
数据产品-数据埋点
想要做数据,首先得有数据。对于数据分析来说,数据分析之始在于数据之源。
数据的来源通常分为:
1.内部数据:web日志,用户行为数据,业务数据,遗留系统数据....
2.外部数据:调研,爬虫,导入数据,同行内部数据....
起初公司数据埋点这块是用的百度移动统计。但是不能结合电商的业务数据,各个路径转化率获取不到,只有一些流量数据,拿不到一些交易金额,转化率的数据。我们根本不知道用户是如何的一种状态,用户行为和特征全靠经验。更别说一些留存分析,用户来源质量分析,各个转化率如何,以及用户再APP上的各种行为监测。这不满足我们的数据驱动业务的做法。
1.埋点如何埋?怎么采集?
首先埋点方案的选型很重要,这关系着日后的埋点质量问题。从是否开源,SDK是否支持H5、安卓、IOS。部署方式是私有化,还是saas化(考虑到公司的数据还是比较重要的数据,出于安全考虑,需要本地化部署)这几个方面入手决定用神策开源埋点SDK。这样节省了大部分的工作量,SDK一旦部署基础信息比如(时间、地点、浏览器、硬件设备)都会自动化的采集。最后我们选取了神策数据这家第三方服务商
发一张调研的埋点方案各竞品公司对比图
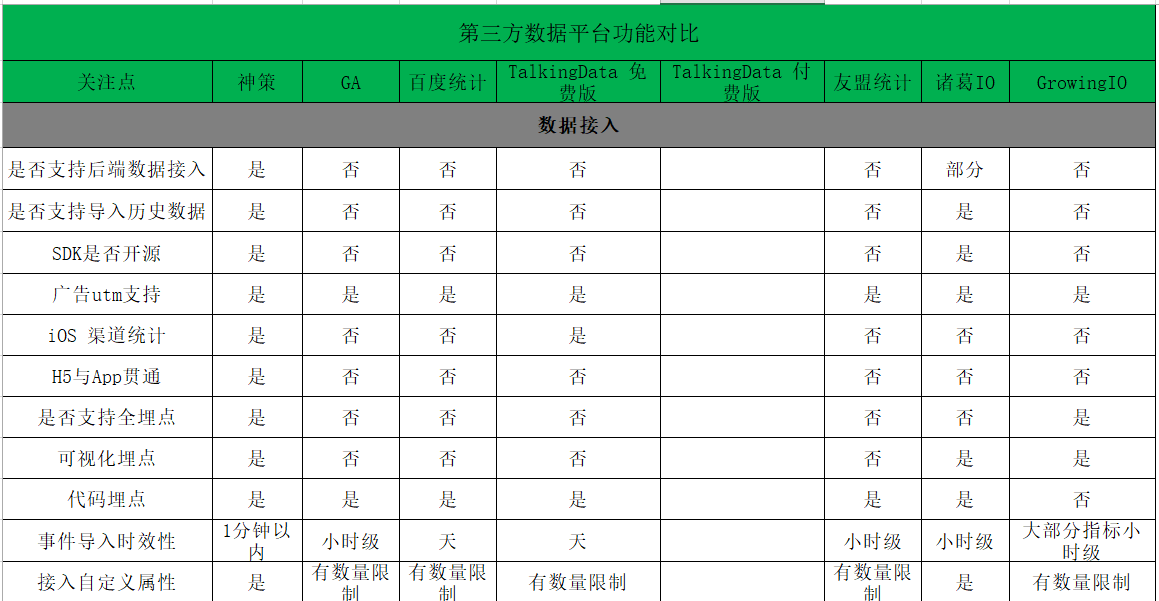
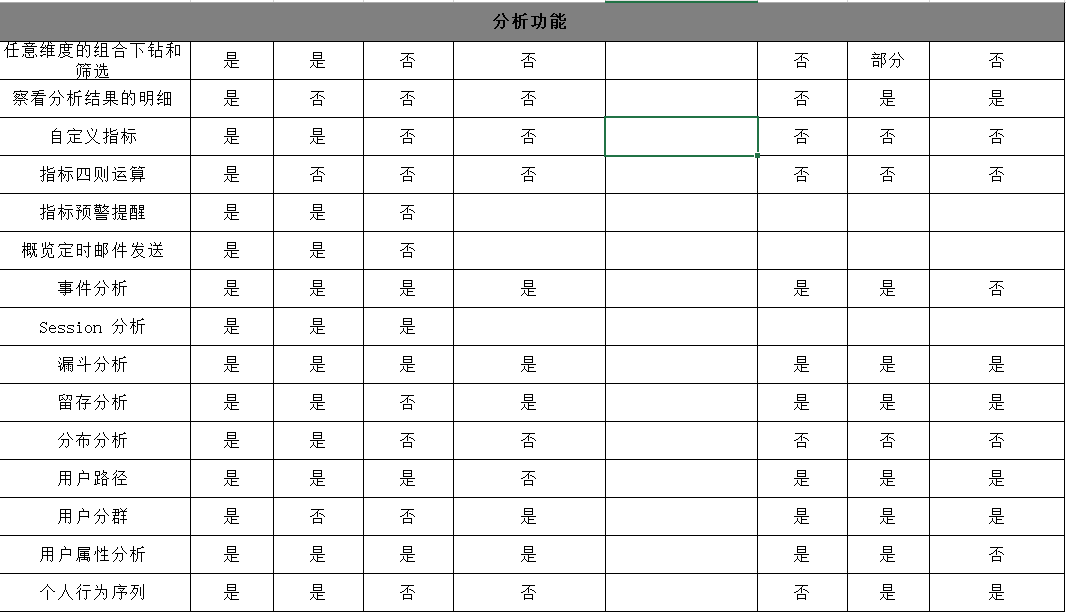
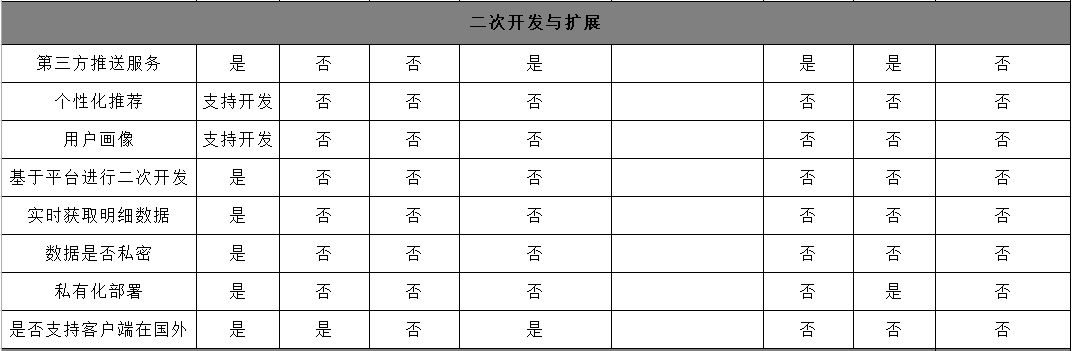
竞品分析总结完毕后,进入正题。
================================================================分割线
通常采集的信息分为:
1.基础信息采集
2.浏览页面采集
3.触点事件采集
数据埋点的形式多种多样,但数据埋点的原理都是相同的。很多时候我们在观察和分析一个埋点的时候,首先要了解这个埋点信息是采用的什么数据埋点方案,不然我们会因为信息不足导致无法判断,如下是一个埋点案例数据:
数据埋点形式和参数说明:
[{
//配置信息
"user_id":"123", //埋点负责人的账号id
"business":"xx业务", //埋点数据的业务分类
"label":"标签属性",//对埋点数据进行分类,对每个分类打标签
//环境信息
"uid":"123", //用户唯一ID,只要访问就生成一个新的身份标示
"user_id":"123", //用户的账户ID,仅登录用户可获取得到
"name":"joker",//用户的账户名称,仅登录用户可获取得到
"city_id":"2",//如果用户访问的页面有城市属性,这里可以获取页面的城市属性id
"city_name":"上海",//如果用户访问的页面有城市属性,这里可以获取页面的城市属性值
"locate_city_id":"1",//用户访问时候所定位的城市id
"locate_city_name":"北京",//用户访问时候所定位的城市属性值
"app_version":"10.9.2",//用户当前使用的app版本
"os_version":"11.8.2", //用户当前手机系统的版本
"os_souce":"android" //用户当前的手机系统(Android,iPhone,小程序、web…)
//
"evs":[{
"id":"a1234"//坑位模块的全app唯一标示id
"val_val":{ //以下所有数据为同时携带的想要获取的数据内容
"user_id":"123", //访问用户的账号id;
"content_id":"123234", //商品唯一id标示
"title":"时尚卫衣清场版",//商品标题;
"price":"298",//商品价格;
"business_id":"4",//商品分类属性id
"business":"女装",//商品分类属性
"strategy":"abc123",//不同策略的策略id,用于区分不同策略的数据效果
"shop_id":"123",//商品所属的店铺id
"mark":"清仓节",//个性化的数据标签,比如清仓节代表此商品正在参加年尾甩货活动
"position":"2",//商品在列表中展示排序的第几个位置
}
}]
}]
PS:公共字段和配置信息,不用每次上报,浪费资源。当用户触发某一操作在和一系列事件信息一同上报(如关闭应用,则上报公共字段信息。如一天上报一次公共信息)
数据触发事件上报策略说明:
1.露出上报采用实际展示曝光上报策略,只有当事件本身实际曝光显示在屏幕当中才需要触发上报策略进行数据上报(露出像素>0px);
-
滑动:在页面内上下滑动时,不重复记录;
-
刷新:刷新当前页面时,重复记录曝光;
-
翻页:下拉到新一页后再返回到前一页,上下滑动不重复记录
-
返回:事件点击到落地页后,从落地页返回(包括返回按钮返回、滑动返回、支付等行为后自动跳转返回),不重复记录录曝光;
-
唤醒:a) 手机锁屏被打开,直接展示事件所在的页面,不重复记录曝光;b) 应用或者浏览器在后台被唤醒,展示广告所在的页面,不重复记录曝光;
2.没有特殊限制定义,埋点需要根据坑位颗粒端逐条上报,不做去重处理;
总结下:
关于数据上报的问题,以目前的网络条件每分钟实施信息上报是不难的事情,这样可以减少埋点的漏报数量,保证数据的完整性。
当然上报机制还需要根据实际业务进行和各部门商量着来。
埋点的数据分析如遇到数据缺失的情况或者上报策略出错,如第一天的数据,上报之后变成了第二天的数据,如果数据量小,愿意回溯,那么设置一个回溯周期。如果数据量大,直接忽略就好了。数据量大的情况下应该考虑改变上报机制才是治疗之本。数据准确不准确,有时候也不是说数据完整才有意义,样本数据够也可以。90%的样本数据,还在乎那10%吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号