

RCNN、Fast RCNN和Faster RCNN总结
参考:https://www.bilibili.com/video/BV1af4y1m7iL?p=1
1.RCNN(Region-CNN)
1.1 RCNN的总述
1.得到候选框:通过Selective Search算法在每张图片中生成1k~2k的候选区域。ss算法具体如何实现?
2.特征提取:将候选框中的图片缩放成227x227,然后通过包含CNN的神经网络对每个候选区域进行特征提取,并拉直成一维向量
3.SVM分类:将一维向量送入SVM分类器中预测属于各个类的概率,然后利用非极大值抑制剔除一些建议框
4.修正候选区域:利用回归器修正候选区域位置
1.2 RCNN的细节详述
1.2.1 特征提取
将2000个候选区域都缩放到227x227pixel,接着将每个候选区域输入事先训练好的AlexNet CNN网络,每个候选区域获取4096维的特征,从而得到2000×4096维矩阵。 如何缩放?
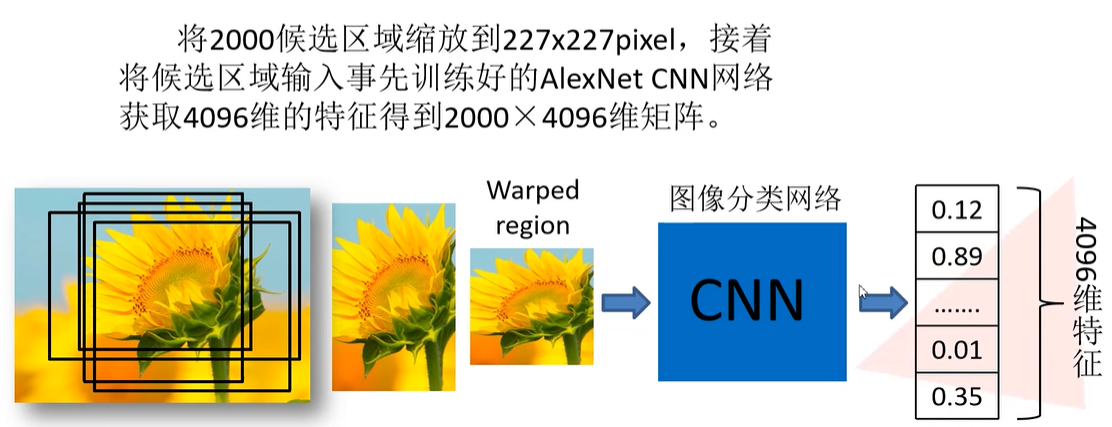
1.2.2 SVM分类
将2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘(不需要映射到高维上面的吗?), 获得2000×20维矩阵表示每个建议框是某个目标类别的得分。分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除一些建议框,得到该列即该类中得分最高的一些建议框。
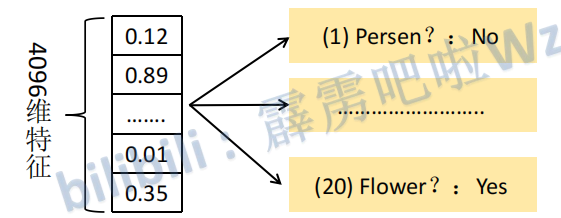
使用20个SVM的原因:这里是假设有二十个类别。而SVM是一个二分类,所以20个SVM就可以进行20个分类.
1.2.3 非极大值抑制剔除建议框
选出每一类(列)中SVM得分最高的建议框A,然后计算A和其他建议框的IOU值。假设A和B的IOU值大于给定阈值,这就说明A和B重合过多,就剔除B。因为重合过多就说明A和B实际框住的是同一个物体,但是A的得分高,效果更好,故保留A剔除B。当阈值的设置合适时,就可以保证每个物体上只有一个框。每一行只保留得分最高的类别,此类别就是框住的类别。
存在的问题:
- 当两物体之间的距离很近且给定的阈值太小时,那么容易导致两个物体中有一个物体的框被剔除掉(漏检)
- 不能保证每个物体都有框(漏检)
- 如果A框到没有物体的地方或A与其他框的重合不多,就会导致A被保留下来(误检)
1.2.4 修正候选区域
对NMS处理后剩余的建议框进一步筛选。接着分别用20个回归器对上述20个类别中剩余的建议框进行回
归操作,最终得到每个类别的修正后的得分最高的 bounding box。 如何进行回归操作呢?
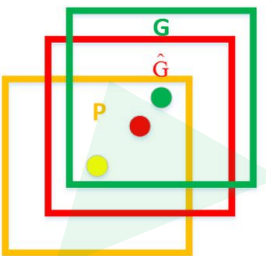
如下图,黄色框口P表示建议框Region Proposal, 绿色窗口G表示实际框Ground Truth,红色窗口
表示Region Proposal进行回归后的预测窗口,可以用 最小二乘法解决的线性回归问题。
1.3 RCNN存在的问题
1.测试速度慢: 测试一张图片约53s(CPU)。用Selective Search算法 提取候选框用时约2秒,一张图像内候选框之间存在大 量重叠,提取特征操作冗余。
2.训练速度慢: 过程及其繁琐
3.训练所需空间大: 对于SVM和bbox(bounding box)回归训练,需要从每个图像中的每个目标候选框提取特征,并写入磁盘。对于非常深的网络( 和网络深浅有什么关系?),如VGG16,从VOC07 训练集上的5k张图像上提取的特征需要数百GB的存储空间。
2.Fast RCNN
2.1 Fast RCNN的总述
1.得到候选框:利用ss算法(Selective Search)在一张图像生成1K~2K个候选区域,随机选取64个候选区域
2.特征提取:将整张图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵
3.一个神经网络进行分类和生成bbox的回归参数:将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到目标所属的类别和bbox的回归参数 。(ROI:Region of Interest)
Fast RCNN与RCNN区别:RCNN中是输入特征区域对应的图像(227x227)得到相应的特征向量,然后将特征向量输入到SVM进行分类、利用回归器修正候选区域位置
2.2 Fast RCNN的细节详述
2.2.1 候选区域选取
随机选取候选区域:在Fast RCNN中并没有使用所有的候选框,而是随机从正样本和负样本拿出总共64个。正样本是指候选框与真实值之间的IOU值大于0.5。负样本是指候选框与真实值之间的IOU值在[0.1,0.5),且是从IOU最大的开始采样(先采样正样本,其余的从负样本的最大IOU开始取,总共取64个)。
2.2.2 ROI pooling层缩放
首先将每个候选框的特征图分割成7*7,总共49块,然后对每一块进行max pooling(每块中取像素最大的点)。
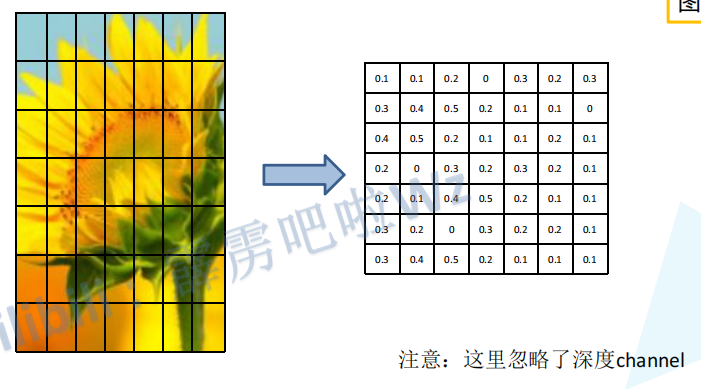
注:特征图肯定不是上图那个样子,这里只是为了方便而这么画的
2.2.3.分类器和bbox回归器
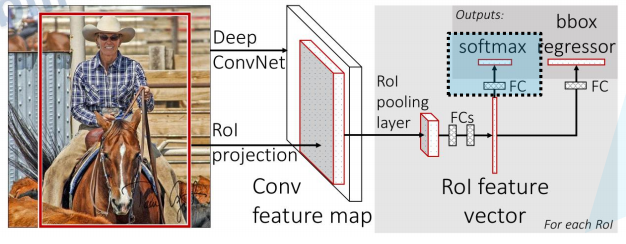
上图中除了上面标注FCs以外的所有长方体块都是表示图像的矩阵。
从上图可知,
-
首先将整张图片输入进行特征提取的到特征图。
-
然后将候选框在特征图中框出的区域输入到ROI pooling层中,得到7*7的矩阵。
-
再将7*7矩阵展平以后输入到两个全连接层中得到ROI feature vector。
-
然后将ROI feature vector分别输入到两个不同的全连接层得到分类的结果和bbox的回归参数。输出分类结果的部分就叫分类器,输出bbox回归参数的就叫做bbox回归器。
分类器:输出N+1个类别的概率(N为检测目标的种类, 1为背景)共N+1个节点 。N+1个概率相加的结果为1。
bbox回归器:输出对应N+1个类别的候选边界框回归参数(dx, dy, dw, dh),即输出共(N+1)x4个节点。利用这些参数就可以计算出最终的预测框,计算公式如下:一个候选框预测出N+1个预测框吗?答:分类器得出此候选框属于哪一类,bbox回归器得出此候选框的此类的最终预测框

这里的dx§是dx的意思。
解释以下第一个公式 G x ^ = P w d x ( P ) + P x \widehat{G_x}=P_wd_x(P)+P_x Gx =Pwdx(P)+Px:这里的就是利用参数 d x ( P ) d_x(P) dx(P)和 P w P_w Pw来调节 P x P_x Px使其变得更加准确。可以更加准确的原因是最终的预测框会与真实框进行比较,然后调节参数 d x d_x dx,使得这个参数可以调节预测框去接近真实框。是这个公式,而不是其他的,作者是怎么得出这个公式的??
2.2.4 损失函数

这里的v是是什么意思,我不太明白?
Lcls(p,u) = - logpu,这里的Pu代表预测类别为u的概率
L l o c ( t u , v ) = ∑ i ∈ { x , y , w , h } s m o o t h L 1 ( t i u − v i ) L_loc(t^u,v) = \sum_{i\in {\{x,y,w,h\}}}smooth_{L_1}(t_i^u-v_i) Lloc(tu,v)=i∈{x,y,w,h}∑smoothL1(tiu−vi):就是两框之间的差距
s m o o t h L 1 ( x ) = { 0.5 x 2 , i f ∣ x ∣ < 1 ∣ x ∣ − 0.5 , o t h e r w i s e smooth_{L_1}(x)= \left\{ \begin{array}{lr} 0.5x^2, & if |x|<1 \\ |x|-0.5, & otherwise \end{array} \right. smoothL1(x)={0.5x2,∣x∣−0.5,if∣x∣<1otherwise
v x = G x − P x P w v_x=\frac{G_x-P_x}{P_w} vx=PwGx−Px: G x G_x Gx为真实框对应的x
[u=>1]:方括号内的条件满足则为1,不满足则为0。当u=0时表示背景,而当u为其他大于一的数时表示类别标签。也就是说当框内的东西为背景时,是没有边界框回归损失,因为背景可没有被框住。
2.3 Fast RCNN与RCNN框架之间的对比


Fast RCNN特征提取、分类、参数回归都融合成在了一个CNN网络中了,而RCNN分成了三个部分。
3.Faster RCNN
同样使用VGG16作为网络的backbone(主干),推理速度在GPU上达到5fps(包括候选区域的生成),准确率也有进一步的提升。
Faster RCNN=Fast RCNN+RPN
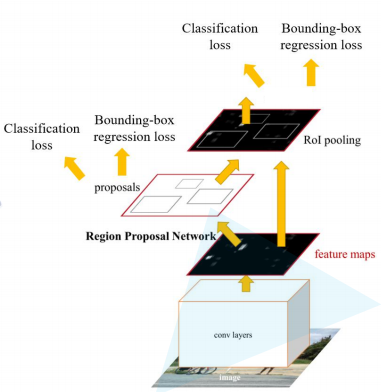
3.1 Faster RCNN的总述
1.得到候选框:将整张图像输入conv层得到特征图,将特征图输入到RPN中得到候选框
2.特征提取:将RPN生成的候选框投影到特征图上获得相应的特征矩阵
3.一个神经网络进行分类和生成bbox的回归参数:将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到目标所属的类别和bbox的回归参数 。(ROI:Region of Interest)
Faster RCNN与Fast RCNN的区别:Faster RCNN利用RPN获取候选框。Fast RCNN利用ss算法获取候选框。
下图是Faster RCNN的整体架构
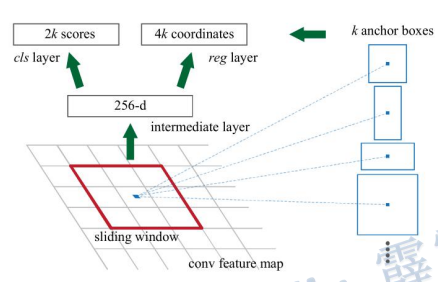
3.2 RPN(Region Proposal Network)
3.2.1 RPN的构成
RPN的作用是筛选出可能会有目标的框”。RPN是用一个全卷积网络来实现的,可以与检测网络共享整幅图像的卷积特征,从而产生几乎无代价的区域推荐。
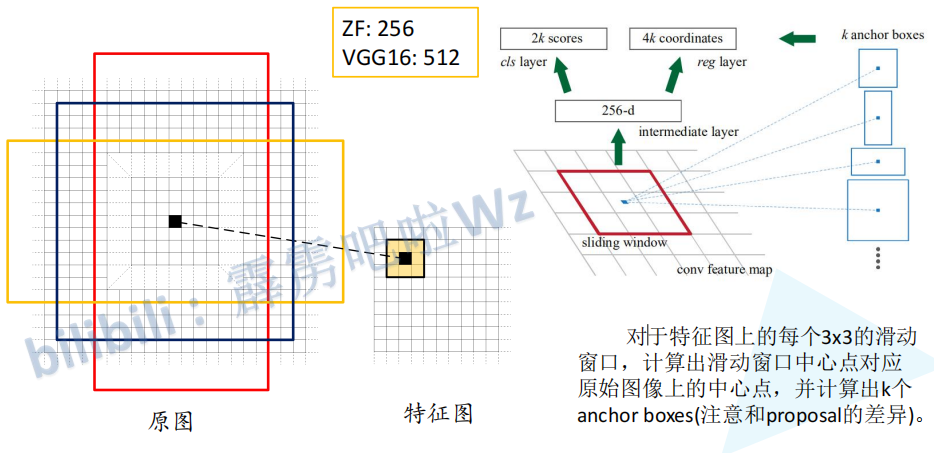
图中右边的解释:sliding window(滑动窗口)在 conv feature map(特征图)滑动。每滑动到一个区域,输出一个一维的向量(256个元素)。将这个一维向量分别输入到两个全连接层中,分别产生2k个score和4k个coordinate。下面对上面这句话进行补充解释:
一维向量的生成:一维向量有256个元素,这是因为特征图是由ZF生成的,ZF生成的特征图有256个channel。如果特征图是由VGG16生成的话,特征图就有512个channel,此时一维向量就有512个元素。一维向量的生成过程为:利用256或512个3*3的conv(步长为1,padding为全零填充)在特征图上滑动,从而生成一个和特征图shape一致的图,这个图的每一个像素点下的256或512个channel都代表一个上面提到的一维向量。每个一维向量都预测出k个anchor box(论文种k=9)。
9个anchor box:k代表k个anchor box,anchor boxes指的是以滑动窗口中心点对应原始图像上的中心点为中心的一些框。k一般为9,即9种anchor box。9种anchor box:anchor box的大小有{ 12 8 2 , 25 6 2 , 51 2 2 128^2,256^2,512^2 1282,2562,5122}三种,anchor box的宽高比例有{1:1,1:2,2:1}三种。所以在每个位置(每个滑动窗口)在原图上都对应3*3=9个anchor(作者说这些是经验所得)。下面是9个anchor的示意图:
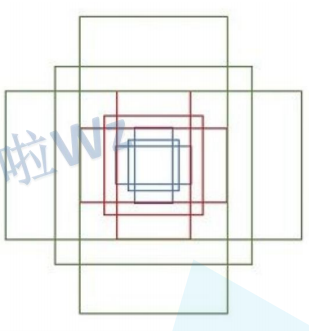
那么问题来了!ZF感受野是 171 ,VGG感受野是 228 (感受野:特征图的一个像素点对应原图多大一块),对于VGG来说,输入网络的一维向量只能代表原图中 22 8 2 228^2 2282大小的面积,而在预测到的anchor中有两种面积是大于 22 8 2 228^2 2282,分别为:{ 25 6 2 , 51 2 2 256^2,512^2 2562,5122}。为什么可以通过面积小的预测出面积大的区域呢?答:比如你看到一个物体的一部分就可以猜出这个物体是什么。
anchor box的两个预测值:每个anchor box有两个score,分别表示anchor box中为背景的概率和anchor box中为目标的概率,两个score相加不一定为一。每个anchor box有四个coordinate,这四个coordinate是anchor box的回归参数(dx, dy, dw, dh),通过(dx, dy, dw, dh)将anchor box调整成proposal(候选框)。
score和coordinate的形成:利用2k个1*1的卷积核对256-d进行卷积,从而使得每一个像素点对应的一维向量都输出2k个score。利用4k个1*1的卷积核对256-d进行卷积,从而使得每一个像素点对应的一维向量都输出4k个coordinate。这里的score核coordinate为什么是对应的?明明是通过两个不同的全连接层生成的?
候选框最终的确定(举例):对于一张1000x600x3的图像,大约有60x40x9=20k个anchor,忽略跨越边界的anchor以后,剩下约6k个anchor。将6k个anchor通过(dx, dy, dw, dh)调整成6k个proposal(候选框)。候选框之间存在大量重叠,基于候选框的cls得分,采用非极大值抑制剔除重叠框,IoU设为0.7,这样每张图片只剩2k个候选框。
3.2.2 RPN的训练与损失函数
训练RPN过程中的数据采样:在一张图片中所有的anchor中采样256个anchor,这256个anchor中有128个正样本和128个负样本。如果正样本不足128个,就用负样本填充,如正样本有100个,那负样本就有156个。
正样本:i)样本与gt的IOU大于0.7。ii)样本是与gt相交中IOU最大的
负样本:与所有的gt的IOU都小于0.3的样本
RPN的损失函数:
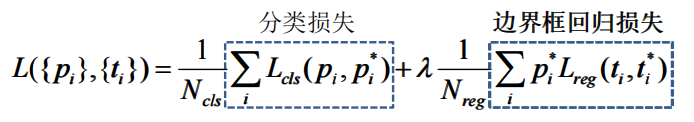
p i p_i pi表示第i个anchor中真实标签的score,如某一个anchor的目标和背景的score分别为0.9和0.2,若anchor中是背景,那么 p i = − l n 0.2 p_i=-ln0.2 pi=−ln0.2。
各个参数的意义:
p i ∗ p^*_i pi∗当为正样本时为 1,当为负样本时为 0。
t i t_i ti表示预测第 i个anchor的边界框回归参数。
t i ∗ t^*_i ti∗表示第i个anchor对应的gt的边界框回归参数。
N c l s N_{cls} Ncls表示一个min-batch中的所有样本数量,即一次采样的数量,即256。
N r e g N_{reg} Nreg表示特征图上像素点的个数,约2400个。
补充解释:
为了简单,经常将 λ 1 N r e g \lambda\frac{1}{N_{reg}} λNreg1令成 1 N c l s \frac{1}{N_{cls}} Ncls1,因为两者差不多。
L c l s L_{cls} Lcls为softmax cross entropy,而不是BInary cross entropy,即某一个anchor的目标和背景的score分别为0.9和0.2。若anchor中是目标,那么 p i = − l n 0.9 p_i=-ln0.9 pi=−ln0.9。
如果这里 L c l s L_{cls} Lcls为BInary cross entropy时,每个anchor只需要一个score而不是两个。假设当背景的score为0.2时,就可以推断出目标的score为0.8。若anchor中是目标,则 p i = − l n 0.8 p_i=-ln0.8 pi=−ln0.8。
这里的边界框回归损失和Fast RCNN中的是一样的。
3.3 Faster RCNN的损失函数

与Fast RCNN的损失函数完全一致。
3.4 Faster R-CNN的训练过程
原论文中采用分别训练RPN以及Fast R-CNN的方法 看不懂!!:
(1)利用ImageNet预训练分类模型初始化前置卷积网络层参数,并开始单独训练RPN网络参数;
(2)固定RPN网络独有的卷积层以及全连接层参数,再利用ImageNet预训练分类模型初始化前置卷积网络参数,并利用RPN 网络生成的目标建议框去训练Fast RCNN网络参数。
(3)固定利用Fast RCNN训练好的前置卷积网络层参数,去微调RPN网络独有的卷积层以及全连接层参数。
(4)同样保持固定前置卷积网络层参数,去微调Fast RCNN网络的全连接层参数。最后RPN网络与Fast RCNN网络共享前置卷积网络层参数,构成一个统一网络。
现在一般不采用原论文的方式,而直接采用RPN Loss+ Fast R-CNN Loss的联合训练方法 。
3.5 Faster RCNN、Fast RCNN与RCNN框架之间的对比
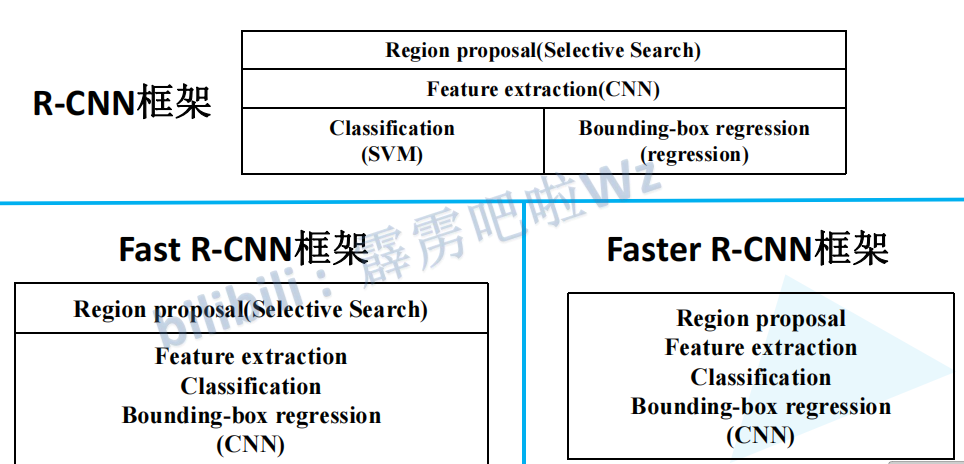
Fast RCNN特征提取、分类、参数回归都融合成在了一个CNN网络中了,而RCNN分成了三个部分。
Faster RCNN进一步将所有过程都融入了CNN中。
小知识补充:
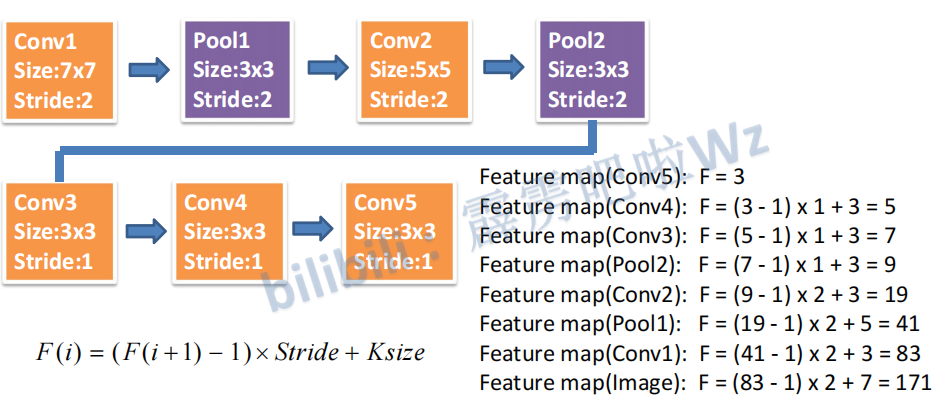
计算感受野
计算Faster RCNN中ZF网络feature map 中3x3滑动窗口在原图中感受野的大小。为什么这么计算呢?
1x1卷积核
1x1卷积核改变输出通道数(channels),而不改变输出的宽度和高度。1x1卷积的作用是减少或增加channel的数量(降维\升维、跨通道信息交互。(参考此链接)
4. FPN(Feature Pyramid Networks)
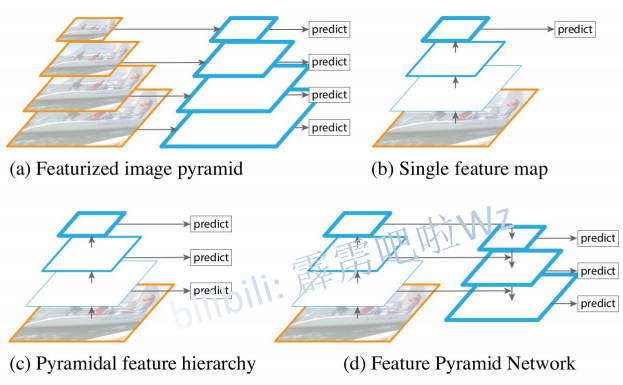
(a)将图片缩放到不同的大小,并将对不同大小的图片进行预测。此种方法要进行多次预测,效率很低。
(b)通过backbone(主干网络)得到最终的特征图,然后在特征图上进行预测,此种方法就是Fast RCNN中用到的方法。此种方法对小目标的预测效果不佳,这是因为大目标占有的像素点比较多,小目标占有的像素点比较少,即小目标对特征图的形成起到的作用比较小,即特征图中包含较少的小目标的信息。
(c)对每一层产生的特征图进行预测,和SDD算法类似
(d)对不同的特征图进行融合,也就是FPN。下图是FPN网络的一些细节。
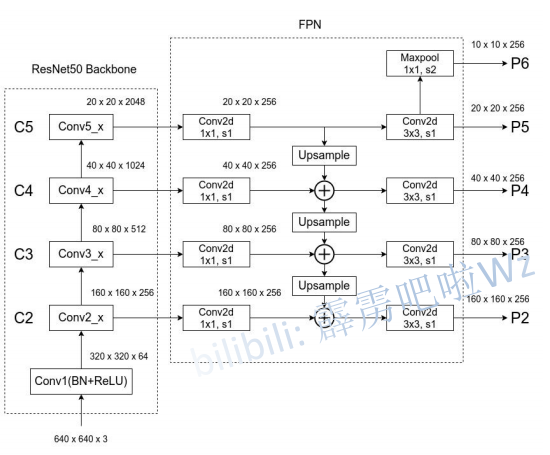
可以看到,FPN将每一层的特征图都经过256个1*1的卷积核变成channel为256的特征图。然后上层的特征图通过上采样使得特征图的shape和下层的特征图的shape一样,最后两特征图的对应位置直接相加,从而实现融合。P2到P5的特征图用于Fast RCNN,P2到P6用于RPN。(Faster RCNN=Fast RCNN+RPN)
Fast RCNN进行预测:对不同大小的目标采用不同的特征图进行预测,目标较小就使用较底层的特征图。因为较底层的特征图中小目标的信息损失没那么严重。这里的目标指的就是RPN得到候选框。通过以下公式得到此目标(候选框里的内容)需要利用哪个特征图进行预测:
k = ⌊ k 0 + l o g 2 ( w h 244 ) ⌋ k=\lfloor k_0+log_2(\frac{\sqrt {wh}}{244}) \rfloor k=⌊k0+log2(244wh)⌋
k 0 = 4 k_0=4 k0=4,w和h是候选框的宽和高,k指的是特征图P的下标。
RPN生成候选框:上一章中的Faster RCNN是在一个特征图上预测不同大小的anchor,但是在FPN中是在不同的特征图上预测不同大小的anchor,即P2到P6分别预测{ 3 2 2 , 6 4 2 , 12 8 2 , 25 6 2 , 51 2 2 32^2,64^2,128^2,256^2,512^2 322,642,1282,2562,5122},就是P2对应 3 2 2 32^2 322、P3对应 6 4 2 64^2 642……。每一尺寸都对应三个比例,即{1:2,1:1,2:1},如P2对应 3 2 2 32^2 322, 3 2 2 32^2 322又分为{1:2,1:1,2:1}。
思考题
我对为什么这些人能想到这些优化和方法的理解??

 浙公网安备 33010602011771号
浙公网安备 33010602011771号