
转载tcptrace cwnd问题
转载自https://www.kawabangga.com/posts/5217

途中,每根竖线的高度可以理解为一次性发送的数据多少:第一个请求中(图中第一次升高),一开始慢慢发,越发越快,这是因为 TCP 要避免出现拥塞,所以在链接刚建立的时候会 slow start,慢慢发送,如果网络能接受,就逐渐加大发送的速度,如果发生拥塞控制了(不通的拥塞控制算法不通,cubic 使用丢包来作为拥塞控制事件)就降低发送的速度。所以开始的时候 cwnd 拥塞控制窗口在慢慢打开。其中,绿线 rwnd 并不是瓶颈,它看起来比较低,是因为我抓包的时候 TCP 连接已经存在了,没有抓到 SYN 包,所以 wireshark 并不知道 window scaling factor 是多少。
但是!!为什么 2 秒之后,在发送第二个请求的时候,这个竖线的高度又从很小开始了呢?这可是同一个 TCP 连接呀,没有重建。并且也没有丢包和重传。
我以前理解的拥塞控制算法 cubic,只会在发生拥塞事件的时候缩小 cwnd。所以我以为我看错了,但是切换到 window scaling 视图,发现 cwnd 确实每个请求都会 reset。
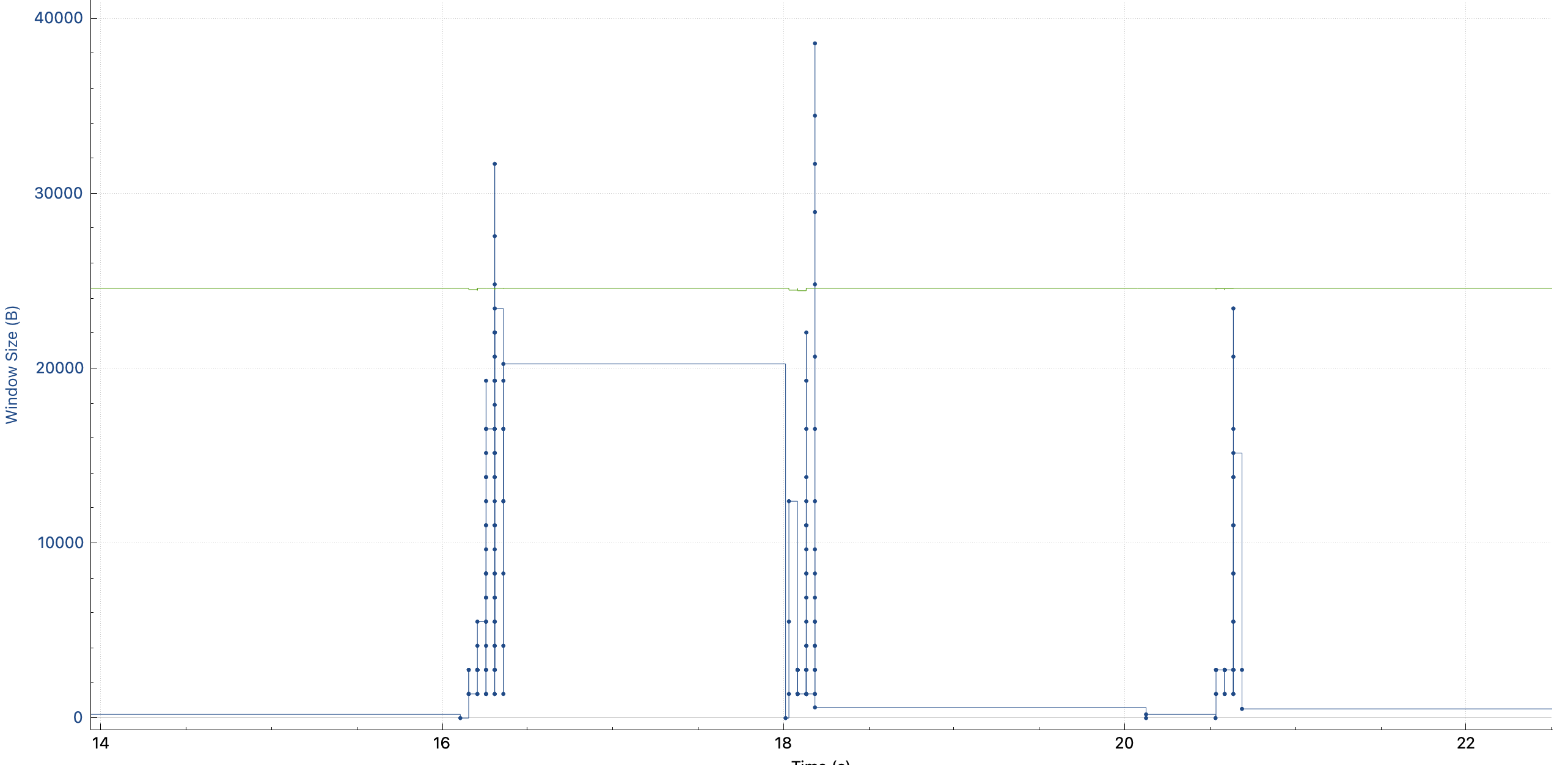
这跟我所理解的拥塞控制算法不一样!于是我搜索“why my cwnd reduced without retrans“,却几乎没有看到有用的信息。
甚至从这个回答里确认:cubic 在 idle 的时候不会 reset cwnd。这个回答倒提到了可能是应用的问题。
写了一个循环,使用 ss 一直打印出来这个连接的 cwnd 值:
while true; do ss -i | grep 172.16.1.1 -A 1; sleep 0.1; done
从这个命令的输出中,成功地复现了问题!排出了我们平台代码的问题:
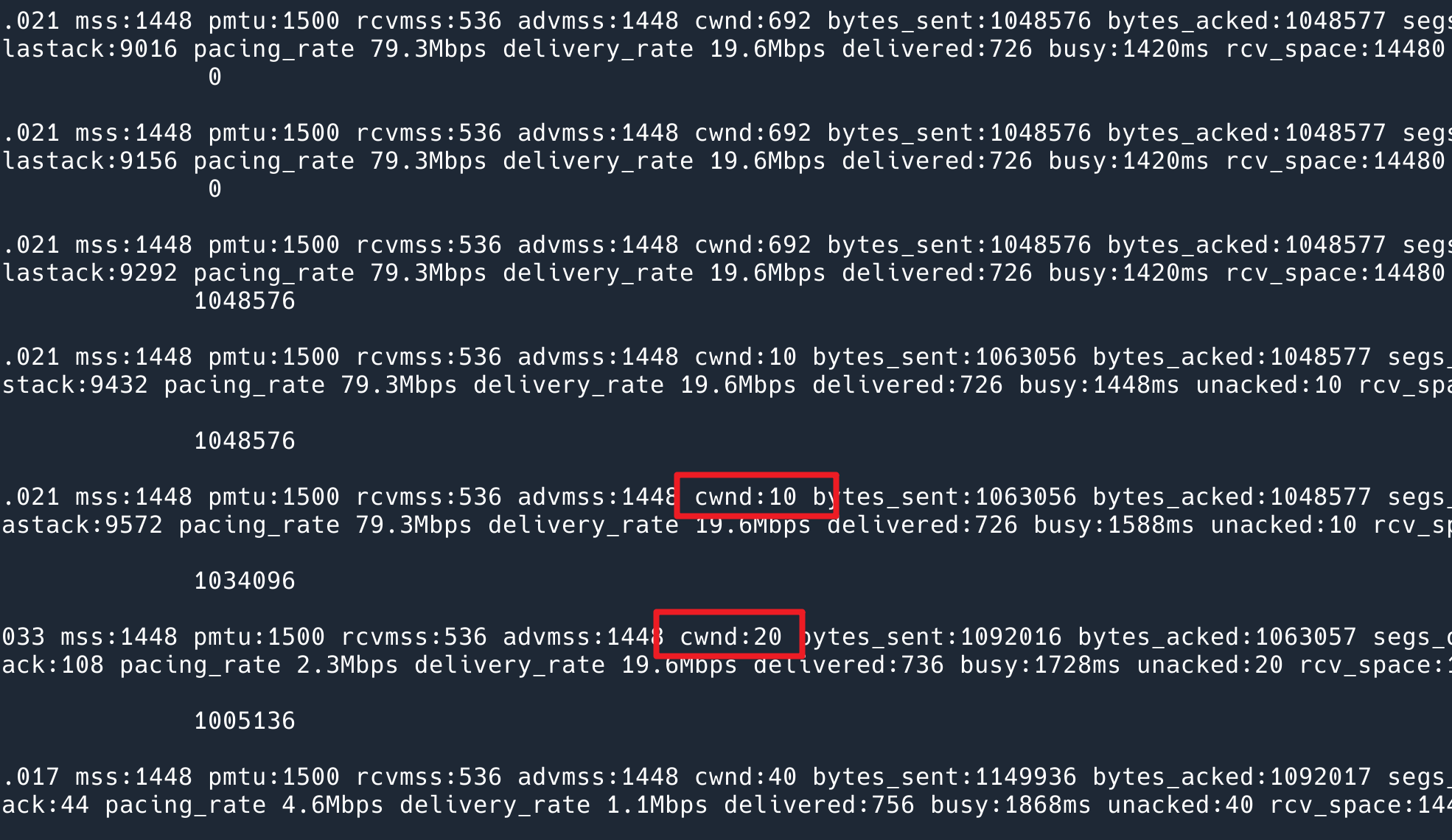
到这里我开始怀疑是 SDN 的问题了,为了验证,我去一个简单的网络环境,纯物理网,重新跑了一次我的代码,发现 cwnd 没有重置,说明就是 SDN 的问题。
于是叫来一个网络组的同事,给他看了这个。结果他也感觉很惊讶(再次卖个关子,不是只有我一个人不知道这个行为,有了些许安慰)。认为这不应该发生。但是他又对他们的代码很有信心,认为这不可能是是 SDN 的问题。然后他突然说,这应该是网络延迟造成的问题,SDN 所在的环境本身有 50ms 的延迟,我测试的物理网却没有。
于是我去找了一个有 100ms 延迟的物理网环境测试,结果……果然不是 SDN 的问题,观察到了一模一样的现象。
这时候已经进入到未知领域了。我去打开了 chatGPT 这个废物,它说是拥塞控制算法在 idle 之后会降低 cwnd。多新鲜呐,从没听说过。
我们的拥塞控制算法就用的 cubic,于是我和这个网络的同事一起去看了 cubic 的代码。如果能看到这逻辑的话,也就一切就说得通了。
看了半天,只有几百行,又是用 eBPF 探测又是测试的,愣是没找到这个会 idle 的时候 reset cwnd 的逻辑。感觉进入了死胡同,在网上搜 cubic reset cwnd when idle 也是徒劳无功。
同事想到一个点子:我们换成 BBR,看是否可以解决问题?!
从现象来看,BBR 速度快很多。原本以为问题解决了,但是看了下我的脚本的输出,发现其实问题依然是存在的,发送完数据之后 cwnd 会降到 4,只不过 BBR window scaling 非常快,一开始发数据蹭就跳到 1384 了。
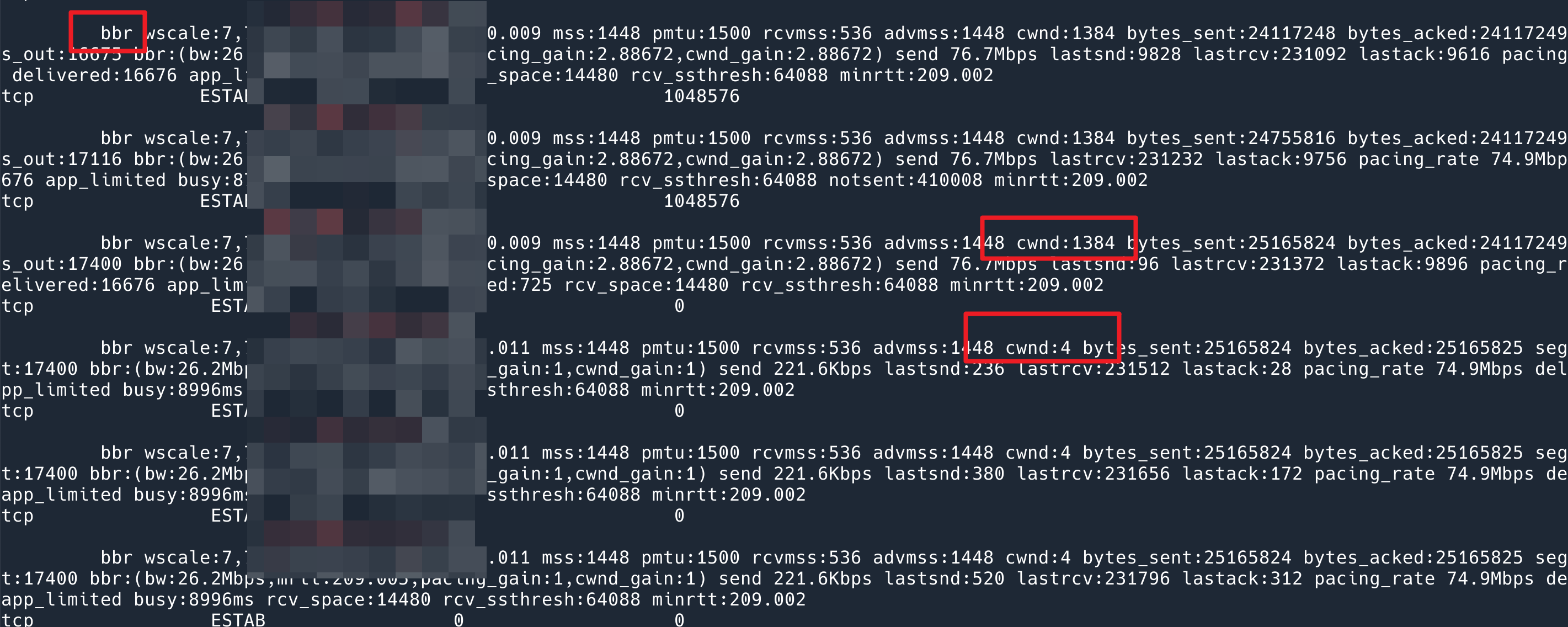
不过这倒是提醒我了:要么就是所有的算法都实现了这个 reset cwnd when idle 的鬼逻辑,要么,这根本不是算法实现的,而是系统实现的!
考虑到看了一下午 cubic 的代码了,我更倾向于后者。
接下来该怎么做呢?总不能把协议栈的代码看一遍吧。
这时我靠直觉做了一个动作,我把系统 TCP 相关的配置打印出来,sysctl -a | grep tcp ,想看看有没有线索,结果一个 net.ipv4.tcp_slow_start_after_idle 直接就点醒了我。这不就正是我们遇到的问题么?
我把它改成 0,问题就完全解决了:
|
1
2
|
$ sysctl -w net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_slow_start_after_idle = 0
|
后面再观测 cwnd,稳定在 1000 左右。
有了这个行为,我再去寻找这么做的原因就简单了。
RFC2414 里面提到:
TCP 需要在 3 种情况用到 slow start(从这个表述也可以看出,slow_start_after_idle 不是拥塞控制算法应该做的,拥塞控制算法要做的是实现 slow start,TCP 的实现是使用 slow start):
- 连接刚刚建立的时候 (Initial Window)
- 连接在 idle 一段时间之后,重新启动的时候 (Restart Window)
- 发生丢包的时候 (Loss Window)
那么为什么需要 (2) idle 后要 slow start 呢?我找到了 RFC 5681,有关 “Restarting Idle Connections“ 的部分,大意是:
拥塞控制算法使用收到的 ACK 来确认网络质量从而避免拥塞,但是在 idle 了一段时间之后,没有 ACK 在传输,拥塞控制算法所保存的状态可能已经不能反映此时的网络情况了,比如发送了一波数据,直到发送完成的时候网络都比较空闲,然后连接 idle 了 10s,又要开始发数据,此时网络恰好负载比较高,如果 TCP 使用 10s 之前的知识去重新开始发送数据的话,就会造成拥塞;另外,10s 之后即使网络负载没变,网络环境可能变了(路由表切换之类的?),同样会造成 10s 之前的知识已经不适用了。
所以,这个 RFC 里面定义:
在 RTO(Retransmission Timeouts) 时间内,如果发送端没有发送任何 segment 出去,那么下次发送数据的时候,cwnd 要降低到 RW(Restart Window, RW = min(IW,cwnd)).
到此,以上的行为就解释的通了。
那么解决方法呢?因为这个参数是 by network namespace 的,我们打算在高延迟的网络中对我们这个进程关闭这个参数。
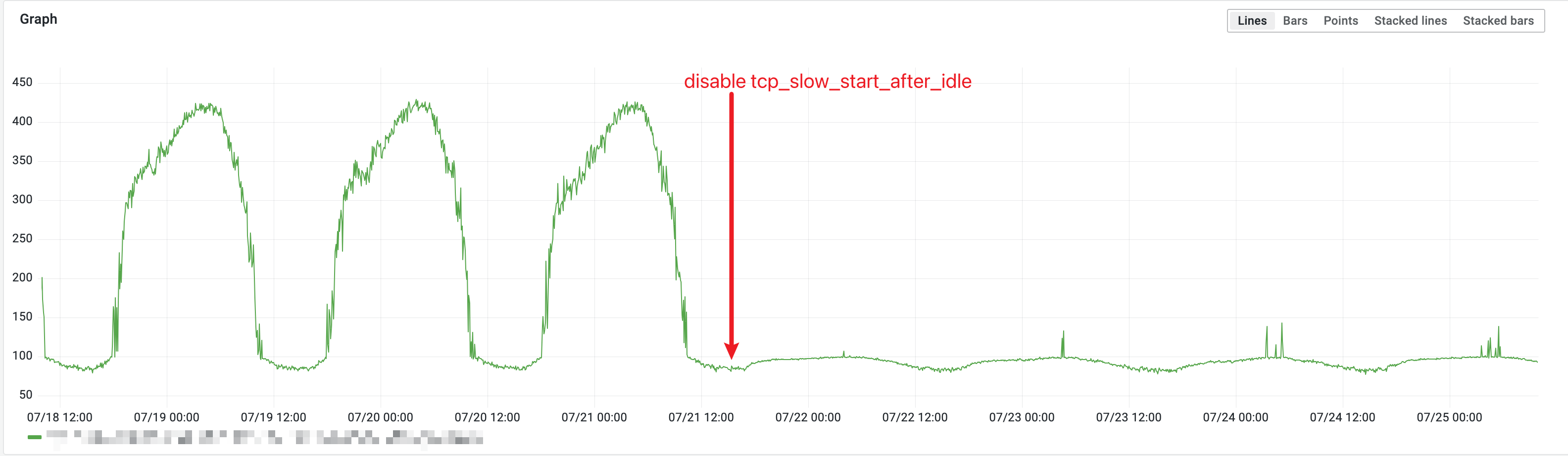
tcp_slow_start_after_idle 的效果,可以看到在业务低峰,QPS 比较低的情况下,延迟有很大改善另一个思路是,既然 TCP 连接在 idle 的时候会 reset,那么我一直在这个连接上发送数据,不让它达到 idle 的条件,那么自然就不会被 reset cwnd 了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号