数据库面试题汇总--关系型数据库(主要为 Mysql)
数据库知识作为面试必考题,在面试的过程中占比很好,尤其是后端开发,一定要精通,尤其是索引和事务,每个专业的面试官都会问,一定不能只停留在增删查改上。
1、数据库三范式
第一范式:要求每列都是最小的数据单元,不可分割。
比如学生表(学号、姓名、性别、出生年月),出生年月还可以分为(出生年、出生月、出生日),那么它就不符合第一范式了。
第二范式:在第一范式的基础上,要求每列都和主键相关。
比如学生表(学号、姓名、课程号、学分),这里姓名依赖学号、学分依赖课程号,第二范式强调非主键字段必须依赖主键,所以不符合第二范式。
可能会存在的问题:
(1)数据冗余:每条记录都含有相同的信息,比如所有学生都选了同一门课程。
(2)删除异常:删除学生,则对应的课程也被删除了。
(3)插入异常:学生未选课,则无法插入数据库。
(4)更新异常:调整课程学分,可能所有行都要更新。
正确的设计应该如下:
学生表(学号、姓名)
课程表(课程号、学分)
学生选课表(学号、课程号、成绩)
第三范式:在第二范式的基础上,要求每列都和主键直接相关,而不是间接相关。
比如学生表(学号、姓名、年龄、学院名称、学院电话)
因为存在依赖关系:学号->学生->所在学院->学院电话,而第三范式要求任何字段都不能由其他字段派生出来,它要求字段没有冗余,即不存在传递依赖。
可能存在的问题:
(1)数据冗余:重复保存学院信息
(2)更新异常:更新学院信息时,可能需要更新多条记录,不然会出现数据不一致的情况。
正确的设计应该如下:
学生表(学号、姓名、年龄、所在学院)
学院表(学院名称、学院电话)
2、分别说一下范式和反范式的优缺点
范式化
优点:
(1)减少数据冗余。
(2)表中重复数据较少,更新比较快。
(3)范式化的表通常比反范式化的表更小。
缺点
(1)查询时需要多表联合查询,降低了查询效率。
(2)增加了索引优化的难度。
反范式化
优点:
(1)可以减少表的关联。
(2)更好进行索引的优化。
缺点:
(1)数据的冗余。
(2)对数据进行修改需要更多的成本。
3、Mysql 数据库索引B+ 树和 B 树的区别
(1)B+树的非叶子节点只存储关键字和指向子节点的指针,而B树的非叶子节点还存储了数据,在同样大小的情况下,B+树可以存储更多的数据。
(2)B+树叶子节点存储了所有的关键字和数据,并且多个节点用链表连接,可以快速进行查找。
(3)B+树非叶子节点不存储数据,所以查询时间复杂度固定为O(logN),B树查询时间复杂度不确定,最好为O(1)
4、为什么 B+ 树比 B 树更适合应用于数据库索引,除了数据库索引,还有什么地方用到了(操作系统的文件索引)
因为B树的叶子节点和非叶子节点都存储了数据,导致了非叶子节点能存储的关键字和指针变少,如果要存储大量数据,只能增加树的高度,导致IO操作变多, 查询性能降低。
除数据库索引,还有操作系统的文件索引用到了B树。
5、聚簇索引和非聚簇索引
(1)聚簇索引,又叫主键索引,每个表只有一个主键索引,叶子节点保存主键的值和数据。
(2)非聚簇索引,又叫辅助索引,叶子节点保存索引字段的值和主键的值。
6、前缀索引和覆盖索引
(1)前缀索引
对于列的值较长,比如TEXT、BLOB、VARCHAR,就必须建立前缀索引,即将值得前一部分作为索引。这样既可以节约空间,又可以提高查询效率。但无法使用前缀索引做ORDER BY和GROUP BY,也无法使用前缀索引做覆盖扫描。
(2)覆盖索引
select的数据列从索引中就能获得,不必再从数据表中读取。如果一个索引中包含了(或覆盖了)查询语句中字段与条件的数据就叫做覆盖索引。
当发起一个被索引覆盖的查询(也叫作索引覆盖查询)时,在EXPLAIN的Extra列可以看到Using index的信息
7、介绍一下数据库的事务
事务是一个操作序列,这些操作要么全都执行,要么全都不执行。
事务具有四大特性:A(原子性)、C(一致性)、I(隔离性)、D(持久性)
- Mysql 有哪些隔离级别
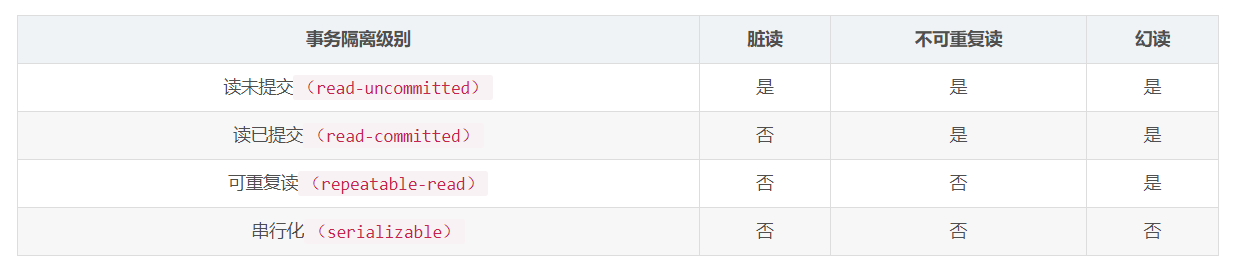
8、Mysql 什么情况会造成脏读、不可重复度、幻读?如何解决
脏读:有两个事务A和B,A读取被B修改但未提交的的字段,此时B回滚,那么A读取的字段就是临时无效的。可以提高隔离级别到读已提交解决脏读问题。
不可重复读:有两个事务A和B,A读取了一个字段值,此时B更新并且提交了事务,A再重新读取这个字段,就和之前不相等了。可以提高隔离级别到可重复读解决这个问题。
幻读:有两个事务A和B,A读取了某个范围内的记录,此时B在该范围内插入了新的记录并提交,当A再次读取该范围内的纪录时,会产生幻行。可以提高隔离级别到可串行化,或者使用MVCC + next-key解决。
9、Mysql 在可重复读的隔离级别下会不会有幻读的情况,为什么?
不会,MySQL的默认隔离级别是RR,使用MVCC + next-key锁的方式解决幻读。

PS:其实严格来说,是存在幻读的。。。可以尝试一下这个操作,A开启事务,执行查询,此时B开启事务新增一条数据并提交,此时A再查询,发现没有幻读,但是如果A执行一个update操作,再查询,会发现出现了幻读。我认为应该是A在执行update操作的时候,新建了一条创建版本号为A事务版本号的记录,然后标记B事务创建的记录为待删除的,查询的版本号依据是删除版本号为空或大于当前版本号,并且创建版本号小于等于当前事务版本号,那么这里刚刚A更新的这条数据,显然也符合查询的条件,所以也会被查出来。
MVCC版本号原理参考文章:https://www.cnblogs.com/shujiying/p/11347632.html
详细测试参考文章:https://blog.csdn.net/w139074301/article/details/111052454
10、Mysql 事务是如何实现的
- 原子性:通过
undo log实现的。每条数据的变更都伴随一条undo log日志的生成,当系统发生错误或者执行回滚数据根据undo log做逆向操作。 - 一致性:通过
redo log实现的。redo log记录了数据的修改日志。数据要持久化到硬盘,先是储存到缓冲池中,然后缓冲池中的数据定期同步到磁盘中,如果系统宕机,可能会丢失数据,系统重启后会读取redo log恢复记录。 - 隔离性:mysql数据库通过
MVCC + next-key锁机制实现隔离性。 - 一致性:上面3大特性,保证了事务的一致性。
11、Binlog 和 Redo log 的区别是什么,分别是什么用?
binlog是二进制文件,记录了对数据库更改的所有操作,不包括select, show操作,因为这两个操作没有对数据本身做修改。但是若操作了数据,但数据没变化,也会记录到binlog。常用来数据恢复,数据备份。
redo log又叫重做日志文件,记录了事务的修改,不管事务是否提交都记录下来。在实例和介质失败时,InnoDB存储引擎会根据redo log恢复到之前的状态,保证数据的完整性。
必须了解的mysql三大日志-binlog、redo log和undo log:https://segmentfault.com/a/1190000023827696
12、谈一谈 MVCC 多版本并发控制
MVCC是通过在每行记录后面增加两个列实现的。这两个列,一个保存了行的创建时间,一个保存了行的删除时间。存储的并不是真正的时间,而是系统版本号(System Version Number)。每开始一个新的事务,系统版本号都会递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。
- select
InnoDB会根据下面两个条件检查每行记录
(1)InnoDB只查找版本号小于或等于当前事务版本号的行,这样可以确保事务读取的行,要么是在事务开始之前就已经存在的,要么是事务自身插入或修改的。
(2)行的删除版本号要么未定义,要么大于当前事务版本号。这样可以确保事务读取到的行,在事务开始之前未被删除。
只有符合上述两个条件的记录,才会作为查询结果返回。
-
insert
InnoDB为插入的每一行保存当前系统版本号作为行版本号。 -
delete
InnoDB为删除的每一行保存当前系统版本号作为行删除标识。 -
update
InnoDB插入一行新纪录,保存当前系统版本号作为行版本号,同时保存当前系统版本号到原来的行作为行删除标识。
13、Innodb 和 MyISAM 的区别是什么
(1)InnoDB支持事务,MyISAM不支持。
(2)InnoDB支持外键,MyISAM不支持。
(3)InnoDB主键索引的叶子节点存储的是数据文件,辅助索引的叶子节点是主键的值。MyISAM的主键索引和辅助索引,叶子节点存储的都是数据文件的指针。
(4)InnoDB不保存表的行数,执行 select count(*) from tb需要全表扫描。MyISAM 用一个变量保存了整个表的行数,执行上述语句只需要读取该变量,速度很快。
(5)InnoDB所有的表在磁盘上保存在一个文件,MyISAM存储在三个文件。
(6)InnoDB需要更多的内存和存储,MyISAM可被压缩,存储空间较小。
(7)Innodb 移植方案拷贝文件、备份 binlog,或者用 mysqldump,移植较困难。MyISAM 数据以文件形式存储,在备份和回复时可以单独针对表进行操作。
(8)InnoDB支持行锁,表锁,MyISAM支持表锁。
(9)Innodb 在5.7版本之前不支持全文索引。MyISAM 支持全文索引。
14、Innodb 的默认加锁方式是什么,是怎么实现的
InnoDB的默认加锁方式是行级锁,通过给索引上的索引项加锁来实现的。
15、如何高效处理大库 DDL
DDL是指数据定义语句,即建表、建视图这种。比如数据字段的定义,遵循从小原则。表的创建,降低耦合。
16、Mysql 索引重建
(1)mysqldump导出然后重新导入,drop index + recreate index
(2)alter table xxx ENGINE = InnoDB
(3)repaire table xxx,这种对于InnoDB的无效
(4)OPTIMIZE TABLE xxx
17、对于多列索引,哪些情况下能用到索引,哪些情况用不到索引
(1)like以%开头
(2)or查询,必须左右字段都是索引,否则索引失效
(3)联合索引,遵从最左匹配原则,如果不是使用第一列索引,索引失效
(4)数据出现隐形转换,如varchar字段没加单引号,自动转为int类型,会使索引失效
(5)索引字段使用not、<>、!=,索引失效
(6)索引字段使用函数,索引无效
18、为什么使用数据库索引可以提高效率,在什么情况下会用不到数据库索引?
默认执行sql语句是进行全表扫描,遇到匹配条件的就加入搜索结果集。如果有索引,就会去索引表中一次定位到特定值的行数,减少遍历匹配的次数。索引把无序的数据变成了相对有序的数据结构。
用不到索引的情况,如上题。
19、共享锁和排它锁的使用场景
更新、新增、删除默认加排它锁,查询默认不加锁。
共享锁:使用语法select * from tb lock in share mode,自身可以读,其他事务也可以读(也可以继续加共享锁),但是其他事务无法修改。
排它锁:使用语法select * from tb for update,自身可以进行增删改查,其他事务无法进行任何操作。
20、关系型数据库和非关系数据库的优缺点
(1)关系型数据库
-
优点:
二维表格,容易理解。
容易操作。
易于维护。
支持SQL。 -
缺点:
读写性能较差。
固定的表结构,不够灵活。
应对高并发场景,磁盘I/O存在瓶颈。
海量数据的读写性能差。
(2)非关系型数据库
-
优点:
不需要SQL解析,读写性能高。
可以使用内存或者硬盘作为载体,速度快。
基于键值对,数据没有耦合性,方便扩展。
部署简单。 -
缺点:
不支持SQL,增加了学习成本。
没有事务。
21、Mysql 什么情况会造成慢查,如何查看慢查询
响应时间超过阈值会产生慢查询日志。一般以下情况会造成慢查询。
(1)没有设置索引,或者查询没有用到索引。
(2)I/O吞吐量过小。
(3)内存不足。
(4)网络不好。
(5)查询的数据量过大。
(6)锁或者死锁。
(7)返回了不必要的行或列。
(8)查询语句存在问题,需要优化。
慢查询日志默认是关闭的,如果非必要,不要开启,会影响性能。
使用SHOW VARIABLES LIKE 'slow_query%';
slow_query_log,慢查询开启关闭状态
slow_query_log_file,慢查询日志存储位置,用文本编辑器打开存储位置的文件,查询慢查询
22、如何处理慢查询,你一般是怎么处理慢查询的
(1)把数据、日志、索引放到不同的I/O设备上,增加读取速度。
(2)纵向、横向分割表,减少表的尺寸。
(3)升级硬件。
(4)根据查询条件,建立索引,索引优化。
(5)提高网速。
(6)扩大服务器内存。
(7)分库分表。
23、Mysql 中 varchar 和 char 的区别
varchar会根据存储的内容改变长度,char是定长,如果长度不够,则使用空格补齐。
24、数据库外键的优缺点
优点:
(1)能最大限度的保证数据的一致性和完整性。
(2)增加ER图的可读性。
缺点:
(1)影响数据操作的效率。
(2)增加开发难度,导致表过多。
25、有没有使用过数据库的视图
使用 create view view_name as select * from tb创建视图。
使用create or replace view view_name as select * from tb修改视图。
使用select * from view_name正常查询视图。
使用drop view view_name删除视图。
数据库–视图的基本概念以及作用:https://blog.csdn.net/buhuikanjian/article/details/53105416
26、Mysql 中插入数据使用自增 id 好还是使用 uuid,为什么?
(1)单实例或者单节点组,不担心网络爬虫获取数据量,推荐使用自增ID,性能更好。
(2)分布式场景,20个节点下的小规模分布式场景,推荐uuid。20~200个节点的中规模分布式场景,推荐自增ID + 步长的策略。200以上节点,推荐雪花算法的全局自增ID。
27、Mysql 有哪些数据类型,使用的时候有没有什么注意点
(1)整数类型:BIT、BOOL、TINY INT、SMALL INT、MEDIUM INT、INT、BIG INT。
(2)浮点数类型:FLOAT、DOUBLE、DECIMAL。
(3)字符串类型:CHAR、VARCHAR、TINY TEXT、TEXT、MEDIUM TEXT、LONGTEXT、TINY BLOB、MEDIUM BLOB、LONG BLOB。
(4)日期类型:DATE、DATETIME、TIMESTAMP、TIME、YEAR
使用的时候建议遵循从小原则。
(1)使用char或者varchar的时候,注意char会去掉字符串末尾的空格。
(2)使用text或者blob的时候,注意定期清理碎片空间,使用OPTIMIZE TABLE命令。
(3)浮点数会造成精度丢失,尽量使用decimal。
28、Mysql 集群有哪几种方式,分别适用于什么场景
(1)组建MySQL集群的方式:
LVS + Keepalived + MySQL
DRBD + Heartbeat + MySQL
MySQL + Proxy
MySQL Cluster
MySQL + MHA
MySQL + MMM
(2)场景:
如果是双主复制,不需要数据拆分,可以使用MHA或Keepalived或Heartbeat
如果是双主复制,需要数据拆分,采用Cobar
如果是双主复制+Slave,还做了数据拆分,需要读写分离,采用Amoeba
29、Mysql 主从模式如何保证主从强一致性
主从复制原理:master写数据留下写入日志,slave根据master留下的日志模仿数据执行过程写入。
这个过程有两个地方可能导致主从数据不一致:
(1)master写日志不成功。
(2)slave根据日志模仿数据不成功。
解决方法:
(1)master上修改配置
innodb_flush_log_at_trx_commit = 1
sync_binlog = 1
上述两个选项的作用是:保证每次事务提交后,都能实时刷新到磁盘中,尤其是确保每次事务对应的binlog都能及时刷新到磁盘中。
(2)slave上修改配置
master_info_repository = "TABLE"
relay_log_info_repository = "TABLE"
relay_log_recovery = 1
上述前两个选项的作用是:确保在slave上和复制相关的元数据表也采用InnoDB引擎,受到InnoDB事务安全的保护,而后一个选项的作用是开启relay log自动修复机制,发生crash时,会自动判断哪些relay log需要重新从master上抓取回来再次应用,以此避免部分数据丢失的可能性。
30、Mysql 集群如何保证主从可用性
使用HA检测工具,HA工具部署在第三台服务器上,同时连接主从,检测主从是否存活。如果主库宕机则及时将从库升级为主库,将原来的主库降级为从库。
31、Mysql 读写分离有哪些解决办法
(1)配置多数据源。
(2)使用中间件代理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号