Calcite执行计划优化
CBO与RBO并非对立关系,而是基于RBO的拓展
CBO = RBO + Cost Model + Model Iteration,通过代价模型,在一定的时间空间范围内通过动态规划算法来获得最终的执行计划
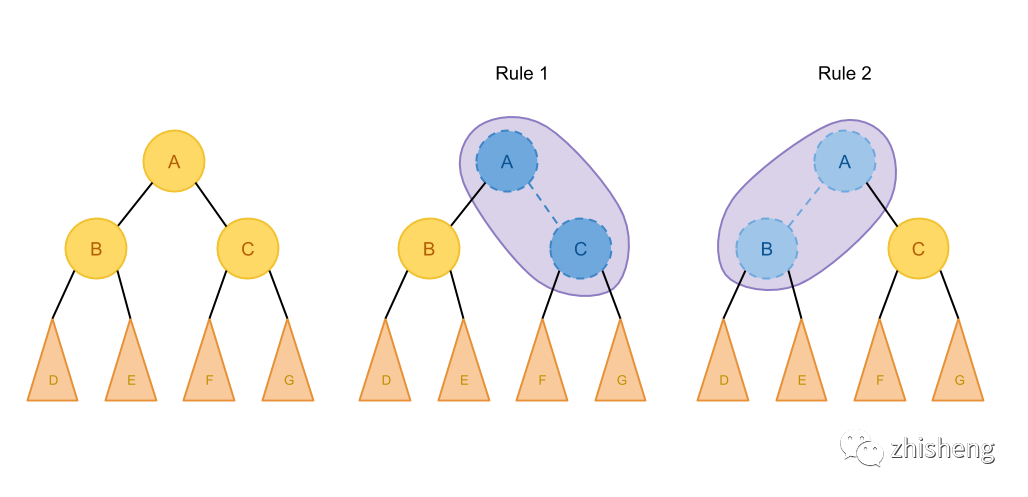
claicte的优化原理是,它假定如果一个表达式最优,那它的局部也是最优的。成本最优假设利用了贪心算法的思想,在计算的过程中, 如果一个方案是由几个局部区域组合而成,那么在计算总成本时, 我们只考虑每个局部目前已知的最优方案和成本即可。
Cost(A)∼Cost(B)+Cost(C)
Calicte提供的优化器:
HepPlanner(RBO)
简单理解就是两个循环,第一个循环会遍历节点,第二个循环规则进行匹配,开始和结束会有RelNode与HepRelVertex的转换
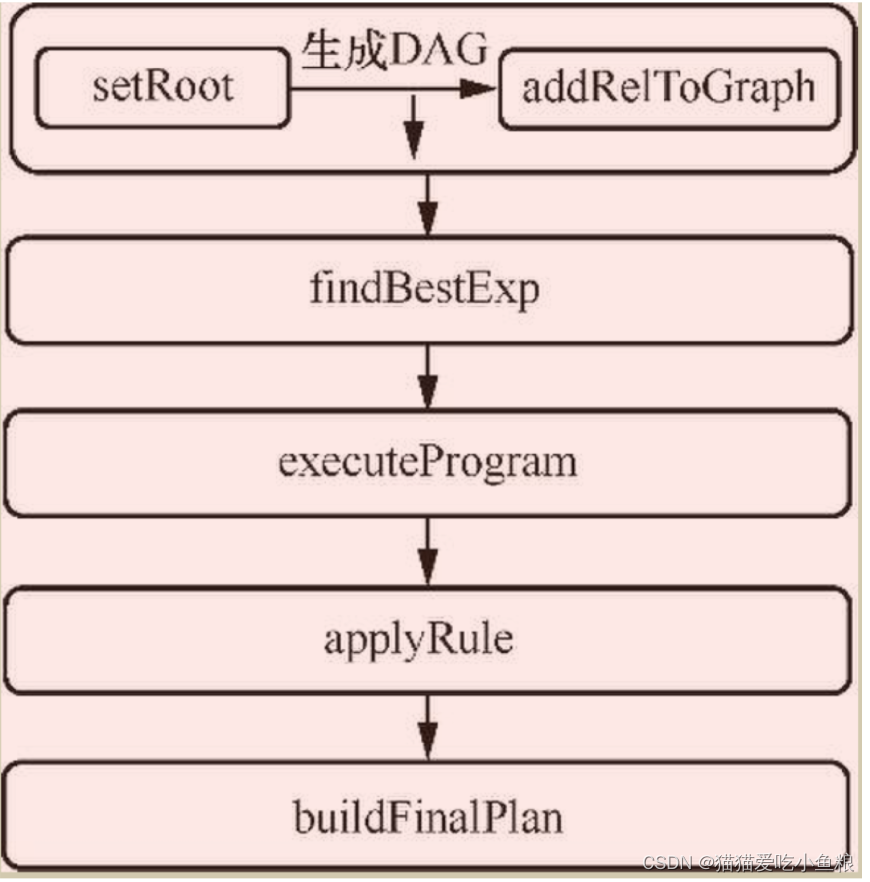
- setRoot 方法将每一个RelNode转换为相应的HepRelVertex,作为顶点最终构建出一个有向无环图(DAG)
- 调用findBestExp方法匹配规则、应用规则
- executeProgram() 会遍历所有注册的规则,然后进行匹配。规则的制定是通过 withOperandSupplier 来实现的,需要传递一个只有 apply() 的 OperandTransform 函数式Function,入参 OperandBuilder,出参 Done,代表已经完成。OperandBuilder 是制定规则的关键,通过调用 operand(Class)传入相应节点的 RelNode 的 Class 便可以定义该规则
- Project 节点下面没有任何子节点输入withOperandSupplier(b0 ->b0.operand(Project.class).noInputs)
- Project节点的一个输入是Join算子withOperandSupplier(b0 ->b0.operand(Project.class).oneInput(b1 ->b1.operand(Join.class).anyInputs()))
- FilterJoinRule:withOperandSupplier(b0 -> b0.operand(Filter.class).oneInput(b1 -> b1.operand(Join.class).anyInputs()))
- 遍历的每一条规则通过 applyRule() 方法判断该规则是否匹配,如果匹配则返回转换后的节点,如果不匹配则继续循环,当匹配次数达到最大值时就会结束循环,得到优化后的DAG
- ARBITRARY:任意匹配方式,该方式和深度优先遍历是一样的,采用的也是深度优先的方式。
- BOTTOM_UP:从叶子节点开始匹配一直到根节点,一种从下到上的方式。
- TOP_DOWN:从根节点开始匹配,一直到叶子节点,一种从上到下的方式。
- DEPTH_FIRS:深度优先遍历。
- buildFinalPlane() 将每一个节点转化为RelNode并返回
VolcanoPlanner(CBO)
不是简单地应用rule,而是会使用贪心、动态规划算法,计算每种rule匹配后生成新的SQL树的cost,与原先SQL树的Cost信息相比较,如果新的树的Cost比较低,那么才会真正应用对应的rule
Calcite当中默认提供了数据行数、CPU代价、I/O代价,通过这3个方面来影响一个规则的好坏
贪心:认为多个局部的最优代价相加后即是全局的最优代价
动态规划:分解子问题,复用已经求解的子问题
- setRoot()调用registerImpl(),遍历RelNode树的所有节点,addRelToSet()计算并记录每个节点的代价,如果有等价表达式同时它的代价更小,更新这个RelSubset
- 先遍历节点再遍历规则,若匹配则会调用 fireRules() 将规则加到 RuleQueue 队列
- findBestExp() 通过 RuleDriver 死循环地从 RuleQueue 中取出规则,两个条件可以打破循环
- 规则队列中弹出的规则为null
- 抛出VolcanoTimeoutException异常
- RelSubset#buildCheapestPlan 递归地组装每一个节点的最优解,返回优化后的RelNode树

 浙公网安备 33010602011771号
浙公网安备 33010602011771号