因此合理的硬件组合就非常重要。
在选择硬件之前,我们先把电脑硬件对深度学习性能影响的重要程度排个序:
GPU>CPU≈主板(CPU主板相辅相成)>内存>硬盘>电源>机箱(装的下就行)
再以这个顺序去选择硬件,并控制整体预算。由于特殊时期,显卡市场太混乱,变化太快,所以以上数据仅供参考(一般来说同级别下显存越大深度学习效率越高,除了个别打鸡血版本)。理论TFLOPS数据来源:FP32 性能(单精度 TFLOPS)GPU 基准测试列表
TFLOPS
TFLOPS是Tera和Floating-point operations per second词组的组合,后者的意思是每秒浮点运算次数,Tera则是万亿的意思,合起来就是每秒浮点运算多少万亿次。因为现在的图像是分成像素点来处理的,每个点的色彩都要进行浮点运算,然后组合成一幅图片,所以这个参数就说明了显卡或者GPU每秒能处理多少个像素点。(参考自:链接)

3090:可以并行。对于我的模型,可能需要两块3090才能运行。
4090:无法并行,单卡性能比3090高20%左右。怕后期不更新,始终不能并行。
v100:32G,6万。
a6000:48GB,三万多。
A100:80G,10万。
购买三张显卡。
显卡放在一起怕散热会有问题,就比如现在正在用的显卡,
cpu:i9-10850
主板:z590
电源:
1颗7K83 64核心
256g内存
2tbssd
4张4090
2个2000w电源
参考:链接
-
Tensor Core:一个进行矩阵计算的东西,可以加快矩阵计算。
-
张量内存加速器 (TMA) 单元:Tensor Core在进行矩阵计算之前,需要将矩阵从全局内存拷贝到共享内存中,然后Tensor Core从共享内存取出数据进行计算。张量内存加速器 (TMA) 单元就是在Tensor Core计算矩阵的时候就开始将下一个需要计算的矩阵拷贝到共享内存中。GPU计算性能很大一部分取决于从全局内存拷贝到共享内存的速度,一般来说Tensor Core利用率约为 45-65%,也就是说Tensor Core很多时间都在等数据从全局内存拷贝到共享内存。
-
内存带宽:数据从全局内存拷贝到共享内存的速度。
-
GPU中有各种内存,它们的速度大概如下:L2 缓存中的矩阵内存块比全局 GPU 内存(GPU RAM)快 3-5 倍,共享内存比全局 GPU 内存快约 7-10 倍,而 Tensor Cores 的寄存器比全局 GPU 内存快约 200 倍。我们在以下架构上有以下共享内存大小:
Volta (Titan V):128kb 共享内存/6 MB L2
Turing(RTX 20s 系列):96 kb 共享内存/5.5 MB L2
Ampere(RTX 30s 系列):128 kb 共享内存/6 MB L2
Ada(RTX 40s 系列):128 kb 共享内存/72 MB L2


 浙公网安备 33010602011771号
浙公网安备 33010602011771号