
Pytorch
损失函数(Loss Function)创建项目的方式
conda create -n 环境名称 python版本
DataSet类代码实战
read_data.py
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
# 将两个路径进行拼接
self.path = os.path.join(self.root_dir, self.label_dir)
# 将文件夹下的内容变成列表
self.img_path = os.listdir(self.path)
# 在python中__getitem__(self, key):方法被称为魔法方法,这个方法返回所给键对应的值。
# 1 当对象是序列时,键是整数。当对象是映射时(字典),键是任意值
# 2 在定义类时,如果希望能按照键取类的值,则需要定义__getitem__方法
# 3 如果给类定义了__getitem__方法,则当按照键取值时,可以直接返回__getitem__方法执行的结果
def __getitem__(self, idx):
img_name = self.img_path[idx]
# 相对于这个程序的相对路径
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
# 返回列表长度
return len(self.img_path)
root_dir = "dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset
rename_dataset.py
import os
root_dir = "dataset/train"
target_dir = "ants_image"
img_path = os.listdir("D:\\workspace\\learn_pytorch\\" + os.path.join(root_dir, target_dir))
print(img_path)
label = target_dir.split('_')[0]
print(label)
out_dir = "ants_label"
for i in img_path:
file_name = i.split('.jpg')[0]
# with open("D:\\workspace\\learn_pytorch\\" + os.path.join(root_dir, out_dir, "{}.txt").format(file_name), 'w') as f:
with open("D:\\workspace\\learn_pytorch\\" + os.path.join(root_dir, out_dir+f'{file_name}.txt'), 'w') as f:
f.write(label)
TensorBoard的使用
tensorboard的用途
tensorboard可以用来查看loss是否能够按照我们预想的变化,或者查看训练到某一步输出的图像是什么样子的。
tensorboard写日志
from tensorboardX import SummaryWriter
writer = SummaryWriter("logs") # 创建一个logs文件夹,writer写的文件都在该文件夹下
#writer.add_image()
for i in range(100):
writer.add_scalar("y=2x",2*i,i)
writer.close()
tensorboard读日志
① 在 Anaconda 终端里面,激活py环境(conda activate pytorch),再输入 tensorboard --logdir=D:/workspace/pytorch/transform/logs 命令,将网址赋值浏览器的网址栏,回车,即可查看tensorboard显示日志情况。
② 为避免多人使用端口导致冲突,也可以在后面加上后缀,使得端口独立,tensorboard --logdir=D:\workspace\pytorch\transform\logs --port=6007
③ 输入网址可得Tensorboard界面。
tensorboard读取图片
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
img_path1 = "Data/FirstTypeData/train/ants/0013035.jpg"
img_PIL1 = Image.open(img_path1)
img_array1 = np.array(img_PIL1)
img_path2 = "Data/SecondTypeData/train/bees_image/17209602_fe5a5a746f.jpg"
img_PIL2 = Image.open(img_path2)
img_array2 = np.array(img_PIL2)
writer = SummaryWriter("logs")
writer.add_image("test",img_array1,1,dataformats="HWC") # 1 表示该图片在第1步
writer.add_image("test",img_array2,2,dataformats="HWC") # 2 表示该图片在第2步
writer.close()
在terminal中输入tensorboard --logdir=D:\workspace\pytorch\transboard\logs --port=6007后运行效果如下:

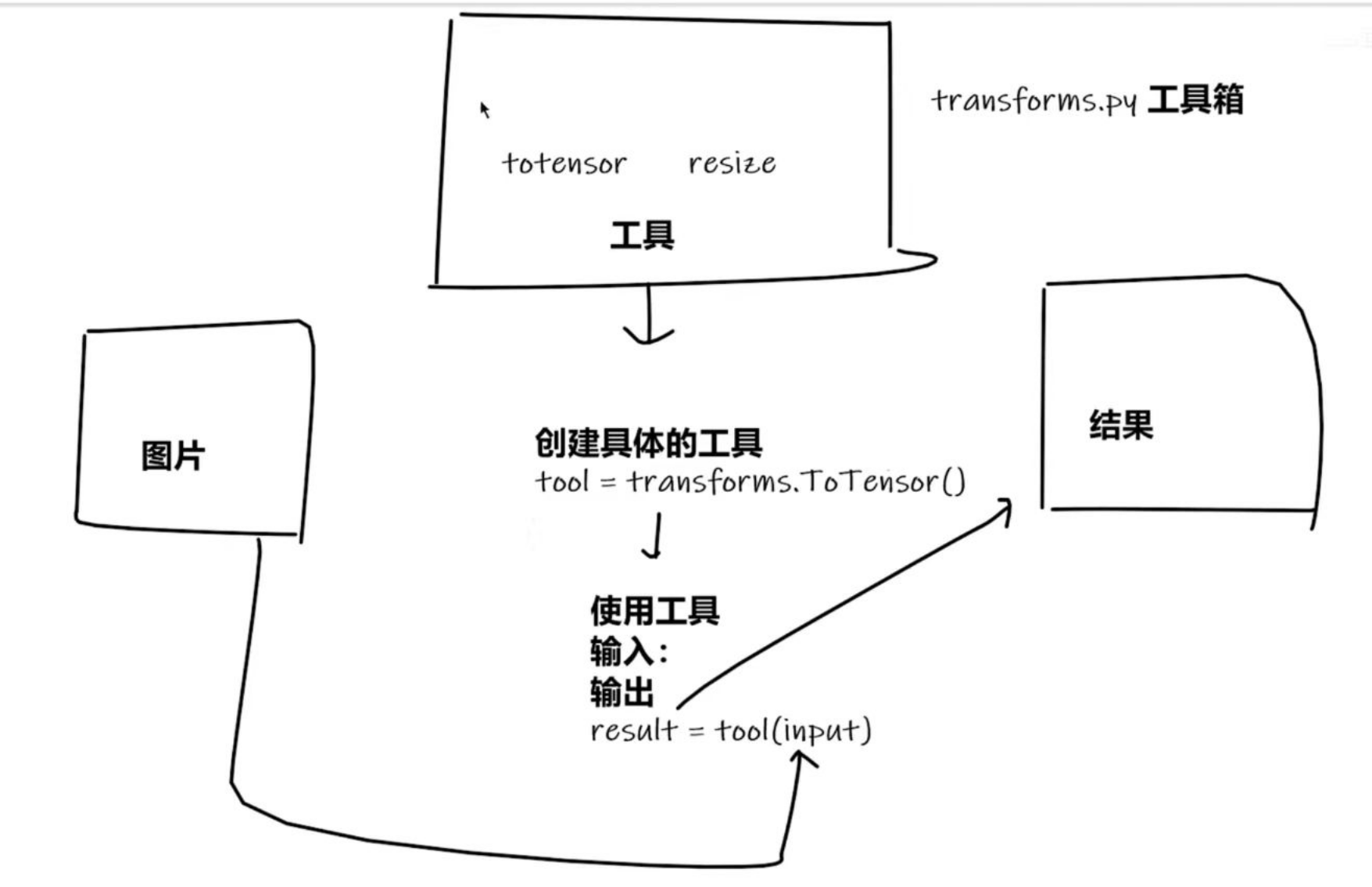
torchvision中的transforms
transforms的用途
①transforms当成工具箱的话,里面的class就是不同的工具。例如像tensor、resize这些工具。
②transforms拿一些特定格式的图片,经过transforms里面的工具,获得我们想要的结果。
transforms结构及用法
transform的图示
from PIL import Image
from torchvision import transforms
# from torch.utils.tensorboard import SummaryWriter
from tensorboardX import SummaryWriter
# python的用法->tensor数据类型
img_path = "D:/workspace/pytorch-learn/dataset/train/bees_image/16838648_415acd9e3f.jpg"
img = Image.open(img_path)
writer = SummaryWriter("logs")
# 1、transforms该如何使用(python)
# 2、为什么我们需要tensor数据类型
tensor_trans = transforms.ToTensor() # 创建transforms.ToTensor类的实例化对象
tensor_img = tensor_trans(img) # 调用transforms.ToTensor类的__call__的魔术方法
print(tensor_img)
writer.add_image("Tensor_img", tensor_img)
writer.close()
运行效果如下:
tensor([[[0.0980, 0.0863, 0.0902, ..., 0.0314, 0.0314, 0.0431],
[0.0784, 0.0863, 0.0863, ..., 0.0235, 0.0196, 0.0196],
[0.0510, 0.0784, 0.0863, ..., 0.0431, 0.0353, 0.0392],
...,
[0.7765, 0.7804, 0.6941, ..., 0.7529, 0.7333, 0.7804],
[0.6784, 0.8000, 0.7529, ..., 0.7490, 0.7098, 0.7961],
[0.7882, 0.7176, 0.6431, ..., 0.7373, 0.6824, 0.7529]],
[[0.0863, 0.0667, 0.0667, ..., 0.0706, 0.0706, 0.0667],
[0.0824, 0.0863, 0.0824, ..., 0.0510, 0.0471, 0.0392],
[0.0863, 0.1020, 0.0941, ..., 0.0510, 0.0431, 0.0392],
...,
[0.8980, 0.9137, 0.8392, ..., 0.8941, 0.8510, 0.8745],
[0.7882, 0.9020, 0.8510, ..., 0.8627, 0.8118, 0.8902],
[0.8980, 0.8196, 0.7412, ..., 0.8510, 0.7843, 0.8471]],
[[0.1216, 0.0902, 0.0667, ..., 0.0392, 0.0392, 0.0510],
[0.0980, 0.0941, 0.0745, ..., 0.0235, 0.0196, 0.0235],
[0.0667, 0.0863, 0.0745, ..., 0.0314, 0.0235, 0.0314],
...,
[0.9176, 0.9529, 0.9098, ..., 0.9490, 0.8941, 0.9137],
[0.8353, 0.9608, 0.9294, ..., 0.9255, 0.8627, 0.9294],
[0.9451, 0.8784, 0.8196, ..., 0.9137, 0.8353, 0.8863]]])
扩展:python中_call_()的使用
class Person:
def __call__(self, name):
print("__call_" + "hello" + name)
def hello(self, name):
print("hello" + name)
person = Person()
person("张三") # 内置call不用.,可直接通过对象进行调用
person.hello("李四") # 通过对象.方法进行调用
运行效果如下:

transforms.Tensor的使用
from PIL import Image
from tensorboardX import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
# 读取图片
img = Image.open("../images/pytorch.jpg")
print(img)
# ToTensor的使用
# """Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
writer.close()
测试环境如下,在terminal下输入tensorboard --logdir=D:/workspace/pytorch/transform/logs,即可在TensorBoard中显示图片的形状,运行效果如下
Normalize的使用(归一化)
# Normalize的使用(归一化)
# """Normalize a tensor image with mean and standard deviation.
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([5, 2, 6], [6, 3, 4])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm, 2)
writer.close()
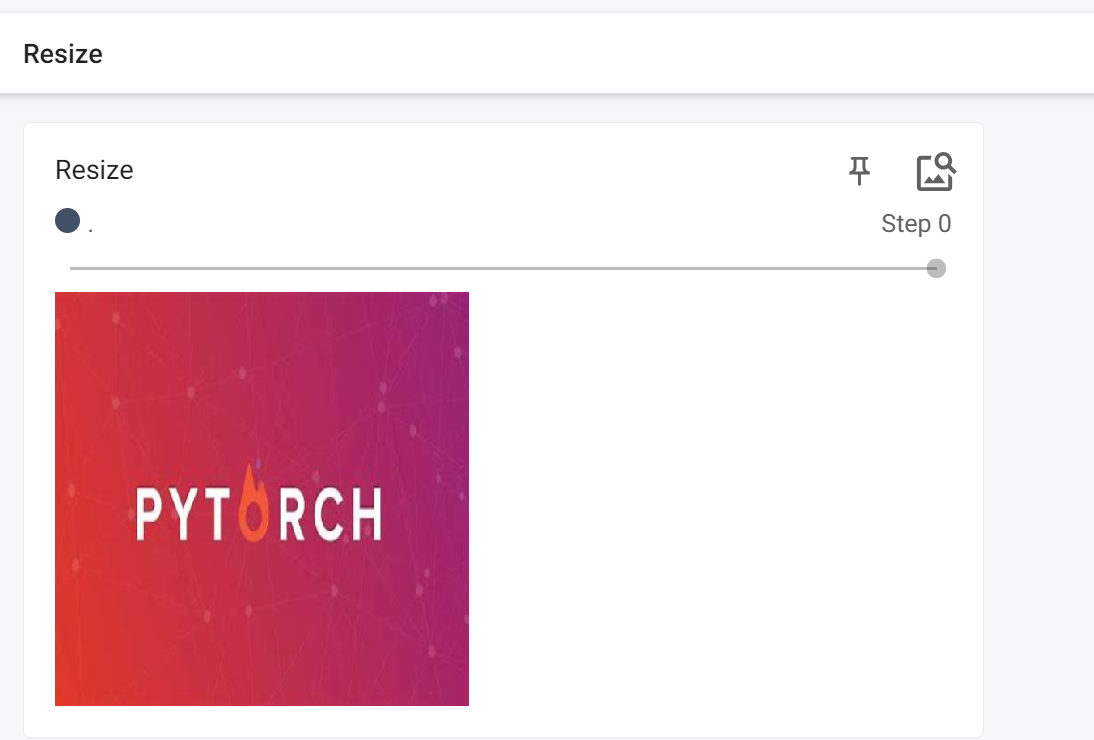
Resize()的使用
# Resize
print(img.size)
trans_resize = transforms.Resize((512, 512))
# img PTL -> resize -> img_resize PIL
img_resize = trans_resize(img)
# img_resize PIL -> totensor ->img_resize tensor
img_resize = trans_totensor(img_resize)
writer.add_image("Resize", img_resize, 0)
print(img_resize) # <PIL.Image.Image image mode=RGB size=512x512 at 0x226457A8708>
测试环境如下,在terminal下输入tensorboard --logdir=D:\workspace\pytorch\transform\logs,即可在TensorBoard中显示图片的形状,运行效果如下
Compose()的使用

# compose - resize - 2 等比缩放
trans_resize_2 = transforms.Resize(512)
# PIL->PIL->tensor
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2, 1)
测试环境如下,在terminal下输入tensorboard --logdir=D:\workspace\pytorch\transform\logs,即可在TensorBoard中显示图片的形状,运行效果如下

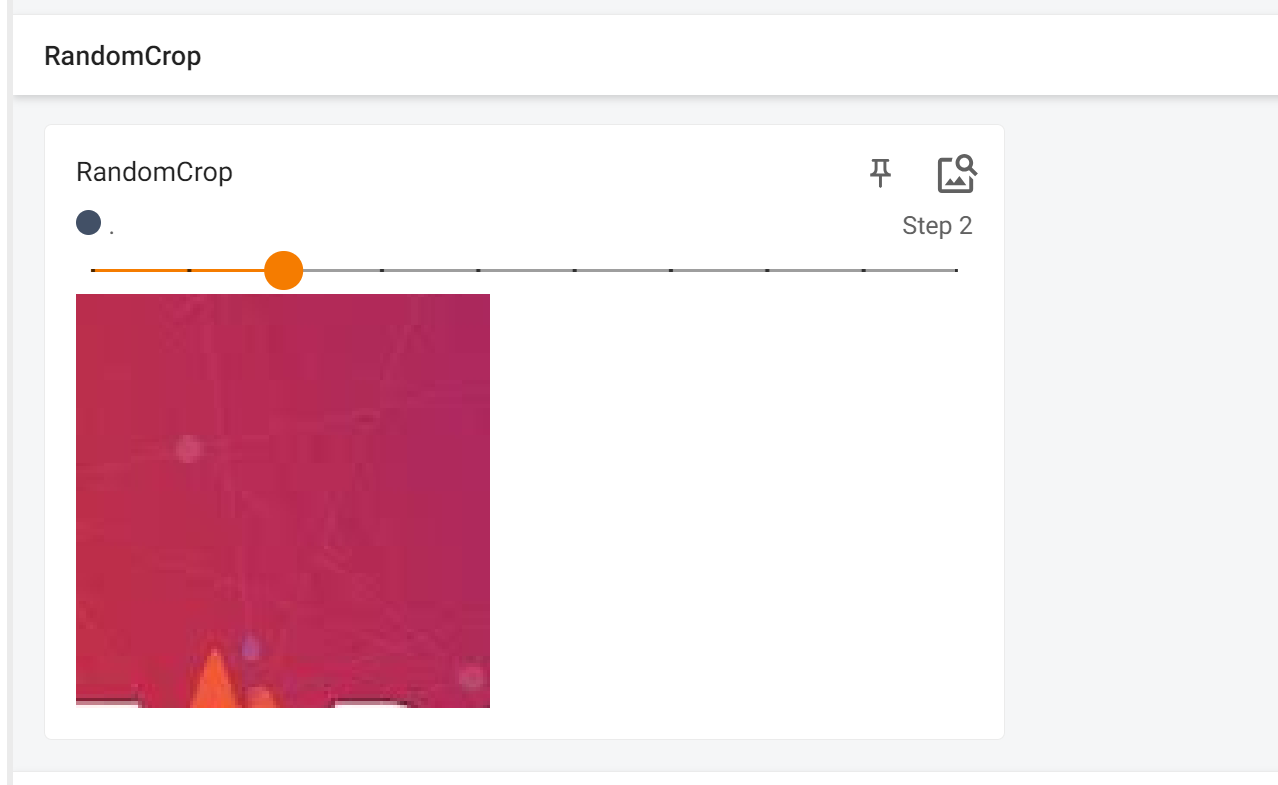
# RandomCrop
trans_random = transforms.RandomCrop(120)
print(type(trans_random))
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop", img_crop, i)
测试环境如下,在terminal下输入tensorboard --logdir=D:\workspace\pytorch\transform\logs,即可在TensorBoard中显示图片的形状,运行效果如下
总结使用方法
- 关注输入和输出类型
- 多看官网文档
- 关注方法需要什么参数
不知道返回值的时候
- print(type)
- debug
torchvision中数据集的使用
torchvision数据集介绍
①torchvision中有很多数据集,当我们写代码是指定相应的数据集指定一些参数,它就可以自行下载。
②CIFAR-10数据集包含60000张32x32的彩色图片,一共10个类别,其中50000张训练图片,10000张测试图片。
import torchvision
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, download=True)
print(test_set[0])
print(test_set.classes)
img, target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])
img.show()
输出结果如下:
(<PIL.Image.Image image mode=RGB size=32x32 at 0x1DC5F0EE7C8>, 3)
['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
<PIL.Image.Image image mode=RGB size=32x32 at 0x1DC5F101CC8>
3
cat
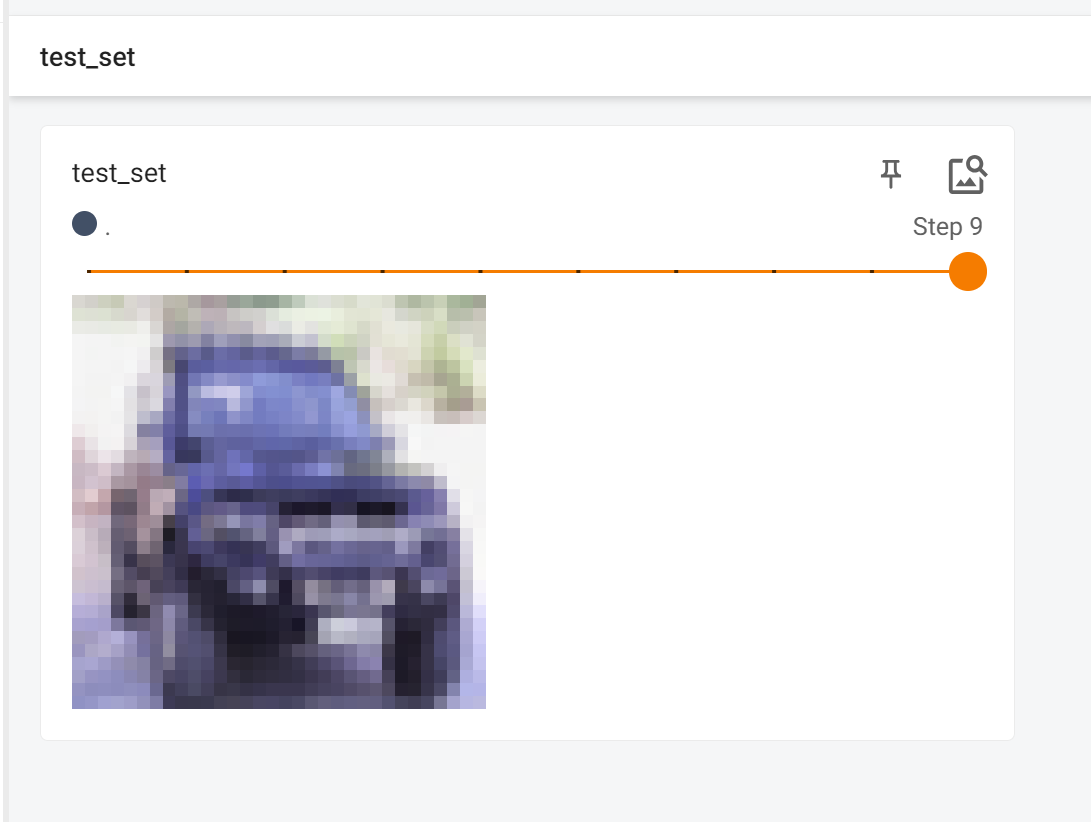
tensorboard查看内容
import torchvision
from tensorboardX import SummaryWriter
dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True) # 将ToTensor应用到数据集中的每一张图片,每一张图片转为Tensor数据类型
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
writer = SummaryWriter("logs")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
print(img.size())
writer.close() # 一定要把读写关闭,否则显示不出来图片
运行效果如下:
Files already downloaded and verified
Files already downloaded and verified
torch.Size([3, 32, 32])
torch.Size([3, 32, 32])
torch.Size([3, 32, 32])
torch.Size([3, 32, 32])
torch.Size([3, 32, 32])
torch.Size([3, 32, 32])
torch.Size([3, 32, 32])
torch.Size([3, 32, 32])
torch.Size([3, 32, 32])
torch.Size([3, 32, 32])
DataLoader的使用
DataLoad的用途
①DataSet只是去告诉程序,数据集的位置在哪里,数据集第一个数据给它一个索引0,它对应的是第一个数据。
②DataLoader就是把数据加载到神经网络当中,DataLoader所做的事就是每次从DataSet中取出数据,至于怎么取数据,是由DataLoader中的参数决定的。
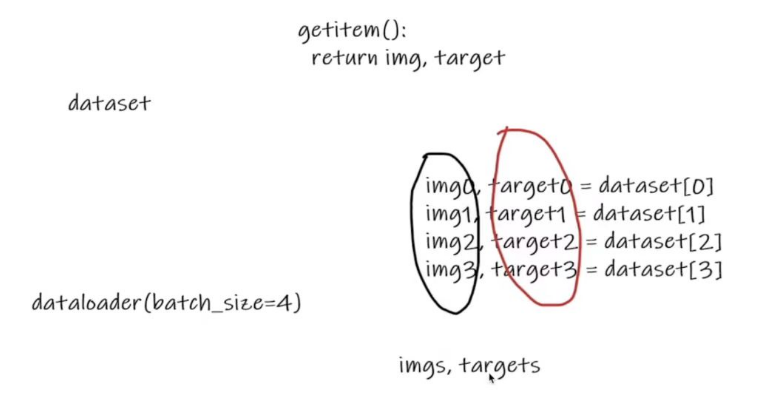
import torchvision.datasets
from torch.utils.data import DataLoader
from tensorboardX import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("../torchvision_with_DataSet/dataset", train=False, transform=torchvision.transforms.ToTensor())
# batch_size=4使得img0,target0=dataset[0]、img1, target1 = dataset[1]、img2, target2 = dataset[2]、img3, target3 = dataset[3],然后这四个数据作为Dataloader的一个返回
# drop_last:设置为True,当最后一次设置的数据集不满足batch_size的时候,这时候这些数据就会被舍弃;设置为False,就不会被舍弃
# shuffle:设置为True,tensorboard显示相同的step不会被打乱,设置为False,tensorboard显示相同的step会被打乱
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape) # torch.Size([3, 32, 32])
print(target) # 3
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data # 每个data都是由4张图片组成,imgs.size 为 [4,3,32,32],四张32×32图片三通道,targets由四个标签组成
writer.add_images("epoch:{}".format(epoch), imgs, step)
step += 1
# print(imgs.shape)
# print(targets)
writer.close()
小tips:将图片的路径放置到
神经网络的基本骨架
nn.Module模块使用
①nn.Module是对所有神经网络提供的一个基本的类
②我们的神经网络是继承nn.Module这个类,即nn.Module为父类,nn.Module为所有神经网络提供一个模板,对其中一些我们不满意的部分进行修改。
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__() # 继承父类的初始化
def forward(self, input): # 将forward函数进行重写
output = input + 1
return output
tudui = Tudui()
x = torch.tensor(1.0) # 创建一个值为 1.0 的tensor
output = tudui(x)
print(output)
super(Myclass, self)._init_()
①简单理解就是子类把父类的_init_()放到自己的_init_()中,这样子类就有了父类的_init_()的那些东西
②myclass类继承nn.Module,super(Myclass, self).init()就是对继承自父类nn.Module的属性进行初始化。而且是用nn.Module的初始化方法来初始化继承的属性。
③super()._init_()来通过初始化父类属性以初始化自身继承了父类的那部分属性,这样一来,作为nn.Module的子类就无序再初始化那一部分属性了,只需要初始化新加的元素。
④子类继承了父类的所有属性和方法,父类属性自然会用父类方法来进行初始化。
forward函数
①使用pytorch的时候,不需要手动调用forward函数,只要在实例化一个对象中传入对应的参数就可以自动调用forward函数。
②因为pytorch中的大部分方法都继承自torch.nn.Module,而torch.nn.Module的_call_(self)函数中会返回forward()函数的结果,因此pytorch中的forward()函数等于是被嵌套在了call(self)函数中;因此forward()函数可以直接通过类名被调用,而不用实例化对象
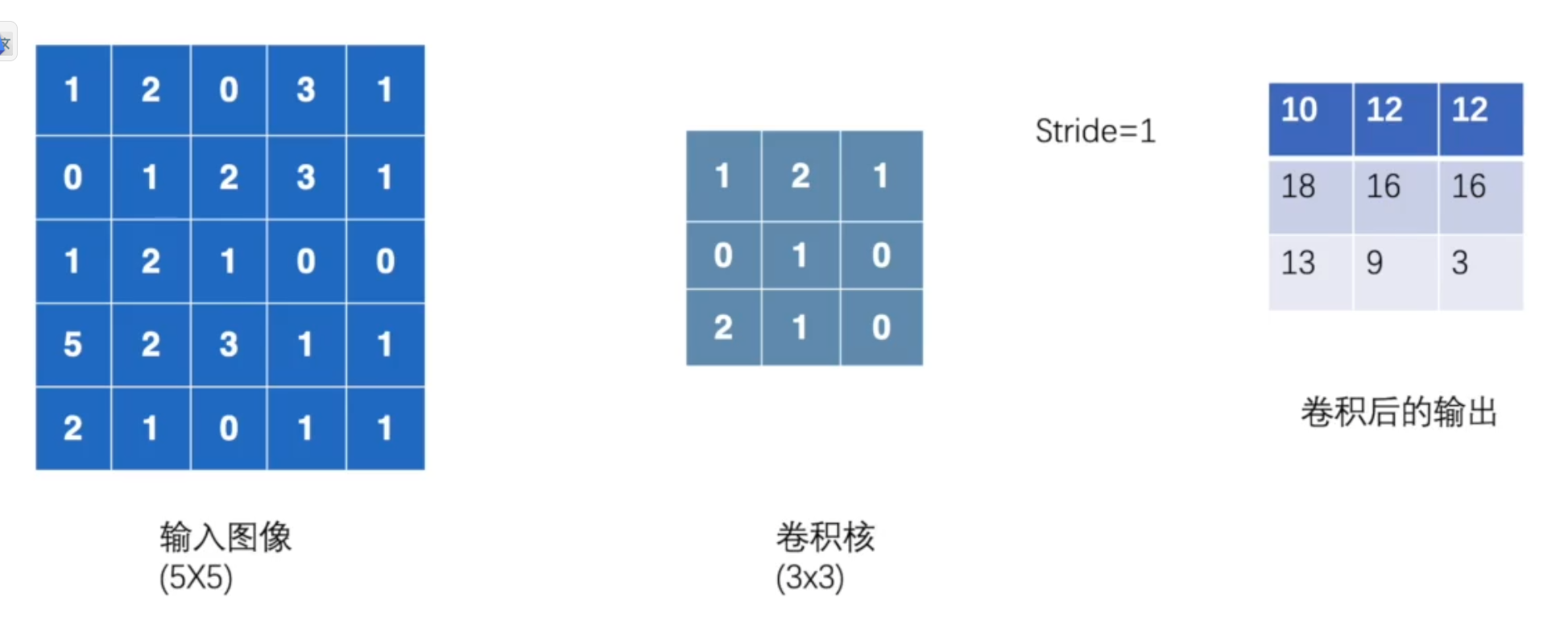
卷积操作
卷积原理
①卷积核不停地在原图上进行滑动,对应元素相乘再相加。
②下图为每次滑动移动1格,然后再利用原图与卷积核上的数值进行计算得到缩略图矩阵的数据,如下图所示。
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
print(input.shape)
print(kernel.shape)
# 灰度图用2为矩阵表示,所以通道数channel设置为1.彩色图用3为矩阵表示,通道数为2
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape)
print(kernel.shape)
output = F.conv2d(input, kernel, stride=1)
print(output)
运行结果如下:
torch.Size([5, 5])
torch.Size([3, 3])
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
print(input.shape)
print(kernel.shape)
input = torch.reshape(input, (1,1,5,5))
kernel = torch.reshape(kernel, (1,1,3,3))
print(input.shape)
print(kernel.shape)
output2 = F.conv2d(input, kernel, stride=2) # 步伐为2
print(output2)
运行结果如下:
torch.Size([5, 5])
torch.Size([3, 3])
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
tensor([[[[10, 12],
[13, 3]]]])
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
print(input.shape)
print(kernel.shape)
input = torch.reshape(input, (1,1,5,5))
kernel = torch.reshape(kernel, (1,1,3,3))
print(input.shape)
print(kernel.shape)
# padding填充的值为0
output3 = F.conv2d(input, kernel, stride=1, padding=1) # 周围只填充一层
print(output3)
运行结果如下:
torch.Size([5, 5])
torch.Size([3, 3])
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
卷积层
①Conv1d代表一维卷积,Conv2d代表二维卷积,Conv3d代表三维卷积
②kernel_size在训练过程中不断调整,定义为3就是3x3的卷积核,实际我们在训练神经网络的过程就是对kernel_size不断调整
③可以根据输入的参数获得输出的情况,如下图所示。

搭建卷积层代码如下:
import torch
import torchvision
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch import nn
from tensorboardX import SummaryWriter
dataset = torchvision.datasets.CIFAR10('../torchvision_with_DataSet/dataset', train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64, drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1,
padding=0) # 彩色图像输入为3层,我们想让它的输出为6层,选3 * 3 的卷积
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
print(tudui)
# tensorboard显示
writer = SummaryWriter("logs")
step = 0
# 卷积层处理图片
for data in dataloader:
imgs, target = data
output = tudui(imgs)
# print(imgs.shape) # 输入为3通道32×32的64张图片
# print(output.shape) # 输出为6通道30×30的64张图片
writer.add_images("input", imgs, step)
output = torch.reshape(output, (-1, 3, 30, 30)) # 把原来6个通道拉为3个通道,为了保证所有维度总数不变,其余的分量分到第一个维度中
writer.add_images("output", output, step)
step += 1
writer.close()

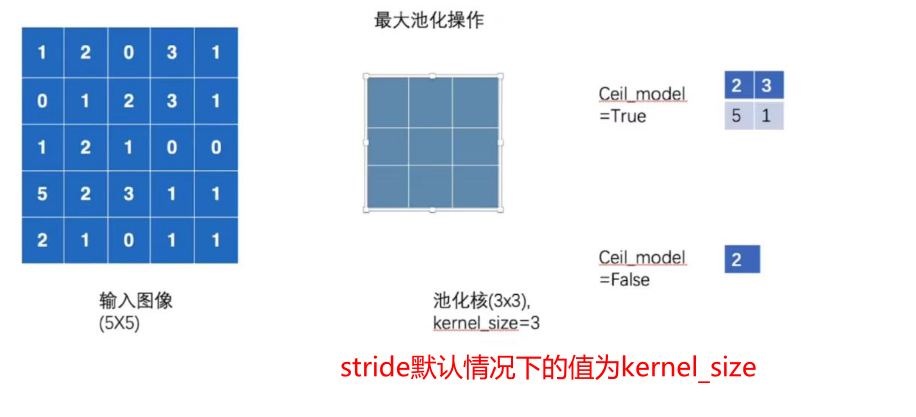
最大池化层
池化层原理
①最大池化层有时也被称为下采样
②dilation为空洞卷积
③Ceil_model为当超出区域时,只取最左上角的值
④池化使得数据由5x5变为3x3,甚至1x1的,这样导致计算的参数会大大减小。例如1080P的电影经过池化的转为720P的电影、或360P的电影后,同样的网速下,视频更为不卡。

池化层处理数据
import torch
import torchvision.datasets
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../torchvision_with_DataSet/dataset", train=False,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
# -1表示根据其他设置,自动计算,把input的参数补全,加上channel数
# input = torch.reshape(input, (-1, 1, 5, 5))
# print(input.shape)
step = 0
# 为什么需要最大池化?
# 保留数据的输入特征,减少数据量,训练的更快
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpoll1 = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output = self.maxpoll1(input)
return output
tudui = Tudui()
# output = tudui(input)
# print(output)
writer = SummaryWriter("logs_maxpool")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input1", imgs, step)
output = tudui(imgs)
writer.add_images("output1", output, step)
step += 1
writer.close()
运行效果如下:
非线性激活
非线性变换的目的是给网络中加入一些非线性特征,非线性越多才能训练出符合各种特征的模型。

import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
input = torch.tensor([[1, -0.5],
[-1, 3]])
output = torch.reshape(input, (-1, 1, 2, 2))
print(output.shape)
dataset = torchvision.datasets.CIFAR10("../torchvision_with_DataSet/dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
# output = self.relu1(input)
output = self.sigmoid1(input)
return output
tudui = Tudui()
# print(tudui(input))
writer = SummaryWriter("log_relu")
step = 0
for data in dataloader:
imgs, tragets = data
writer.add_images("input", imgs, global_step=step)
output = tudui(imgs)
writer.add_images("output", output, global_step=step)
step += 1
writer.close()
运行效果如下:
线性层以及其它层
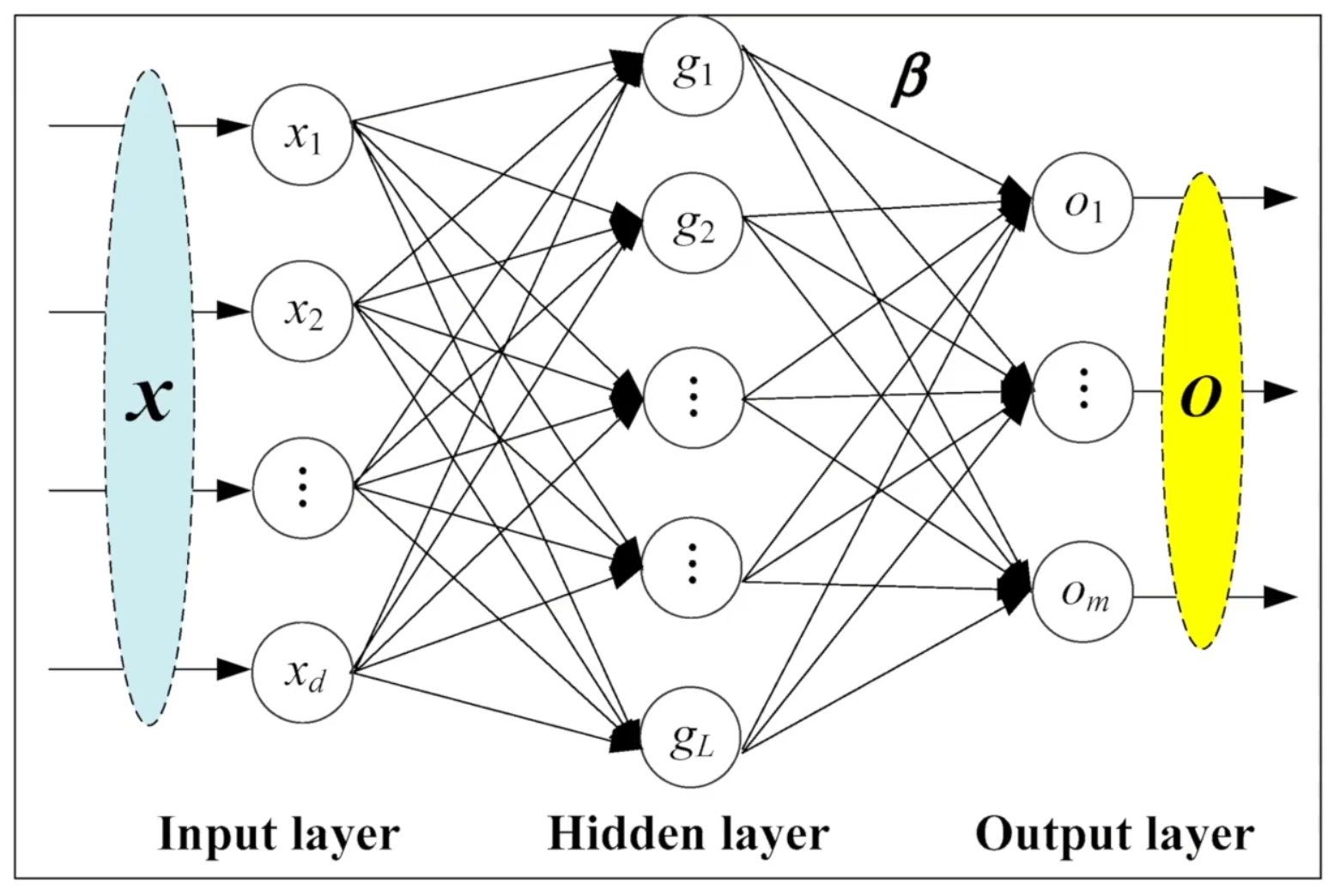
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
参数分析:
- in_features (int) – size of each input sample
- out_features (int) – size of each output sample
- bias (bool) – If set to
False, the layer will not learn an additive bias. Default:True(偏差(布尔值)– 如果设置为False,则层将不会学习加b。默认:True)
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../torchvision_with_DataSet/dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64, drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
tudui = Tudui()
for data in dataloader:
imgs, target = data
print(imgs.shape)
# output = torch.reshape(imgs, (1, 1, 1, -1))
output = torch.flatten(imgs)
print(output.shape)
output = tudui(output)
print(output.shape)
运行效果如下:
torch.Size([64, 3, 32, 32])
torch.Size([196608])
torch.Size([10])
torch.Size([64, 3, 32, 32])
torch.Size([196608])
torch.Size([10])
torch.Size([64, 3, 32, 32])
torch.Size([196608])
torch.Size([10])
...
补充:
torch.flatten(input, start_dim=0, end_dim=- 1) →张量

搭建小实战和Sequential使用
好处如下
①把网络结构放在Sequential里面,好处就是代码写起来比较简洁、易懂。
②可以根据神经网络每层的尺寸,根据下图的公式计算出神经网络中的参数。
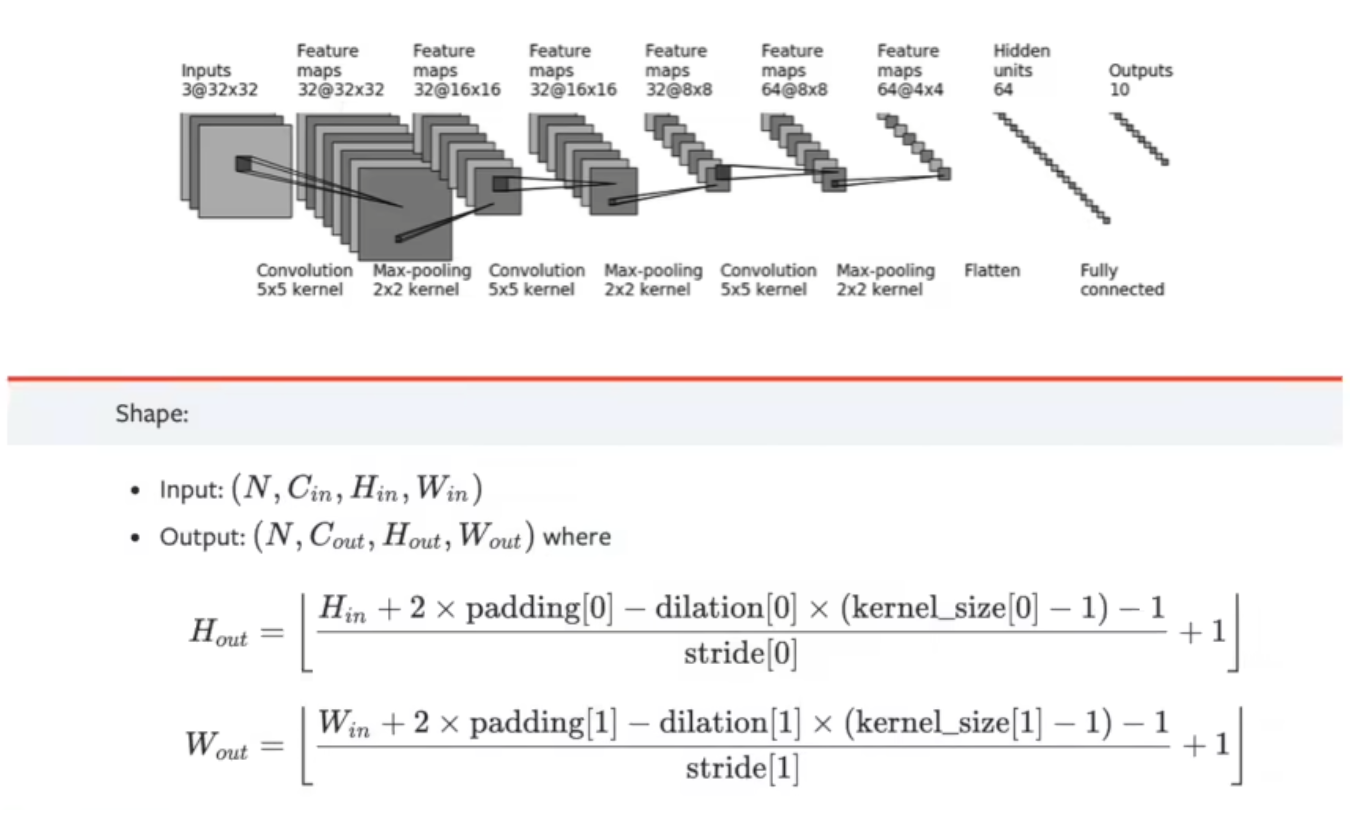
参数分析:
Hin:输入的高
dilation:未采用空洞卷积,默认为1
未知参数:padding、stride
Hout:输出的高
搭建神经网络模型
根据CRFAR10搭建网络模型
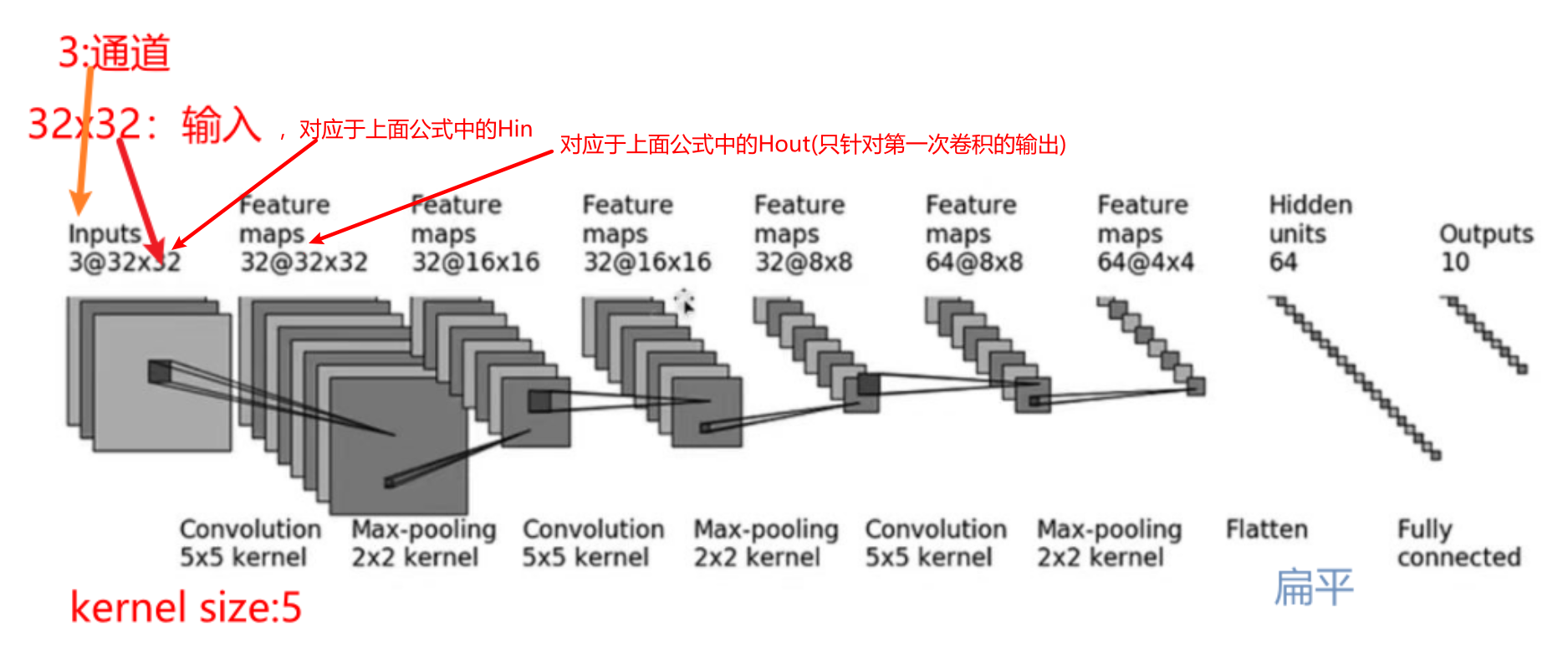
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 新建第一层卷积层
self.conv1 = Conv2d(3, 32, 5, padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32, 32, 5, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(1024, 64)
self.linear2 = Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
tudui = Tudui()
print(tudui)
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
简化后的写法:
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 新建第一层卷积层
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui()
print(tudui)
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
输出结果如下:
Tudui(
(model1): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([64, 10])
运行效果如下:
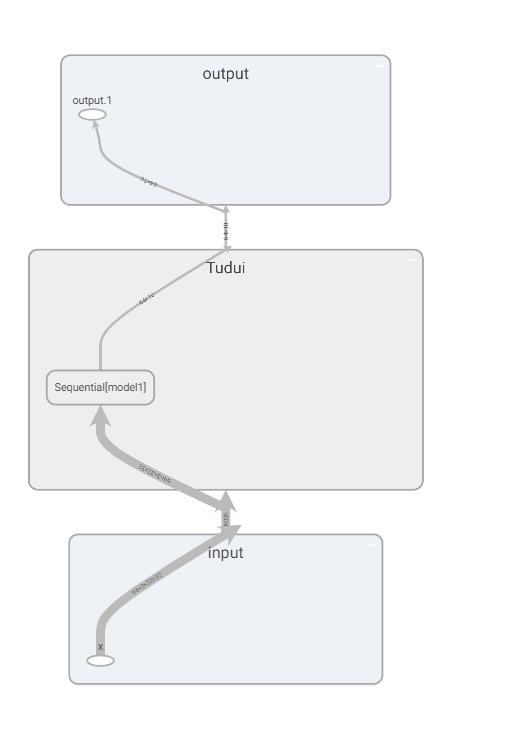
损失函数与反向传播

损失函数
①Loss损失函数一方面计算实际输出和目标之间的差距。
②Loss损失函数另一方面为我们更新输出提供一定的依据。
注意:loss function的值是越小越好
L1loss损失函数
① L1loss数学公式如下图所示,例子如下图所示。

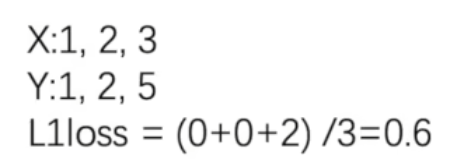
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
outputs = torch.reshape(targets, (1, 1, 1, 3))
print(inputs)
print(targets)
# 默认是mean,计算平均值[(1-1)+(2-2)+(5-3)]/3=0.667
# loss = L1Loss()
loss = L1Loss(reduction="sum")
result = loss(inputs, targets)
print(result) # tensor(2.)
MSE损失函数

import torch
from torch.nn import L1Loss, MSELoss
from torch import nn
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
# batchsize:1(batchsize是输入图片的数量) channel:1(C是通道数) weight:1(W是宽) height:3(H是高)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
outputs = torch.reshape(targets, (1, 1, 1, 3))
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets)
print(result_mse) # 1.333【2^2/3】
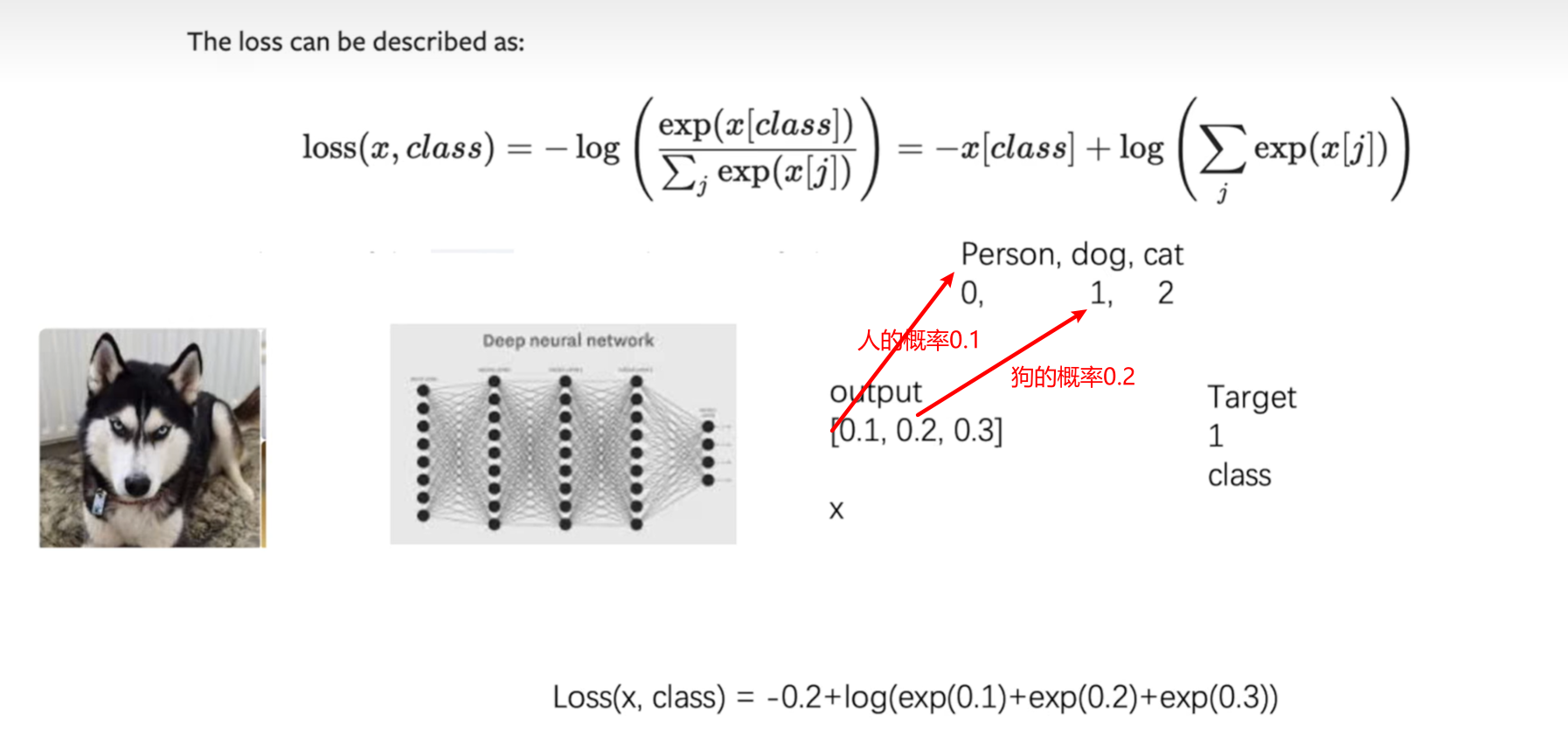
交叉熵损失函数
常用于分类的损失函数
import torch
import torch.nn.functional as F
from torch import nn
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# 卷积核
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
# 重新变换:通道数为1,batch为1,数据维度5x5
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape)
print(kernel.shape)
output1 = F.conv2d(input, kernel, stride=1)
print(output1)
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross) # tensor(1.1019)x
搭建神经网络
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10('../torchvision_with_DataSet/dataset', train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
print(outputs)
print(targets)
result_loss = loss(outputs, targets)
print(result_loss)
输出结果如下:
tensor([[-0.0482, 0.1419, -0.0266, 0.0194, 0.0727, 0.0062, 0.0675, -0.0183,
-0.0773, -0.0356]], grad_fn=<AddmmBackward0>)
tensor([3])
tensor(2.2954, grad_fn=<NllLossBackward0>)
tensor([[-0.0826, 0.1348, -0.0375, 0.0342, 0.0927, -0.0335, 0.0841, -0.0071,
-0.0592, -0.0782]], grad_fn=<AddmmBackward0>)
tensor([8])
tensor(2.3692, grad_fn=<NllLossBackward0>)
tensor([[-0.0640, 0.1211, -0.0672, 0.0288, 0.0787, -0.0088, 0.0804, -0.0183,
-0.0726, -0.0555]], grad_fn=<AddmmBackward0>)
tensor([8])
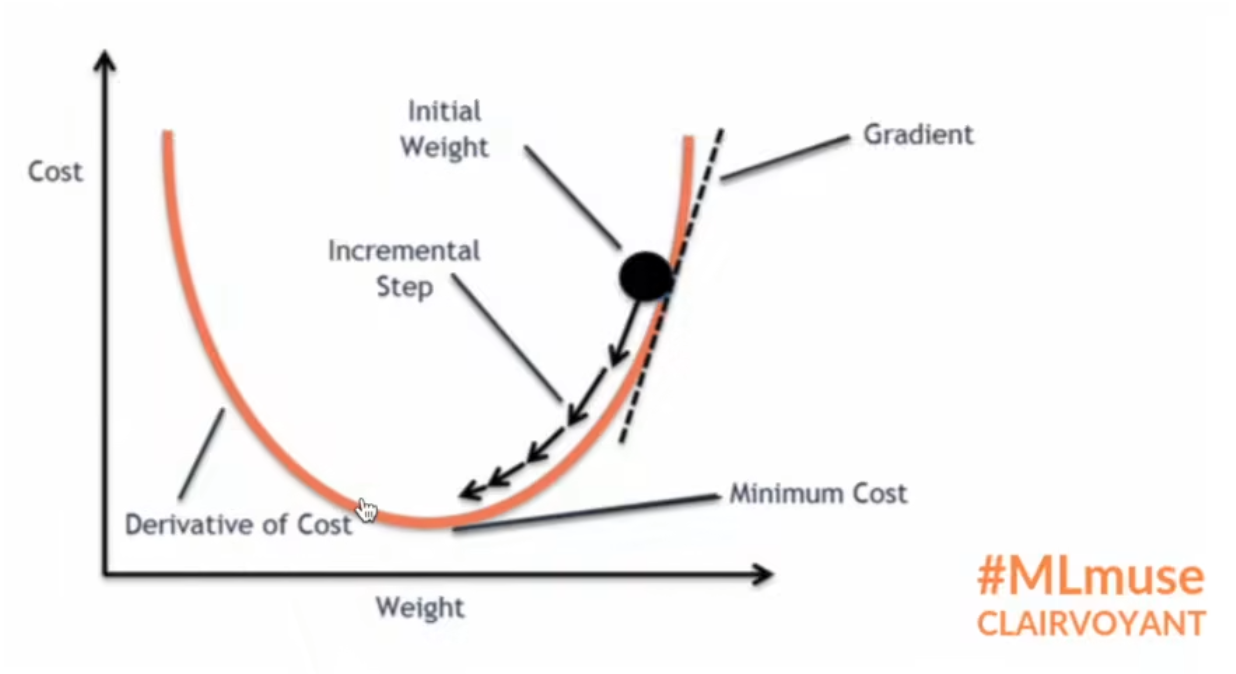
反向传播
什么是神经网络的反向传播机制?
定义:反向传播是"误差反向传播"的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。该方法对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。(误差的反向传播)
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10('../torchvision_with_DataSet/dataset', train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
# print(outputs)
# print(targets)
result_loss = loss(outputs, targets)
# 反向传播
result_loss.backward()
print("ok")
# print(result_loss)
优化器
①损失函数调用backward方法,就可以调用损失函数的反向传播方法,就可以求出我们需要调节的梯度,我们就可以利用我们的优化器就可以根据梯度对参数进行调整,达到整体误差降低的目的。
②梯度要清零,如果梯度不清零会导致梯度累加
神经网络优化一轮
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64,drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss() # 交叉熵
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(),lr=0.01) # 随机梯度下降优化器
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets) # 计算实际输出与目标输出的差距
optim.zero_grad() # 梯度清零
result_loss.backward() # 反向传播,计算损失函数的梯度
optim.step() # 根据梯度,对网络的参数进行调优
print(result_loss) # 对数据只看了一遍,只看了一轮,所以loss下降不大
神经网络优化多轮
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../torchvision_with_DataSet/dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui()
loss = nn.CrossEntropyLoss()
# 设置优化器
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad() # 将网络模型中每一个可以调节参数的梯度设置为0
result_loss.backward() # 反向传播求出每一个可以调节节点的梯度
optim.step() # 对每个参数的每个参数进行调优
running_loss += result_loss
print(running_loss)
运行结果如下:
Files already downloaded and verified
tensor(18572.7617, grad_fn=<AddBackward0>)
tensor(16135.2334, grad_fn=<AddBackward0>)
tensor(15418.3721, grad_fn=<AddBackward0>)
tensor(16082.0986, grad_fn=<AddBackward0>)
tensor(17837.6621, grad_fn=<AddBackward0>)
tensor(19959.7852, grad_fn=<AddBackward0>)
现有网络模型的使用及修改
下载网络模型
import torchvision
#trauin_data = torchvision.datasets.ImageNet("./dataset",split="train",download=True,transform=torchvision.transforms.ToTensor()) # 这个数据集没有办法再公开的访问了
vgg16_true = torchvision.models.vgg16(pretrained=True) # 下载卷积层对应的参数是多少、池化层对应的参数时多少,这些参数时ImageNet训练好了的
vgg16_false = torchvision.models.vgg16(pretrained=False) # 没有预训练的参数
print("ok")
print(vgg16_true)
ok
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
查看函数用法
import torchvision
help(torchvision.models.vgg16)
Help on function vgg16 in module torchvision.models.vgg:
vgg16(pretrained:bool=False, progress:bool=True, **kwargs:Any) -> torchvision.models.vgg.VGG
VGG 16-layer model (configuration "D")
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_.
The required minimum input size of the model is 32x32.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
网络模型添加
import torchvision
from torch import nn
dataset = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
vgg16_true = torchvision.models.vgg16(pretrained=True) # 下载卷积层对应的参数是多少、池化层对应的参数时多少,这些参数时ImageNet训练好了的
vgg16_true.add_module('add_linear',nn.Linear(1000,10)) # 在VGG16后面添加一个线性层,使得输出为适应CIFAR10的输出,CIFAR10需要输出10个种类
print(vgg16_true)
Files already downloaded and verified
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
(add_linear): Linear(in_features=1000, out_features=10, bias=True)
)
网络模型修改
import torchvision
from torch import nn
vgg16_false = torchvision.models.vgg16(pretrained=False) # 没有预训练的参数
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096,10)
print(vgg16_false)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
网络模型的保存与读取
网络模型保存(方式一)
import torchvision
import torch
vgg16 = torchvision.models.vgg16(pretrained=False) # 模型中的参数是未经过训练的
torch.save(vgg16,"./model/vgg16_method1.pth") # 保存方式一:模型结构 + 模型参数
print(vgg16)
运行结果如下:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
网络模型导入(方式一)
import torch
model = torch.load("./model/vgg16_method1.pth") # 保存方式一对应的加载模型
print(model)
运行结果如下:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
网络模型保存(方式二)-推荐
import torchvision
import torch
vgg16 = torchvision.models.vgg16(weights=None)
torch.save(vgg16.state_dict(),"./model/vgg16_method2.pth") # 保存方式二:模型参数(官方推荐),不再保存网络模型结构
print(vgg16)
运行结果如下:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
网络模型导入(方式二)
import torch
import torchvision
vgg16 = torchvision.models.vgg16(weights=None)
print(vgg16)
vgg16.load_state_dict(torch.load("./model/vgg16_method2.pth")) # 将模型参数导入到模型结构中
print(vgg16)
运行效果如下:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
网络陷阱-创建模型
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.conv1 = nn.Conv2d(3,64,kernel_size=3)
def forward(self,x):
x = self.conv1(x)
return x
tudui = Tudui()
torch.save(tudui, "./model/tudui_method1.pth")
网路陷阱-失败加载模型
①保存网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
torch.save(tudui, "tudui_method1.pth")
②在运行下面的代码过程中,即下面为第一个代码块运行,无法直接导入网络模型。原因是没有导入自定义的网络模型
import torch
model = torch.load("./model/tudui_method1.pth") # 无法直接加载方式一保存的网络结构
print(model)
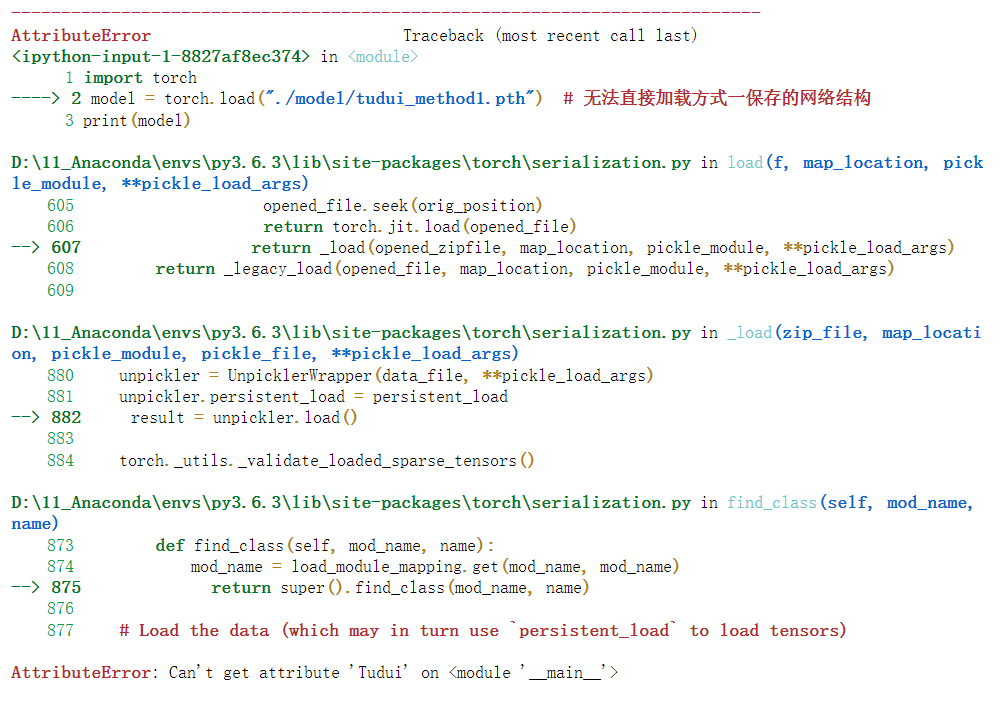
网络陷阱-成功加载模型(方式一)
import torch
from torch import nn
# 确保网络模型是我们想要的网络模型,需要在加载前还写明网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
# tudui=Tudui # 不需要写这一步,不需要创建网络模型
model = torch.load('./model/tudui_mothod1.pth') # 无法直接加载方式一保存的网络结构
print(model)
运行结果如下:
Tudui(
(conv1): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1))
)
网络陷阱-成功加载模型(方式二)
import torch
import model_save import * # 它就相当于把 model_save.py 里的网络模型定义写到这里了
#tudui = Tudui # 不需要写这一步,不需要创建网络模型
model = torch.load("tudui_method1.pth")
print(model)
完整模型训练套路
简单总结一下下面提到的代码的训练模型的基本步骤:
- 准备数据集
- dataloader加载数据集
- 搭建网络模型
- 创建网络模型实例
- 定义损失函数
- 定义优化器
- 设置网络训练的参数
- 开始训练
- 验证模型
- 保存模型
- 将训练结果展示
CIFAR10 model网络模型
下面是用CIFAR10 model网络来完成分类问题,网络模型如下图所示。
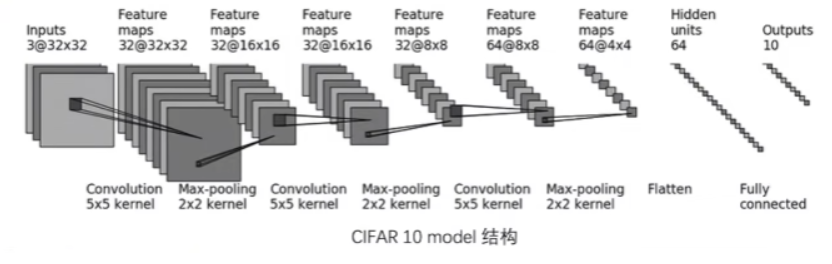
DataLoader加载数据集
import torchvision
from torch import nn
from torch.utils.data import DataLoader
# 准备数据集
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,则打印:训练数据集的长度为:10
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
# 利用 Dataloader 来加载数据集
train_dataloader = DataLoader(train_data_size, batch_size=64)
test_dataloader = DataLoader(test_data_size, batch_size=64)
运行结果如下:
Files already downloaded and verified
Files already downloaded and verified
训练数据集的长度:50000
测试数据集的长度:10000
测试网络是否正确
import torch
from torch import nn
# 搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2), # 输入通道3,输出通道32,卷积核尺寸5x5,步长1,填充2
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(), #展平后变成了64x4x4
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
if __name__ == '__main__':
tudui = Tudui()
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape) # 测试输出的尺寸是不是我们想要的
torch.Size([64, 10])
网络训练数据
import torchvision
from torch import nn
from torch.utils.data import DataLoader
# from model import * 相当于把 model中的所有内容写到这里,这里直接把 model 写在这里
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3,32,5,1,2), # 输入通道3,输出通道32,卷积核尺寸5×5,步长1,填充2
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(), # 展平后变成 64*4*4 了
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
# 准备数据集
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,则打印:训练数据集的长度为:10
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
# 利用 Dataloader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
tudui = Tudui()
# 损失函数
loss_fn = nn.CrossEntropyLoss() # 交叉熵,fn 是 fuction 的缩写
# 优化器
learning = 0.01 # 1e-2 就是 0.01 的意思
optimizer = torch.optim.SGD(tudui.parameters(),learning) # 随机梯度下降优化器
# 设置网络的一些参数
# 记录训练的次数
total_train_step = 0
# 训练的轮次
epoch = 10
for i in range(epoch):
print("-----第 {} 轮训练开始-----".format(i+1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 计算实际输出与目标输出的差距
# 优化器对模型调优
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播,计算损失函数的梯度
optimizer.step() # 根据梯度,对网络的参数进行调优
total_train_step = total_train_step + 1
#print("训练次数:{},Loss:{}".format(total_train_step,loss)) # 方式一:获得loss值
print("训练次数:{},Loss:{}".format(total_train_step,loss.item())) # 方式二:获得loss值
item作用
import torch
a = torch.tensor(5)
print(a)
print(a.item())
tensor(5)
5
查看训练损失
①在pytorch中,tensor有一个require_grad参数,如果设置为True,则反向传播时,该tensor就会自动求导
②tensor的requires_grad的属性默认为False,若一个节点(叶子变量:自己创建的tensor)requires_grad被设置为True,那么所有依赖它的节点requires_grad都为True(即使其它相依赖的tensor的requires_grad = Fasle)
③当requires_grad设置为False,反向传播时就不会自动求导了,因此大大节约了显存或者内存
④with torch.no_grad的作用在该模块下,所有计算得出的tensor的requires_grad=False
⑤即使一个tensor(命名为x)的requires_grad=True,在with torch.no_grad计算,由x得到的新tensor(命名为w-标量)requires_grad也为False,且grad_fn也为None,即不会对w求导
⑥torch.no_grad():停止计算梯度,不能进行反向传播
import torchvision
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# from model import * 相当于把 model中的所有内容写到这里,这里直接把 model 写在这里
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3,32,5,1,2), # 输入通道3,输出通道32,卷积核尺寸5×5,步长1,填充2
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(), # 展平后变成 64*4*4 了
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
# 准备数据集
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,则打印:训练数据集的长度为:10
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
# 利用 Dataloader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
tudui = Tudui()
# 损失函数
loss_fn = nn.CrossEntropyLoss() # 交叉熵,fn 是 fuction 的缩写
# 优化器
learning = 0.01 # 1e-2 就是 0.01 的意思
optimizer = torch.optim.SGD(tudui.parameters(),learning) # 随机梯度下降优化器
# 设置网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮次
epoch = 10
# 添加 tensorboard
writer = SummaryWriter("logs")
for i in range(epoch):
print("-----第 {} 轮训练开始-----".format(i+1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 计算实际输出与目标输出的差距
# 优化器对模型调优
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播,计算损失函数的梯度
optimizer.step() # 根据梯度,对网络的参数进行调优
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step,loss.item())) # 方式二:获得loss值
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始(每一轮训练后都查看在测试数据集上的loss情况)
total_test_loss = 0
with torch.no_grad(): # 没有梯度计算,节约内存
for data in test_dataloader: # 测试数据集提取数据
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 仅data数据在网络模型上的损失
total_test_loss = total_test_loss + loss.item() # 所有loss
print("整体测试集上的Loss:{}".format(total_test_loss))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
total_test_step = total_test_step + 1
writer.close()
运行结果如下:
Files already downloaded and verified
Files already downloaded and verified
训练数据集的长度:50000
测试数据集的长度:10000
-----第 1 轮训练开始-----
训练次数:100,Loss:2.2818071842193604
训练次数:200,Loss:2.267061471939087
训练次数:300,Loss:2.2060177326202393
训练次数:400,Loss:2.1160497665405273
训练次数:500,Loss:2.03908371925354
训练次数:600,Loss:2.0013811588287354
训练次数:700,Loss:1.971280574798584
整体测试集上的Loss:311.444508433342
-----第 2 轮训练开始-----
训练次数:800,Loss:1.8406707048416138
训练次数:900,Loss:1.835253357887268
训练次数:1000,Loss:1.9193772077560425
训练次数:1100,Loss:1.9817758798599243
训练次数:1200,Loss:1.6866414546966553
训练次数:1300,Loss:1.6833062171936035
训练次数:1400,Loss:1.7423250675201416
训练次数:1500,Loss:1.7910836935043335
整体测试集上的Loss:295.83529579639435
-----第 3 轮训练开始-----
训练次数:1600,Loss:1.7340000867843628
训练次数:1700,Loss:1.6623749732971191
训练次数:1800,Loss:1.9103188514709473
训练次数:1900,Loss:1.722930908203125
训练次数:2000,Loss:1.8943604230880737
训练次数:2100,Loss:1.4975690841674805
训练次数:2200,Loss:1.464676856994629
训练次数:2300,Loss:1.7708508968353271
整体测试集上的Loss:273.4990575313568
-----第 4 轮训练开始-----
训练次数:2400,Loss:1.7362182140350342
训练次数:2500,Loss:1.3517616987228394
训练次数:2600,Loss:1.5586233139038086
训练次数:2700,Loss:1.6879914999008179
训练次数:2800,Loss:1.469564437866211
训练次数:2900,Loss:1.5893890857696533
训练次数:3000,Loss:1.352890968322754
训练次数:3100,Loss:1.4961837530136108
整体测试集上的Loss:270.01156997680664
-----第 5 轮训练开始-----
训练次数:3200,Loss:1.3372247219085693
训练次数:3300,Loss:1.4689146280288696
训练次数:3400,Loss:1.4240412712097168
训练次数:3500,Loss:1.5419731140136719
训练次数:3600,Loss:1.5850610733032227
训练次数:3700,Loss:1.343977451324463
训练次数:3800,Loss:1.3023576736450195
训练次数:3900,Loss:1.4324713945388794
整体测试集上的Loss:257.1781986951828
-----第 6 轮训练开始-----
训练次数:4000,Loss:1.3752213716506958
训练次数:4100,Loss:1.4291632175445557
训练次数:4200,Loss:1.5042070150375366
训练次数:4300,Loss:1.1800527572631836
训练次数:4400,Loss:1.1353368759155273
训练次数:4500,Loss:1.3278626203536987
训练次数:4600,Loss:1.385879397392273
整体测试集上的Loss:243.80352401733398
-----第 7 轮训练开始-----
训练次数:4700,Loss:1.3193678855895996
训练次数:4800,Loss:1.5091830492019653
训练次数:4900,Loss:1.390406608581543
训练次数:5000,Loss:1.377677083015442
训练次数:5100,Loss:0.9832243919372559
训练次数:5200,Loss:1.306634545326233
训练次数:5300,Loss:1.2060096263885498
训练次数:5400,Loss:1.3645224571228027
整体测试集上的Loss:227.03500604629517
-----第 8 轮训练开始-----
训练次数:5500,Loss:1.2007256746292114
训练次数:5600,Loss:1.2000162601470947
训练次数:5700,Loss:1.217725157737732
训练次数:5800,Loss:1.2193546295166016
训练次数:5900,Loss:1.344832420349121
训练次数:6000,Loss:1.5032548904418945
训练次数:6100,Loss:0.9945251941680908
训练次数:6200,Loss:1.0842390060424805
整体测试集上的Loss:210.75880527496338
-----第 9 轮训练开始-----
训练次数:6300,Loss:1.3924059867858887
训练次数:6400,Loss:1.08247971534729
训练次数:6500,Loss:1.6116385459899902
训练次数:6600,Loss:1.0441133975982666
训练次数:6700,Loss:1.0808278322219849
训练次数:6800,Loss:1.1203839778900146
训练次数:6900,Loss:1.065340518951416
训练次数:7000,Loss:0.8646073341369629
整体测试集上的Loss:200.43587028980255
-----第 10 轮训练开始-----
训练次数:7100,Loss:1.2311145067214966
训练次数:7200,Loss:0.9793491363525391
训练次数:7300,Loss:1.1264833211898804
训练次数:7400,Loss:0.8558132648468018
训练次数:7500,Loss:1.1851539611816406
训练次数:7600,Loss:1.2427409887313843
训练次数:7700,Loss:0.8233367204666138
训练次数:7800,Loss:1.2412829399108887
整体测试集上的Loss:194.5557427406311
在 Anaconda 终端里面,激活pytorch环境,再输入 tensorboard --logdir=ogs 命令,将网址赋值浏览器的网址栏,回车,即可查看tensorboard显示日志情况
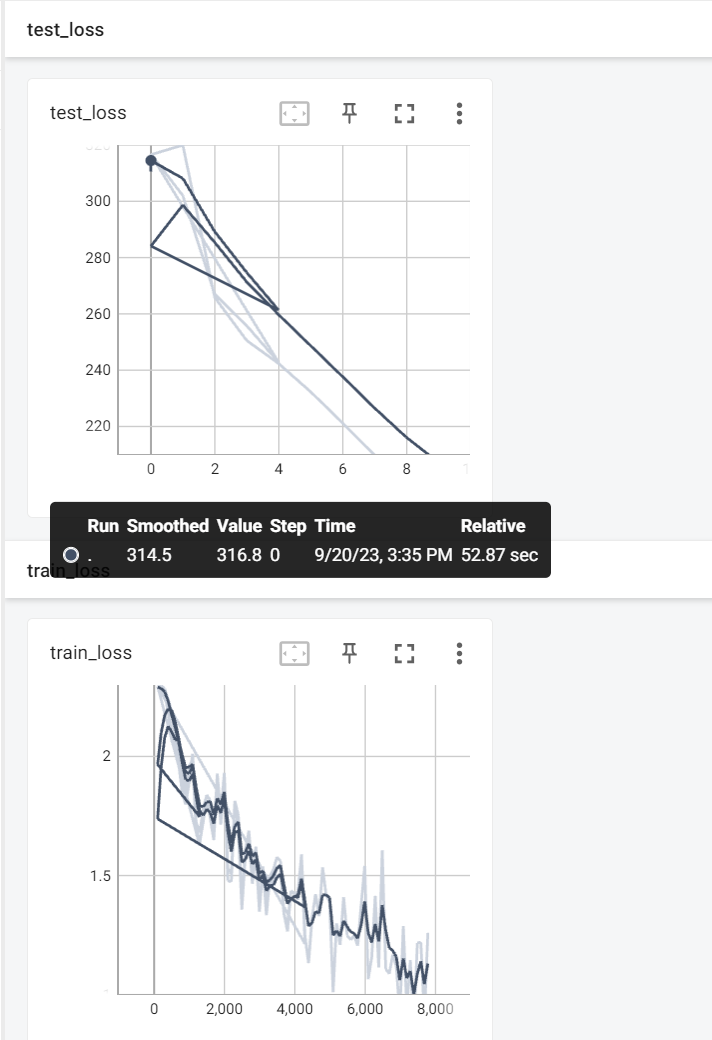
保留每一轮后参数
import torchvision
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# from model import * 相当于把 model中的所有内容写到这里,这里直接把 model 写在这里
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3,32,5,1,2), # 输入通道3,输出通道32,卷积核尺寸5×5,步长1,填充2
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(), # 展平后变成 64*4*4 了
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
# 准备数据集
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,则打印:训练数据集的长度为:10
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
# 利用 Dataloader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
tudui = Tudui()
# 损失函数
loss_fn = nn.CrossEntropyLoss() # 交叉熵,fn 是 fuction 的缩写
# 优化器
learning = 0.01 # 1e-2 就是 0.01 的意思
optimizer = torch.optim.SGD(tudui.parameters(),learning) # 随机梯度下降优化器
# 设置网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮次
epoch = 10
# 添加 tensorboard
writer = SummaryWriter("logs")
for i in range(epoch):
print("-----第 {} 轮训练开始-----".format(i+1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 计算实际输出与目标输出的差距
# 优化器对模型调优
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播,计算损失函数的梯度
optimizer.step() # 根据梯度,对网络的参数进行调优
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step,loss.item())) # 方式二:获得loss值
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始(每一轮训练后都查看在测试数据集上的loss情况)
total_test_loss = 0
with torch.no_grad(): # 没有梯度了
for data in test_dataloader: # 测试数据集提取数据
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 仅data数据在网络模型上的损失
total_test_loss = total_test_loss + loss.item() # 所有loss
print("整体测试集上的Loss:{}".format(total_test_loss))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "./model/tudui_{}.pth".format(i)) # 保存每一轮训练后的结果
print("模型已保存")
writer.close()
argmax作用
import torch
outputs = torch.tensor([[0.1,0.2],
[0.05,0.4]])
print(outputs.argmax(0)) # 竖着看,最大值的索引
print(outputs.argmax(1)) # 横着看,最大值的索引
preds = outputs.argmax(0)
targets = torch.tensor([0,1])
print((preds == targets).sum()) # 对应位置相等的个数
tensor([0, 1])
tensor([1, 1])
tensor(2)
打印正确率
import torchvision
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# from model import * 相当于把 model中的所有内容写到这里,这里直接把 model 写在这里
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3,32,5,1,2), # 输入通道3,输出通道32,卷积核尺寸5×5,步长1,填充2
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(), # 展平后变成 64*4*4 了
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
# 准备数据集
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,则打印:训练数据集的长度为:10
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
# 利用 Dataloader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
tudui = Tudui()
# 损失函数
loss_fn = nn.CrossEntropyLoss() # 交叉熵,fn 是 fuction 的缩写
# 优化器
learning = 0.01 # 1e-2 就是 0.01 的意思
optimizer = torch.optim.SGD(tudui.parameters(),learning) # 随机梯度下降优化器
# 设置网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮次
epoch = 10
# 添加 tensorboard
writer = SummaryWriter("logs")
for i in range(epoch):
print("-----第 {} 轮训练开始-----".format(i+1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 计算实际输出与目标输出的差距
# 优化器对模型调优
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播,计算损失函数的梯度
optimizer.step() # 根据梯度,对网络的参数进行调优
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step,loss.item())) # 方式二:获得loss值
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始(每一轮训练后都查看在测试数据集上的loss情况)
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 没有梯度了
for data in test_dataloader: # 测试数据集提取数据
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 仅data数据在网络模型上的损失
total_test_loss = total_test_loss + loss.item() # 所有loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "./model/tudui_{}.pth".format(i)) # 保存每一轮训练后的结果
print("模型已保存")
writer.close()
运行效果如下:
Files already downloaded and verified
Files already downloaded and verified
训练数据集的长度为:50000
测试数据集的长度为:10000
--------------------第1轮训练开始--------------------
训练次数:100,loss:2.290602684020996
训练次数:200,loss:2.287285327911377
训练次数:300,loss:2.2444310188293457
训练次数:400,loss:2.169663429260254
训练次数:500,loss:2.1361947059631348
训练次数:600,loss:2.075166702270508
训练次数:700,loss:1.9815199375152588
整体测试集上的loss为:312.1001933813095
整体测试集上的正确率为:0.29269999265670776
模型已保存
--------------------第2轮训练开始--------------------
训练次数:800,loss:1.8577196598052979
训练次数:900,loss:1.850684642791748
训练次数:1000,loss:1.9485677480697632
训练次数:1100,loss:1.9768987894058228
训练次数:1200,loss:1.6851532459259033
训练次数:1300,loss:1.6394447088241577
训练次数:1400,loss:1.726165771484375
训练次数:1500,loss:1.813376545906067
整体测试集上的loss为:292.74943912029266
整体测试集上的正确率为:0.33219999074935913
模型已保存
--------------------第3轮训练开始--------------------
训练次数:1600,loss:1.7275582551956177
训练次数:1700,loss:1.6258721351623535
训练次数:1800,loss:1.9269616603851318
训练次数:1900,loss:1.6683919429779053
训练次数:2000,loss:1.945574164390564
训练次数:2100,loss:1.5271880626678467
训练次数:2200,loss:1.458802342414856
训练次数:2300,loss:1.7970935106277466
整体测试集上的loss为:258.29104018211365
整体测试集上的正确率为:0.4025999903678894
模型已保存
--------------------第4轮训练开始--------------------
训练次数:2400,loss:1.7016180753707886
训练次数:2500,loss:1.3566914796829224
训练次数:2600,loss:1.5722663402557373
训练次数:2700,loss:1.6519713401794434
训练次数:2800,loss:1.4794732332229614
训练次数:2900,loss:1.5956920385360718
训练次数:3000,loss:1.3555442094802856
训练次数:3100,loss:1.5187991857528687
整体测试集上的loss为:251.28711569309235
整体测试集上的正确率为:0.41530001163482666
模型已保存
--------------------第5轮训练开始--------------------
训练次数:3200,loss:1.3214302062988281
训练次数:3300,loss:1.4614449739456177
训练次数:3400,loss:1.454591989517212
训练次数:3500,loss:1.5601571798324585
训练次数:3600,loss:1.5753967761993408
训练次数:3700,loss:1.3145686388015747
训练次数:3800,loss:1.289497971534729
训练次数:3900,loss:1.450293779373169
整体测试集上的loss为:245.25754117965698
整体测试集上的正确率为:0.42750000953674316
模型已保存
--------------------第6轮训练开始--------------------
训练次数:4000,loss:1.4143743515014648
训练次数:4100,loss:1.4589511156082153
训练次数:4200,loss:1.5510549545288086
训练次数:4300,loss:1.2015137672424316
训练次数:4400,loss:1.1165118217468262
训练次数:4500,loss:1.3256618976593018
训练次数:4600,loss:1.4347445964813232
整体测试集上的loss为:237.9616264104843
整体测试集上的正确率为:0.4487000107765198
模型已保存
--------------------第7轮训练开始--------------------
训练次数:4700,loss:1.2991517782211304
训练次数:4800,loss:1.5193597078323364
训练次数:4900,loss:1.4198514223098755
训练次数:5000,loss:1.4244966506958008
训练次数:5100,loss:0.9594044089317322
训练次数:5200,loss:1.2893214225769043
训练次数:5300,loss:1.2365928888320923
训练次数:5400,loss:1.4055867195129395
整体测试集上的loss为:227.9086148738861
整体测试集上的正确率为:0.4733999967575073
模型已保存
--------------------第8轮训练开始--------------------
训练次数:5500,loss:1.2435195446014404
训练次数:5600,loss:1.2319049835205078
训练次数:5700,loss:1.234939455986023
训练次数:5800,loss:1.2523704767227173
训练次数:5900,loss:1.3638105392456055
训练次数:6000,loss:1.5132554769515991
训练次数:6100,loss:1.0711324214935303
训练次数:6200,loss:1.095482349395752
整体测试集上的loss为:218.40774488449097
整体测试集上的正确率为:0.49779999256134033
模型已保存
--------------------第9轮训练开始--------------------
训练次数:6300,loss:1.465518593788147
训练次数:6400,loss:1.1293203830718994
训练次数:6500,loss:1.5588335990905762
训练次数:6600,loss:1.102211594581604
训练次数:6700,loss:1.0397547483444214
训练次数:6800,loss:1.1206637620925903
训练次数:6900,loss:1.0915988683700562
训练次数:7000,loss:0.9147582650184631
整体测试集上的loss为:208.8978431224823
整体测试集上的正确率为:0.527400016784668
模型已保存
--------------------第10轮训练开始--------------------
训练次数:7100,loss:1.2496709823608398
训练次数:7200,loss:1.0066224336624146
训练次数:7300,loss:1.111189365386963
训练次数:7400,loss:0.8599532842636108
训练次数:7500,loss:1.2524861097335815
训练次数:7600,loss:1.2837167978286743
训练次数:7700,loss:0.8742030262947083
训练次数:7800,loss:1.2658190727233887
整体测试集上的loss为:200.53929316997528
整体测试集上的正确率为:0.5494999885559082
模型已保存
特殊层作用
①model.train()和model.eval()的区别在于Batch Normalization和DropOut两层。
②如果模型中有BN层(Batch Normalization)和Dropout,需要在训练时添加model.train()。model.train()是保证BN层能够用到每一批数据的均值和方差。对于Dropout,model.train()是随机取一部分网络连接来训练更新参数。
③ 不启用 Batch Normalization 和 Dropout。 如果模型中有BN层(Batch Normalization)和Dropout,在测试时添加model.eval()。model.eval()是保证BN层能够用全部训练数据的均值和方差,即测试过程中要保证BN层的均值和方差不变。对于Dropout,model.eval()是利用到了所有网络连接,即不进行随机舍弃神经元。
④ 训练完train样本后,生成的模型model要用来测试样本。在model(test)之前,需要加上model.eval(),否则的话,有输入数据,即使不训练,它也会改变权值。这是model中含有BN层和Dropout所带来的的性质。
⑤ 在做one classification的时候,训练集和测试集的样本分布是不一样的,尤其需要注意这一点。
import torchvision
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# from model import * 相当于把 model中的所有内容写到这里,这里直接把 model 写在这里
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3,32,5,1,2), # 输入通道3,输出通道32,卷积核尺寸5×5,步长1,填充2
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(), # 展平后变成 64*4*4 了
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self, x):
x = self.model1(x)
return x
# 准备数据集
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10,则打印:训练数据集的长度为:10
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
# 利用 Dataloader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
tudui = Tudui()
# 损失函数
loss_fn = nn.CrossEntropyLoss() # 交叉熵,fn 是 fuction 的缩写
# 优化器
learning = 0.01 # 1e-2 就是 0.01 的意思
optimizer = torch.optim.SGD(tudui.parameters(),learning) # 随机梯度下降优化器
# 设置网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮次
epoch = 10
# 添加 tensorboard
writer = SummaryWriter("logs")
for i in range(epoch):
print("-----第 {} 轮训练开始-----".format(i+1))
# 训练步骤开始
tudui.train() # 当网络中有dropout层、batchnorm层时,这些层能起作用
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 计算实际输出与目标输出的差距
# 优化器对模型调优
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播,计算损失函数的梯度
optimizer.step() # 根据梯度,对网络的参数进行调优
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step,loss.item())) # 方式二:获得loss值
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 测试步骤开始(每一轮训练后都查看在测试数据集上的loss情况)
tudui.eval() # 当网络中有dropout层、batchnorm层时,这些层不能起作用
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 没有梯度了
for data in test_dataloader: # 测试数据集提取数据
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 仅data数据在网络模型上的损失
total_test_loss = total_test_loss + loss.item() # 所有loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "./model/tudui_{}.pth".format(i)) # 保存每一轮训练后的结果
#torch.save(tudui.state_dict(),"tudui_{}.path".format(i)) # 保存方式二
print("模型已保存")
writer.close()
运行效果如下:
Files already downloaded and verified
Files already downloaded and verified
训练数据集的长度:50000
测试数据集的长度:10000
-----第 1 轮训练开始-----
训练次数:100,Loss:2.292330265045166
训练次数:200,Loss:2.2909886837005615
训练次数:300,Loss:2.2775135040283203
训练次数:400,Loss:2.2197389602661133
训练次数:500,Loss:2.1354541778564453
训练次数:600,Loss:2.034959077835083
训练次数:700,Loss:2.0130105018615723
整体测试集上的Loss:319.69296860694885
整体测试集上的正确率:0.2678999900817871
模型已保存
-----第 2 轮训练开始-----
训练次数:800,Loss:1.8924949169158936
训练次数:900,Loss:1.8564952611923218
训练次数:1000,Loss:1.9163199663162231
训练次数:1100,Loss:1.972761631011963
训练次数:1200,Loss:1.698002815246582
训练次数:1300,Loss:1.6668578386306763
训练次数:1400,Loss:1.7467551231384277
训练次数:1500,Loss:1.8171281814575195
整体测试集上的Loss:294.6422094106674
整体测试集上的正确率:0.3321000039577484
模型已保存
-----第 3 轮训练开始-----
训练次数:1600,Loss:1.7753604650497437
训练次数:1700,Loss:1.637514591217041
训练次数:1800,Loss:1.936806559562683
训练次数:1900,Loss:1.710182785987854
训练次数:2000,Loss:1.9697281122207642
训练次数:2100,Loss:1.507324457168579
训练次数:2200,Loss:1.4598215818405151
训练次数:2300,Loss:1.8211809396743774
整体测试集上的Loss:268.6419733762741
整体测试集上的正确率:0.37880000472068787
模型已保存
-----第 4 轮训练开始-----
训练次数:2400,Loss:1.696730136871338
训练次数:2500,Loss:1.3451323509216309
训练次数:2600,Loss:1.614168643951416
训练次数:2700,Loss:1.5963644981384277
训练次数:2800,Loss:1.4918489456176758
训练次数:2900,Loss:1.6028531789779663
训练次数:3000,Loss:1.3561456203460693
训练次数:3100,Loss:1.5363717079162598
整体测试集上的Loss:260.29946398735046
整体测试集上的正确率:0.39590001106262207
模型已保存
-----第 5 轮训练开始-----
训练次数:3200,Loss:1.3781168460845947
训练次数:3300,Loss:1.4570066928863525
训练次数:3400,Loss:1.4464694261550903
训练次数:3500,Loss:1.5474085807800293
训练次数:3600,Loss:1.5136005878448486
训练次数:3700,Loss:1.3479602336883545
训练次数:3800,Loss:1.2738752365112305
训练次数:3900,Loss:1.483515977859497
整体测试集上的Loss:243.80596554279327
整体测试集上的正确率:0.4325999915599823
模型已保存
-----第 6 轮训练开始-----
训练次数:4000,Loss:1.376009464263916
训练次数:4100,Loss:1.4102662801742554
训练次数:4200,Loss:1.5586539506912231
训练次数:4300,Loss:1.202476978302002
训练次数:4400,Loss:1.0953962802886963
训练次数:4500,Loss:1.3712406158447266
训练次数:4600,Loss:1.3603018522262573
整体测试集上的Loss:229.96637046337128
整体测试集上的正确率:0.4652999937534332
模型已保存
-----第 7 轮训练开始-----
训练次数:4700,Loss:1.3486863374710083
训练次数:4800,Loss:1.4762073755264282
训练次数:4900,Loss:1.3585703372955322
训练次数:5000,Loss:1.3923097848892212
训练次数:5100,Loss:0.9942217469215393
训练次数:5200,Loss:1.3098843097686768
训练次数:5300,Loss:1.1401594877243042
训练次数:5400,Loss:1.3566023111343384
整体测试集上的Loss:217.51882588863373
整体测试集上的正确率:0.499099999666214
模型已保存
-----第 8 轮训练开始-----
训练次数:5500,Loss:1.25923752784729
训练次数:5600,Loss:1.188690185546875
训练次数:5700,Loss:1.223688006401062
训练次数:5800,Loss:1.2504695653915405
训练次数:5900,Loss:1.3733277320861816
训练次数:6000,Loss:1.5391217470169067
训练次数:6100,Loss:1.0835392475128174
训练次数:6200,Loss:1.0833714008331299
整体测试集上的Loss:206.92583346366882
整体测试集上的正确率:0.5250999927520752
模型已保存
-----第 9 轮训练开始-----
训练次数:6300,Loss:1.4169930219650269
训练次数:6400,Loss:1.0912859439849854
训练次数:6500,Loss:1.5215225219726562
训练次数:6600,Loss:1.044875979423523
训练次数:6700,Loss:1.091143012046814
训练次数:6800,Loss:1.1253798007965088
训练次数:6900,Loss:1.106575608253479
训练次数:7000,Loss:0.8582056164741516
整体测试集上的Loss:198.72406196594238
整体测试集上的正确率:0.5472999811172485
模型已保存
-----第 10 轮训练开始-----
训练次数:7100,Loss:1.2614285945892334
训练次数:7200,Loss:1.0269255638122559
训练次数:7300,Loss:1.104204773902893
训练次数:7400,Loss:0.8442661166191101
训练次数:7500,Loss:1.2488468885421753
训练次数:7600,Loss:1.2494431734085083
训练次数:7700,Loss:0.8363684415817261
训练次数:7800,Loss:1.2570160627365112
整体测试集上的Loss:193.20221555233002
整体测试集上的正确率:0.5633000135421753
模型已保存
完整的模型验证套路
利用已经训练好的模型,然后给它输入
import torch
import torchvision
from PIL import Image
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
image_path = "../images/airplane.jpg"
image = Image.open(image_path)
# print(type(image)) # <class 'PIL.JpegIm agePlugin.JpegImageFile'>
# 注意:png格式是四个通道,除了RGB三通道外,还有一个透明度通道。因此,要保留其颜色通道。
# 加上这一步后,可以适应png jpg各种格式的图片。当然,如果图片本来就是三个颜色通道,通过此操作,不变.
# image = image.convert('RGB')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
# 拷贝网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(64*4*4, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 加载网络模型
model = torch.load("tudui_29_gpu.pth", map_location=torch.device('cpu'))
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval() # 易遗忘
with torch.no_grad():
output = model(image)
output = model(image)
print(output)
print(output.argmax(1))
运行结果如下:
torch.Size([3, 32, 32])
Tudui(
(model): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
tensor([[ 8.2018, -1.2829, 6.1294, 2.2612, 2.3820, -2.4763, -2.6638, -3.2455,
0.0971, -8.9255]], grad_fn=<AddmmBackward0>)
tensor([0])
CIFAR10中所对应的类别
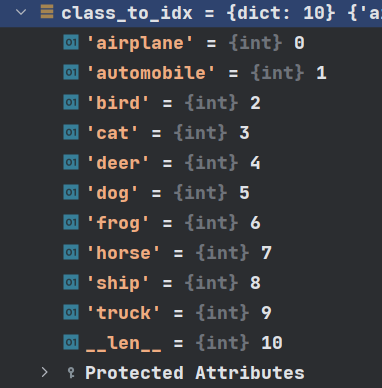
基本知识
梯度下降
什么是梯度下降?
梯度下降是一种用于训练神经网络等机器学习模型的优化算法。它的目标是找到模型参数的最佳值,以最小化某个损失函数的值。损失函数是一个衡量模型预测与实际结果之间差异的函数。
梯度下降的基本思想是沿着损失函数梯度的反方向更新模型参数,以逐步减小损失函数的值,直到找到最小值。这就好像在山上寻找最低点,每一步都沿着最陡峭的下坡方向移动。
批量梯度下降(Batch Gradient Descent)
批量梯度下降是最基本的梯度下降算法之一。它的步骤如下:
- 计算梯度(Gradient Computation):首先,根据损失函数计算模型参数的梯度。梯度告诉我们损失函数在当前参数值附近的变化方向。
- 参数更新(Parameter Update):然后,通过将当前参数减去学习率(learning rate)乘以梯度来更新参数。学习率决定了每次更新的步长大小。
- 重复迭代(Iterate):重复上述两个步骤,直到损失函数收敛到最小值或达到预定的迭代次数。
随机梯度下降(Stochastic Gradient Descent)->重点
随机梯度下降是梯度下降的变体,它在每次迭代中只使用训练数据中的一个样本来计算梯度。其步骤如下:
- 随机选择样本(Random Sample Selection):在每次迭代开始时,随机选择一个训练样本。
- 计算梯度(Gradient Computation):更新参数,然后继续下一次迭代。
- 参数更新(Parameter Update):更新参数,然后继续下一次迭代。
由于随机性,随机梯度下降可能会在搜索最小值的路径上有所不同,但通常更快的收敛到局部最小值。
随机梯度下降(Stochastic Gradient Descent,SGD)是梯度下降算法的一种变体,它通常用于训练机器学习模型,特别是神经网络。SGD的主要特点是在每次迭代中仅使用一个训练样本来计算梯度和更新模型参数,而不是像批量梯度下降那样使用整个训练数据集。
以下是SGD的详细介绍:
工作原理:
- 初始化参数:首先,SGD会初始化模型的参数,通常为随机值。
- 迭代过程:然后,SGD会进入迭代过程,每次迭代都会执行以下步骤:
- 随机选择样本:从训练数据集中随机选择一个训练样本。
- 计算梯度:使用选定的样本计算损失函数关于模型参数的梯度。
- 更新参数:根据计算得到的梯度,更新模型的参数。更新规则通常遵循以下形式:新参数 = 旧参数 - 学习率 * 梯度。
- 重复迭代:重复执行迭代过程,通常迭代数会事先设定,或者可以根据性能来动态调整。
优点:
- 收敛速度快:由于每次迭代只使用一个样本,因此SGD通常比批量梯度下降收敛更快。
- 适用于大型数据集:SGD适用于大型数据集,因为它不需要在内存中同时存储整个数据集。
- 容易跳出局部最小值:由于随机性,SGD更有可能跳出局部最小值并找到全局最小值。
缺点:
- 不稳定:SGD的随机性可能导致损失函数在训练过程中出现震荡,使得收敛路径不稳定。
- 噪声影响:由于每次迭代只考虑一个样本,导致梯度估计中存在噪声,可能影响收敛性。
- 需要调整学习率:学习率的选择对SGD的性能影响很大,需要仔细调整。
为了改进SGD的不稳定性和噪声影响,通常会使用一些SGD的变种,如带动量的SGD(Momentum SGD)、Adagrad、RMSProp和Adam等,这些算法在实际应用中更加稳定且通常能够更快地收敛。
总之,SGD是一种常用的优化算法,特别适用于大型数据集和深度学习模型的训练。通过调整学习率和其他超参数,可以有效地使用SGD来训练各种机器学习模型。
小批量梯度下降(Mini-Batch Gradient Descent)
小批量梯度下降是上述两种方法的折衷,它在每次迭代中使用一小部分(称为小批量)训练样本来计算梯度。这种方法结合了批量梯度下降的稳定性和随机梯度下降的速度。
小批量梯度下降的步骤与批量梯度下降类似,只是在每次迭代中使用小批量数据而不是整个训练集。
总之,这些是梯度下降算法的基本概念,通过使用不同的梯度下降变体,可以有效地训练神经网络和其他机器学习模型。
反向传播算法(难)
反向传播(Backpropagation)是深度学习中用于训练神经网络的核心算法之一。它通过计算损失函数对神经网络参数的梯度(导数),然后沿着梯度的方向更新参数,从而使网络逐渐学会如何进行正确的预测。反向传播算法的工作原理如下:
-
前向传播(Forward Propagation):反向传播的第一步是前向传播。在这一步中,输入数据通过神经网络的每一层,从输入层一直传递到输出层,每一层都应用一些权重和激活函数。最终,网络生成一个预测结果。
-
损失函数计算:在前向传播结束后,我们需要计算损失函数(Loss Function)。损失函数度量了网络的预测值与实际标记之间的误差。我们的目标是通过调整网络参数来最小化这个误差,使得预测更准确。
-
反向传播(Backward Propagation):反向传播是核心步骤。它从损失函数开始,沿着神经网络的层次结构向后传播梯度。具体步骤如下:
- 计算输出层的梯度: 首先,计算输出层的梯度。这是损失函数关于输出的梯度。我们知道损失函数是关于预测值和真实标签的函数,所以可以计算出输出层的梯度。
- 传播梯度到前一层: 接下来,将输出层的梯度传播到前一层。这是通过链式法则实现的,将当前层的梯度乘以权重矩阵的转置。
- 重复该过程: 重复这个过程,依次计算并传播梯度,直到达到输入层。这样,我们就可以得到每一层的梯度。
-
参数更新:一旦我们得到了每一层的梯度,就可以以=使用梯度下降算法或其变种来更新网络参数。通常,我们将学习率(learning rate)与梯度相乘,然后从当前参数中减去这个值,以更新参数。
-
重复训练: 反向传播是一个迭代过程。我们通常会多次重复整个过程,直到网络的性能达到满意的水平为止。在每一次迭代中,网络参数都会被微调,以减小损失函数的值。
反向传播算法的关键思想是通过计算梯度来了解如何调整每一层的参数,以最小化损失函数。这种方法使神经网络能够逐渐学习复杂的模式和规律,从而在各种任务中取得出色的性能,如图像分类、语音识别和自然语言处理。
神经网络
神经网络是机器学习的一种算法,由输入层、隐层和输出层组成。严格上来说,神经网络的隐层(灰色部分)是由感知机组成,黄色代表输入层,蓝色代表输出层。
神经网络的基本概念
- 神经元(Neuron):神经网络的基本单元,就像大脑中的神经元一样。每个神经元接受输入,执一些计算,并生成输出
- 输入(Input):神经网络的输入是一组特征或数据,用于执行任务。例如:对于图像识别,输入可以是像素值;对于自然语言处理,输入可以是单词或字符
- 权重(Weight):每个神经元都有与之关联的权重,用于调整输入的重要性。权重表示神经元学习到的知识
- 激活函数(Activation Function):激活函数决定神经元的输出。它通常是一个非线性函数,如Sigmoid、ReLU(Rectified Linear Unit)等,使得神经网络可以学习非线性关系。
- 隐藏层(Hidden Layer):神经网络通常有多个神经元组成的层级结构组成。除了输入层和输出层外,中间的层被称为隐藏层,因为它们的计算过程在模型外部时不可见的。
- 前向传播(Forward Propagation):前向传播是指输入数据从网络的输入层经过一系列的权重和激活函数计算,最终得到输出的过程。这是神经网络用于进行预测或分类的过程。
- 反向传播(Backpropagation):反向传播用于度量神经网络的输出与实际目标之间的差异。训练的目标是最小化损失函数。
- 损失函数(Loss Function):损失函数用于度量神经网络的输出与实际目标之间的差异。训练的目标是最小化损失函数。
- 优化算法(Optimization Algorithm):优化算法用于更新神经网络的权重,以减小损失函数。常见的优化算法包括梯度下降、随机梯度下降和Adam等。
- 输出层(Output Layer):输出层产生最终的预测或分类的结果。它的结构取决于任务类型,例如二分类问题可能使用一个神经元,而多分类问题可能使用多个神经元。
神经网络的基本思想是通过学习适当的权重来映射输入到输出,使其能够解决各种任务。这种学习过程是通过前向传播和反向传播来实现的,神经网络不断地调整权重以提高性能。
神经网络的工作原理
神经网络的工作原理涉及一下几个关键步骤:
- 前向传播(Forward Propagation):输入数据从输入层传递到隐藏层,然后再传递到输出层。每个神经元中,输入与权重相乘,然后通过激活函数进行处理,产生输出。
- 权重调整(Weight Updates):网络的输出与真实目标之间存在误差。通过使用损失函数来度量误差,然后使用优化算法(如梯度下降);来更新网络中的权重,以减小误差。
- 反向传播(Backpropagation):误差从输出层向后传播到隐藏层,以计算每个神经元的梯度。这个梯度告诉我们如何调整权重以减小误差。
感知机
感知机就是一个分类的工具,只能处理二分类的问题,而且只能进行线性划分。感知机是后面要提到的神经网络的基础结构。
训练集、验证集与测试集的概念
训练集
- 训练集就像是教材中的习题,它是我们用来训练机器学习模型的数据集。
- 这个数据集包含了大量的样本数据,每个样本都有输入特征(比如图片、文本或数字)和对应的目标标签(比如图片中是猫还是狗)
- 模型通过训练集中的样本来学习如何进行预测,就像学生通过做习题来学习一样
验证集
- 验证集就像是模拟考试,它是用来评估模型在训练过程中的表现的数据集
- 当我们训练模型时,我们需要知道它是否真正的学到了东西,而不仅仅是记住了训练集的答案。验证集提供了独立的数据集,用于评估模型的性能
- 我们可以使用验证集来调整模型的超参数(比如学习率、层数等),以找到最佳的模型配置
测试集
- 测试集就像是真正的考试,它是用来最终评估模型性能的数据集
- 当模型训练和验证都完成后,我们使用测试集来评估模型在未见过的数据上的表现。这可以告诉我们模型在实际应用中的性能如何
- 测试集通常不会在训练和验证过程中使用,以确保评估的客观性
总之,训练集是用来训练模型的数据,验证集用于模型调优和评估,而测试集用于最终评估模型的性能。这个分离数据集的方式有助于确保模型能够泛化到未见过的数据,而不仅仅是记住了训练集的答案。这是机器学习和深度学习中非常重要的概念。
过拟合和欠拟合
过拟合(overfitting):
在机器学习中,当我们用复杂的模型来训练数据时,模型可能会“背诵”训练数据,但却没有真正学到通用的规律。这意味着当模型遇到新的数据时,它可能表现不佳,因为他没有理解问题的本质,只是记住了训练数据中的细节。过拟合通常伴随着模型在训练数据上表现的非常好,但在未见过的数据上表现差。
欠拟合(Underfitting):
但我们使用过于简单的模型来拟合训练数据时,模型可能无法捕捉到数据中的复杂关系和规律。这意味着即使在训练数据上表现一般,但当模型遇到复杂的、未见过的数据时,它也不能很好地做出预测。欠拟合通常伴随模型在训练数据上表现差。
如何解决过拟合和欠拟合:
解决过拟合的方法包括:
- 收集更多的训练数据,以确保模型能够学到更多的通用规律
- 简化模型,减少模型的复杂度,可以通过减少模型的层数或参数数量来实现
- 使用正则化技巧,如L1正则化或L2正则化,来降低模型的复杂度
- 使用丢弃(dropout)等技术来减少模型对某些特征的依赖
解决欠拟合的方法包括:
- 增加模型的复杂度,可以增加模型的层数或参数数量
- 改进特征工程,确保模型可以看到更多有用的特征
- 增加训练时间,让模型有更多机会学习数据的规律
总之,过拟合和欠拟合是机器学习中常见的问题,但可以通过调整模型复杂度、收集更多数据和使用正则化等方法来解决。
正则化
正则化是什么?
在机器学习中,正则化是一种方法,它帮助模型更好的学习数据的规律,而不是只是记住答案。正则化通过向模型的学习过程中添加一些额外的规则或约束来实现。
为什么需要正则化?
在我们训练机器学习模型时,模型可能会太”贪婪“,适途完美地适应每一个训练样本。这可能导致模型在面对新的数据时表现不佳,因为他没有真正学会问题的本质。
正则化的方式:
正则化可以有两种不同的方式。两种常见的正则化方法是:
-
L1正则化:通过向模型的训练过程添加一些额外的规则,使模型更倾向于保留一些重要的特征,而将其他特征的权重减小到接近零
L1正则化的工作方式:LI正则化的关键是在模型的损失函数中添加一个额外的项,这个项是特征权重的绝对值之和。这意味着模型在学习过程中会尽量使一些特征的权重变得非常小,甚至等于零。
L1正则化的好处:
- 降低模型的复杂度:通过减小不重特征的权重,L1正则化可以使模型更加简单,更容易泛化到新的数据
- 特征选择:L1正则化可以帮助识别和选择最重要的数据,这对于处理高位数据非常有用
- 防止过拟合:L1正则化可以减少模型对训练数据的过分拟合,提高模型的泛化能力
-
L2正则化:就像是告诉小朋友们,他们的答案不能太小或太大,要保持在一个适中的范围内。在模型中,L2正则化会让权重参数更加平滑,避免过分复杂。
正则化的好处:
正则化可以帮助模型更好地泛化到新的数据,这使得模型在面对未见过的数据时更有信心,表现的更好。所以,正则化就像是给学习机器一些额外的规则,帮助他们更好的学习数据的规律,而不是死记硬背答案。
特征工程
特征工程涉及到数据的预处理和特征的选择、提取、转换等过程,旨在为机器学习模型提供更有信息量、更能表达问题本质的特征,从而提高模型的性能。
特征是什么?
首先,特征就像是问题的线索或提示,它们帮助我们理解和解决问题。想象一下,你在玩猜谜游戏,特征就是那些提示你猜出答案的线索,比如颜色、形状、大小等等。
特征工程是什么?
特征工程就像是为猜谜游戏设计更好的线索。它是一个过程,通过处理数据和设计新的特征,让我们的机器学习模型更好地理解问题。特征过程可以包括以下几个方面:
- 特征选择:从原始数据中选择最重要的特征,去掉不相关或冗余的特征。就像是在猜谜游戏中只保留最有用的线索一样。
- 特征提取:将原始数据转换成更有信息量的特征。例如,从文本中提取关键词,从图像中提取颜色直方图等。
- 特征变换:对特征进行变换,使其更适合模型的要求。例如:对数据进行标准化,将数据缩放到相同的范围内。
- 特征创造:有时候,我们需要创造新的特征,以便更好地捕捉数据中的模式。这就像是设计新的线索来解决更复杂的谜题。
为什么特征工程重要?:
特征工程非常重要,因为好的特征可以让模型更好地理解数据,更好地做出预测或决策。没有好的特征,就像是在猜谜游戏中没有足够的线索一样,很难解决问题。
特征过程的目标:
特征工程的目标是提高模型的性能、降低过拟合风险、加快模型训练速度,并使模型更具解释性。就像是为小朋友设计更好的线索,让他们更容易猜出答案一样。
总之,特征工程是机器学习中的重要环节,它通过设计更好的特征,帮助模型更好的理解问题,提高模型的性能。
回归拟合问题和分类识别问题
回归拟合问题
想象一下,你有一些数据点,它们散布在一个坐标图上,就像点在纸上一样。回归拟合问题就像是要找到一条线,这些线尽量靠近这些点,使得他们离这条线的距离尽可能小。这条线可以帮助你预测未来的数据点在哪里。
举个例子,如果你知道一只小植物的年龄和它的高度,你可以使用回归拟合来找到一条直线,这条直线可以告诉你,随着年龄增加,这棵植物的高度会变得多高。
分类识别问题
现在,想象一下你有一堆不同种类的动物,比如,猫、狗和鸟,它们有不同的特征。分类识别问题就是像要教计算机如何辨别这些不同的动物。
所以,回归拟合问题时关于找到一条线来预测数据,而分类识别问题时关于教计算机如何分辨不同的东西,就像是告诉计算机上这是什么东西。
归一化
机器学习中的归一化是一种数据预处理技术,用于将不同特征的数据尺度和范围统一到相似的水平,以便更好的训练机器学习模型。它的目的是消除特征之间的量纲差异,避免某些特征对模型的影响过大,从而提高模型的性能和稳定性。
归一化的常见方法包括:
- 最小-最大缩放(Min-Max Scaling):将特征的值缩放到一个固定的范围,通常是[0,1]或[-1,1]。这种方法适用于特征的分布不受异常值影响的情况。
- Z-Score标注化(Standardization):将特征的值转化为均值0,标准差为1的标准正态分布。这种方法适用于特征的分布接近正态分布的情况。
- Robust标准化(Robust Scaling):使用特征的中位数和四分位距来缩放特征值,可以减弱异常值对归一化的影响。
为什么需要归一化?
- 归一化有助于提高机器学习算法的收敛速度,尤其是梯度下降等迭代算法
- 归一化可以使模型更加稳定,减少了特征尺度不同带来的模型不稳定性
- 归一化可以提高模型的泛化能力,使其在新数据上的表现更好
总之,机器学习中的归一化是一种重要的数据预处理技术,用于确保特征的尺度和范围在合理范围内,以便模型能够更好地学习和泛化。
什么是泛化?
在机器学习中,泛化意味着模型不仅仅能够适应训练数据中的样本,还能够在面对以前未见过的数据时表现良好。泛化是机器学习模型的一种能力,它使模型能够在面对未知数据时仍然有效工作。
卷积神经网络及python实现
卷积神经网络(convolutional Neural Network,CNN)是一种专门用于处理图像和图像类数据的深度学习模型。
卷积核(kernel)
卷积核就像是一个特殊的放大镜,它帮助我们看图片中的不同部分,这个放大镜会在图片上滑动,然后帮助我们找到一些特别的东西,比如图案、颜色或者形状。卷积核是CNN的核心概念之一。它是一个小的矩阵(通常是3x3或5x5大小),用于在输入图像上滑动并执行卷积操作。卷积操作是一种特殊的加权求和,它帮助模型从图像中提取特征。卷积核中的权重参数是可以学习的,通过训练来逐渐调整以提取有用的特征。
CNN典型拓扑结构
CNN通常由多个层级组成,包括卷积层、池化层和全连接层。典型的CNN结构如下:
- 卷积层(Convolutional layer):卷积层应用卷积来检测图像中的特征,例如边缘、纹理或形状。多个卷积核可以检测不同的特征。卷积操作在整个输入图像上执行,生成一个特征映射(Feature Map)。
- 池化层(Pooling Layer):池化层用于减低特征映射的维度,减少计算复杂性,并使模型对图像变换更加鲁棒。常见的池化操作是最大池化,他选择每个小区域中的最大值。
- 全连接层(Fully Connected Layer):全连接层用于将池化层的输出连接到模型的输出层,以进行分类或回归等任务。全连接层包含神经元,每个神经元与上一层的每个神经元相连接。
CNN的权值共享机制
CNN具有权值共享机制,这意味着在卷积层中,每个卷积核都与整个输入图像进行卷积操作。这就是说,学习到的特征检测器可以应用于图像的不同位置,从而使模型具有平移不变形。这是CNN在图像处理中非常强大的一个特性,因为它可以识别图像中的特征,而不受其位置的影响。
CNN提取的特征:
CNN从输入图像中提取层次化的特征,这些特征逐渐变得更加抽象和复杂。低层次的特征可以包括边缘、纹理和简单的形状,而高层次的特征可以包括物体的部分或整体,甚至是物体的类别。这些特征是通过卷积核在不同层级上提取的,最终用于图像分类、对象检测、图像生成等任务。
总之,CNN是一种用于图像处理的深度学习模型,通过卷积核、权值共享机制和层次化特征提取来识别和理解图像中的信息。它已经在计算机视觉领域取得了重大的突破,用于各种图像相关任务。
CNN代码实践(可跑)
# 步骤1:导入必要的库#
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import torch.nn.functional as F
# 步骤2:准备数据
# 我们需要一个数据集来训练我们的CNN。在这个示例中,我们将使用PyTorch内置的CIFAR-10数据集,它包含了10个不同类别的图片。
# 数据预处理,将图像数据转化为合适的格式
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 下载训练集和测试集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
# 步骤3:定义CNN模型
# 我们将定义一个简单的CNN模型,它包括卷积层、池化层和全连接层。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # 输入通道3(彩色图像),输出通道6,卷积核大小5x5
self.pool = nn.MaxPool2d(2, 2) # 最大池化,2x2的窗口
self.conv2 = nn.Conv2d(6, 16, 5) # 输入通道6,输出通道16,卷积核大小5x5
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 全连接层
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) # 输出10个类别
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
# 步骤4:定义损失函数和优化器
# # 我们将使用交叉熵损失函数来衡量模型的性能,并使用随机梯度下降(SGD)作为优化器来更新模型的参数。
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # 随机梯度下降
if __name__ == '__main__':
# 步骤5:训练模型
for epoch in range(10): # 两次迭代
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad() # 清空梯度
outputs = net(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新参数
running_loss += loss.item()
if i % 2000 == 1999: # 每2000个小批次打印一次损失
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
running_loss = 0.0
# 步骤6:测试模型
# 训练完成后,我们可以使用测试数据集来评估模型的性能。
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {100 * correct / total:.2f}%')
运行效果如下:
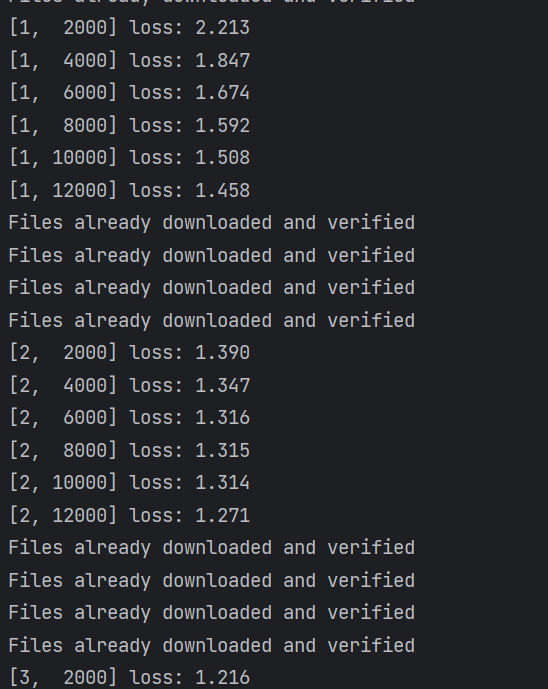
RNN循环神经网络的基本原理
RNN的工作原理是这样的:它有一个隐藏的记忆单元,可以保存之前的信息。在处理每个新的输入(比如一段文字中的每个字或一个时间序列中的每个时间点)时,RNN会考虑之前的信息并更新记忆。
RNN的关键点:
- 隐藏状态(Hidden State):RNN的隐藏状态就像大脑的记忆,它包含了之前看到的所有信息。在每个时间步,RNN会将新的输入和前一个时间步的隐藏状态结合起来,更新隐藏状态。
- 循环结构:RNN 中的循环结构允许信息在不同时间步之间传递。这使得 RNN 能够处理序列数据,比如自然语言文本、时间序列数据等。
- 输出:RNN 可以在每个时间步生成一个输出,也可以在整个序列处理后生成一个总的输出,取决于任务的要求。
- 训练:RNN 的训练是通过反向传播算法来进行的,目标是最小化模型的预测误差。这意味着模型会学习如何根据之前的信息来进行预测或分类。
需要注意的是,传统的RNN在处理长序列时存在梯度消失或梯度爆炸的问题,导致难以捕捉长距离依赖关系。因此,有一些改进型的RNN架构,比如长短时记忆网络(LSTM)和门控循环单元(GRU),被设计出来以解决这些问题,它们在实际应用中更常见。
总结一下: RNN是一种神经网络架构,用于处理序列数据。它通过隐藏状态来记住之前的信息,可以用于自然语言处理、时间序列分析、机器翻译等任务。但传统RNN存在梯度问题,因此通常使用改进型架构如LSTM和GRU。
LSTM文本分类实战
前置知识
embedding
当我们处理文本数据或分类问题时,通常需要将文字转化为数字,因为计算机更容易处理数字。嵌入(Embedding)是一种将文字或类别型数据映射为连续数字向量的方法。

但是,这样的表达方式可能不够有效,因为数字之间没有特定的关联。嵌入就是一种方法,他将每个词汇映射到一个连续的向量空间中,使得词汇之间的关系可以更好地被模型学习。
例如,我们可以将每个词汇映射为一个长度为N的向量,其中N是嵌入向量的维度。这样,每个词汇都可以用一个N维的向量表示。这些嵌入向量的值是模型根据文本数据学习到的,它们编码了词汇之间的语义信息。
举个例子,如果我们将"猫"映射为一个3维的嵌入向量 [0.2, 0.8, -0.5],将"狗"映射为 [0.6, 0.3, 0.9],那么这些向量之间的距离或相似度可以表示词汇之间的语义关系。例如,"猫"和"狗"的嵌入向量可能会更接近,因为它们都是动物。
总之,嵌入是一种将类别型数据(如文字)映射到连续向量空间的方法,以便于计算机模型学习和处理数据。在深度学习中,嵌入通常用于自然语言处理(NLP)任务,如文本分类、机器翻译和情感分析,以帮助模型理解和处理文本数据。
data文件夹中的部分信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号