[Java核心技术]第九章-集合(映射-HashMap&TreeMap)
HashMap
基本操作
HashMap<Integer,Integer> firstAccurMap=new HashMap<Integer,Integer>();
firstAccurMap.put(0, -1);
firstAccurMap.containsKey(sum-k);
int begPos=firstAccurMap.get(sum-k);
HashMap底层实现
- 在JDK1.6,JDK1.7中,HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。
- 而JDK1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
散列表
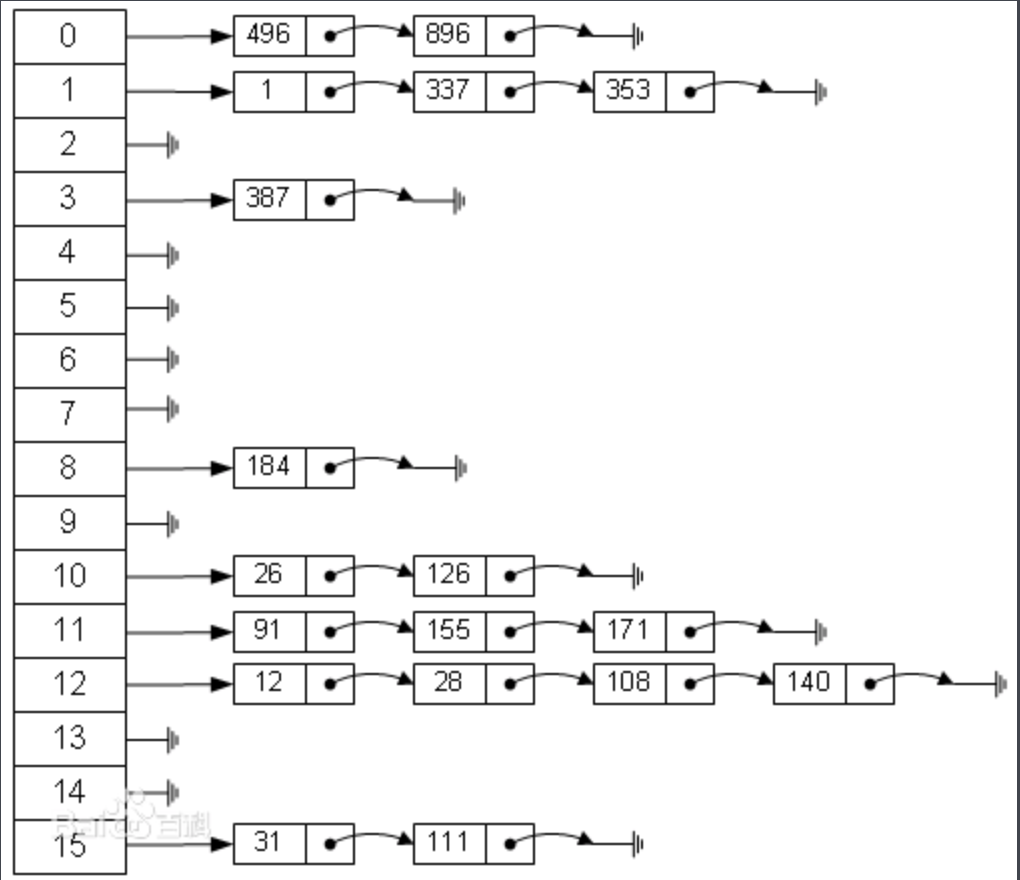
定义
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问>记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)>为哈希(Hash) 函数。
解决冲突的方法
拉链法是其中之一。
查找时间复杂度
- O(1),设计Hash函数时目标是减少冲突,使链表的长度尽量短。
散列表的查找过程基本上和造表过程相同。一些关键码可通过散列函数转换的地址直接找到,另一些关键码在散列函数得到的地址上产生了冲突,需要按>处理冲突的方法进行查找。在介绍的三种处理冲突的方法中,产生冲突后的查找仍然是给定值与关键码进行比较的过程。所以,对散列表查找效率的量度,依然用平均查找长度来衡量。
查找过程中,关键码的比较次数,取决于产生冲突的多少,产生的冲突少,查找效率就高,产生的冲突多,查找效率就低。因此,影响产生冲突多少的因素,也就是影响查找效率的因素。影响产生冲突多少有以下三个因素:
1 散列函数是否均匀;
2 处理冲突的方法;
3 散列表的装填因子。
TreeMap
TreeMap底层是红黑树。
posted on 2019-06-02 19:39 coding_gaga 阅读(163) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号