Redis入门之六大数据类型
一、启动redis
进入redis文件夹下,输入如下命令启动redis
src/redis-server ./redis.conf
启动之后和客户端进行连接
src/redis-cli
会出现这么一个东西127.0.0.1:6379>,也就表示成功了。
二、redis的数据类型
redis有5种数据类型,分别如下
- String:字符串
- List:列表
- Set:集合
- Hash:散列
- Sorted Set:有序集合
- HyperLogLog:基数
三、数据类型使用
(1)字符串
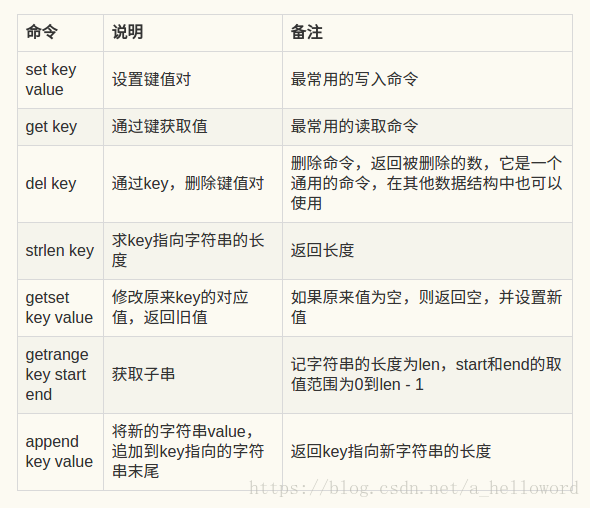
赋值命令
set key value
取值命令
get key
// 先获取key对应的value,再进行赋值。返回key对应的原来的value
getset key
删除命令
del key
@Test
public void testStringCommand() {
@SuppressWarnings("resource")
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring.xml");
@SuppressWarnings("unchecked")
RedisTemplate<String, String> redisTemplate = applicationContext.getBean(RedisTemplate.class);
// 设值
redisTemplate.opsForValue().set("key1", "value1");
redisTemplate.opsForValue().set("key2", "value2");
// 通过key获取值
String value1 = (String)redisTemplate.opsForValue().get("key1");
System.out.println(value1);
// 通过key删除值
redisTemplate.delete("key1");
// 求长度
Long length = redisTemplate.opsForValue().size("key2");
System.out.println(length);
// 设置新值并返回旧值
String oldValue = redisTemplate.opsForValue().getAndSet("key2", "newValue");
System.out.println(oldValue);
String value2 = redisTemplate.opsForValue().get("key2");
System.out.println(value2);
// 求字串
String rangeValue = redisTemplate.opsForValue().get("key2", 0, 3);
System.out.println(rangeValue);
// 追加字符串到末尾,返回新串长度
int newLen = redisTemplate.opsForValue().append("key2", " append");
System.out.println(newLen);
value2 = redisTemplate.opsForValue().get("key2");
System.out.println(value2);
}
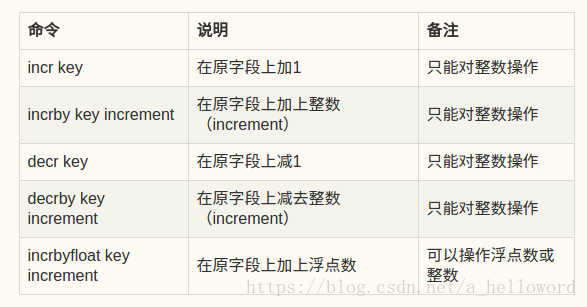
数值增减命令
- incr key:将key对应的value加1操作,如果没有定义当前变量,则初始化当前变量为0,再执行加1操作。
- decr key:将key对应的value减1操作,如果没有定义当前变量,则初始化当前变量为0,再执行减1操作。
- incrby key increment:将key对应的value加increment,如果没有定义当前变量,则初始化当前变量为0,再执行加increment操作。
- decr key increment:将key对应的value减increment,如果没有定义当前变量,则初始化当前变量为0,再执行减increment操作。
如果对一个不能转化为数字类型的字符串执行上面的操作,则会报错。
(error) ERR value is not an integer or out of range
@SuppressWarnings("unchecked")
@Test
public void testNumberCommand() {
// 加载配置文件
@SuppressWarnings("resource")
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring.xml");
// 获取实例
@SuppressWarnings("rawtypes")
RedisTemplate rt = applicationContext.getBean(RedisTemplate.class);
rt.opsForValue().set("i","9");
printCurrValue(rt,"i");
rt.opsForValue().increment("i", 1);
printCurrValue(rt,"i");
// RedisTemplate没有支持减法,所以用下面的代码代替,原有值必须为整数, 否则运行出错
rt.getConnectionFactory().getConnection().decr(rt.getKeySerializer().serialize("i"));
printCurrValue(rt,"i");
rt.getConnectionFactory().getConnection().decrBy(rt.getKeySerializer().serialize("i"), 6);
printCurrValue(rt,"i");
rt.opsForValue().increment("i", 2.3);
printCurrValue(rt,"i");
}
/**
* 打印当前key的值
* @param rt
* @param key
*/
public void printCurrValue(@SuppressWarnings("rawtypes") RedisTemplate rt,String key) {
String i = (String)rt.opsForValue().get(key);
System.out.println(i);
}
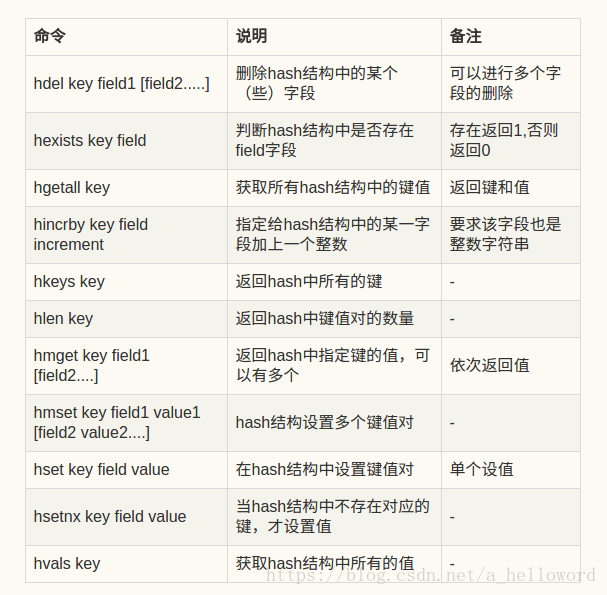
(2)散列
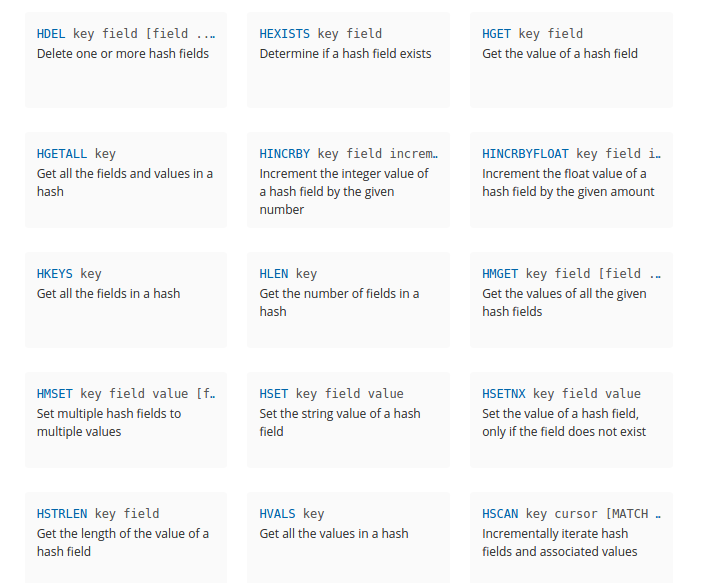
和Java中的Map类似,一个对象里有许多键值对,适合存储对象,如果内存足够大,一个Redis的hash结构可以存储2^32-1键值对(40多亿)。
package com.codeliu.test;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.data.redis.core.RedisTemplate;
/**
* 测试redis散列(hash)操作
* @author liu
*/
public class HashTest {
@SuppressWarnings({ "rawtypes", "unchecked", "unused" })
@Test
public void testHash() {
@SuppressWarnings("resource")
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring.xml");
RedisTemplate rt = applicationContext.getBean(RedisTemplate.class);
String key = "hash";
HashMap<String,String> map = new HashMap<>();
map.put("f1", "value1");
map.put("f2", "value2");
// 相当于hmset命令
rt.opsForHash().putAll(key, map);
// 相当于hset命令
rt.opsForHash().put(key, "f3", "6");
printValueForHash(rt,key,"f3");
// 相当于hexists key field命令
boolean exist = rt.opsForHash().hasKey(key, "f3");
System.out.println(exist);
// 相当于hgetall命令
Map<String, String> keyvalMap = rt.opsForHash().entries(key);
// 相当于hincrby命令
rt.opsForHash().increment(key, "f3", 2);
printValueForHash(rt,key,"f3");
// 相当于hincrbyfloat命令
rt.opsForHash().increment(key, "f3", 0.3);
printValueForHash(rt,key,"f3");
// 相当于hvals命令
List<String> list = rt.opsForHash().values(key);
Set<String> set = rt.opsForHash().keys(key);
List<String> keyList = new ArrayList<>();
keyList.add("f1");
keyList.add("f2");
// 相当于hmget命令
List<String> value = rt.opsForHash().multiGet(key, keyList);
// 相当于hsetnx命令
boolean success = rt.opsForHash().putIfAbsent(key, "f4", "value4");
System.out.println(success);
// 相当于hdel命令
long result = rt.opsForHash().delete(key, "f1","f2");
System.out.println(result);
}
/**
* 返回hash中指定键的值
* @param rt
* @param key hash
* @param field hashKey
*/
@SuppressWarnings("rawtypes")
private void printValueForHash(RedisTemplate rt, String key, String field) {
@SuppressWarnings("unchecked")
Object value = rt.opsForHash().get(key, field);
System.out.println(value);
}
}
注意下面几点
- hgetall命令会返回所有的键值对,并保存到一个map对象中,如果hash结构很大,那么要考虑它对JVM的影响。
- 使用rt.opsForHash().putAll(key, map);方法相当于执行了hmset命令,使用了map,由于配置了默认的序列化器为字符串,所以它也只会用字符串进行转化,这样才能执行对应的数值加法,如果使用其他的序列化器,则后面的命令可能会抛出异常。
org.springframework.data.redis.serializer.SerializationException: Cannot deserialize; nested exception is org.springframework.core.serializer.support.SerializationFailedException: Failed to deserialize payload. Is the byte array a result of corresponding serialization for DefaultDeserializer?; nested exception is java.io.EOFException
at org.springframework.data.redis.serializer.JdkSerializationRedisSerializer.deserialize(JdkSerializationRedisSerializer.java:81)
at org.springframework.data.redis.core.AbstractOperations.deserializeHashKey(AbstractOperations.java:327)
at org.springframework.data.redis.core.AbstractOperations.deserializeHashMap(AbstractOperations.java:279)
at org.springframework.data.redis.core.DefaultHashOperations.entries(DefaultHashOperations.java:227)
at com.codeliu.test.HashTest.testHash(HashTest.java:39)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:50)
at org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
at org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:47)
at org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:325)
at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:78)
at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:57)
at org.junit.runners.ParentRunner$3.run(ParentRunner.java:290)
at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71)
at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:288)
at org.junit.runners.ParentRunner.access$000(ParentRunner.java:58)
at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:268)
at org.junit.runners.ParentRunner.run(ParentRunner.java:363)
at org.eclipse.jdt.internal.junit4.runner.JUnit4TestReference.run(JUnit4TestReference.java:86)
at org.eclipse.jdt.internal.junit.runner.TestExecution.run(TestExecution.java:38)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.runTests(RemoteTestRunner.java:538)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.runTests(RemoteTestRunner.java:760)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.run(RemoteTestRunner.java:460)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.main(RemoteTestRunner.java:206)
Caused by: org.springframework.core.serializer.support.SerializationFailedException: Failed to deserialize payload. Is the byte array a result of corresponding serialization for DefaultDeserializer?; nested exception is java.io.EOFException
at org.springframework.core.serializer.support.DeserializingConverter.convert(DeserializingConverter.java:78)
at org.springframework.core.serializer.support.DeserializingConverter.convert(DeserializingConverter.java:36)
at org.springframework.data.redis.serializer.JdkSerializationRedisSerializer.deserialize(JdkSerializationRedisSerializer.java:79)
... 27 more
Caused by: java.io.EOFException
at java.io.ObjectInputStream$PeekInputStream.readFully(ObjectInputStream.java:2638)
at java.io.ObjectInputStream$BlockDataInputStream.readShort(ObjectInputStream.java:3113)
at java.io.ObjectInputStream.readStreamHeader(ObjectInputStream.java:854)
at java.io.ObjectInputStream.<init>(ObjectInputStream.java:349)
at org.springframework.core.ConfigurableObjectInputStream.<init>(ConfigurableObjectInputStream.java:63)
at org.springframework.core.ConfigurableObjectInputStream.<init>(ConfigurableObjectInputStream.java:49)
at org.springframework.core.serializer.DefaultDeserializer.deserialize(DefaultDeserializer.java:68)
at org.springframework.core.serializer.support.DeserializingConverter.convert(DeserializingConverter.java:73)
... 29 more
- 在使用大的hash结构时,要考虑返回数据的大小,以避免返回太多数据,引发JVM内存溢出或者redis的性能问题。
(3)链表(Linked-List)
可以存储多个字符串,而且是有序的,能够存储2^32 - 1个节点(超过40亿个节点)。Redis链表是双向的。插入和删除元素效率高,查找元素效率低。
Redis链表命令分为左操作和右操作两种,左操作意味着从左到右,右操作意味着从右到左。
| 命令 | 说明 | 备注
| - - - - - - - - - - | - - - - - | - - - - -
|push key node1 [node2] … | 把节点node1加入到链表最左边 | 可以一次加入多个
|rpush key node1 [node2]…|把节点node1加入到链表最右边|可以一次加入多个
|lindex key index|读取下标为index的节点|返回节点字符串,从0开始算
|llen key|求链表的长度|返回链表节点数
|lpop key|删除左边第一个节点,并将其返回|-
|rpop key|删除右边第一个节点,并将其返回|-
|linsert key before|after pivot node| 插入一个节点node,可以指定在值为pivot的节点的前面或后面|如果list不存在,则报错,如果没有值为对应pivot,也会插入失败返回-1
|lpushx list node|如果存在key为list的链表,则 插入节点node作为从左到右的第一个节点|如果list不存在,则失败
|rpushx list node|如果存在key为list的链表,则 插入节点node作为从左到右的最后一个节点|如果list不存在,则失败
|lrange list start end|获取链表list从start下标到end下标的节点值|包含start和end下标的值
|lrem list count value|如果count为0,则删除所有值等于value的节点,如果count不为0,则先对count取绝对值,假设记为abs,然后从左到右删除不大于abs个等于value的节点|注意count为整数
|lset key index node|设置列表下标为index的节点的值为node|-
|ltrim key start stop|修剪链表,只保留从start到stop的区间的节点,其余的都删掉|包含start和end的下标的节点会保留
注意下面几点
-
对于大量数据操作的时候,要考虑插入和删除内容的大小,因为这将时十分消耗性能的命令,会导致redis服务器的卡顿。对于不允许出现卡顿的服务器,可以进行分批次操作。
-
上面这些操作链表的命令都是进程不安全的,因为当我们操作这些命令的时候,其他redis的客户端可能也在操作同一个链表,这样就会造成并发数据安全和一致性的问题,为了克服这些问题,Redis提供了链表的阻塞命令,它们在运行的时候,会给链表加锁,以保证操作链表的命令安全性。
链表的阻塞命令
| 命令 | 说明 | 备注 |
|---|---|---|
| blpop key timeout | 移出并获取列表的第一个元素,如果列表没有元素,会阻塞列表直到等待超时或发现可弹出元素为止 | 相对于lpop命令,它的操作是进程安全的 |
| brpop key timeout | 移出并获取列表的最后一个元素,如果列表没有元素,会阻塞列表直到等待超时或发现可弹出元素为止 | 相对于rpop命令,它的操作是进程安全的 |
| rpoplpush key src dest | 按从左到右的顺序,将一个链表的最后一个元素移除,插入到链表最左边 | 不能设置超时时间 |
| brpoplpush key src dest timeout | 按从左到右的顺序,将一个链表的最后一个元素移除,插入到链表最左边,并可以设置超时时间 | 可设置超时时间 |
package com.codeliu.test;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.List;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.data.redis.connection.RedisListCommands;
import org.springframework.data.redis.core.RedisTemplate;
/**
* 测试Redis链表(List)操作
* @author liu
*/
public class ListTest {
public void printList(RedisTemplate<String, String> rt,String key) {
// 求链表长度
long size = rt.opsForList().size(key);
// 获取整个链表的值
List<String> valueList = rt.opsForList().range(key, 0, size);
System.out.println(valueList);
}
@SuppressWarnings({ "resource", "rawtypes", "unchecked", "unused" })
@Test
public void testList() {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring.xml");
RedisTemplate rt = applicationContext.getBean(RedisTemplate.class);
// 删除链表,以便我们反复测试
rt.delete("lits");
// 把node3插入链表list
rt.opsForList().leftPush("lits", "node3");
List<String> nodeList = new ArrayList<>();
for(int i = 2; i >= 1; i--) {
nodeList.add("node" + i);
}
// 相当于lpush把多个节点从左往右插入链表
rt.opsForList().leftPushAll("list", nodeList);
// 从右边插入一个节点
rt.opsForList().rightPush("list", "node4");
// 获取下标为0的节点
String node1 = (String)rt.opsForList().index("list", 0);
// 获取链表长度
long size = rt.opsForList().size("list");
// 从左边弹出一个节点
String lpop = (String)rt.opsForList().leftPop("list");
// 从右边弹出一个节点
String rpop = (String)rt.opsForList().rightPop("list");
// 使用更底层的命令才能操作linsert命令,在node2前面插入一个节点
try {
rt.getConnectionFactory().getConnection().lInsert("list".getBytes("utf-8"),
RedisListCommands.Position.BEFORE,
"node2".getBytes("utf-8"), "before_node2".getBytes("utf-8"));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
// 判断list是否存在,如果存在则从左边插入head节点
rt.opsForList().leftPushIfPresent("list", "head");
// 判断是否存在,如果存在就从右边插入end节点
rt.opsForList().rightPushIfPresent("list", "end");
// 从左到右,获取下标从0到10的节点元素
List<String> lits = rt.opsForList().range("list", 0, 10);
nodeList.clear();
for(int i = 0; i < 3; i++) {
nodeList.add("node");
}
// 在链表左边插入三个值为node的节点
rt.opsForList().leftPushAll("list", nodeList);
// 从左到右删除至多三个节点
rt.opsForList().remove("list", 3, "node");
// 给下标为0的节点设置新值
rt.opsForList().set("list", 0, "new value1");
// 打印链表数据
printList(rt,"list");
}
}
/**
* spring对阻塞命令的操作
*/
@SuppressWarnings({ "resource", "rawtypes", "unchecked" })
@Test
public void testBList() {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring.xml");
RedisTemplate rt = applicationContext.getBean(RedisTemplate.class);
// 清空数据,可以重复测试
rt.delete("list1");
rt.delete("list2");
// 初始化链表list
List<String> nodeList = new ArrayList<String>();
for(int i = 1; i <= 5; i++) {
nodeList.add("node" + i);
}
rt.opsForList().leftPushAll("list1", nodeList);
// spring使用参数超时时间作为阻塞命令区分,等价于blpop命令,并且可以设置时间参数
rt.opsForList().leftPop("list1", 1, TimeUnit.SECONDS);
nodeList.clear();
// 初始化链表list2
for(int i = 1; i<= 3; i++) {
nodeList.add("data" + i);
}
rt.opsForList().leftPushAll("list2", nodeList);
// 相当于rpoplpush命令,弹出list1最右边的节点,插入到list2最左边
rt.opsForList().rightPopAndLeftPush("list1", "list2");
// 相当于brpoplpush命令,注意在spring中使用超时参数区分
rt.opsForList().rightPopAndLeftPush("list1", "list2",1, TimeUnit.SECONDS);
// 打印链表数据
printList(rt,"list1");
printList(rt,"list2");
}
在多线程环境中能在一定程度上保证数据的一致性而性能却不佳。
(4)集合(Set)
Redis的集合不是一个线性结构,而是一个hash表结构,内部会根据hash分子来存储和查找数据,理论上一个集合可以存储2^32 - 1个元素,因为采用hash结构,所以插入、删除、查找的复杂度都是O(1),要注意以下几点
- 每一个元素都不能重复,插入重复元素会失败。
- 集合是无序的。
- 集合每一个元素都是String类型。
Redis的集合可以操作其他的集合,比如求两个或以上集合的交集、差集和并集。
| 命令 | 说明 | 备注 |
|---|---|---|
| sadd key member1 [member2 member3…] | 给键为key的集合增加成员 | 可以同时增加多个 |
| scard key | 统计键为key的集合成员数 | - |
| sdiff key1 [key2] | 求出两个集合的差集 | 参数如果是单key,就返回这个key的所有元素 |
| sdiffstore des key1 [key2] | 先按sdiff命令的规则,找出key1和key2两个集合的差集,然后将其保存到des集合中 | - |
| sinter key1 [key2] | 求key1和key2两个集合的交集 | 参数如果是单key,就返回这个key的所有元素 |
| sinterstore des key1 [key2] | 先按sinter命令的规则,找出key1和key2两个集合的交集,然后将其保存到des集合中 | - |
| sismember key member | 判断member是否是键为key的集合的成员 | 是返回1,否则返回0 |
| smembers key | 返回集合所有成员 | 如果数据量大,需要考虑迭代遍历的问题 |
| smove src des member | 将成员member从集合src迁移到集合des中 | - |
| spop key | 随机弹出集合中的一个元素 | 注意其随机性,因为集合是无序的 |
| srandmember key [count] | 随机返回集合中一个或多个元素,count为返回总数,如果为负数,先求绝对值 | count为整数,如果不填默认为1,如果count大于等于集合总数,则返回整个集合 |
| srem key member1 [member2…] | 移除集合中的元素,可以是多个元素 | 对于很大的集合可以通过它删除部分元素,避免删除大量数据引发Redis停顿 |
| sunion key1 [key2] | 求两个集合的并集 | 参数如果是单key,那么redis就返回这个key的所有元素 |
| sunionstore des key1 key2 | 先执行sunion命令求出并集,然后保存到键为des的集合中 | - |
package com.codeliu.test;
import java.util.List;
import java.util.Set;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.data.redis.core.RedisTemplate;
/**
* 测试Redis集合(set)操作
* @author liu
*/
public class SetTest {
@SuppressWarnings({ "resource", "rawtypes", "unchecked", "unused" })
@Test
public void testSet() {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring.xml");
RedisTemplate rt = applicationContext.getBean(RedisTemplate.class);
Set<String> set = null;
// 将元素加入列表
rt.boundSetOps("set1").add("v1","v2","v3","v4","v5","v6");
rt.boundSetOps("set2").add("v0","v2","v4","v6","v8");
// 求集合长度
rt.opsForSet().size("set1");
// 求差集
set = rt.opsForSet().difference("set1", "set2");
// 求并集
set = rt.opsForSet().intersect("set1", "set2");
// 判断集合中是否有某元素
boolean exist = rt.opsForSet().isMember("set1", "v1");
// 获取集合所有元素
set = rt.opsForSet().members("set1");
// 从集合中随机弹出一个元素
String val = (String)rt.opsForSet().pop("set1");
// 随机获取一个集合的元素
val = (String)rt.opsForSet().randomMember("set1");
// 随机获取集合2个元素
List<String> list = rt.opsForSet().randomMembers("set2", 2L);
// 删除一个集合的元素,参数可以是多个
rt.opsForSet().remove("set1", "v1");
// 求两个集合的并集
rt.opsForSet().union("set1","set2");
// 求两个集合的差集,并保存到集合diff_set中
rt.opsForSet().differenceAndStore("set1", "set2", "diff_set");
// 求两个集合的交集,并保存到集合inter_set中
rt.opsForSet().intersectAndStore("set1", "set2", "inter_set");
// 求两个集合的并集,并保存到union_set中
rt.opsForSet().unionAndStore("set1", "set2", "union_set");
}
}
(5)有序集合(ZSet)
有序集合和无序集合类似,和无序集合的主要区别在于每一个元素除了值以外,还会多一个分数。分数是一个浮点数,double类型,根据分数,Redis就支持对分数排序。和无序集合一样,每一个元素都是唯一的,但对于不同元素,它的分数可以一样。元素也是String类型,也是一种基于hash的存储结构。

有序集合依赖key标识它是哪个集合,依赖分数进行排序,所以值和分数是必须的,不仅可以对分数进行排序,在满足一定条件下,也可以对值进行排序。
| 命令 | 说明 | 备注 |
|---|---|---|
| zadd key score1 value1 [score2 value2…] | 向有序集合key,增加一个或多个成员 | 如果不存在对应的key,则创建键为key的有序集合 |
| zcard key | 获取有序集合的成员数 | - |
| zcount key min max | 根据分数返回对应的成员列表 | min为最小值,max为最大值,默认为包含min和max值,采用数学区间表示的方法,如果需要不包含,则在分数前面加上“(”,注意不支持“["表示 |
| zincrby key increment member | 给有序集合成员值为member的分数增加increment | - |
| zinterstore desKey numKeys key1 [key2 key3…] | 求多个有序集合的交集,并且将结果保存到desKey中 | numKeys是一个整数,表示有几个有序集合 |
| zlexcount key min max | 求有序集合key成员值在min和max的范围 | Redis借助数据区间的表示方法,”[“表示包含该值,"("表示不包含该值 |
| zrange key start stop [withscores] | 按照分值的大小(从小到大)返回成员,加入start和stop参数可以截取某一段返回。如果输入可选项withscores,则连同分数一起返回。 | 这里记集合最大长度为len,则Redis将集合排序后,形成一个从0到len - 1的下标,然后根据start和stop控制的下标(包含start和stop)返回 |
| zrank key member | 按从小到大求有序集合的排行 | 排名第一的为0,排名第二的为1.。。 |
| zrangebylex key min max [limit offset count] | 根据值从小到大排序,limit可选,当Redis求出范围集合后,会产生下标0到n,然后根据偏移量offset和限定返回数count,返回对应成员 | Redis借助数据区间的表示方法,”[“表示包含该值,"("表示不包含该值 |
| zrangebyscore key min max [withscores] [limit offset count] | 根据分数的大小,从小到大求取范围,选项withscores和limit参考zrange命令和zrangebylex | 默认为包含min和max值,采用数学区间表示的方法,如果需要不包含,则在分数前面加上“(”,注意不支持“["表示 |
| zremrangebyscore key start stop | 根据分数区间进行删除 | 按照score进行排序,根据start和stop进行删除,Redis借助数据区间的表示方法,”[“表示包含该值,"("表示不包含该值 |
| zremrangebyrank key start stop | 按照分数从小到大的删除,从0开始计算 | - |
| zremrangebylex key min max | 按照值的分布进行删除 | - |
| zrevrange key start stop [withscores] | 从大到小的按分数排序,参数参见zrange | 与zrange相同,只是排序是从大到小 |
| zrevrangebyscore key max min [withscores] | 从大到小的按分数排序,参数请参见zrangebyscore | 于zrangebyscore相同,只是排序是从大到小 |
| zrevrank key member | 按从大到小的顺序,求元素的排行 | 排名第一为0,第二为1… |
| zscore key member | 返回成员的分数值 | 返回成员的分数 |
| zunionstore desKey numKeys key1 [key2 key3 key4…] | 求多个有序集合的并集,其中numKeys是有序集合的个数 | - |
在spring中使用Redis的有序集合,需要注意Spring对Redis有序集合的元素值和分数的范围(Range)和限制(Limit)进行了封装。
TypedTuple,它是ZSetOperations接口的内部接口,源码如下
public interface ZSetOperations<K, V> {
/**
* Typed ZSet tuple.
*/
public interface TypedTuple<V> extends Comparable<TypedTuple<V>> {
//获取值
V getValue();
//获取分数
Double getScore();
}
}
有一个默认的实现类DefaultTypedTuple,在默认的情况下会把带有分数的有序集合的值和分数封装到这个类中,这样就可以通过这个类对象读取相应的值和分数。
Spring不仅对有序集合元素封装,也对范围和限制进行了封装,使用接口RedisZSetCommand下的内部类Range和Limit进行封装的。Range有一个静态的range方法,使用它可以生成一个Range对象。
package com.codeliu.test;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.data.redis.connection.RedisZSetCommands.Limit;
import org.springframework.data.redis.connection.RedisZSetCommands.Range;
import org.springframework.data.redis.core.DefaultTypedTuple;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ZSetOperations.TypedTuple;
/**
* 测试Redis的有序集合(ZSet)的命令
* @author liu
*/
public class ZSetTest {
/**
* 打印普通集合
* @param set
*/
private void printSet(Set<String> set) {
if(set != null && set.isEmpty()) {
return ;
}
Iterator<String> iterator = set.iterator();
while(iterator.hasNext()) {
System.out.println(iterator.next() + "\t");
}
System.out.println();
}
/**
* 打印TypedTuple集合
* @param set
*/
@SuppressWarnings({ "rawtypes", "unchecked" })
private void printTypedTuple(Set<TypedTuple> set) {
if(set != null && set.isEmpty()) {
return ;
}
Iterator iterator = set.iterator();
while(iterator.hasNext()) {
TypedTuple<String> val = (TypedTuple<String>)iterator.next();
System.out.println("{value = " + val.getValue() + ",score = " + val.getScore() + "}");
}
}
@SuppressWarnings({ "resource", "rawtypes", "unchecked", "unused" })
@Test
public void testZSet() {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring.xml");
RedisTemplate rt = applicationContext.getBean(RedisTemplate.class);
// spring提供接口TypedTuple操作有序集合
Set<TypedTuple> set1 = new HashSet<>();
Set<TypedTuple> set2 = new HashSet<>();
int j = 9;
for(int i = 1; i <= 9; i++) {
j--;
// 计算分数和值
Double score1 = Double.valueOf(i);
String value1 = "x" + i;
Double score2 = Double.valueOf(j);
String value2 = j % 2 == 1 ? "y" + j : "x" + j;
// 使用spring提供的默认TypedTuple---DefaultTypedTuple
TypedTuple t1 = new DefaultTypedTuple(value1, score1);
set1.add(t1);
TypedTuple t2 = new DefaultTypedTuple(value2, score2);
set2.add(t2);
}
// 将元素插入有序集合zset1
rt.opsForZSet().add("zset1", set1);
rt.opsForZSet().add("zset2", set2);
// 统计总数
Long size = null;
size = rt.opsForZSet().zCard("zset1");
// 统计3<=score<=6
size = rt.opsForZSet().count("zset1", 3, 6);
Set set = null;
// 从下标1开始截取5个元素,但是不返回分数,每一个元素都是String
set = rt.opsForZSet().range("zset1", 1, 5);
printSet(set);
// 截取集合所有元素,并且对集合按分数排序,并返回分数,每一个元素都是TypedTuple
set = rt.opsForZSet().rangeWithScores("zset1", 0, -1);
printTypedTuple(set);
// 将zset1和zset2两个集合的交集放入集合inter_zset
size = rt.opsForZSet().intersectAndStore("zset1", "zset2", "inter_zset");
// 区间
Range range = Range.range();
// 小于
range.lt("x8");
// 大于
range.gt("x1");
set = rt.opsForZSet().rangeByLex("zset1", range);
printSet(set);
// 小于等于
range.lte("x8");
// 大于等于
range.gte("x1");
set = rt.opsForZSet().rangeByLex("zset1", range);
printSet(set);
// 限制返回个数
Limit limit = Limit.limit();
limit.count(4);
// 限制从第五个元素开始截取
limit.offset(5);
// 求区间内的元素,并限制返回4条
set = rt.opsForZSet().rangeByLex("zset1", range, limit);
printSet(set);
// 求排行,排名第一返回0,第二返回1
Long rank = rt.opsForZSet().rank("zset1", "x4");
System.out.println("rank = " + rank);
// 删除元素,返回删除个数
size = rt.opsForZSet().remove("zset1", "x5","x6");
System.out.println("delete = " + size);
// 按照排行删除从0开始算,这里将删除排行第2和第3的元素
size = rt.opsForZSet().removeRange("zset1", 1, 2);
// 获取集合所有的元素和分数,以-1代表所有元素
set = rt.opsForZSet().rangeWithScores("zset2", 0, -1);
printTypedTuple(set);
// 删除指定元素
size = rt.opsForZSet().remove("zset2", "y5","y3");
System.out.println("size = " + size);
// 给集合中一个元素的分数加上11
Double db1 = rt.opsForZSet().incrementScore("zset1", "x1", 11);
rt.opsForZSet().removeRangeByScore("zset1", 1, 2);
set = rt.opsForZSet().reverseRangeWithScores("zset2", 1, 10);
printTypedTuple(set);
}
}
(6)基数(HyperLogLog)
基数是一种算法。比如一本英文著作由几百万个单词组成,内存不足以存储他们,但英文单词本身是有限的,在这几百万个单词中有许多重复的单词,去掉重复的,内存就足够存储了。比如数字集合{1,2,5,7,9,1,5,9}的基数集合为{1,2,5,7,9},那么基数为5。**基数的作用是评估大约需要准备多少个存储单元去存储数据。**基数不能存储元素。
| 命令 | 说明 | 备注 |
|---|---|---|
| pfadd key element | 添加指定元素到HyperLogLog中 | 如果已经存储该元素,则返回0,添加失败 |
| pfcount key | 返回HyperLogLog的基数值 | - |
| pfmerge desKey key1 [key2 key3…] | 合并多个HyperLogLog,并将其保存在desKey中 | - |
package com.codeliu.test;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.data.redis.core.RedisTemplate;
/**
* 测试Redis的基数命令
* @author liu
*/
public class HyperLogLogTest {
@SuppressWarnings({ "resource", "rawtypes", "unchecked" })
@Test
public void testHyperLogLog() {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("spring.xml");
RedisTemplate rt = applicationContext.getBean(RedisTemplate.class);
rt.opsForHyperLogLog().add("HyperLogLog", "a", "b", "c", "d", "a");
rt.opsForHyperLogLog().add("HyperLogLog2", "a");
rt.opsForHyperLogLog().add("HyperLogLog2", "z");
Long size = rt.opsForHyperLogLog().size("HyperLogLog");
System.out.println("size = " + size);
size = rt.opsForHyperLogLog().size("HyperLogLog2");
System.out.println("size = " + size);
rt.opsForHyperLogLog().union("des_key", "HyperLogLog","HyperLogLog2");
size = rt.opsForHyperLogLog().size("des_key");
System.out.println("size = " + size);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号