javaIO——BufferedReader
今天来学习一下 java.io.BufferedReader ,从命名可以看出,跟前面学习的 StringReader 和 CharArrayReader 有些不一样,这些都是按照数据源类型命名,BufferedReader 显然不是。BufferedReader 字面意思即是“缓冲读取器”,所以它肯定是对其它读取器进行一个包装,然后提供缓冲的功能。看一下注释:Reads text from a character-input stream, buffering characters so as to provide for the efficient reading of characters, arrays, and lines. 从一个字符输入流读取文本,通过缓冲字符从而提供对字符、数组和行的高效读取。
1. 关键字段

上图红框中为 BufferedReader 的关键字段:
1.1. in 是它包装的真正提供数据输入的读取器;
1.2. cb[] 是缓冲区,可以在构造方法中指定缓冲区大小,不指定即使用默认值 private static int defaultCharBufferSize = 8192; ;
1.3. nChars 是缓冲区当前的有效的长度(假如 cb.length = 1024,nChars=128,就表示当前缓冲了 128 个字符,128~1023 的索引位置没有意义);
1.4. nextChar 表示缓冲区中尚未被读取的字符的开始位置(如上例, 假如 nextChar=90,表示缓冲区当前有 128 个字符,但是 0~89 索引位的字符已经被读取过了,也就是失效了);
2. 核心方法
2.1. fill() ,填充缓冲区:


/**
* Fills the input buffer, taking the mark into account if it is valid.
*/
private void fill() throws IOException {
int dst;
if (markedChar <= UNMARKED) {
/* No mark */
dst = 0;
} else {
/* Marked */
int delta = nextChar - markedChar;
if (delta >= readAheadLimit) {
/* Gone past read-ahead limit: Invalidate mark */
markedChar = INVALIDATED;
readAheadLimit = 0;
dst = 0;
} else {
if (readAheadLimit <= cb.length) {
/* Shuffle in the current buffer */
System.arraycopy(cb, markedChar, cb, 0, delta);
markedChar = 0;
dst = delta;
} else {
/* Reallocate buffer to accommodate read-ahead limit */
char ncb[] = new char[readAheadLimit];
System.arraycopy(cb, markedChar, ncb, 0, delta);
cb = ncb;
markedChar = 0;
dst = delta;
}
nextChar = nChars = delta;
}
}
int n;
do {
n = in.read(cb, dst, cb.length - dst);
} while (n == 0);
if (n > 0) {
nChars = dst + n;
nextChar = dst;
}
}
上述方法中,前面一部分都是计算本次填充应该从缓冲区的什么位置开始(牵涉到流的标记什么的,这个暂时没有深究)。关键部分是这几行:

2.2. read() 和 read(char cbuf[], int off, int len) ,提供给外部调用的读取方法:
前面说了,BufferedReader 只是一个包装类,所以它应该将被包装对象的功能提供,所以 read 方法必不可少。
read() ,读取单个字符的方法:

read(char cbuf[], int off, int len) ,读取多个字符的方法:

可以看到,这个方法并没有调用 fill(),而是调用 read1 方法,那我们再来看看 read1 方法:
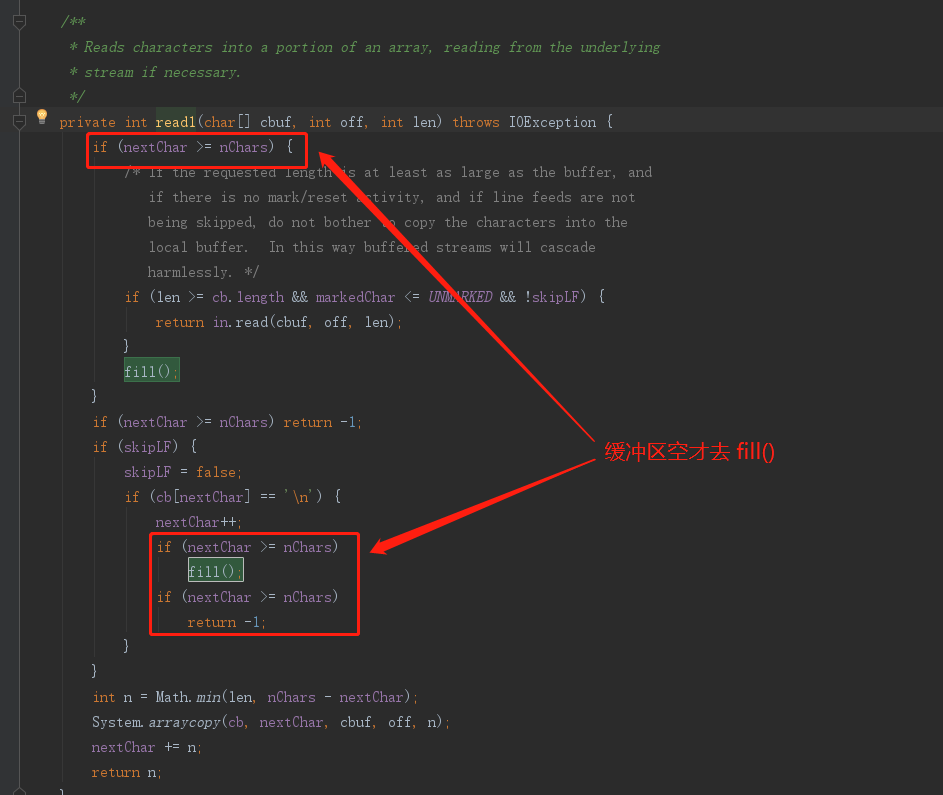
可以看出,只有当缓冲区为空了,才会尝试去填充缓冲区,这也就解答了前面提问“为什么可以直接将有效位置置为本次填充开始位置”
3. 总结:
3.1. 只有当缓冲区为空时,才会调用 fill() 方法,从真正的数据流中读取数据填充到缓冲区;
3.2. 每次填充缓冲区,都尝试将缓冲区填满(但不保证填满,这取决于 被包装流的 read 实现);
3.3. 填充缓冲区时,会阻塞直至读取到有效数据至缓冲区(想想如果不阻塞,也没有意义,因为根据 3.1,没有读到有效数据返回也是徒然);
3.4. 对于多字符读取方法,会阻塞直至读取到参数指定长度的内容,或者流结束;
【附】实践篇:
BufferedReader 效率测试实践:https://www.cnblogs.com/coding-one/p/11369976.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号