
HashMap详解
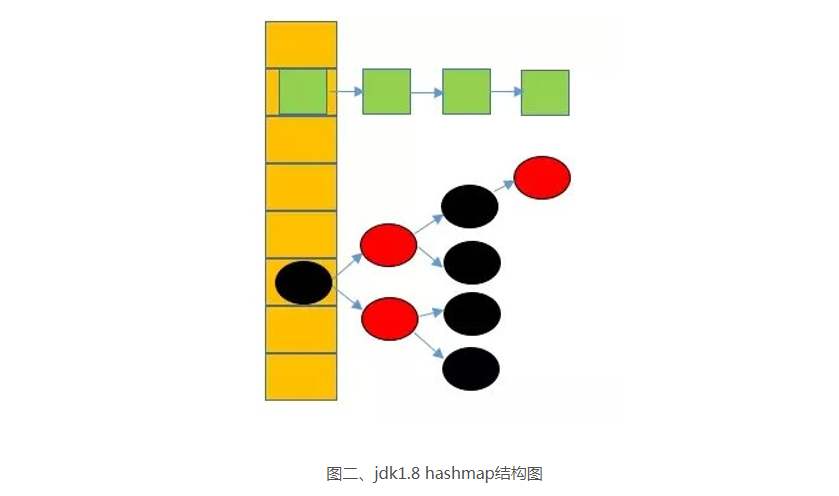
HashMap底层数据结构?
-
底层:数组+链表 大概结构如图:

-
能说得再详细一点吗?
1.在jdk1.7中,HashMap的主干由一个一个的Entry数组组成,源码:
/** * An empty table instance to share when the table is not inflated. */ static final Entry<?,?>[] EMPTY_TABLE = {}; /** * The table, resized as necessary. Length MUST Always be a power of two. */ transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash; /** * Creates new entry. */ Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } ...... //后面的省略 }2.jdk1.8中,HashMap主干由名叫Node的数组组成,源码:
transient Node<K,V>[] table;static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } .... //略 }以及一些其他的默认属性:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认数组长度2^4=16 static final int MAXIMUM_CAPACITY = 1 << 30; // 最大数组容量2^30 static final float DEFAULT_LOAD_FACTOR = 0.75f; // 默认负载因子 static final int TREEIFY_THRESHOLD = 8; // 链表转红黑树的阈值 static final int UNTREEIFY_THRESHOLD = 6; // 扩容时红黑树转链表的阈值
说说put方法的具体?
-
put的实现原理
在每次put数据的时候,会调用HashMap的hashCode计算key的hash值,然后执行:
n = tab.length //n就是数组的长度 index = (n - 1) & hash计算出的index,就是HashMap数组的下标索引,然后添加进去,但是在添加的的时候还会做检查:
1.检查到这个位置没有数据,则直接添加。
2.检查到这个位置有数据,则还需要再做一次判断:
(1)调用equals方法判断这两个key是不是一样:
如果是同一个key,那么就对之前的value进行覆盖,如果不同,则添加在后面,这样就会形成链表。(这是jdk1.8以后的尾插法,之前都是在头部插入,有什么区别呢?后续~~),
注:可能会有小伙伴会有疑问,为什么两个不同的key值会计算出相同的索引??
这就是所谓的hash冲突,即便内容不同,但是很有可能计算出来的hashCode值一样。
jdk1.7和jdk1.8put的区别是什么?
-
jdk1.7中使用的是 “头部插入法”,即当有新的元素加入到链表中的时候,是加在链表头部。然而,从jdk1.8以后,都修改了,执行“尾部插入法”,即插在链表的末尾。
-
为什么要把“头部插入法”修改为“尾部插入法”呢?
也许有点小伙伴会觉得,这也没啥讲究的,可能人家心情不好就随手给改了~~~~然鹅,这里面大有文章!!!!
我们知道,HashMap是会动态扩容的,扩容的影响因素有两个:
- Capacity:HashMap当前长度。
- LoadFactor:负载因子,默认值0.75f。
- 官方源码说明:
The next size value at which to resize (capacity * load factor).如果不指定长度,一开始的capacity默认值是16(为什么是16呢?后续),当添加了:
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); //即阈值 = 16*0.75=12当添加了12个数据,在添加第13个的时候,就会进行扩容,而且扩容为原来的两倍!!(扩容细节后续~~~)
-
这个扩容和尾插法有什么关系呢??
举个例子,现在往一个容量大小为2的HashMap中put两个值,负载因子是0.75,则在put第二个的时候就会进行resize!
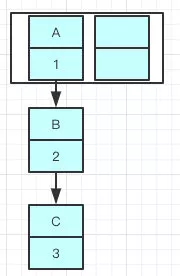
现在我们用
多个线程插入三个键值对:A = 1 ,B = 2,C = 3 ;如果我们在 resize 执行之前打一个断点,这样就会出现数据已经添加了但是还没来得及扩容,此时 A 是指向 B 的:
![扩容前]()
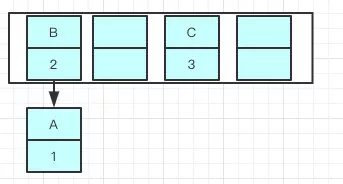
而resize的机制是,使用
单链表的头插入方法,同一位置上的新元素总会被放到链表的头部,而在扩容之前数组中同一条Entry链上的元素,会被重新计算,然后放到不同的位置上,如果这时候刚好把 B 放到了A原来的位置,如图:![]()
此时的情况是,B 居然指向了 A ???还记得没有扩容之前吗?是 A 指向 B !!
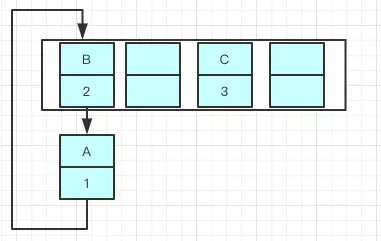
由于是多线程同时操作,当所有线程都执行完毕以后,就可能会出现这样的情况:
![]()
此时居然出现了环状的链表结构,如果这个时候去取值,就会出错——InfiniteLoop(死循环)。
-
结论:
使用头插会改变链表的上的顺序,但是如果使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
Java7在多线程操作HashMap时可能引起死循环,原因是扩容转移后前后链表顺序倒置,在转移过程中修改了原来链表中节点的引用关系。
Java8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系。
说说resize时,扩容是怎么实现的?
(1)扩容:新建一个Entry空数组,长度是原来的两倍。
(2)ReHash :遍历原来的Entry数组,把所有的数据重新Hash到新的数组。
-
为什么要重新Hash呢,直接复制过去不是更快捷方便吗?
因为扩容以后的数组长度变了,
index = HashCode(Key) & (Length - 1),扩容后的length和之前不一样了,之前是16,现在是32,重新Hash算出来的index值肯定也不一样,而且重新计算后,会使元素更加均匀的分布在HashMap表中,如果直接复制的话,那么数据肯定都堆在一起了。
为什么HashMap初始化时默认容量是16?为什么要是2的n次幂?
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 ,
有几方面的原因:
-
根据上述官方的定义可知,16 = 2^4,也就是提醒我们这个数最好设置为 2 的N次幂。
-
在计算index的时候:
index = (n - 1) & hash,n就是数组的长度,这里就是16,而16-1 = 15 ,15的二进制数为:1111,假设hash值为:01011101100011,则:
01011101100011 & 1111 --------------------- index: 0011可以看出,15的二进制全都是1,假设默认值是8,则8-1=7 ,7的二进制是 111,再假设默认值是32,
32-1 = 31 ,31的二进制 11111。可以发现这样的规律,所有2的n次幂的数减一的二进制所有位都是1。
这样一来,在计算index的时候,就只和hashCode的最后几位有关,这样可以极大的提高效率。
而至于为什么非要用 16 而不用8或者32,官方也没有具体说明,所以这个应该只是一个经验数字,除了他满足是2的幂以外,不大也不小,刚好合适,能满足日常大部分需求。
-
index计算的时候,为什么要用位运算
&呢?主要是效率问题,位运算(&)效率要比代替取模运算(%)高很多,主要原因是位运算直接对内存数据进行操作,不需要转成十进制,因此处理速度非常快。在jdk1.8之前的index计算就是用的取模运算:
%.
为什么加载因子是0.75f?
加载因子太大的话,也就是说需要尽可能的把HashMap表填满了才进行扩容,那这样会使得hash冲突的 概率增大,但是如果加载因子太小,那只用了很小一部分空间就要开始扩容,使得空间利用率很低。那怎 么办平衡hash碰撞和空间利用率这个问题,这就是问题的关键!!
根据官方源码的注释可以看到:
threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
* factorial(k)). The first values are:
*
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million
大概意思就是说,在理想情况下,使用随机哈希码,节点出现的频率在hash桶中遵循泊松分布,同时给出了桶中元素个数和概率的对照表。从上面的表中可以看到当桶中元素到达8个的时候,概率已经变得非常小,也就是说用0.75作为加载因子,每个碰撞位置的链表长度超过8个的概率达到了一百万分之一。
即加载因子为0.75,同一个桶中出现8个元素然后转化为红黑树的概率为100万分之一。
HashMap的主要构造器都有哪些?
- HashMap():构建一个初始容量为 16,负载因子为 0.75 的 HashMap
- HashMap(int initialCapacity):构建一个初始容量为 initialCapacity,负载因子为 0.75 的 HashMap
- HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的负载因子创建一个 HashMap。
HashMap的主要属性参数:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认数组长度2^4=16
static final int MAXIMUM_CAPACITY = 1 << 30; // 最大数组容量2^30
static final float DEFAULT_LOAD_FACTOR = 0.75f; // 默认负载因子
static final int TREEIFY_THRESHOLD = 8; // 链表转红黑树的阈值
static final int UNTREEIFY_THRESHOLD = 6; // 扩容时红黑树转链表的阈值
最后:
限于笔者水平有限,难免有些不足或错漏之处,欢迎各位大佬批评指出,不胜感激~~
个人网站:https://www.coding-makes-me-happy.top/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号