
图分类任务实战
图分类任务
前期准备
- 这回咱们拿到的不是一个图,而是一堆图(188个)
- 对这些图整体进行分类任务,数据集概述如下:
import torch
# 导入TUDataset,这是一个用于加载图数据集的类。
from torch_geometric.datasets import TUDataset #分子数据集:https://chrsmrrs.github.io/datasets/
# 创建一个名为dataset的图数据集对象。这一行指定了数据集的根目录和数据集的名称。数据集包含多个图,每个图表示一种分子结构,。
dataset = TUDataset(root='data/TUDataset', name='MUTAG')
print()
print(f'Dataset: {dataset}:') # 打印数据集的信息,包括数据集的名称。
print('====================')
print(f'Number of graphs: {len(dataset)}') # 打印数据集中包含的图的数量。
print(f'Number of features: {dataset.num_features}') # 打印每个图中节点的特征数量。
print(f'Number of classes: {dataset.num_classes}') # 打印数据集中的类别数量。在分子数据集中,通常表示不同种类的分子。
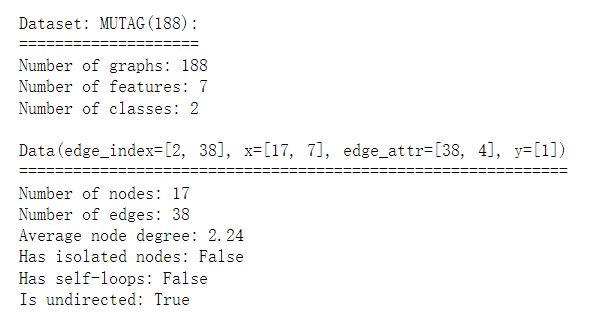
data = dataset[0] # Get the first graph object.
print()
"""
edge_index=[2, 38]:这部分信息表示图中的边的索引。edge_index 是一个2xN的矩阵,其中每一列代表一条边,N 是边的总数。在这个例子中,图中有 38 条边,每个边由两个节点组成。
x=[17, 7]:这部分信息表示图中的节点特征。x是一个节点特征矩阵,其中17表示图中有17个节点,每个节点的特征向量的维度为7.
edge_attr=[38, 4]:这部分信息表示图中每条边的特征。edge_attr 是一个边特征矩阵,其中38表示有38条边,每个边的特征向量的维度为 4。
y=[1]:这部分信息表示图的标签或类别。在这个例子中,图被标记为一个类别,其值为 1。
"""
print(data)
print('=============================================================')
# Gather some statistics about the first graph.
print(f'Number of nodes: {data.num_nodes}') # 打印第一个图中的节点数量。
print(f'Number of edges: {data.num_edges}') # 打印第一个图中的边的数量。
print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}') # 计算并打印平均节点度(每个节点连接的边的平均数量)。
print(f'Has isolated nodes: {data.has_isolated_nodes()}') # 检查并打印图是否包含孤立节点(只与自己连接的节点)。
print(f'Has self-loops: {data.has_self_loops()}') # 检查并打印图是否包含自环(节点与自己连接的边)。
print(f'Is undirected: {data.is_undirected()}') # 检查并打印图是否是无向图。
输出结果:
Mini-batching
图神经网络中的 Mini-batching 流程:
1. 图数据准备: 首先,你需要准备一个大型的图数据集。这个图可以表示各种关系,如社交网络、知识图谱、通信网络等。图数据由节点和边组成,节点代表实体,边代表它们之间的连接关系。节点和边可以有特征,类似于传统神经网络中的输入特征。
2. Mini-batch 划分: 大型图数据通常无法一次性输入到图神经网络中,因此你将图数据划分成多个小批量(mini-batch)数据。每个小批量包含一部分节点和它们之间的连接关系。小批量的大小通常是一个超参数,例如 32 或 64,表示每次训练时处理的节点数量。
3. 节点表示初始化: 在 Mini-batch 训练开始时,为每个节点初始化表示。这通常是一个随机向量,可以是节点特征的一部分。节点表示将随着训练逐渐更新,以捕获节点之间的信息传递。
4. 前向传播: 对于每个小批量数据,进行前向传播。这涉及计算节点表示的更新,以便考虑它们的邻居节点。节点表示的更新通常使用聚合函数(如池化或均值池化)来汇总邻居节点的信息。
5. 汇总: 在前向传播期间,节点表示会根据邻居节点的信息进行汇总,以更新每个节点的表示。这使得节点能够考虑到它们的邻居节点的信息,以更好地捕获图中的关系。
6. 计算损失: 使用前向传播的结果计算损失函数,以度量模型的性能。损失函数通常比较模型的预测输出与真实标签,然后计算误差。
7. 反向传播: 对损失进行反向传播,计算每个节点表示的梯度。这些梯度将用于更新节点表示,以改善模型的性能。
8. 参数更新: 使用梯度下降等优化算法来更新图神经网络的参数,以减小损失函数的值。这会改善模型的性能,并使其能够更好地捕获图中的模式。
9. 重复迭代: 以上的步骤将在多次迭代中执行,通常称为"epoch"。在每个 epoch 中,会多次处理不同的 Mini-batch,直到模型收敛或达到预定的停止条件。
总之,Mini-batching 是一种有效处理大型图数据的方法,通过将数据划分成小批量并利用前向传播和反向传播来训练图神经网络。这有助于提高训练效率,使模型能够处理大规模的图数据。
# 导入用于加载和准备图数据以进行训练的库
from torch_geometric.loader import DataLoader
# 常见DataLoader对象,用于加载训练数据
# batch_size=64:每次从训练数据中加载 64 个图作为一个批次。
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
for step, data in enumerate(train_loader):
print(f'Step {step + 1}:')
print('=======')
# 当前小批量中包含的图的数量
print(f'Number of graphs in the current batch: {data.num_graphs}')
print(data)
print()
# DataBatch(edge_index=[2, 2420], x=[1091, 7], edge_attr=[2420, 4], y=[60], batch=[1091], ptr=[61])
# data输出分析
# 1、edge_index=[2, 2420]:这部分信息表示批量中所有图的边索引。edge_index 是一个 2xN 的矩阵,其中 N 表示边的总数。
# 在这个批量中,共有 2420 条边,每一列代表一条边,前一行是起始节点,后一行是结束节点。
# 2、x=[1091, 7]:这部分信息表示批量中的节点特征。x 是一个节点特征矩阵,其中 1091 表示批量中有 1091 个节点,每个节点的特征向量的维度为 7。
# 3、edge_attr=[2420, 4]:这部分信息表示批量中的每条边的特征。edge_attr 是一个边特征矩阵,其中 2420 表示有 2420条边,每个边的特征向量的维度为 4。
# 4、y=[60]:这部分信息表示批量中的图的标签或类别。在这个示例中,批量中包含了60个图,每个图被标记为一个类别。
# 5、batch=[1091]:这部分信息是关于节点所属的子图(即批量中的哪个图)的信息。这表示在批量中的1091个节点中,有1091个节点属于同一个子图。
# 6、ptr=[61]:这部分信息指示批量中的每个图的节点范围。在这个示例中,有61个图,ptr 表示每个图的节点数目的范围,用于在批量中划分不同的图。
设计网络架构
-
其实还是对各个节点进行特征编码,只不过现在多了一步聚合操作
-
把各个节点特征汇总成全局特征就相当于得到了整个图的编码

from torch.nn import Linear # 导入线性层的模块
import torch.nn.functional as F # 导入pytorch中的函数模块,通常用于激活函数等操作
from torch_geometric.nn import GCNConv # 导入GCVConv模块,用于实现图卷积层
from torch_geometric.nn import global_mean_pool # 导入global_mean_pool模块,用于执行全局平均池化
class GCN(torch.nn.Module):
def __init__(self, hidden_channels):
super(GCN, self).__init__()
# 设置随机种子,以确保结果的可重复性。
torch.manual_seed(12345)
self.conv1 = GCNConv(dataset.num_node_features, hidden_channels)
self.conv2 = GCNConv(hidden_channels, hidden_channels)
self.conv3 = GCNConv(hidden_channels, hidden_channels)
# 创建一个线性层,将 GCN 模型的输出特征维度(hidden_channels)映射到数据集的类别数量
self.lin = Linear(hidden_channels, dataset.num_classes)
def forward(self, x, edge_index, batch):
# 1.对各节点进行编码
x = self.conv1(x, edge_index)
x = x.relu()
x = self.conv2(x, edge_index)
x = x.relu()
x = self.conv3(x, edge_index)
# 2. 平均操作(使用全局平均池化对节点特征进行汇总,生成一个全局特征向量 x。)
x = global_mean_pool(x, batch) # [batch_size, hidden_channels]
# 3. 输出
x = F.dropout(x, p=0.5, training=self.training)
# # 使用线性层将全局特征映射到类别数量,生成最终的输出。
x = self.lin(x)
return x
model = GCN(hidden_channels=64)
print(model)

# 创建模型
model = GCN(hidden_channels=64)
# 定义优化器和损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = torch.nn.CrossEntropyLoss()
# 训练函数
def train():
model.train()
for data in train_loader: # Iterate in batches over the training dataset.
out = model(data.x, data.edge_index, data.batch) # Perform a single forward pass.
loss = criterion(out, data.y) # Compute the loss.
loss.backward() # Derive gradients.
optimizer.step() # Update parameters based on gradients.
optimizer.zero_grad() # Clear gradients.
# 测试模型
def test(loader):
model.eval() # 将模型设置为评估模式,以禁用一些特定于训练的操作,如 dropout。
correct = 0
for data in loader: # Iterate in batches over the training/test dataset.
out = model(data.x, data.edge_index, data.batch)
pred = out.argmax(dim=1) # 找到每个样本中概率最高的类别,即模型的预测。
correct += int((pred == data.y).sum()) # 将正确预测的样本数量累积到计数器中。
return correct / len(loader.dataset) # 计算并返回准确率,即正确预测的样本数量除以总样本数量。
# 训练和测试循环
for epoch in range(1, 201):
train()
train_acc = test(train_loader)
print(f'Epoch: {epoch:03d}, Train Acc: {train_acc:.4f}')
Epoch: 001, Train Acc: 0.6649
Epoch: 002, Train Acc: 0.6649
Epoch: 003, Train Acc: 0.6649
Epoch: 004, Train Acc: 0.6702
Epoch: 005, Train Acc: 0.6809
Epoch: 006, Train Acc: 0.7181
Epoch: 007, Train Acc: 0.7234
Epoch: 008, Train Acc: 0.7234
Epoch: 009, Train Acc: 0.7287
Epoch: 010, Train Acc: 0.7340
Epoch: 011, Train Acc: 0.7340
Epoch: 012, Train Acc: 0.7447
Epoch: 013, Train Acc: 0.7447
Epoch: 014, Train Acc: 0.7394
Epoch: 015, Train Acc: 0.7394
Epoch: 016, Train Acc: 0.7500
Epoch: 017, Train Acc: 0.7394
Epoch: 018, Train Acc: 0.7500
Epoch: 019, Train Acc: 0.7500
Epoch: 020, Train Acc: 0.7394
Epoch: 021, Train Acc: 0.7553
Epoch: 022, Train Acc: 0.7553
Epoch: 023, Train Acc: 0.7660
Epoch: 024, Train Acc: 0.7606
Epoch: 025, Train Acc: 0.7660
Epoch: 026, Train Acc: 0.7660
Epoch: 027, Train Acc: 0.7766
Epoch: 028, Train Acc: 0.7660
Epoch: 029, Train Acc: 0.7660
Epoch: 030, Train Acc: 0.7819
Epoch: 031, Train Acc: 0.7660
Epoch: 032, Train Acc: 0.7660
Epoch: 033, Train Acc: 0.7819
Epoch: 034, Train Acc: 0.7660
Epoch: 035, Train Acc: 0.7766
Epoch: 036, Train Acc: 0.7819
Epoch: 037, Train Acc: 0.7553
Epoch: 038, Train Acc: 0.7660
Epoch: 039, Train Acc: 0.7713
Epoch: 040, Train Acc: 0.7606
Epoch: 041, Train Acc: 0.7660
Epoch: 042, Train Acc: 0.7819
Epoch: 043, Train Acc: 0.7819
Epoch: 044, Train Acc: 0.7713
Epoch: 045, Train Acc: 0.7606
Epoch: 046, Train Acc: 0.7926
Epoch: 047, Train Acc: 0.7713
Epoch: 048, Train Acc: 0.7606
Epoch: 049, Train Acc: 0.7660
Epoch: 050, Train Acc: 0.7819
Epoch: 051, Train Acc: 0.7766
Epoch: 052, Train Acc: 0.7606
Epoch: 053, Train Acc: 0.7660
Epoch: 054, Train Acc: 0.7766
Epoch: 055, Train Acc: 0.7713
Epoch: 056, Train Acc: 0.7606
Epoch: 057, Train Acc: 0.7766
Epoch: 058, Train Acc: 0.7766
Epoch: 059, Train Acc: 0.7766
Epoch: 060, Train Acc: 0.7606
Epoch: 061, Train Acc: 0.7819
Epoch: 062, Train Acc: 0.7713
Epoch: 063, Train Acc: 0.7660
Epoch: 064, Train Acc: 0.7766
Epoch: 065, Train Acc: 0.7766
Epoch: 066, Train Acc: 0.7766
Epoch: 067, Train Acc: 0.7819
Epoch: 068, Train Acc: 0.7819
Epoch: 069, Train Acc: 0.7713
Epoch: 070, Train Acc: 0.7660
Epoch: 071, Train Acc: 0.7713
Epoch: 072, Train Acc: 0.7872
Epoch: 073, Train Acc: 0.7713
Epoch: 074, Train Acc: 0.7713
Epoch: 075, Train Acc: 0.7819
Epoch: 076, Train Acc: 0.7766
Epoch: 077, Train Acc: 0.7713
Epoch: 078, Train Acc: 0.7713
Epoch: 079, Train Acc: 0.7819
Epoch: 080, Train Acc: 0.7766
Epoch: 081, Train Acc: 0.7979
Epoch: 082, Train Acc: 0.7766
Epoch: 083, Train Acc: 0.7713
Epoch: 084, Train Acc: 0.7713
Epoch: 085, Train Acc: 0.7766
Epoch: 086, Train Acc: 0.7766
Epoch: 087, Train Acc: 0.7766
Epoch: 088, Train Acc: 0.7872
Epoch: 089, Train Acc: 0.7766
Epoch: 090, Train Acc: 0.7766
Epoch: 091, Train Acc: 0.7819
Epoch: 092, Train Acc: 0.7766
Epoch: 093, Train Acc: 0.7819
Epoch: 094, Train Acc: 0.7926
Epoch: 095, Train Acc: 0.7766
Epoch: 096, Train Acc: 0.7819
Epoch: 097, Train Acc: 0.7766
Epoch: 098, Train Acc: 0.7766
Epoch: 099, Train Acc: 0.7713
Epoch: 100, Train Acc: 0.8085
Epoch: 101, Train Acc: 0.7766
Epoch: 102, Train Acc: 0.7766
Epoch: 103, Train Acc: 0.7766
Epoch: 104, Train Acc: 0.7819
Epoch: 105, Train Acc: 0.7819
Epoch: 106, Train Acc: 0.8085
Epoch: 107, Train Acc: 0.7819
Epoch: 108, Train Acc: 0.7819
Epoch: 109, Train Acc: 0.7872
Epoch: 110, Train Acc: 0.7979
Epoch: 111, Train Acc: 0.7872
Epoch: 112, Train Acc: 0.7872
Epoch: 113, Train Acc: 0.7979
Epoch: 114, Train Acc: 0.7926
Epoch: 115, Train Acc: 0.7872
Epoch: 116, Train Acc: 0.8032
Epoch: 117, Train Acc: 0.7872
Epoch: 118, Train Acc: 0.7766
Epoch: 119, Train Acc: 0.8138
Epoch: 120, Train Acc: 0.7926
Epoch: 121, Train Acc: 0.7766
Epoch: 122, Train Acc: 0.8138
Epoch: 123, Train Acc: 0.7926
Epoch: 124, Train Acc: 0.7553
Epoch: 125, Train Acc: 0.7766
Epoch: 126, Train Acc: 0.7926
Epoch: 127, Train Acc: 0.7872
Epoch: 128, Train Acc: 0.7872
Epoch: 129, Train Acc: 0.7872
Epoch: 130, Train Acc: 0.8032
Epoch: 131, Train Acc: 0.7872
Epoch: 132, Train Acc: 0.7713
Epoch: 133, Train Acc: 0.8138
Epoch: 134, Train Acc: 0.7979
Epoch: 135, Train Acc: 0.7979
Epoch: 136, Train Acc: 0.7979
Epoch: 137, Train Acc: 0.7979
Epoch: 138, Train Acc: 0.7979
Epoch: 139, Train Acc: 0.8032
Epoch: 140, Train Acc: 0.8085
Epoch: 141, Train Acc: 0.8138
Epoch: 142, Train Acc: 0.8138
Epoch: 143, Train Acc: 0.8085
Epoch: 144, Train Acc: 0.8085
Epoch: 145, Train Acc: 0.7926
Epoch: 146, Train Acc: 0.8085
Epoch: 147, Train Acc: 0.8191
Epoch: 148, Train Acc: 0.7819
Epoch: 149, Train Acc: 0.8138
Epoch: 150, Train Acc: 0.8191
Epoch: 151, Train Acc: 0.7819
Epoch: 152, Train Acc: 0.8138
Epoch: 153, Train Acc: 0.8085
Epoch: 154, Train Acc: 0.8191
Epoch: 155, Train Acc: 0.8085
Epoch: 156, Train Acc: 0.8032
Epoch: 157, Train Acc: 0.8245
Epoch: 158, Train Acc: 0.7872
Epoch: 159, Train Acc: 0.8191
Epoch: 160, Train Acc: 0.8298
Epoch: 161, Train Acc: 0.8191
Epoch: 162, Train Acc: 0.8191
Epoch: 163, Train Acc: 0.8138
Epoch: 164, Train Acc: 0.8191
Epoch: 165, Train Acc: 0.8245
Epoch: 166, Train Acc: 0.8191
Epoch: 167, Train Acc: 0.8298
Epoch: 168, Train Acc: 0.8191
Epoch: 169, Train Acc: 0.8245
Epoch: 170, Train Acc: 0.8085
Epoch: 171, Train Acc: 0.8245
Epoch: 172, Train Acc: 0.8191
Epoch: 173, Train Acc: 0.8191
Epoch: 174, Train Acc: 0.8191
Epoch: 175, Train Acc: 0.8138
Epoch: 176, Train Acc: 0.8298
Epoch: 177, Train Acc: 0.8245
Epoch: 178, Train Acc: 0.8191
Epoch: 179, Train Acc: 0.8138
Epoch: 180, Train Acc: 0.8351
Epoch: 181, Train Acc: 0.8191
Epoch: 182, Train Acc: 0.8457
Epoch: 183, Train Acc: 0.8351
Epoch: 184, Train Acc: 0.8351
Epoch: 185, Train Acc: 0.8298
Epoch: 186, Train Acc: 0.8404
Epoch: 187, Train Acc: 0.8191
Epoch: 188, Train Acc: 0.8032
Epoch: 189, Train Acc: 0.8191
Epoch: 190, Train Acc: 0.8298
Epoch: 191, Train Acc: 0.8404
Epoch: 192, Train Acc: 0.8564
Epoch: 193, Train Acc: 0.8404
Epoch: 194, Train Acc: 0.8351
Epoch: 195, Train Acc: 0.8351
Epoch: 196, Train Acc: 0.8404
Epoch: 197, Train Acc: 0.8404
Epoch: 198, Train Acc: 0.8298
Epoch: 199, Train Acc: 0.8617
Epoch: 200, Train Acc: 0.8617

 浙公网安备 33010602011771号
浙公网安备 33010602011771号