

OpenCL快速入门教程
参考链接
一、OpenCL中的一些函数
OpenCL的Kernel相当于CUDA的device
OpenCL的Work-item相当于CUDA的thread
OpenCL的Work-group相当于CUDA的block
OpenCL的ND-Range相当于CUDA的grid
get_global_id(dim) :CUDA中需要计算线程的id,而在opencl中线程id直接通过这个函数直接获取
get_global_size(dim):线程总数量
get_group_id(dim):dim可以为0,1,2,分别代表CUDA中的blockIdx.x、blockIdx.y、blockIdx.z
get_num_groups(dim):
get_local_id(dim):dim可以为0,1,2,分别代表CUDA中的threadIdx.x、threadIdx.y、threadIdx.z
get_local_size(dim)
二、内存模型:
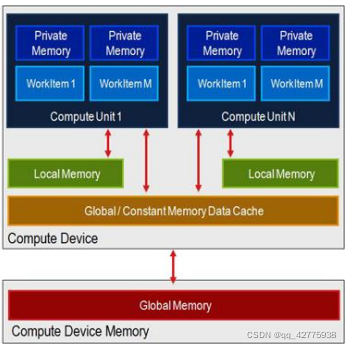
箭头表示可以访问。所有的workItem都可以读Global Memory的数据。我们在利用opencl写并行函数的时候,可以看到函数的形参是类似这样定义的:__global int *C,这就代表C所指向的地方是Global Memory。
三、opencl编程实践
opencl需要包含头文件:#include<CL/cl.h>
这里新建一个Vadd.cl文件,用于保存__kernel函数的相关代码。然后在testOpenCL.cpp中建立环境和调用Vadd.cl文件中的__kernel函数。
实现矩阵乘法(参考:矩阵乘法):
Vadd.cl中代码如下:
__kernel void matrix_mult(
const int Ndim,
const int Mdim,
const int Pdim,
__global const float* A,
__global const float* B,
__global float* C)
{
int i = get_global_id(0);
int j = get_global_id(1);
int k;
float tmp;
if ((i < Ndim) && (j < Mdim)) {
tmp = 0.0;
for (k = 0; k < Pdim; k++)
tmp += A[i*Pdim + k] * B[k*Mdim + j];
C[i*Mdim + j] = tmp;
}
}
testOpenCL.cpp中代码如下:
#include <CL/cl.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <iostream>
#include <fstream>
using namespace std;
#define NWITEMS 6
#pragma comment (lib,"OpenCL.lib")
//把文本文件读入一个 string 中
int convertToString(const char *filename, std::string& s)
{
size_t size;
char* str;
std::fstream f(filename, (std::fstream::in | std::fstream::binary));
if (f.is_open())
{
size_t fileSize;
f.seekg(0, std::fstream::end);
size = fileSize = (size_t)f.tellg();
f.seekg(0, std::fstream::beg);
str = new char[size + 1];
if (!str)
{
f.close();
return NULL;
}
f.read(str, fileSize);
f.close();
str[size] = '\0';
s = str;
delete[] str;
return 0;
}
printf("Error: Failed to open file %s\n", filename);
return 1;
}
int main()
{
cl_uint status;
cl_platform_id platform;
//创建平台对象
status = clGetPlatformIDs(1, &platform, NULL);
cl_device_id device;
//创建 GPU 设备
clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU,
1,
&device,
NULL);
//创建context
cl_context context = clCreateContext(NULL,
1,
&device,
NULL, NULL, NULL);
//创建命令队列
cl_command_queue commandQueue = clCreateCommandQueue(context,
device,
CL_QUEUE_PROFILING_ENABLE, NULL);
if (commandQueue == NULL)
perror("Failed to create commandQueue for device 0.");
//建立要传入从机的数据
/******** 创建内核和内存对象 ********/
const int Ndim = 4;
const int Mdim = 3;
const int Pdim = 4;
int szA = Ndim * Pdim;
int szB = Pdim * Mdim;
int szC = Ndim * Mdim;
float *A;
float *B;
float *C;
A = (float *)malloc(szA * sizeof(float));
B = (float *)malloc(szB * sizeof(float));
C = (float *)malloc(szC * sizeof(float));
int i, j;
for (i = 0; i < szA; i++)
A[i] = (float)((float)i + 1.0);
for (i = 0; i < szB; i++)
B[i] = (float)((float)i + 1.0);
//创建三个 OpenCL 内存对象,并把buf1 的内容通过隐式拷贝的方式
//拷贝到clbuf1, buf2 的内容通过显示拷贝的方式拷贝到clbuf2
cl_mem memObjects[3] = { 0, 0, 0 };
memObjects[0] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(float)* szA, A, NULL);
memObjects[1] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(float)* szB, B, NULL);
memObjects[2] = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_COPY_HOST_PTR,
sizeof(float)* szC, C, NULL);
if (memObjects[0] == NULL || memObjects[1] == NULL || memObjects[2] == NULL)
perror("Error in clCreateBuffer.\n");
const char * filename = "Vadd.cl";
std::string sourceStr;
status = convertToString(filename, sourceStr);
if (status)
cout << status << " !!!!!!!!" << endl;
const char * source = sourceStr.c_str();
size_t sourceSize[] = { strlen(source) };
//创建程序对象
cl_program program = clCreateProgramWithSource(
context,
1,
&source,
sourceSize,
NULL);
//编译程序对象
status = clBuildProgram(program, 1, &device, NULL, NULL, NULL);
if (status)
cout << status << " !!!!!!!!" << endl;
if (status != 0)
{
printf("clBuild failed:%d\n", status);
char tbuf[0x10000];
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0x10000, tbuf,
NULL);
printf("\n%s\n", tbuf);
//return −1;
}
//创建 Kernel 对象
cl_kernel kernel = clCreateKernel(program, "matrix_mult", NULL);
//设置 Kernel 参数
cl_int clnum = NWITEMS;
status = clSetKernelArg(kernel, 0, sizeof(int), &Ndim);
status = clSetKernelArg(kernel, 1, sizeof(int), &Mdim);
status = clSetKernelArg(kernel, 2, sizeof(int), &Pdim);
status = clSetKernelArg(kernel, 3, sizeof(cl_mem), &memObjects[0]);
status = clSetKernelArg(kernel, 4, sizeof(cl_mem), &memObjects[1]);
status = clSetKernelArg(kernel, 5, sizeof(cl_mem), &memObjects[2]);
if (status)
cout << "参数设置错误" << endl;
//执行 kernel
size_t global[2];
cl_event prof_event;
cl_ulong ev_start_time = (cl_ulong)0;
cl_ulong ev_end_time = (cl_ulong)0;
double rum_time;
global[0] = (size_t)Ndim;
global[1] = (size_t)Mdim;
status = clEnqueueNDRangeKernel(commandQueue, kernel, 2, NULL,
global, NULL, 0, NULL, &prof_event);
if (status)
cout << "执行内核时错误" << endl;
clFinish(commandQueue);
//读取时间
status = clGetEventProfilingInfo(prof_event, CL_PROFILING_COMMAND_QUEUED,
sizeof(cl_ulong), &ev_start_time, NULL);
status = clGetEventProfilingInfo(prof_event, CL_PROFILING_COMMAND_END,
sizeof(cl_ulong), &ev_end_time, NULL);
if (status)
perror("读取时间的时候发生错误\n");
rum_time = (double)(ev_end_time - ev_start_time);
cout << "执行时间为:" << rum_time << endl;
//数据拷回 host 内存
status = clEnqueueReadBuffer(commandQueue, memObjects[2], CL_TRUE, 0,
sizeof(float)* szC, C, 0, NULL, NULL);
if (status)
perror("读回数据的时候发生错误\n");
//结果显示
printf("\nArray A:\n");
for (i = 0; i < Ndim; i++) {
for (j = 0; j < Pdim; j++)
printf("%.3f\t", A[i*Pdim + j]);
printf("\n");
}
printf("\nArray B:\n");
for (i = 0; i < Pdim; i++) {
for (j = 0; j < Mdim; j++)
printf("%.3f\t", B[i*Mdim + j]);
printf("\n");
}
printf("\nArray C:\n");
for (i = 0; i < Ndim; i++) {
for (j = 0; j < Mdim; j++)
printf("%.3f\t", C[i*Mdim + j]);
printf("\n");
}
cout << endl;
if (A)
free(A);
if (B)
free(B);
if (C)
free(C);
//删除 OpenCL 资源对象
clReleaseMemObject(memObjects[2]);
clReleaseMemObject(memObjects[1]);
clReleaseMemObject(memObjects[0]);
clReleaseProgram(program);
clReleaseCommandQueue(commandQueue);
clReleaseContext(context);
system("pause");
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号