
0x01 为什么要做拥塞控制
我们知道TCP是一个可靠的传输层协议,与UDP最大的不同首先是可靠,然后是,为了实现可靠性,TCP需要在发送端和接收端维护发送窗口和接收窗口来缓存尚未被确认的报文。发送窗口是拥塞控制算法对当前网络传输能力的一个评估,发送窗口越大,拥塞控制算法认为
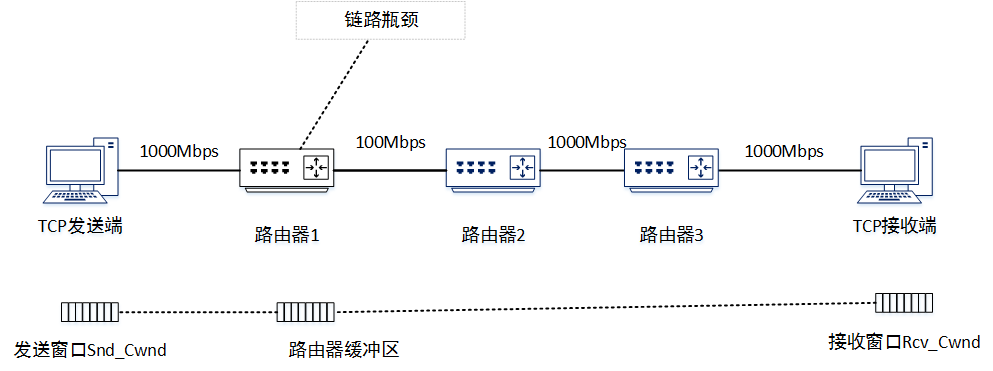
那么什么时候是网络拥塞呢?根据乡农公式,每条信道都有其最大容量,比如我们通过ethtool看到的网卡工作带宽100M,1000M等,当网络主机向网络中灌输的流量大于链路瓶颈带宽时,链路瓶颈处的路由器由于无法即时转发所有报文,需要先将部分报文缓冲在本地,等待端口空闲时转发,那么这个时候网络就可以被称作发生了拥塞。从以下几个角度看,我们都应该让主机主动探测网络状况,并在拥塞时降低报文的发送速率。
- 传输效率角度
路由器缓冲报文本是为了平滑链路中的突发流量,即路由器希望链路中的总体流量和其带宽基本一致,可能有时候多一点,有时候少一点,多的时候,路由器就缓冲一部分,并在链路流量少的时候把缓冲区内的流量也排空,但路由器的缓冲区大小也会有一个上限,一般都为链路的一个BDP级别,当路由器实在缓冲不了上游超发的流量的时候,只能丢掉后来的报文,那么这些被丢掉的报文白白浪费了从源点传输到该路由器的带宽,造成了传输效率的下降,从端点来看,就是发送端统计的吞吐率(Throughput)和接收端收到报文的速率(Goodput)有较大差距。
- 时延角度
当然为了减少链路的丢包,我们可以增大路由器的缓冲区大小,把所有上游超发的报文都缓冲下来,等待链路空闲时进行转发,但这又会导致另外一个问题,那就是BufferBloat现象,路由器缓冲区大小被无限制的扩大,甚至出现部分路由器永远有报文缓冲在缓冲区内,导致所有上游的报文都要在缓冲区内排一会儿队才能够转发到下游,造成了不变要的排队时延。我们所感受到的网络时延,其实是由主机协议栈打包解包时延,链路传播时延和路由器内的排队时延组成,其中协议栈的解包打包由于主机性能提升已经微不足道,基本都在纳秒级别,而链路的传播时延和网络的拓扑,空间距离的远近有关,受限于物理条件和光速已经很难突破,倒是排队时延还有很大的降低空间。例如路由器的缓冲区大小设置为一个BDP,而端主机采用诸如Reno,Cubic等拥塞控制算法时,路由器内缓冲区基本就处于高占用率的状态了,缓冲区达到一个BDP意味着排队的时延和链路的传播时延基本在一个等级了,这里面的优化空间还是很大的,目前也是有很多针对BufferBloat的算法,例如BBR,Codel等。
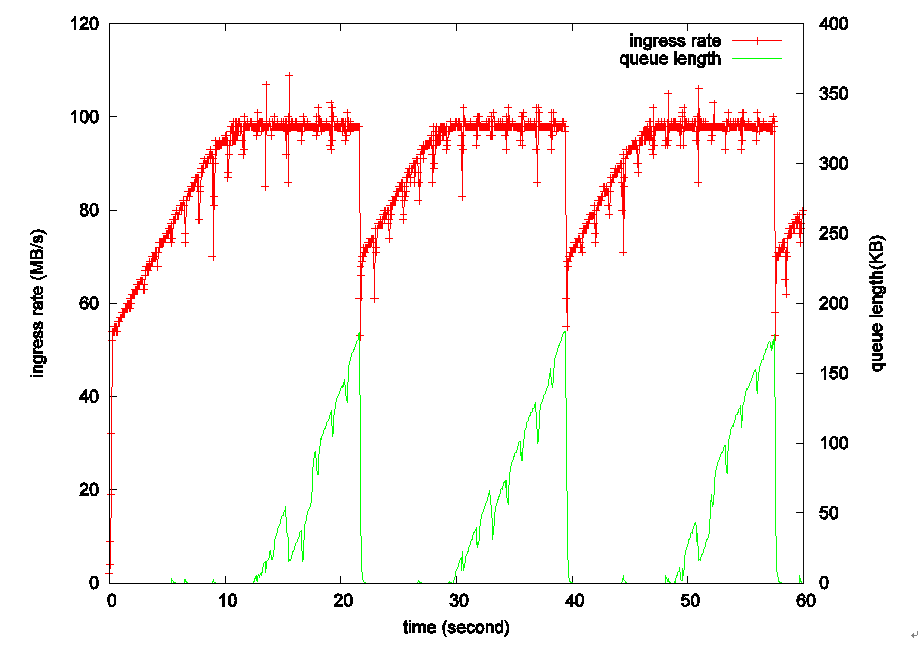
图1 TCP-Reno算法的吞吐率和队列长度变化
其实,当上游的流量达到路由器出口带宽时,上游继续增大发送窗口除了带来额外的排队时延,不能带来一点好处,上游的吞吐率也不会因为发送窗口的增大而增大,这是由窗口机制本身造成的,由于受下游速率的限制,超发的报文也只能缓存在路由器缓冲区中。典型的,比如图1中的Reno算法,Reno很简单就是线性增长发送窗口,直到探测到丢包,才会把窗口减小,那么当发送窗口达到BDP后,图中10秒左右处,继续增大窗口,上游的吞吐率(红线)会维持在链路瓶颈带宽,而路由器缓冲队列(绿线)随之慢慢增大,直到达到路由器缓冲区的最大长度,并发生丢包。关于这个,早在,TCP-Vegas,TCP-BBR也都是基于这一现象决定拥塞控制的时机的。
- 公平性角度
除了上面两个原因,TCP还要考虑公平性,这也是TCP要进行拥塞控制的重要原因,如果不考虑大家的感受,网络就是一个囚徒困境,增大自身的吞吐率总会比减小吞吐率收益更大,虽然会有人遭殃,but who cares...也确实有人这么干的,比如某某加速。因此,拥塞控制的一个重要目标就是让大家能够一个相对均势,不单单是一种拥塞控制算法与另外一种拥塞控制算法,一种拥塞控制算法的多条数据流之间也有肯能存在不公平。
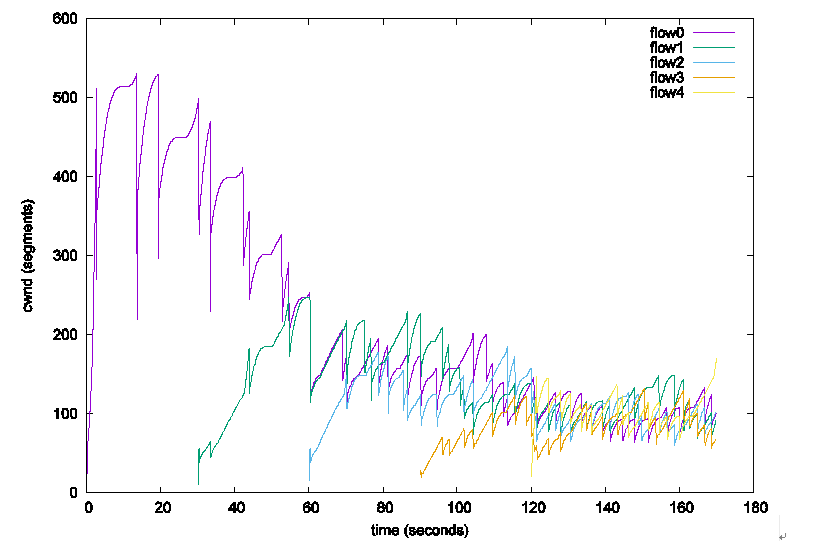
图2 TCP-Cubic 公平性收敛
0x02 拥塞控制基本原理
拥塞控制的核心问题是如何获得当前链路的状态,链路是否发生了拥塞,拥塞的程度是多少,或者当前空闲的带宽是多少,当前共有多少条数据流在共享链路等等,主机根据当前的链路状态决定是否增加发送窗口,增大多少等。
基于丢包
最典型的的方法是以丢包为链路发生拥塞的依据,在未检测到丢包时,不断增大发送窗口去探测网络的带宽,而当检测到丢包时,便认为链路拥塞,并减小发送窗口,代表算法有TCP-Reno,TCP-Cubic等。图2中的Cubic算法就是一个例子,但看第一条流flow0启动至flow1加入网络的这一段时间内,其发送窗口一直处于不断增大的状态,到500个报文段时,链路出现丢包,并开始减小,然后一直处于这一个循环中。这类算法一般都有以下几个特点:
- 一般来说简单可靠,当信道较好时,丢包基本等同于链路发生了拥塞,在网络环境没有那么复杂的年代,没有什么异构化,无线网,大文件等等,简单可靠的方法都能解决问题为什么不用呢?
- 特殊环境下不可靠,比如无线网络,信道本身就会有好多丢包,发送端感受到的丢包中有大部分都不是路由器主动丢弃的,这时候如果不借助时延,ECN等信息来判断丢包的类型的话,这类算法就只能来者不拒,把丢包全部当作链路发生拥塞的标志了,于是会看到下面这条链路利用率随着丢包率提升而下降的曲线,非常的惨烈,这还只是100Mbps,50ms网络下的表现,BDP越大,表现也会越惨烈,到了0.3%的丢包率时,基本就无法正常传输了。
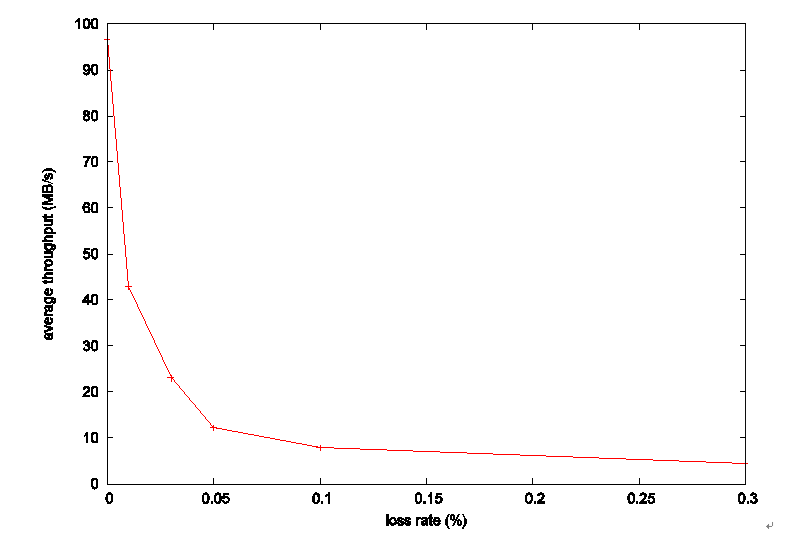
图3 Cubic吞吐率随丢包率变化
- 信息量小,当链路出现丢包时,发送端能够知道的就是链路中可能发生了拥塞,至于拥塞到底有多严重完全不知道,怎么办呢,只能把当前窗口减半,或者减到70%之类的,至于减到该值后,能不能缓解当前网络的拥塞,不知道,也有可能减小到一半后,还是有丢包,那也只能继续减下去了,这也是为什么这类算法在有随机丢包的环境下表现那么惨的原因了,这里放上一张实验室测得的数据图,
- 信号来得较晚,按理说图2中10秒处,链路总流量已经达到瓶颈带宽了,继续增大发送窗口没有任何好处,也就是达到了膝点,然而发送端不知道啊,只有到了20秒处发生了丢包,发送端才知道链路出现了拥塞,也就过了涯点,这个点做拥塞控制真的是已经到了末班车了,即使不进行拥塞控制,路由器上的队列管理算法也会把该丢的报文丢了,这里就有些机制的路由器端队列管理算法,比如RED,会在路由器缓冲区爆表前提前丢一些报文告诉上游降速。
- 链路空闲时带宽利用率低,这个就是以丢包为拥塞控制依据的另外一个问题了,丢包只发生在拥塞时,那么拥塞前呢,怎么增长发送速率,是一个RTT把发送窗口增长一个MSS,还是翻倍,三倍?这时候发送端对链路更加迷茫了,只知道路由器缓冲区还没爆表,至于是还有大量空闲带宽还是已经到了悬崖边缘完全不知道,只好硬着头皮往上走了,当然Bic,Cubic算法相对聪明些,它们记录了拥塞的历史信息,以上一次丢包时的窗口大小为链路瓶颈带宽,来加快带宽探测的速率。
基于网络测量类
网络测量类一般指基于时延或者瓶颈带宽,从图1可以看到,当上游流量达到瓶颈带宽时,瓶颈路由器就会产生一个缓冲队列,而发送端也会感受到时延增大,同时吞吐率也不再随着发送窗口的增大而增大了,发送端也就能够获知当前网络已经进入了拥塞状态了,并采取相应的处理。先说优点吧:
1. 首先根据时延变化来判断网络是否拥塞能够有效解决信道不可靠时随机丢包影响链路利用率的问题,时延的测量结果基本不受丢包的影响,如果拥塞控制算法完全依赖时延是否增大来判断链路是否拥塞,即不在检测到丢包时减小发送窗口,是完全能够屏蔽掉随机丢包带来的影响的。但完全无视丢包是一个非常激进的做法,事实上Linux内核的拥塞控制算法中只有最近加入的BBR才完全无视了丢包,完全无视掉丢包可能会带来另外一些问题,比如是否对基于丢包类的拥塞控制算法公平,又比如,丢包也有可能是网关限速丢掉的呢,还是有很多要考虑的因素的。
基于路由器反馈类
瓶颈带宽大小 ,当前的总流量,共享该链路的数据流数量,有了这三个信息,拥塞控制就可以做的无比精准,最简单的方法就是路由器直接把当前带宽平均分配到每条流,并把每条流得到的带宽写入报文捎带给发送端,发送端以此作为吞吐率,这种方法能够得到理论的最佳值,当然即使是在路由器,准确的估计当前链路中流的数量也不是一件容易的事情,但相对于端主机去做这件事情,还是准确多了,基于路由器反馈类的算法需要配套的链路状态获取协议例如ECN,DCTCP,XCP,RCP等等,相对来说比较小众,可靠性高,性能好,但需要链路上的所有路由器都支持信息的反馈,部署成本太大,但是在数据中心之类的可控范围内还是很有用处的。
0x04 拥塞控制算法分析
TCP-Reno
Reno应该是最简单的想法了,发送端根据是否丢包判断网络中是否发生了拥塞,没有发现丢包时,发送端每个RTT把发送窗口调大一个MSS继续探测网络的容量,当网络中出现了一定数量的重复确认报文(dup ack)时认为网络发生了拥塞,并将发送窗口减半,继续探测,而当出现RTO时,认为网络状况更加糟糕,直接把发送窗口打回两个MSS。
TCP-Cubic
Cubic衍生于Bic算法,Bic觉得Reno那样线性探测带宽上限的做法过慢,无论是每个RTT增长一个MSS,还是每个RTT增长多个MSS,都无法改变算法O(n)的本质,Reno探测到带宽上限的时间正比于BDP,带宽利用率低。BIC认为上一次发生拥塞时的发送窗口大小是一个非常有价值的信息,应当充分利用,短时间来看,网络带宽不会出现较大变化,上一次拥塞时的窗口值很有可能是带宽的上限,因此Bic要做的就是在当前窗口和上次拥塞时的窗口之间进行搜索,来找到合适的窗口值,既然是搜索,那么为什么不用最简单,最可靠的二分查找呢,把下一个RTT的窗口值 Cwnd_next 设置为当前窗口值和拥塞点窗口值和的一半,如果下一个RTT发生了拥塞则需要在 Cwnd_next 和 Cwnd_now之间进行查找,否则在Cwnd_next 和 Cwnd_high之间进行查找,Bit将查找带宽上限的速度大大提高了。Bic有一个缺陷,它每进行一次二分查找,需要一个RTT的时间,因此不同RTT数据流查找的频率不一样,也就是说RTT小的流更容易获得较高的带宽。Cubic对Bic进行了更深层次的建模,从(时间,窗口)图,如图2上来看,Bic算法的形状就是一个三次曲线, 因此Cubic用形如 a(t - t0)^3 的三次函数来模拟,其中参数 a 控制了算法的激进程度,a越大算法越容易抢占带宽,这样算法的激进程度就与RTT解耦了。在我看来,Bic和Cubic是非常不错的算法,它们算是把网络问题转化为了数学问题,如果只用丢包作为链路拥塞拥塞的依据,真的很难想得出还有什么更好的策略了。
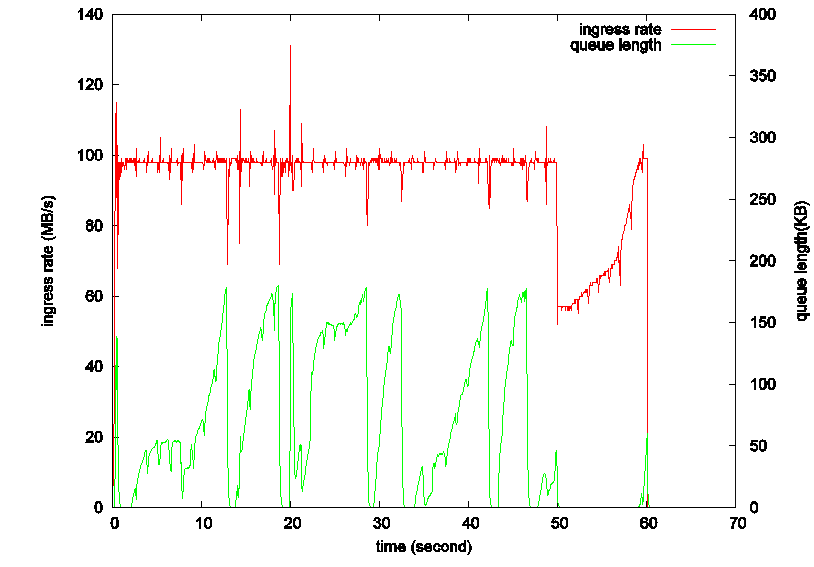
图4 Cubic占据空闲带宽速度
TCP-Vegas
前面介绍到,当发送端的吞吐率达到瓶颈带宽后,吞吐率不会再随着发送窗口的增大而增大了,Vegas算法就是利用这一特征来判断当前网络是否处于拥塞状态。Vegas会维护一个当前链路的最小时延BaseRTT,这个就是信号从发送端到达接收端的时延,没有排队时延(当然,如果在Vegas的整个生命周期内,路由器始终处于拥塞状态,Vegas是分辨不出来的,此时最小时延也会有排队时延),然后它的行为也就和Reno一样了。首先在没有拥塞时吞吐率等于发送窗口除以RTT,即 expected throughput = cwnd / rtt,Vegas根据ACK报文估算当前实际的吞吐率 actual throughput,如果两者相等,那么网络上应该没有拥塞,此时就和Reno一样线性增长发送窗口进行探测,而如果实际吞吐率低于根据窗口估计的吞吐率,则网络发生了拥塞,此时减小发送窗口。Vegas的终极目标是维持估计吞吐率和实际吞吐率基本相等,在两者相等时,Vegas不再调整发送窗口,保持一个相对平稳的发送速率。但由于实际网络中存在突发流量,很难绝对相等,于是Vegas设置了一个下限alpha,和一个上线beta,在此区间内,就认为网络达到了最佳平衡点,路由器既没有缓存大量报文造成排队时延,又保证了有少量报文存在缓冲区中等待转发。
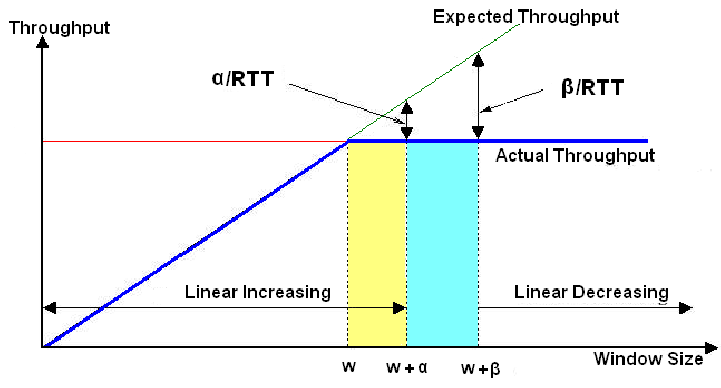
图5 TCP-Vegas
TCP Westwood
Westwood也算是基于时延的吧,它没把时延用在判断是否发生了拥塞上,而是用在了拥塞后,慢启动阈值的设定上。在传统拥塞控制模式下,发送窗口小于慢启动阈值时,发送窗口会指数式地增长,而当发送窗口达到慢启动阈值时,发送窗口将采用一个更低阶的探测方式,因此,慢启动阈值也可以说是拥塞控制算法对带宽的一个保守估计值,即最终拥塞窗口大概率会大于慢启动阈值。在发生拥塞时,拥塞控制算法一般会把发送窗口减半然后再慢慢向上探测来寻找合适的带宽,当发送窗口小于慢启动阈值时,窗口可以在很短的时间内增长至慢启动阈值然后再采用较慢的搜索方式,因此设置一个合适的慢启动阈值能够大大提高拥塞后探测到新的带宽的速度。Westwood就根据测量得到的吞吐率乘以最小RTT得到一个BDP,理论上来说,发送窗口在该BDP以下基本是安全的,于是Westwood也就把慢启动阈值设置到该BDP来快速跳过安全阶段,进入后期较危险的线性探测阶段。比如下面这个Westwood的窗口变化图,拥塞时,窗口总会被过度地减小,Westwood能将窗口迅速拉升至一个较为合理的值然后再去探测。
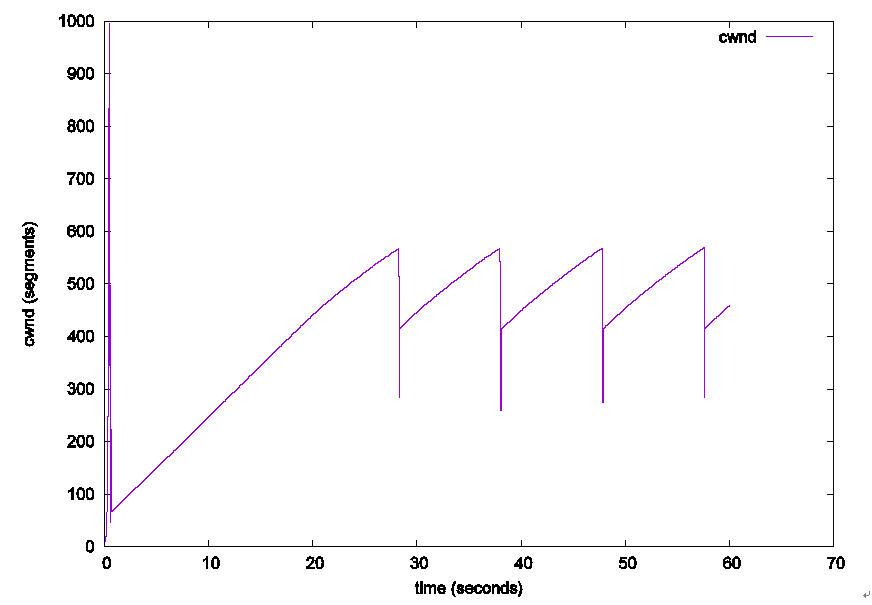
图6 TCP-Westwoord窗口变化
TCP-BBR
BBR,要求使用Pacing,完全摒弃丢包,高吞吐,低时延,说是革新一点都不为过,也许只有Google有能力在Linux内核上做出这么大的改动。本来Vegas已经是拥塞控制本该的样子,但目前网络却不是它该有的样子,且不说各种加速,单是基于丢包类的算法都能够把Vegas活活饿死。这也是BBR算法最有意思的地方,BBR并不是在感受到拥塞的第一时间就降低发送速率,它选择了一种相对保守的做法,也就是等等看,如果一段时间(10秒一次的最低时延探测)后,网络还是拥塞,那可能真的是自己占的带宽太大了,这才降低发送速率,而在期间它的目标是维持在一个相对稳定的吞吐率,注意这里是吞吐率而不是发送窗口,其它数据流增大发送窗口造成网络拥塞加剧,从而导致时延上升,而BBR则根据目标吞吐率和时延的乘积得到新的发送窗口也会增大,因此保障了和其它算法之间的竞争力。然而,基于时延的拥塞控制总是不那么稳定,而且它还存在一个问题,还记得它每隔10秒的一个时延探测周期吗,如果在它降低速率来探测时延的一刹那,有其它流量抢占了它让出的带宽并形成了一定长度的队列,从而导致它测得的时延并不是最低时延,那么TCP-BBR是不会感受到这部分队列的,也就造成队列一直在路由器内无法排出,就像图8那样,在20秒(恰好是BBR时延探测阶段)处加入UDP数据流,造成了路由器持续的队列,这也与BBR算法的初衷不符。当然对于用户来说,把服务器的拥塞控制算法切换到BBR还是能够很大程度提升性能的,尤其是在高时延,高丢包的网络下,BBR相较于Cubic还是要好很多的。
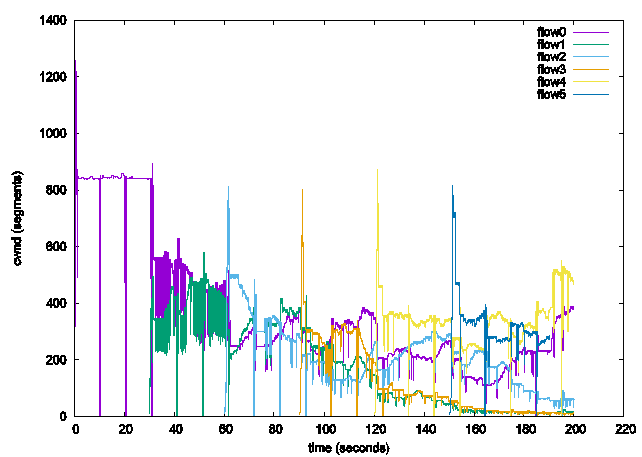
图7 TCP-BBR多条数据流竞争
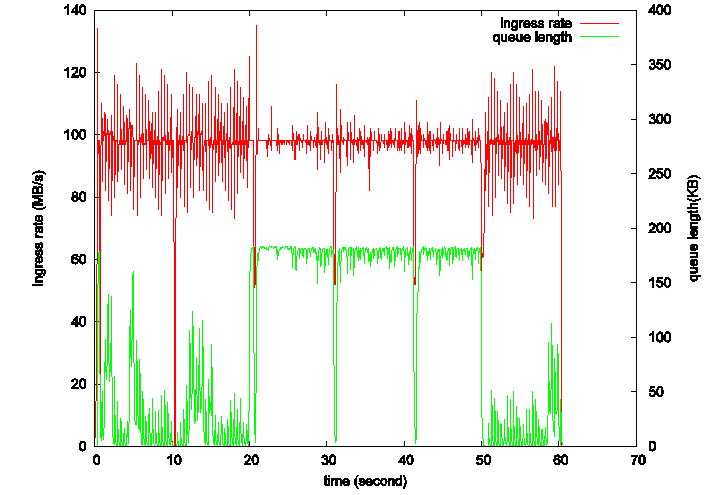
图8 UDP数据流不小心在TCP-BBR时延探测期插入
RCP
大概在2000年到2010年之间,关于显式拥塞控制的研究达到了高潮,ECN,XCP,RCP等等,显式拥塞控制的核心问题是如何让路由器主动反馈信息,反馈什么样的信息以及怎样利用这些信息,在这几点上RCP都可以说把拥塞控制分析的明明白白。RCP(Rate-Control-Protocol)从名字上就可以看出它的目标就是直接控制发送速率,不再像之前拥塞控制算法那样通过窗口去探测合适的速率,RCP路由器会通过Piggy-Back的方式直接告诉端主机一个合适的发送速率,端主机直接按照该速率发送就可以了,这样做至少带来了以下两点好处:
1. 显式拥塞控制该有的优点它都有,包括对随机丢包的免疫,链路利用率高,时延可控等
2. 收敛速度快,相比于一般拥塞控制算法收敛到公平带宽和收敛到高的链路利用率耗时,RCP可以说是指数级的提升了
RCP的基本原理就是把带宽平均分配到每条数据流,也就是 R = C / N , C为带宽, N为经过路由器的数据流数量,C是路由器知道的, N是一个比较难获得的值,常见的有一些算法可以根据5元组估算流的数量,但不适合在拥塞控制算法上用,解包到TCP层对路由器来说开销太大,RCP使用了一个迭代的过程,当前带宽有剩余时,证明对N的估计偏大,则将剩余带宽平均分配给N条流,当拥塞时,证明对N的估计偏小,实际网络可能有更多数据流,则将拥塞平均分配到N条流,减小每条流的发送速率,通过迭代最终N会收敛到经过路由器的数据流数量,这个收敛过程要比Cubic之类的慢慢爬升然后回退的探测过程要快的多。
DCTCP
微软在2010年左右提出的DCTCP是ECN最成功的应用之一,一直以来ECN只被应用于判断链路丢包是否是网络拥塞造成的丢包,也就是返回一个True或者False,并不能提供任何关于链路拥塞程度的信息。ECN协议规定协议栈在接收到带有CE标记的报文后,便会一直向对端发送带有ECE标记的报文,直到对端返回一个CWR报文,也就是说在收到CE报文后,不管下一个报文有没有被路由器标记为拥塞报文,接收端都会向对端通告链路发生了拥塞,因此,发送端收到ECE报文后,只能确定链路在这一段时间内发生了拥塞,并不能确定自己所发的报文里有多少个被标记为了拥塞。微软对协议栈做了一点点修改,接收端在收到CE报文后,按照下图的状态机向对端发送ECE报文,这样对端便可以推算出自己所发的报文中有多少个造成了拥塞,也就是当前网络的拥塞程度,并按这个程度减小当前的发送窗口,从而避免了窗口被过度减小。我曾经也对DCTCP进行过试验,结果简直完美。。。绿色的线是路由器上的队列长度,红色的线是吞吐率,DCTCP基本能够将路由器的缓冲队列长度控制在一条直线上,当然通过设置阈值,可以将这个队列长度向上或向下平移,也就是说DCTCP可以始终保持路由器的各个端口处于满负载,但又不是拥塞的状态下。DCTCP也是让我第一次认识到拥塞控制其实最重要的是控制好路由器端的队列长度。
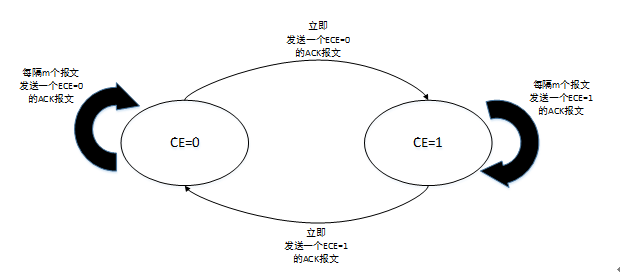
图9 DCTCP接收端对CE标记的处理与状态切换
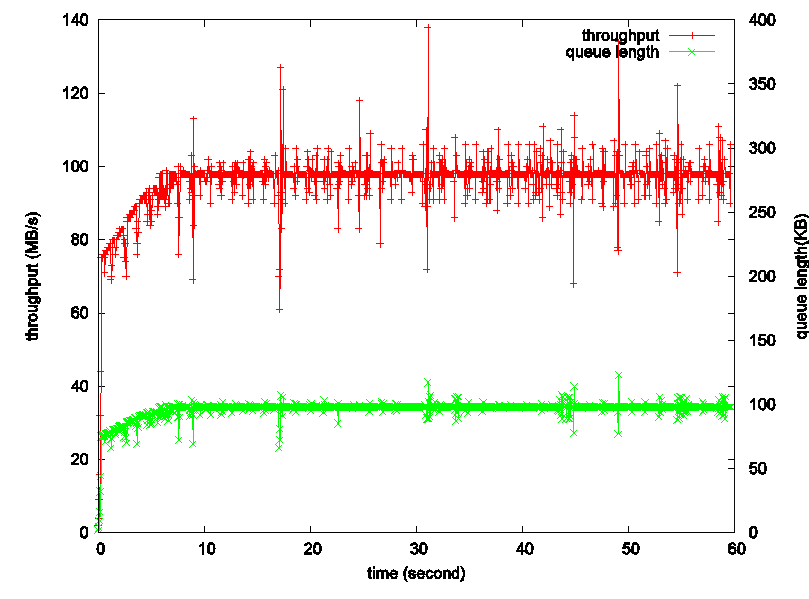
图10 DCTCP路由器端缓存变化(漂亮><)
当然,它也不是毫无缺陷,当发生丢包时,窗口减小的幅度能够对多条数据流收敛到公平带宽的速度造成影响的,由于DCTCP在丢包时那么精确地减小发送窗口,它的公平性收敛速度会较Cubic要慢一些,就是下面的这个样子,当然适当调调参数会好很多。
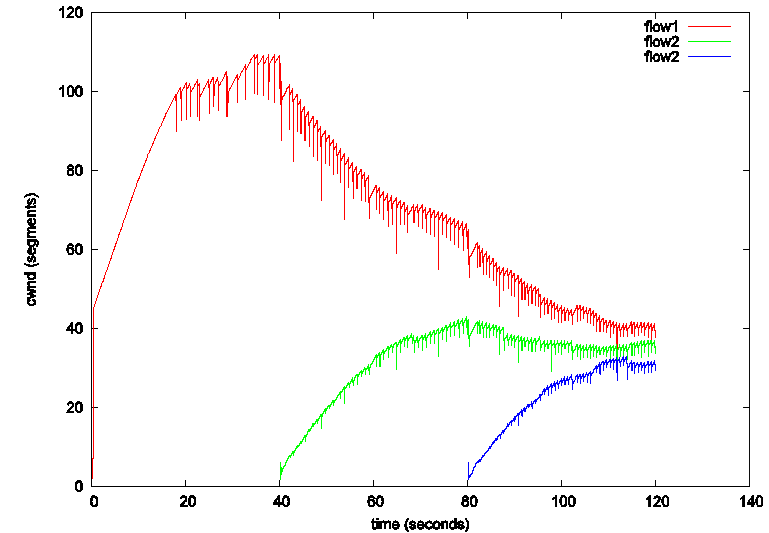
图10 DCTCP相对较慢的公平性收敛
0x05 总结
拥塞控制可能真的没有太多研究的空间了,虽然Google的大神们隔三差五还能搞出个RFC来,基于纯粹基于丢包类的算法,Cubic似乎已经足够好了,探测速度也够快了,但丢包本身就不可靠,这个问题是通过改进探测模型没法解决的问题,基于网络测量类倒是还有很多可以研究的地方,稳定性,可靠性还是有很大提升空间的,像Compound TCP之类的融合丢包和时延的算法还是很有意思的。拥塞控制搞到后面,要低时延还是要高链路利用率,要公平性还是要连利用率之类的平衡性考量了, No Silver Bullet。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号