
HBase
HBase
Hbase是一个基于HDFS的高可靠、高性能、面向列的分布式数据库,源于Google的BigTable论文。HDFS基于流式数据访问,低时间延迟的数据访问不适用于在HDFS上运行。所以,如果需要实时地随机访问超大规模数据集,使用HBase是更好的选择。

HBase是数据库,但并不像传统的Oracle、MySql等关系型数据库。这些关系型数据库也不是为了可扩展的分布式处理而设计的。得益于与Hadoop的整合,给HBase带来了更广阔的发展空间。
-
关系型数据库
表userid username age email 1 zhangsan 20 zhangsan@163.com 2 lisi 22 lisi@163.com 3 wangwu 32 wangwu@163.com 如果一张表的列过多,会影响查询效率,我们将这样的表称为宽表。那么应该如何优化呢? 表User_basic id username 1 zhangsan 2 lisi 3 wangwu 表 User_info id age email 1 zhangsan@163.com 2 22 lisi@163.com 3 32 wangwu@163.com 使用垂直拆分的方法提高效率
| id | username | age | |
|---|---|---|---|
| 1 | zhangsan | 20 | zhangsan@163.com |
| 2 | lisi | 22 | lisi@163.com |
| 3 | wangwu | 32 | wangwu@163.com |
| ... | ... | ... | ... |
| ... | ... | ... | ... |
| 如果一张表的行过多,会影响查询效率,我们将这样的表称为高表,应该如何优化呢? |
| id | username | age | |
|---|---|---|---|
| 1 | zhangsan | 20 | zhangsan@163.com |
| 2 | lisi | 22 | lisi@163.com |
| 3 | wangwu | 32 | wangwu@163.com |
| 4 | ... | ... | ... |
| id | username | age | |
|---|---|---|---|
| 5 | xx | xx | yy@163.com |
| 6 | xx | xx | yy@163.com |
| 7 | xx | xx | yy@163.com |
| ... | ... | ... | ... |
| ... | ... | ... | ... |
可以使用水平拆分的方式提高效率
动态列
| id | username | age | phone | wexin | |
|---|---|---|---|---|---|
| 1 | zhangsan | 20 | zhangsan@163.com | 133 | |
| 2 | lisi | 22 | lisi@163.com | 188 | |
| 3 | wangwu | 32 | wangwu@163.com | weixin123 | |
| 可以处理成这样 |
| id | username | age | dc | |
|---|---|---|---|---|
| 1 | zhangsan | 20 | zhangsan@163.com | |
| 2 | lisi | 22 | lisi@163.com | |
| 3 | wangwu | 32 | wangwu@163.com | |
尽管我们有多种多样的方法可以将表进行优化,但是数据库的总容量还是限制了类似mysql这样的数据库在大数据中的应用
- 特点
- 海量存储:适合存储PB级别的海量数据,在PB级别的数据下能在几十到几百毫秒内返回数据。
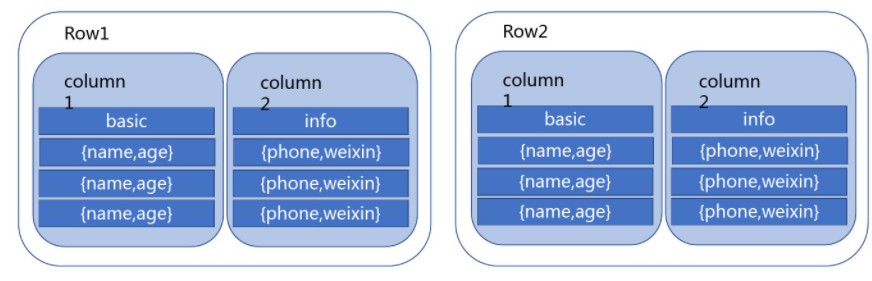
- 列示存储:即列族存储,HBase是根据列族(column family)来存储数据的。列祖下面可以有非常多的列,列祖在创建表的时候就必须指定。
- 极易扩展:通过横向添加RegionServer的机器,进行水平扩展,提升HBase的上层处理能力。
- 稀疏:HBase的列具备相当的灵活性。在列族中可以指定任意多的列,在列数据为空的情况下不占用存储空间。
体系架构
- 体系结构
HBase同样是采用Master/Slaves的主从服务器结构,它由一个HMaster服务器和多个HRegionServer服务器构成,而所有服务器都是通过ZooKeeper协调并处理各服务器运行期间可能遇到的错误。HMaster负责管理所有的HRegionServer,各HRegionServer负责存储许多HRegion,每一个HRegion是对HBase逻辑表的分块。

-
架构
-
HMaster:每台HRegionServer都会和HMaster服务器通信。HMaster的主要任务就是告诉每个HRegionServer它要维护哪些HRegion
HBase中可以启动多个HMaster,通过ZooKeeper的Master选举机制来保证系统中总有一个Master在运行。
功能:
- 管理用户对表的增、删、改、查操作
- 管理HRegionServer的负载均衡,调整HRegion分布
- 在HRegion分裂后,负责新的HRegion的分配
- 在HRegionServer停机后,负责失效HRegionServer上的HRegion迁移
-
HRegion:HBase表的分片,HBase会根据Rowkey值被切分为不同的Region存储在RegionServer中
-
HRegionServer:HRegionServer直接对接用户的读写请求
-
HLog:用于存储数据日志,实质是HDFS的Sequence File
-
Client:包含了访问HBase的接口,另外Client还维护了对应的cache来加速HBase的访问
-
ZooKeeper:master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护工作
-
Store:Hfile存储在Store上,一个Store对应表中的一个列族
-
MemStore:内存存储,位于内存中,用来保存当前的数据操作
-
-
数据模型
- 表(Table):一个稀疏表(不存储值为null的数据),表的索引是行关键字、列关键字和时间戳。
- 行关键字(Row Key):行的主键、唯一标识一行数据,也称行键
- 列族(Column Family):行中的列被分为“列族”,同一个列族的所有成员具有相同的列祖前缀。
- 列关键字(Column Key):也称列键。格式为<family>:<qualifier>family为列族名,quealifier为列族修饰符
- 时间戳(TimeStamp):插入单元格的时间,默认作为单元格的版本号
- 单元格(Cell):一个单元格保存一个值。要定位一个单元格要使用“行键+列键+时间戳”3个要素
- MemStore:内存存储,位于内存中,用来保存当前的数据操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号