
Python类与面向对象
Python类与面向对象
一、面向对象
1.1 面向对象概述
面向对象与面向过程?
面向过程编程的基本思想是:分析解决问题的步骤,使用函数实现每步对应的功能,按照步骤的先后顺序依次调用函数。面向过程只考虑如何解决当前问题,它着眼于问题本身。
面向对象编程的基本思想是:着眼于角色以及角色之间的联系。使用面向对象编程思想解决问题时,开发人员首先会从问题之中提炼出问题涉及的角色,将不同角色各自的特征和关系进行封装,以角色为主体,为不同角度定义不同的属性和方法,以描述角色各自的属性与行为。
1.2 面向对象的基本概念
1.对象
对象是一个程序模块,从用户来看,对象为他们提供所希望的行为。对象既可以是具体的物理实体的事物,也可以是人为的概念,如一名员工、一家公司、一辆汽车、一个故事等。
2.类
在面向对象的方法中,类是具有相同属性和行为的一组对象的集合,它提供了一个抽象的描述,其内部包括属性和方法两个主要部分。
3.抽象
抽象是抽取特定实例的共同特征,形成概念的过程。抽象主要是为了使复杂度降低,它强调主要特征,忽略次要特征,以得到较简单的概念,从而让人们能控制其过程或以综合的角度来了解许多特定的事态。
4.封装
封装是面向对象的核心思想,将对象的属性和行为封装起来,不需要让外界知道具体实现细节,避免了外界直接访问对象属性而造成耦合度过高及过度依赖,同时也阻止了外界对对象内部数据的修改而可能引发的不可预知错误。
5.继承
继承不仅增强了代码复用性,提高了开发效率,也为程序的扩充提供了便利。在软件开发中,类的继承性使所建立的软件具有开放性、可扩充性,这是数据组织和分类行之有效的方法,它降低了创建对象、类的工作量。
6.多态
多态指同一属性或行为在父类及其各派生类中具有不同的语义,面向对象的多态特性使开发更科学、更符合人类的思维习惯,能有效地提高软件开发效率,缩短开发周期,提高软件的可靠性。
二、类与对象
2.1 类与对象的关系
类是对多个对象共同特征的抽象描述,是对象的模板;对象用于描述现实中的个体,它是类的实例。
2.2 类的定义与访问
类的定义格式如下:
class 类名: # 使用class定义类 类名首字母一般为大写
属性名 = 属性值 # 定义属性
def 方法名(self,形参1,形参2,...,形参N): # 定义方法 方法中有一个指向对象的默认参数self
方法体
可以看到,在方法定义的参数中,有一个:self关键字。self关键字是成员方法定义的时候,必须填写的。
- 它用来表示类对象本身的意思
- 当我们使用类对象调用方法的时候,self会自动被python传入
- 在方法内部,想要访问类的成员变量,必须使用self
- self关键字,尽管在参数列表中,但是传参的时候可以忽略它。
2.3 对象的创建与使用
类定义完成后不能直接使用,程序中的类需要实例化为对象才能实现其意义。
对象的创建格式
对象名=类名()
访问对象成员
对象名.属性 # 访问对象属性
对象名.方法() # 访问对象方法
2.4 访问控制
类中定义的属性和方法默认为公有属性和方法,该类的对象可以任意访问类的公有成员。为了契合封装原则,python支持将类中的成员设置为私有成员,在一定程度上限制对象对类成员的访问。
定义私有成员
python通过在类成员名之前添加双下画线(__)来限制成员的访问权限,语法格式如下:
__属性名
__方法名
class PersonInfo:
__weight = 55 # 私有属性
def __info(self): # 私有方法
print(f"我的体重是:{__weight}")
私有成员的访问
对象无法直接访问类的私有成员。下面演示如何在类内部访问私有属性和私有方法。
访问私有属性。私有属性可在公有方法中通过指代类本身的默认参数self访问,类外部可通过公有方法间接获取类的私有属性。
class PersonInfo:
__weight = 65 # 私有属性
def get_weight(self):
print(f'体重:{self.__weight}kg') # 体重:65kg
personInfo = PersonInfo()
personInfo.get_weight()
访问私有方法。私有方法同样在公有方法中通过参数self访问。
class PersonInfo:
__weight = 65 # 私有属性
def __info(self): # 私有方法
print(f"我的体重是:{self.__weight}")
def get_weight(self):
print(f'体重:{self.__weight}kg')
self.__info()
# 创建PersonInfo类的对象person,访问公有方法get_weight()
personInfo = PersonInfo() # 体重:65kg
personInfo.get_weight() # 我的体重是:65
三、构造方法与析构方法
类中有两个特殊的方法:构造方法_init_()和析构方法__del()__。这两个方法分别在类创建和销毁的时候自动调用。
3.1 构造方法
每个类都有一个默认的_init_()方法,如果在定义类时显示地定义了_init()方法,则创建对象时python解释器会调用显式定义的_init_()方法;如果定义类时没有显式定义_init()方法,那么Python解释器会调用默认的_init()方法。
class Information(object):
def __init__(self, name, sex): # 有参构造方法
self.name = name # 添加属性name
self.sex = sex # 添加属性sex
def info(self):
print(f'姓名:{self.name}') # 姓名:齐纳
print(f'性别:{self.sex}') # 性别:男
information = Information('齐纳', '男')
information.info()
注意:前面在类中定义的属性是类属性,可以通过对象或类进行访问;在构造方法中定义的属性是实例属性,只能通过对象进行访问。
3.2 析构方法
在创建对象时,系统会自动调用_init_()方法,在对象被清理时,系统也会自动调用一个_del_()方法,这个方法就是类的析构方法。
扩展:python的垃圾回收机制。Pyhton中的垃圾回收主要采用的是引用计数。引用计数是一种内存管理技术,他通过引用计数器记录所有对象的引用数量,当对象的引用计数器数值为0时,就会将该对象视为垃圾进行回收。
import sys
# getrefcount()函数是sys模块中用于统计对象引用数量的函数,其返回结果通常比预期结果大1,这是因为getrefcount()函数也会统计临时对象的引用
class Destruction:
def __init__(self):
print('对象被创建')
def __del__(self):
print('对象被销毁')
# 调用getrefcount()函数返回Destruction类的对象的引用计数器的值。
destruction = Destruction()
print(sys.getrefcount(destruction)) # 2
3.3 其他方法
_str_()
# __str__字符串方法
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f'Student类对象,name={self.name},age={self.age}'
student = Student("赵无极", 10)
# print(student) # <__main__.Student object at 0x0000017F57579390>
# print(str(student)) # <__main__.Student object at 0x0000017F57579390>
print(student) # Student类对象,name=赵无极,age=10
print(str(student)) # Student类对象,name=赵无极,age=10
# 当类对象需要被转换为字符串之时,会输出如上结果(内存地址)
# 我们可以通过__str__方法,控制类转换为字符串的行为。
_lt_ 小于符号比较方法
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __lt__(self, other):
return self.age < other.age
stu1 = Student("周杰伦", 41)
stu2 = Student("林俊杰", 42)
# 直接对2个对象进行比较是不可以的,但是在类中实现__lt__方法,即可同时完成:小于符号 和 大于符号 2种比较
print(stu1 < stu2) # True
print(stu1 > stu2) # False
_le_ 小于等于比较符号方法
__le__可用于:<=、>=两种比较运算符上。
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __le__(self, other):
return self.age < other.age
stu1 = Student("周杰伦", 41)
stu2 = Student("林俊杰", 41)
print(stu1 <= stu2) # True
print(stu1 >= stu2) # False
_eq_,比较运算符实现方法
不实现__eq__方法,对象之间可以比较,但是是比较内存地址,也即是:不同对象==比较一定是False结果。实现了__eq__方法,就可以按照自己的想法来决定2个对象是否相等了。
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __eq__(self, other):
return self.age == other.age
student1 = Student("周杰库", 41)
student2 = Student("张学友", 41)
print(student2 == student1) # True
3.4 总结

四、类方法和静态方法
4.1 类方法
扩展:实例方法:直接定义、只比普通函数多一个self参数的方法是类最基本的方法,这种方法称为实例方法,它只能通过类实例化的对象调用。
类方法与实例方法有以下不同:
- 类方法使用装饰器@classmethod修饰
- 类方法的第一个参数是cls而非self,它代表类本身
- 类方法即可由对象调用,也可直接由类来调用
- 类方法可以修改类属性,实例方法无法修改类属性
定义类方法
语法格式如下:
类名.类方法
对象名.类方法
class Test:
@classmethod
def use_class_method(cls):
print(f'我是类方法')
test = Test()
Test.use_class_method() # 类名调用方法
test.use_class_method() # 对象名调用方法
从输出结果可以看出,使用类名或对象名均可调用类方法。
4.2 修改类属性
在实例方法中无法修改类属性的值,但在类方法中可以修改类属性的值。
class Apple(object): # 定义Apple类
count = 0 # 定义类属性
def add_one(self):
self.count = 1 # 对象方法
@classmethod
def add_two(cls):
cls.count = 2 # 类方法
apple = Apple()
apple.add_one()
print(Apple.count) # 0
print(apple.count) # 1
Apple.add_two()
print(Apple.count) # 2
从输出结果可以看出,调用实例方法add_one()后访问count的值为0,说明count的值没有被修改;调用类方法add_two()后再次访问count的值为2,说明类属性count的值被修改成功。
思考:通过"self.count=1"只是创建了一个与类属性同名的实例属性count并将其赋值为1,而非对类属性进行重新赋值。
4.3 静态方法
静态方法与实例方法有以下不同:
- 静态方法没有self参数,它需要使用@staticmethod修饰
- 静态方法中需要以“类名.方法名/属性名”的形式访问类的成员
- 静态方法即可有对象调用,亦可直接由类调用
class Example:
num = 10 # 类属性
@staticmethod # 定义静态方法
def static_method():
print(f'类属性的值为:{Example.num}')
print('--静态方法--')
example = Example() # 创建对象
example.static_method() # 对象调用
Example.static_method() # 类调用
总结:类方法和静态方法的区别
类方法和静态方法最主要的区别在于类方法有一个cls参数,使用该参数可以在类方法中访问类的成员;静态方法没有任何默认参数,它无法使用默认参数访问类的成员。因此,静态方法更适合与类无关的操作。
五、继承
5.1 单继承
单继承指的是子类只继承一个父类,其语法格式如下:
class 子类(父类):
class Amphibian:
name = '两栖动物'
def features(self):
print('幼年用腮呼吸')
print('成年用肺兼皮肤呼吸')
class Frog(Amphibian): # Frog类继承自Amphibian类
def attr(self):
print(f'青蛙是{self.name}')
print('我会呱呱叫')
frog = Frog() # 创建类的实例化对象
print(frog.name) # 访问父类的属性 两栖动物
frog.features() # 使用父类的方法 幼年用腮呼吸 成年用肺兼皮肤呼吸
frog.attr() # 使用自身的方法 青蛙是两栖动物 我会呱呱叫
从输出结果可以看出,子类继承父类之后,就拥有了父类继承的属性和方法,它既可以调用自己的方法,也可以调用从分类继承的方法。
扩展:isinstance()函数与issubclass()函数
isinstance(o,t)函数用于检查对象的类型,它有两个参数,第一个参数是要判断类型的对象(o),第二个参数是类型(t),如果o是t类型的对象,则函数返回True,否则返回False
print(isinstance(frog, Frog)) # True
函数issubclass(cls,classinfo)用于检查类的继承关系,它也有2个参数:第一个参数是要判断的子类型(cls);第二个参数是要判断的父类类型(classinfo)。如果cls类型是classinfo类型的子类,则函数返回True,否则返回False。
print(issubclass(Frog, Amphibian)) # True
5.2 多继承
多基础指的是一个子类继承多个父类,其语法格式如下:
class 子类(父类A, 父类B):
class English:
def eng_konw(self):
print('具备英语知识')
class Math:
def math_koow(self):
print('具备数学知识')
class Student(English, Math):
def study(self):
print('学生的任务是学习')
s = Student()
s.eng_konw() # 具备英语知识
s.math_koow() # 具备数学知识
s.study() # 学生的任务是学习
注意事项:多个父类中,如果有同名的成员,那么默认以继承顺序(从左到右)为优先级。
即:先继承的保留,后继承的被覆盖
5.3 方法的重写
子类可以继承父类的属性和方法,若父类的方法不能满足子类的要求,子类可以重写父类的方法,以实现辅助的功能。
class Felines:
def speciality(self):
print("猫科动物特长是爬树")
class Cat(Felines):
name = "猫"
def speciality(self):
print(f'{self.name}会抓老鼠')
print(f'{self.name}会爬树')
cat = Cat()
cat.speciality()
程序运行结果:
猫会抓老鼠
猫会爬树
5.4 super()函数
如果子类重写了父类的方法,但仍希望调用父类中的方法,可以通过super()函数调用父类的方法。
super()函数使用方法如下:
super().方法名()
class Felines:
def speciality(self):
print("猫科动物特长是爬树")
class Cat(Felines):
name = "猫"
def speciality(self):
print(f'{self.name}会抓老鼠')
print(f'{self.name}会爬树')
print("*" * 20)
super().speciality()
cat = Cat()
cat.speciality()
程序运行结果如下:
猫会抓老鼠
猫会爬树
********************
猫科动物特长是爬树
从输出结果可以看出,通过super()函数可以访问被重写的父类方法。
5.5 多态
在Python中,多态值在不考虑对象类型的情况下使用对象。Python中并不需要显式指定对象的类型,只要对象具有预期的方法和表达式操作符,就可以使用对象。
pass关键字的作用是什么?
pass是占位语句,用来保证函数(方法)或类定义的完整性,表示无内容,空的意思。
class Animal(object): # 定义父类Animal
def move(self):
pass
class Rabbit(Animal): # 定义子类Rabbit
def move(self):
print('兔子蹦蹦跳跳')
class Snail(Animal): # 定义子类Snail
def move(self):
print('蜗牛缓慢爬行')
def test(obj):
obj.move()
rabbit = Rabbit()
test(rabbit) # 接受Rabbit对象
snail = Snail()
test(snail) # 接受Snail对象
程序运行结果
兔子蹦蹦跳跳
蜗牛缓慢爬行
从运行结果看出,同一个函数会根据参数的类型去调用不同的方法,从而产生不同的结果。
六、类型注解
7.1 变量的类型注解
Pyhton在3.5版本的时候引入了类型注解,以方便静态类型检查工具,IDE等第三方工具。
类型注解:在代码中涉及数据交互的地方,提供数据类型的注解(显示的说明)。
主要功能:
- 帮助第三方IDE工具(如Pycharm)对代码进行类型推断,协助做代码提示
- 帮助开发者自身对变量进行类型注释
支持:
- 变量的类型注解
- 函数(方法)形参列表和返回值的类型注解
类型注解的语法
基础语法:变量:类型
# 基础数据类型注解
var1: int = 10
var2: float = 3.1515926
var3: bool = True
var_4: str = "boost"
# 类对象类型注解
class Student:
pass
stu: Student = Student()
# 基础容器类型注解
my_list: list = [1, 2, 4]
my_tuple: tuple = (1, 2, 3)
my_set: set = {1, 2, 4}
my_dict: dict = {"name": "张三"}
my_str: str = "李四"
# 容器类型详细注解
"""
1. 元组类型设置类型详细注解,需要将每一个元素都标记出来
2. 字典类型设置类型详细注解,需要2个类型,第一个是key,第二个是value
"""
my_list1: list[int] = {1, 2, 4}
my_tuple1: tuple[str, int, bool] = ("张三", 34, True)
my_set1: set[int] = {1, 2, 4}
my_dict1: dict[str, int] = {"name": "张三"}
除了使用 变量: 类型, 这种语法做注解外,也可以在注释中进行类型注解。
语法:
#type: 类型
# 在注释中进行类型注解
class Student:
pass
var_1 = random.randint(1, 10) # type:int
var_2 = json.loads(data) # type:dict[str,int]
var_3 = func() # type:Student
tips:一般,无法直接看出变量类型之时会添加变量的类型注解。
类型注解的限制
类型注解主要功能在于:
- 帮助第三方IDE工具对代码进行类型判断,协助做代码提示
- 帮助开发者自身对变量进行类型注释(备注)
并不会真正的对类型做验证和判断,也就是说,类型注解仅仅是提示性的,不是决定性的。
var_1: int = "张三"
var_2: str = 123
# 该代码是不会报错的
总结

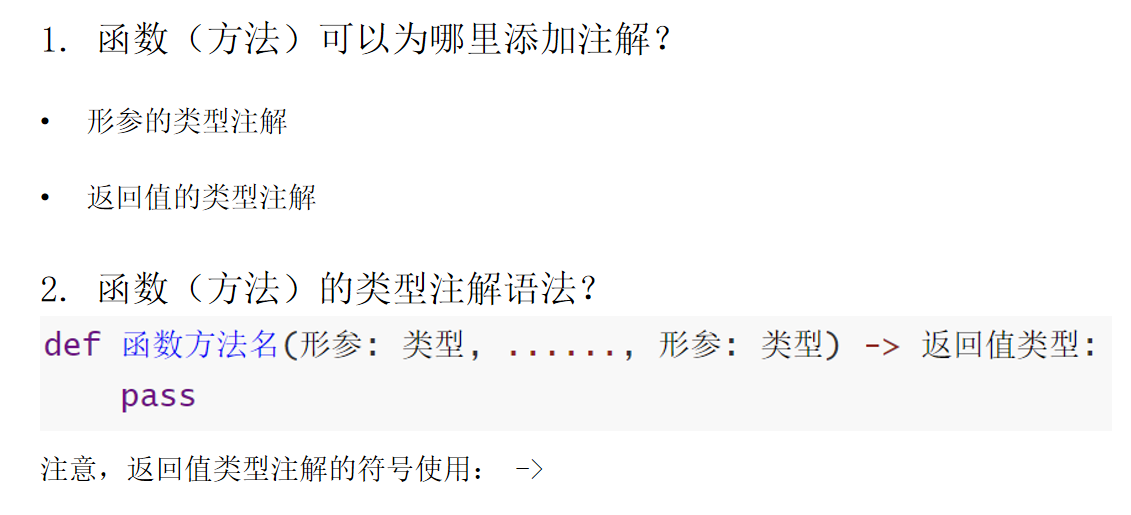
7.2 函数(方法)的类型注解
7.2.1 函数(方法)的类型注解 - 形参注解
函数和方法的形参类型注解语法:
def 函数方法名(形参名:类型,形参名:类型,.......):
pass
def add(x: int, y: int):
return x + y
add(1, 3)
def func(data: list):
data.append(1)
7.2.2 函数(方法)的类型注解 - 返回值注解
函数(方法)的返回值也是可以添加类型注解的。语法如下:
def 函数方法名(形参:类型,形参:类型, .....) -> 返回值类型:
pass
def add(x: int, y: int) -> int:
return x + y
def func(data: list[int]) -> list[int]:
pass
7.2.3 总结
7.3 Union类型
使用Union[类型,...,类型]可以定义联合类型注解
mylist: list[int] = [1, 2, 3]
my_dict: dict[str, int] = {"age": 31, "num": 1}
mylist = [1, 2, "name"]
my_dict = {"name": "周杰伦", "age": 43}
from typing import Union
mylist: list[Union[str, int]] = [1, 2, "name"]
my_dict: dict[str, Union[str, int]] = {"name": "周杰伦", "age": 43}
# Union联合类型注解,在变量注解、函数(方法)形参和返回值注解中,均可使用。
my_list: list[Union[int, str]] = [1, 2, "张三", "李四"]
my_dict: dict[Union[int, str]] = [1, 2, "张三", "李四"]
def func(data: Union[int, str]) -> Union[int, str]:
pass
总结:

七、案例
7.1 学生信息录入
基本需求

实现代码:
class Student:
def __init__(self, name, age, address, count):
self.name = name
self.age = age
self.address = address
self.count = count
print(f"学生{count}信息录入完成,信息为:【学生姓名:{self.name},年龄:{self.age},地址:{self.address}】")
count += 1
for i in range(1, 11):
print(f'当前录入第{i}位学生信息,总共需录入10位学生信息')
name = input("请输入学生姓名:")
age = input("请输入学生年龄:")
address = input("请输入学生地址:")
student = Student(name, age, address, i)
7.2 数据分析案例
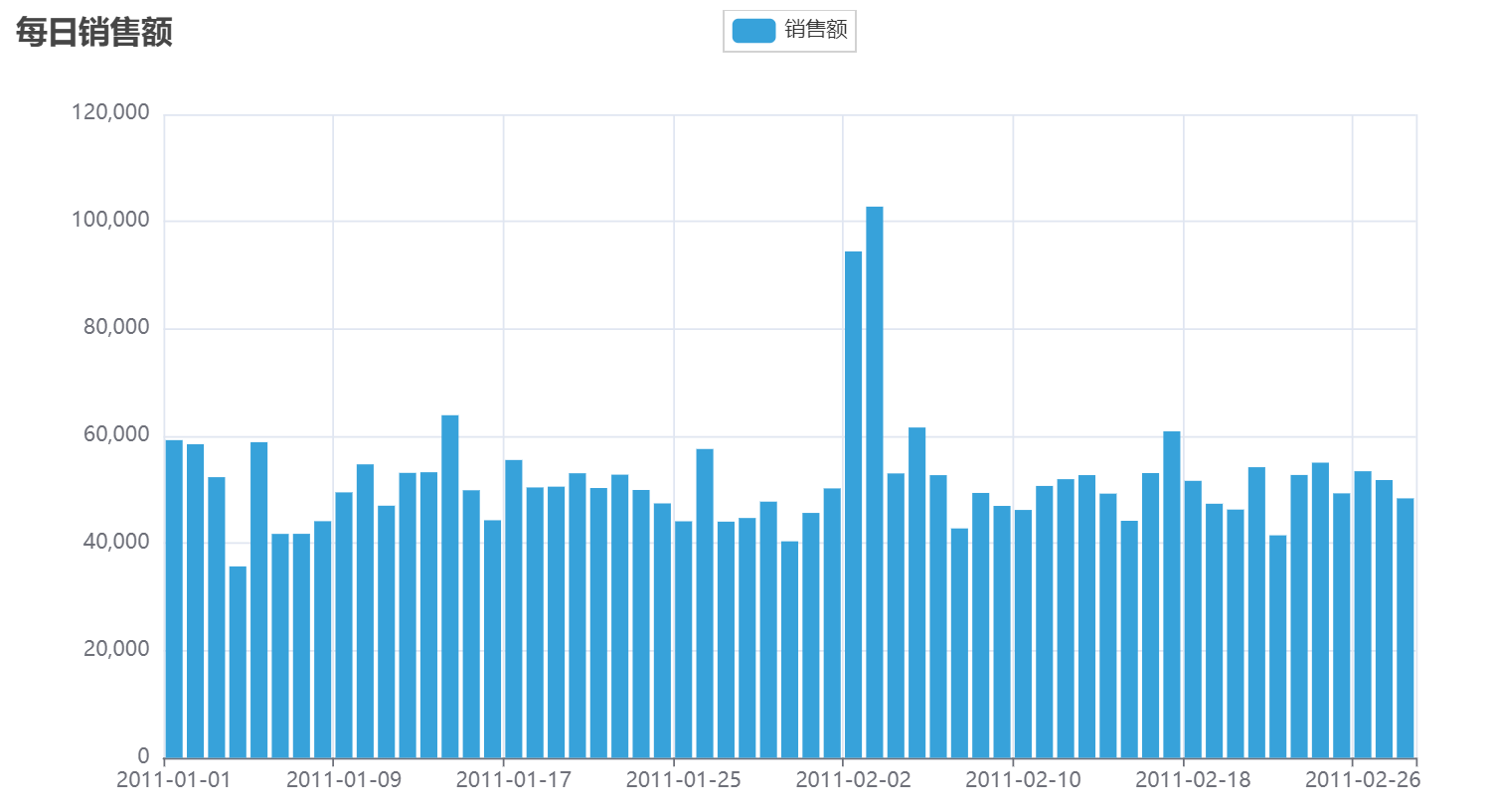
某公司,有2份数据文件,现需要对其进行分析处理,计算每日的销售额并以柱状图表的形式进行展示。
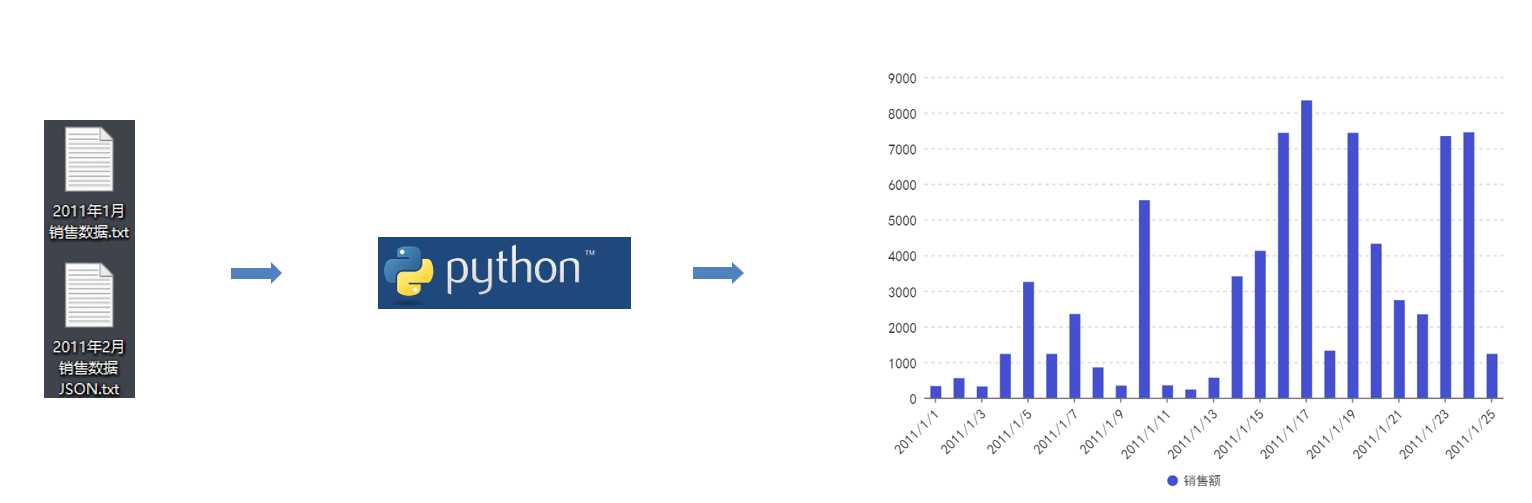
数据内容
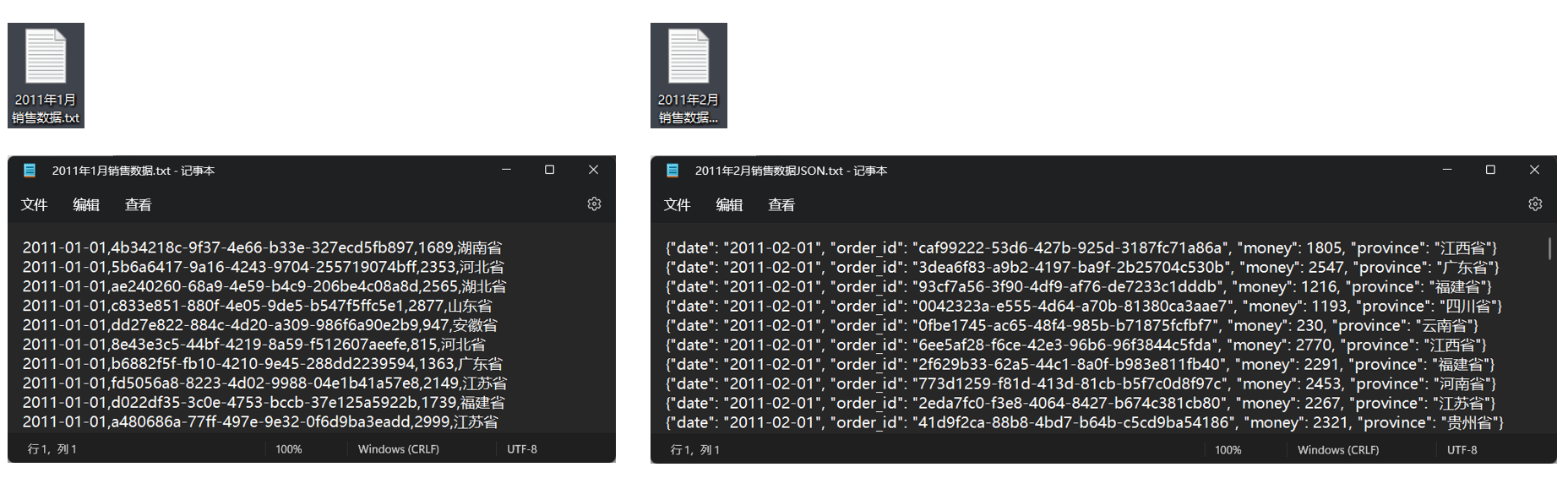
1月份数据是普通文本,使用逗号分割数据记录,从前到后分别是(日期,订单id,销售额,销售省份)
2月份数据是JSON数据,同样包含(日期,订单id,销售额,销售省份)
需求分析
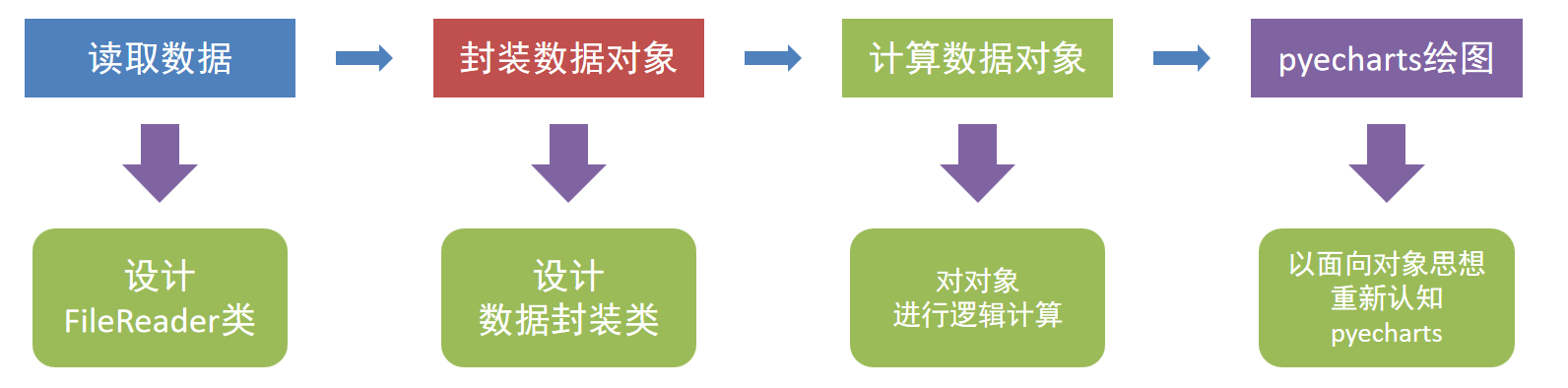
实现代码如下:
数据定义:data_define.py
"""
数据定义的类
"""
class Record:
def __init__(self, date, order_id, money, province):
self.date = date # 订单日期
self.order_id = order_id # 订单ID
self.money = money # 订单金额
self.province = province # 销售省份
def __str__(self):
return f"订单日期={self.date},订单ID={self.order_id},订单金额={self.money},销售省份={self.province}"
操作文件:file_define.py
"""
和文件相关的类定义
"""
import json
# 导包
from data_define import Record
# 先定义一个抽象类用来做顶层设计,确定有哪些功能需要实现
class FileReader:
# 抽象方法
def reader_data(self) -> list[Record]:
# 读取文件数据,读到的每一条数据都转换为Record对象,将他们都封装到list内返回即可
pass
class TextFileReader(FileReader):
def __init__(self, path):
self.path = path # 定义成员变量记录文件路径
# 复写(实现抽象方法)父类的方法
def reader_data(self) -> list[Record]:
f = open(self.path, "r", encoding="UTF-8")
record_list: list[Record] = []
for line in f.readlines():
line = line.strip() # 消除读取到的每一行数据中的\n
data_list = line.split(",")
record = Record(data_list[0], data_list[1], int(data_list[2]), data_list[3])
record_list.append(record)
f.close()
return record_list
class JsonFileReader(FileReader):
def __init__(self, path):
self.path = path # 定义成员变量记录文件路径
# 复写(实现抽象方法)父类的方法
def reader_data(self) -> list[Record]:
f = open(self.path, "r", encoding="UTF-8")
record_list: list[Record] = []
for line in f.readlines():
data_dict = json.loads(line)
record = Record(data_dict["date"], data_dict["order_id"], int(data_dict["money"]), data_dict["province"])
record_list.append(record)
f.close()
return record_list
# 测试使用
if __name__ == '__main__':
text_file_reader = TextFileReader("2011年1月销售数据.txt")
json_filer_reader = JsonFileReader("2011年2月销售数据JSON.txt")
list1 = text_file_reader.reader_data()
list2 = json_filer_reader.reader_data()
for l in list1:
print(l)
for l in list2:
print(l)
主文件:main.py
"""
面向对象,数据分析案例,主业务逻辑代码
实现步骤:
1.设计一个类,可以完成数据的封装
2.设计一个抽象类,定义文件读取的相关功能,并使用子类实现具体功能
3.读取文件,生产数据对象
4.进行数据需求的逻辑计算(计算每一天的销售额)
5.通过PyEcharts进行图形绘制
"""
from file_define import FileReader, TextFileReader, JsonFileReader
from data_define import Record
from pyecharts.charts import Bar
from pyecharts.options import *
from pyecharts.globals import ThemeType
text_file_reader = TextFileReader("2011年1月销售数据.txt")
json_file_reader = JsonFileReader("2011年2月销售数据JSON.txt")
jan_data: list[Record] = text_file_reader.reader_data()
feb_data: list[Record] = json_file_reader.reader_data()
# 将2个月份的数据合并为一个list来存储
all_data: list[Record] = jan_data + feb_data
# 开始进行数据计算
# {"2011-1-1": 1234, "2011-01-02": 100}
data_dict = {}
for record in all_data:
if record.date in data_dict.keys():
# 当前日期已经有记录了,所以和老记录做累加即可
data_dict[record.date] += record.money
else:
data_dict[record.date] = record.money
# 可视化图表开发
bar = Bar(init_opts=InitOpts(theme=ThemeType.LIGHT))
bar.add_xaxis(list(data_dict.keys())) # 添加x轴的数据
bar.add_yaxis("销售额", list(data_dict.values()), label_opts=LabelOpts(is_show=False)) # 添加了y轴的数据
bar.set_global_opts(
title_opts=TitleOpts(title="每日销售额")
)
bar.render("每日销售额柱状图.html")
程序运行结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号