

yolov1~v5的介绍
0. 计算机视觉
参考:https://zhuanlan.zhihu.com/p/94986199
https://zhuanlan.zhihu.com/p/32525231
https://www.bilibili.com/video/BV1yi4y1g7ro?from=search&seid=15480272248284580243
计算机视觉,图像分类是计算机视觉最基本的任务之一,但是在图像分类的基础上,还有更复杂和有意思的任务,如目标检测,图像分割等,见下图所示。其中目标检测是一件比较实际的且具有挑战性的计算机视觉任务,其可以看成图像分类与定位的结合,给定一张图片,目标检测系统要能够识别出图片的目标并给出其位置。
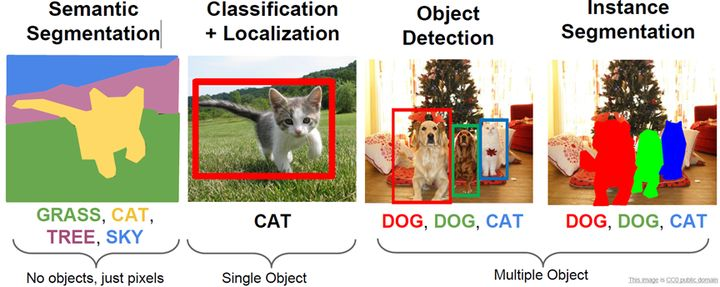
比较流行的目标检测算法可以分为两类,一类是基于Region Proposal的R-CNN系算法(R-CNN,Fast R-CNN, Faster R-CNN),它们是two-stage的,需要先使用启发式方法(selective search)或者CNN网络(RPN)产生Region Proposal,然后再在Region Proposal上做分类与回归。而另一类是Yolo和SSD,这类是one-stage算法,其仅仅使用一个CNN网络直接预测不同目标的类别与位置。第一类方法是准确度高一些,但是速度慢,但是第二类算法是速度快,但是准确性要低一些。
1.yolov1
1.1 原理以及参数的计算方法
1.1.1 原理:
yolo是将图像分割成不重叠的几个部分,每一部分称为一个grid cell。对于每一个grid,预测其中的某一点作为物体的中心(x,y),以此中心形成一个框,所以还必须预测此框的宽(w)和高(h),还必须预测的框框住物体的可能性confidence(置信度)。
故一个框包括五个属性,分别为x,y,w,h,confidence。而每一个grid一般包含几个这样的框。这样的框称为bounding box。
Yolo采用卷积网络来提取特征,然后使用全连接层来得到预测值。
1.1.2 参数的计算方法:
confidence = P*IOU,表示该bounding box中目标属于各个类别的可能性大小以及边界框匹配目标的好坏
P 是一个grid有物体的概率,在有物体的时候为1,没有物体的时候为0.(置信度在某些情况,似乎不是这么计算的)
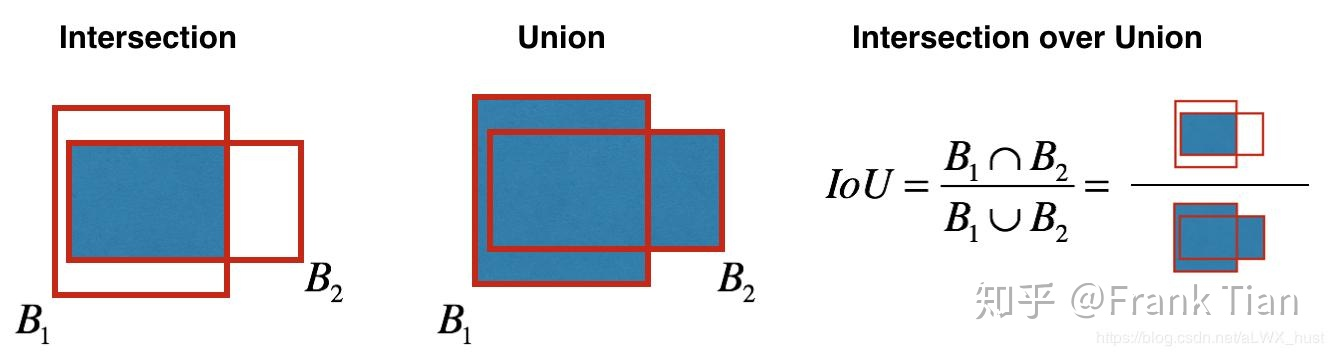
IOU:这个IOU的全称是intersection over union,也就是交并比,它反应了两个框的相似度。IOU预测的是bounding box和真实的物体位置的交并比,如下图所示:
x,y,w,h的计算方法:
如下图,中间框的左上角坐标为(a,b),物体中心坐标(x0,y0),grid的大小为(m,m),红色框的大小为(j,k),整个图片的大小为(p,q)。
则x=(x0-a)/m, y=(y0-b)/m, w=j/p,h=k/q,如此归一化的目的是为了计算的简单。具体如下图右侧:

通过(x,y)就可以还原出(x0,y0),这是因为此中心点在哪个框中是已知的。通过(w,h)就可以还原出(j,k),这是因为图片的大小是已知的。
1.1.3 一些其他参数
1.设每一个单元格要给出预测出C类,每个单元格有B个bounding box,而每个bounding box都有五个属性(x,y,w,h,confidence),则每个单元格需要预测(B5+C)个值。如果图片被分为SS个网格,那么最终需要预测(B*5+C)SS个值。
测试的时候,每一个目标的概率confidence*P©,confidence代表框住物体的概率、P©代表物体为C类的概率
2.ground truth是人为标注的框住物体的框。
3.每个框有多个bounding box,只取IOU最大的。
\4. 缺点:大家可能会想如果一个单元格内存在多个目标怎么办,其实这时候Yolo算法就只能选择其中一个来训练,这也是Yolo算法的缺点之一。
1.2 损失函数:

bounding box损失代表中心点(x,y)和框的(w,h)与实际的差距,confidence损失代表预测的框与实际的框的差距,
classes损失代表预测的分类与实际分类的差距。
让w加上平方根再相减的原因如下图:
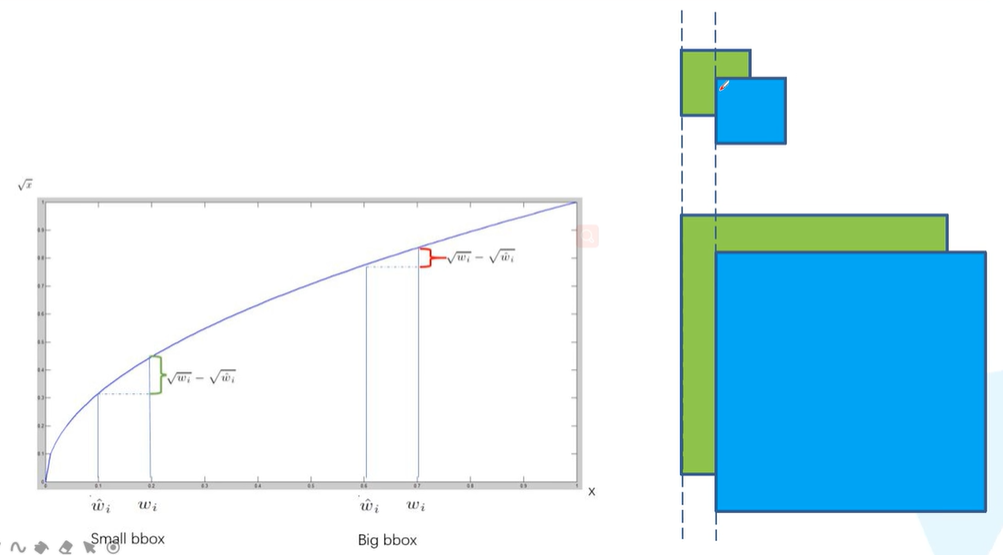
在图中我们可以看到,同样的偏移,对小图的影响会比较大,对大图的影响比较小。而“给w加上平方根再相减”才会使得:大图需要更大的偏移才能达到小图较小偏移的效果。
2.yolov2
参考:https://zhuanlan.zhihu.com/p/35325884
2.1 yolov2的七种优化
1.Batch Normalization:通过计算机像素点的平均值和方差,将像素点的值归一化。
2.High Resolution Classifier:我不懂,好像是用高分辨率的图像进行训练
3.Convolutional With Anchor Boxes:YOLOv2借鉴了Faster R-CNN中RPN网络的先验框(anchor boxes,prior boxes,SSD也采用了先验框)策略。RPN对CNN特征提取器得到的特征图(feature map)进行卷积来预测每个位置的边界框以及置信度(是否含有物体),并且各个位置设置不同尺度和比例的先验框,所以RPN预测的是边界框相对于先验框的offsets值(其实是transform值,详细见Faster R_CNN论文),采用先验框使得模型更容易学习。所以YOLOv2移除了YOLOv1中的全连接层而采用了卷积和anchor boxes来预测边界框。为了使检测所用的特征图分辨率更高,移除其中的一个pool层。
4.Dimension Clusters:在Faster R-CNN和SSD中,先验框的维度(长和宽)都是手动设定的,YOLOv2采用k-means聚类方法对训练集中的边界框做了聚类分析。因为设置先验框的主要目的是为了使得预测框与ground truth的IOU更好,所以聚类分析时选用box与聚类中心box之间的IOU值作为距离指标:
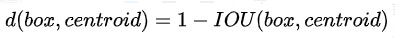
5.Multi-Scale Training:模型只有卷积层和池化层,所以模型可以输入的图像的尺寸可以不同。所以输入不同尺寸的图片进行训练也是可行的。这样同一个模型其实就可以适应多种大小的图片了。
6.Direct location prediction:我不懂,可能是使得anchor在一个cell中,(需要去看 Faster RCNN,看anchor是什么)
7.Fine-Grained Features:像残差网络一样,将底层的信息和高层的信息进行融合
yolov2的骨干网络:Darknet-19
3.yolov3
问题:Faster R-CNN中RPN网络的先验框(anchor boxes,prior boxes)是什么??

 浙公网安备 33010602011771号
浙公网安备 33010602011771号