gin-net-http 转载
package main
import (
"net/http"
"github.com/gin-gonic/gin"
)
func main() {
r := gin.Default()
r.GET("/", func(c *gin.Context) {
c.String(200, "Hello!!!!")
})
r.Run()
}gin框架使用的是定制版本的httprouter,其路由的原理是大量使用公共前缀的树结构,它基本上是一个紧凑的Trie tree(或者只是Radix Tree)。具有公共前缀的节点也共享一个公共父节点。
获取请求方法树
在gin的路由中,每一个HTTP Method(GET、POST、PUT、DELETE…)都对应了一棵 radix tree,我们注册路由的时候会调用下面的addRoute函数:
func (group *RouterGroup) handle(httpMethod, relativePath string, handlers HandlersChain) IRoutes {
absolutePath := group.calculateAbsolutePath(relativePath)
handlers = group.combineHandlers(handlers)
group.engine.addRoute(httpMethod, absolutePath, handlers)
return group.returnObj()
}
func (engine *Engine) addRoute(method, path string, handlers HandlersChain) {
assert1(path[0] == '/', "path must begin with '/'")
assert1(method != "", "HTTP method can not be empty")
assert1(len(handlers) > 0, "there must be at least one handler")
debugPrintRoute(method, path, handlers)
// 获取请求方法对应的树
root := engine.trees.get(method)
if root == nil {// 如果没有就创建一个
root = new(node)
root.fullPath = "/"
engine.trees = append(engine.trees, methodTree{method: method, root: root})
}
root.addRoute(path, handlers)
// Update maxParams
if paramsCount := countParams(path); paramsCount > engine.maxParams {
engine.maxParams = paramsCount
}
if sectionsCount := countSections(path); sectionsCount > engine.maxSections {
engine.maxSections = sectionsCount
}
}在注册路由的时候都是先根据请求方法获取对应的树,也就是gin框架会为每一个请求方法创建一棵对应的树,gin框架中保存请求方法对应树关系使用的是slice;engine.trees的类型是methodTrees,其定义如下:
type methodTree struct {
method string
root *node
}
type methodTrees []methodTree获取请求方法对应树的get方法定义如下:---------->HTTP请求方法的数量是固定的,而且常用的就那几种,所以即使使用切片存储查询起来效率也足够了
func (trees methodTrees) get(method string) *node {
for _, tree := range trees {
if tree.method == method {
return tree.root
}
}
return nil
}所以tress初始化的时候就直接make申请了内存
func New() *Engine {
debugPrintWARNINGNew()
engine := &Engine{
RouterGroup: RouterGroup{
Handlers: nil,
basePath: "/",
root: true,
},
FuncMap: template.FuncMap{},
RedirectTrailingSlash: true,
RedirectFixedPath: false,
HandleMethodNotAllowed: false,
ForwardedByClientIP: true,
RemoteIPHeaders: []string{"X-Forwarded-For", "X-Real-IP"},
TrustedPlatform: defaultPlatform,
UseRawPath: false,
RemoveExtraSlash: false,
UnescapePathValues: true,
MaxMultipartMemory: defaultMultipartMemory,
// 初始化容量为9的切片(HTTP1.1请求方法共9种)
trees: make(methodTrees, 0, 9),
delims: render.Delims{Left: "{{", Right: "}}"},
secureJSONPrefix: "while(1);",
trustedProxies: []string{"0.0.0.0/0", "::/0"},
trustedCIDRs: defaultTrustedCIDRs,
}
engine.RouterGroup.engine = engine
engine.pool.New = func() any {
return engine.allocateContext(engine.maxParams)
}
return engine
}
获取请求方法树后---->执行注册路由
先看下路由树节点
路由树是由一个个节点构成的,gin框架路由树的节点由node结构体表示,它有以下字段:
r.GET("/search/", func2)
r.GET("/support/", func3)
type node struct {
path string// 节点路径,比如上面的s,earch,和upport
// 和children字段对应, 保存的是分裂的分支的第一个字符
// 例如search和support, 那么s节点的indices对应的"eu"
// 代表有两个分支, 分支的首字母分别是e和u
indices string
wildChild bool
// 节点类型,包括static, root, param, catchAll
// static: 静态节点(默认),比如上面的s,earch等节点
// root: 树的根节点
// catchAll: 有*匹配的节点
// param: 参数节点
nType nodeType
// 优先级,子节点、子子节点等注册的handler数量
priority uint32
children []*node // child nodes, at most 1 :param style node at the end of the array
handlers HandlersChain// 处理函数chain(切片)
fullPath string// 完整路径
}注册路由的逻辑主要有addRoute函数和insertChild方法。
root := engine.trees.get(method)
root.addRoute(path, handlers)
// addRoute adds a node with the given handle to the path.
// Not concurrency-safe!
func (n *node) addRoute(path string, handlers HandlersChain) {
fullPath := path
n.priority++
// Empty tree 空树就直接插入当前节点
if len(n.path) == 0 && len(n.children) == 0 {
n.insertChild(path, fullPath, handlers)
n.nType = root
return
}
parentFullPathIndex := 0
walk:
for {
// Find the longest common prefix.
// This also implies that the common prefix contains no ':' or '*'
// since the existing key can't contain those chars.
// 找到最长的通用前缀
// 这也意味着公共前缀不包含“:”"或“*” /
// 因为现有键不能包含这些字符。
i := longestCommonPrefix(path, n.path)
// Split edge
// 分裂边缘(此处分裂的是当前树节点)
// 例如一开始path是search,新加入support,s是他们通用的最长前缀部分
// 那么会将s拿出来作为parent节点,增加earch和upport作为child节点
if i < len(n.path) {
child := node{
path: n.path[i:], // 公共前缀后的部分作为子节点
wildChild: n.wildChild,
nType: static,
indices: n.indices,
children: n.children,
handlers: n.handlers,
priority: n.priority - 1,//子节点优先级-1
fullPath: n.fullPath,
}
n.children = []*node{&child}
// []byte for proper unicode char conversion, see #65
n.indices = bytesconv.BytesToString([]byte{n.path[i]})
n.path = path[:i]
n.handlers = nil
n.wildChild = false
n.fullPath = fullPath[:parentFullPathIndex+i]
}
// Make new node a child of this node
// 将新来的节点插入新的parent节点作为子节点
if i < len(path) {
path = path[i:]
c := path[0]
// '/' after param 处理参数后加斜线情况
if n.nType == param && c == '/' && len(n.children) == 1 {
parentFullPathIndex += len(n.path)
n = n.children[0]
n.priority++
continue walk
}
// Check if a child with the next path byte exists
// 检查路path下一个字节的子节点是否存在
// 比如s的子节点现在是earch和upport,indices为eu
// 如果新加一个路由为super,那么就是和upport有匹配的部分u,将继续分列现在的upport节点
for i, max := 0, len(n.indices); i < max; i++ {
if c == n.indices[i] {
parentFullPathIndex += len(n.path)
i = n.incrementChildPrio(i)
n = n.children[i]
continue walk
}
}
// Otherwise insert it 否则就插入
if c != ':' && c != '*' && n.nType != catchAll {
// []byte for proper unicode char conversion, see #65
// 注意这里是直接拼接第一个字符到n.indices
n.indices += bytesconv.BytesToString([]byte{c})
child := &node{
fullPath: fullPath,
}
// 追加子节点
n.addChild(child)
n.incrementChildPrio(len(n.indices) - 1)
n = child
} else if n.wildChild {// 如果是参数节点
// inserting a wildcard node, need to check if it conflicts with the existing wildcard
n = n.children[len(n.children)-1]
n.priority++
// Check if the wildcard matches 检查通配符是否匹配
if len(path) >= len(n.path) && n.path == path[:len(n.path)] &&
// Adding a child to a catchAll is not possible
n.nType != catchAll &&
// Check for longer wildcard, e.g. :name and :names
(len(n.path) >= len(path) || path[len(n.path)] == '/') {
continue walk
}
// Wildcard conflict
pathSeg := path
if n.nType != catchAll {
pathSeg = strings.SplitN(pathSeg, "/", 2)[0]
}
prefix := fullPath[:strings.Index(fullPath, pathSeg)] + n.path
panic("'" + pathSeg +
"' in new path '" + fullPath +
"' conflicts with existing wildcard '" + n.path +
"' in existing prefix '" + prefix +
"'")
}
n.insertChild(path, fullPath, handlers)
return
}
// Otherwise add handle to current node 已经注册过的节点
if n.handlers != nil {
panic("handlers are already registered for path '" + fullPath + "'")
}
n.handlers = handlers
n.fullPath = fullPath
return
}
}- 第一次注册路由,例如注册search
- 继续注册一条没有公共前缀的路由,例如blog
- 注册一条与先前注册的路由有公共前缀的路由,例如support

insertChild函数是根据path本身进行分割,将/分开的部分分别作为节点保存,形成一棵树结构。参数匹配中的:和*的区别是,前者是匹配一个字段而后者是匹配后面所有的路径。
func (n *node) insertChild(path string, fullPath string, handlers HandlersChain) {
for {
// Find prefix until first wildcard 查找前缀直到第一个通配符
wildcard, i, valid := findWildcard(path)
if i < 0 { // No wildcard found
break
}
// The wildcard name must only contain one ':' or '*' character
// 通配符的名称必须包含':' 和 '*'
if !valid {
panic("only one wildcard per path segment is allowed, has: '" +
wildcard + "' in path '" + fullPath + "'")
}
// check if the wildcard has a name 检查通配符是否有名称
if len(wildcard) < 2 {
panic("wildcards must be named with a non-empty name in path '" + fullPath + "'")
}
if wildcard[0] == ':' { // param
if i > 0 {// 在当前通配符之前插入前缀
// Insert prefix before the current wildcard
n.path = path[:i]
path = path[i:]
}
child := &node{
nType: param,
path: wildcard,
fullPath: fullPath,
}
n.addChild(child)
n.wildChild = true
n = child
n.priority++
// if the path doesn't end with the wildcard, then there
// will be another subpath starting with '/'
// 如果路径没有以通配符结束
// 那么将有另一个以'/'开始的非通配符子路径。
if len(wildcard) < len(path) {
path = path[len(wildcard):]
child := &node{
priority: 1,
fullPath: fullPath,
}
n.addChild(child)
n = child
continue
}
// Otherwise we're done. Insert the handle in the new leaf
// 否则我们就完成了。将处理函数插入新叶子中
n.handlers = handlers
return
}
// catchAll
if i+len(wildcard) != len(path) {
panic("catch-all routes are only allowed at the end of the path in path '" + fullPath + "'")
}
if len(n.path) > 0 && n.path[len(n.path)-1] == '/' {
pathSeg := strings.SplitN(n.children[0].path, "/", 2)[0]
panic("catch-all wildcard '" + path +
"' in new path '" + fullPath +
"' conflicts with existing path segment '" + pathSeg +
"' in existing prefix '" + n.path + pathSeg +
"'")
}
// currently fixed width 1 for '/'
i--
if path[i] != '/' {
panic("no / before catch-all in path '" + fullPath + "'")
}
n.path = path[:i]
// First node: catchAll node with empty path
// 第一个节点:路径为空的catchAll节点
child := &node{
wildChild: true,
nType: catchAll,
fullPath: fullPath,
}
n.addChild(child)
n.indices = string('/')
n = child
n.priority++
// second node: node holding the variable
// 第二个节点:保存变量的节点
child = &node{
path: path[i:],
nType: catchAll,
handlers: handlers,
priority: 1,
fullPath: fullPath,
}
n.children = []*node{child}
return
}
// If no wildcard was found, simply insert the path and handle
// 如果没有找到通配符,只需插入路径和句柄
n.path = path
n.handlers = handlers
n.fullPath = fullPath
}
路由匹配--->accept--->ServeHTTP 回调进入路由匹配
// ServeHTTP conforms to the http.Handler interface.
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
// 这里使用了对象池
c := engine.pool.Get().(*Context)
// Get对象后做初始化
c.writermem.reset(w)
c.Request = req
c.reset()
// 处理HTTP请求的函数
engine.handleHTTPRequest(c)
// 处理完请求后将对象放回池子
engine.pool.Put(c)
}func (engine *Engine) handleHTTPRequest(c *Context) {
httpMethod := c.Request.Method
rPath := c.Request.URL.Path
--------------------
// Find root of the tree for the given HTTP method
t := engine.trees
for i, tl := 0, len(t); i < tl; i++ {
if t[i].method != httpMethod {
continue
}
root := t[i].root
// Find route in tree
value := root.getValue(rPath, c.params, c.skippedNodes, unescape)
if value.params != nil {
c.Params = *value.params
}
if value.handlers != nil {
c.handlers = value.handlers
c.fullPath = value.fullPath
c.Next()
c.writermem.WriteHeaderNow()
return
}
-------------
}
----------------
c.handlers = engine.allNoRoute
serveError(c, http.StatusNotFound, default404Body)
}路由匹配是由节点的 getValue方法实现的。getValue根据给定的路径(键)返回nodeValue值,保存注册的处理函数和匹配到的路径参数数据。
如果找不到任何处理函数,则会尝试TSR(尾随斜杠重定向)
方法函数与中间件函数的执行在c.Next()函数中,即遍历到URI后,它会执行里面对应的[]HandlerFunc各个函数。
gin框架中间件详解
gin框架涉及中间件相关有4个常用的方法,它们分别是c.Next()、c.Abort()、c.Set()、c.Get()
中间件的注册
gin框架中的中间件设计很巧妙,我们可以首先从我们最常用的r := gin.Default()的Default函数开始看,它内部构造一个新的engine之后就通过Use()函数注册了Logger中间件和Recover
// Default returns an Engine instance with the Logger and Recovery middleware already attached.
func Default() *Engine {
debugPrintWARNINGDefault()
engine := New()
engine.Use(Logger(), Recovery())// 默认注册的两个中间件
return engine
}// Use attaches a global middleware to the router. i.e. the middleware attached through Use() will be
// included in the handlers chain for every single request. Even 404, 405, static files...
// For example, this is the right place for a logger or error management middleware.
func (engine *Engine) Use(middleware ...HandlerFunc) IRoutes {
engine.RouterGroup.Use(middleware...)
engine.rebuild404Handlers()
engine.rebuild405Handlers()
return engine
}
// Use adds middleware to the group, see example code in GitHub.
func (group *RouterGroup) Use(middleware ...HandlerFunc) IRoutes {
group.Handlers = append(group.Handlers, middleware...)//注册中间件其实就是将中间件函数追加到group.Handlers中
return group.returnObj()
}注册中间件其实就是将中间件函数追加到group.Handlers中;
而我们注册路由时会将对应路由的函数和之前的中间件函数结合到一起:
func (group *RouterGroup) handle(httpMethod, relativePath string, handlers HandlersChain) IRoutes {
absolutePath := group.calculateAbsolutePath(relativePath)
//路由的中间件函数和处理函数结合到一起组成一条处理函数链条HandlersChain,而它本质上就是一个由HandlerFunc组成的切片:
handlers = group.combineHandlers(handlers) // 将处理请求的函数与中间件函数结合
group.engine.addRoute(httpMethod, absolutePath, handlers)
return group.returnObj()
}
const abortIndex int8 = math.MaxInt8 / 2
func (group *RouterGroup) combineHandlers(handlers HandlersChain) HandlersChain {
finalSize := len(group.Handlers) + len(handlers)
assert1(finalSize < int(abortIndex), "too many handlers")
mergedHandlers := make(HandlersChain, finalSize)
copy(mergedHandlers, group.Handlers)
copy(mergedHandlers[len(group.Handlers):], handlers)
return mergedHandlers
}路由的中间件函数和处理函数结合到一起组成一条处理函数链条HandlersChain,而它本质上就是一个由HandlerFunc组成的切片:
中间件的执行
value := root.getValue(rPath, c.Params, unescape)
if value.handlers != nil {
c.handlers = value.handlers
c.Params = value.params
c.fullPath = value.fullPath
c.Next() // 执行函数HandlersChain
//这里通过索引遍历HandlersChain链条,从而实现依次调用该路由的每一个函数(中间件或处理请求的函数)。
c.writermem.WriteHeaderNow()
return
}
// Next should be used only inside middleware.
// It executes the pending handlers in the chain inside the calling handler.
// See example in GitHub.
func (c *Context) Next() {
c.index++
//这里通过索引遍历HandlersChain链条,从而实现依次调用该路由的每一个函数(中间件或处理请求的函数)。
for c.index < int8(len(c.handlers)) {
c.handlers[c.index](c)
c.index++
}
}So可以在中间件函数中通过再次调用c.Next()实现嵌套调用(func1中调用func2;func2中调用func3),
方法函数的执行按照[]HandlerFunc的顺序,但是如果遇到c.Next(),它的执行顺序如下:
- 当遇到
c.Next(),会执行[]HandlerFunc的下一个函数,然后按照[]HandlerFunc一直执行到底再返回到c.Next()函数的部分执行; - 当遇到
c.Abort()时,后续的[]HandlerFunc不会执行。
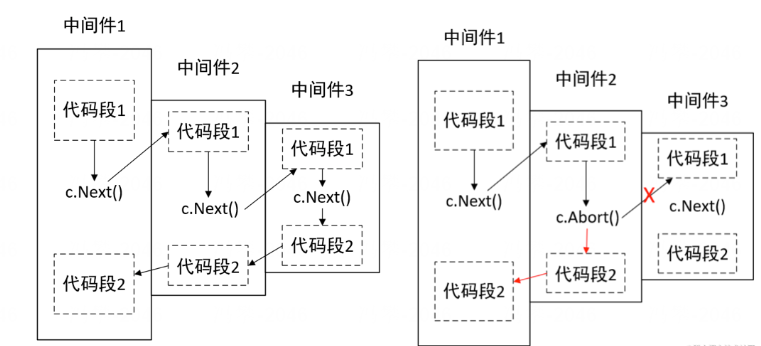
或者通过调用c.Abort()中断整个调用链条,从当前函数返回
// abortIndex represents a typical value used in abort functions.
const abortIndex int8 = math.MaxInt8 >> 1
// Abort prevents pending handlers from being called. Note that this will not stop the current handler.
// Let's say you have an authorization middleware that validates that the current request is authorized.
// If the authorization fails (ex: the password does not match), call Abort to ensure the remaining handlers
// for this request are not called.
func (c *Context) Abort() {
c.index = abortIndex // 直接将索引置为最大限制值,从而退出循环
}
上下文
获取处理请求与响应方法在gin中使用gin.Context类型进行调用。对于每个请求都会创建一个gotouine进行处理,在连接时的请求与响应数据会存在gin.Context中。调用上下文对象可以获取到相应的数据。
gin.Context中的数据是从net/http库中的ResponseWriter和Request中获取的。
c.Set()/c.Get()
c.Set()和c.Get()这两个方法多用于在多个函数之间通过c传递数据的,比如我们可以在认证中间件中获取当前请求的相关信息(userID等)通过c.Set()存入c,然后在后续处理业务逻辑的函数中通过c.Get()来获取当前请求的用户。c就像是一根绳子,将该次请求相关的所有的函数都串起来了。
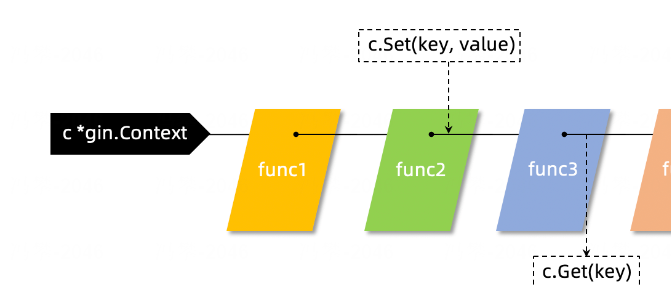
所以:
- gin框架路由使用前缀树,路由注册的过程是构造前缀树的过程,路由匹配的过程就是查找前缀树的过程。
- gin框架的中间件函数和处理函数是以切片形式的调用链条存在的,我们可以顺序调用也可以借助
c.Next()方法实现嵌套调用。 - 借助
c.Set()和c.Get()方法我们能够在不同的中间件函数中传递数据。
请求报文
URL参数
| 方法 | 处理函数 | URL实现 |
|---|---|---|
| c.Param(“id”) == “john” | /user/:id | /user/john |
| c.Query(“id”) == “1234” | /path | /path?id=1234&name=Manu |
| c.QueryArray(“id”) | /queryArr | /queryArr?id=1&id=2 或者 /queryArr?id=1,2 |
| c.QueryMap(“user”) | /queryMap | /queryMap?user[id]=1 |
另外query还带有几种其他方式的获取参数:
DefaultQuery带默认值,若为空则返回默认值;GetQuery返回string和bool值,若为空则bool为true;
x-www-form-urlencoded参数
在Go语言-web与框架-网络协议中有提到,GET请求通常是不带请求体的,在使用表单提交时,它会把数据以application/x-www-form-urlencoded形式拼接到URL后面;POST请求会把数据放到请求体中。使用PostForm可以获取到urlencoded的表单数据。
| 方法 | urlencoded |
|---|---|
| email = c.PostForm(“email”) ➡️ email == mail@example.com | email=mail@example.com |
GetPostForm返回中会多带有一个bool值;DefaultPostForm可以带有一个默认值。
form-data参数
form-data中主要用于提交text和file两种类型,用于POST请求中,它以boundary将请求体分隔成一块一块的。
在gin框架中获取上传的文件时,提供的API有:
FormFile:接收单个文件的上传;MultipartForm:接收多个文件的上传;
RAW参数
gin框架中使用Bind, ShouldBind方法,它会根据Content-Type请求数据类型并利用反射机制自动提取请求中QueryString、form表单、JSON、XML等参数到结构体中。
对于Bind函数,它会调用MustBindWith函数,然后再调用到ShouldBindWith函数;而对于ShouldBind函数,则直接调用ShouldBindWith函数。它们的区别是MustBindWith函数在出错时会返回400的响应。
func (c *Context) MustBindWith(obj interface{}, b binding.Binding) error {
if err := c.ShouldBindWith(obj, b); err != nil {
c.AbortWithError(http.StatusBadRequest, err).SetType(ErrorTypeBind) // nolint: errcheck
return err
}
return nil
}ShouldBindWith函数会按照顺序解析请求完成绑定:
- 如果是
GET请求,只使用Form绑定引擎(query); - 如果是
POST请求,首先检查content-type是否为JSON或XML,然后再使用Form(form-data)
HTTP头部字段
以k-v的存储,紧跟在头部行后面,用于让对方在获取报文主体信息前,提前了解到需要的信息。如果判断到一些条件无法满足可以提前结束,避免不必要的请求与响应。
本文只讨论一些常用的头部字段,关于头部字段的具体说明可以参考:
请求示例:
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36
Host: localhost:1313
Referer: http://localhost:1313/post/golang/gmp01/
Content-Type:x-www-form-urlencoded;
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: en-GB,en-US;q=0.9,en;q=0.8,zh-CN;q=0.7,zh;q=0.6
Connection:keep-alive
Range:bytes=500-999
请求的头字段常用的如下:
| 请求头部 | 说明 |
|---|---|
| User-Agent | 获取身份信息,可用于判断访问者的系统 |
| Host | 服务器的域名端口号 |
| Referer | 浏览器所访问的前一个页面,例如通过页面的超链接跳转 |
| Content-Type | 当有请求体的时候会出现,表示请求体的编码方式 |
| Content-Length | 请求体长度 |
| Accept | 接受响应内容的类型,q代表权重 |
| Accept-Encoding | 客户能处理的页面编码方法,如gzip、compress |
| Accept-Language | 客户能处理的自然语言,如en(英语),zh-cn(简体中文) |
| Connection | 连接类型:是否开启长连接 |
| Range | 仅请求某个实体的一部分 |
| Cookie | 将以前设置的Cookie送回服务器器,可用来作为会话信息 |
| Origin | 发起一个针对跨域资源共享的请求,告诉服务器是从哪个链接过来的 |
| Cache-Control | 用来指定在这次的请求/响应链中的所有缓存机制都必须遵守的指令 |
| Transfer-Encoding | 传输编码方式 |
响应示例:
Server: nginx/1.20.1
Date: Thu, 05 Jan 2023 08:21:35 GMT
Content-Type: text/html
Content-Length: 145
Connection: keep-alive
Location: https://www.chenchaoyi.cn
Content-Disposition:atteachment;filename=“fname.txt”
Access-Control-Allow-Origin:*
响应报文的头部字段
| 头部字段 | 说明 |
|---|---|
| Server | 服务器的信息 |
| Content-Type | 响应体中的编码类型,与请求字段里的Accept相对应 |
| Content-Encoding | 编码方式,与请求字段里的Accept-Encoding相对应 |
| Content-Language | 页面所使用的自然语言,与请求字段里的Accept-Language相对应 |
| Content-Length | 以字节计算的页面长度 |
| Content-Disposition | 客服端访问后下载文件,并建议文件名头部 |
| Content-Range | 响应体中返回的范围,与与请求字段里的Range相对应 |
| Last-Modified | 页面最后被修改的时间和日期,在页面缓存机制中意义重大 |
| Location | 指示客户将请求发送给别处,即重定向到另一个URL |
| Expire | 指定一个时间,超过该时间认为此响应已经过期 |
| Set-Cookie | 服务器希望客户保存一个Cookie |
| Access-Control-Allow-Origin | 指定哪些网站可以参与到跨域资源共享过程中 |
| Transfer-Encoding | 传输编码方式 |
| Trailer | 响应首部,允许发送方在分块发送的消息后面添加额外的元信息 |
传输及编码
浏览器的表单提交支持GET和POST请求,一般来说GET请求提交是不带请求体字段的,而是将传输的数据以application/x-www-form-urlencoded形式拼接到URL后面。而使用POST请求提交时,会将传输数据放在请求体里,且在请求头里的Content-Type字段里定义报文主体的内容传输格式,与其相对的是接收方的Accpet字段。
Content-Type是通过在 <form> 元素中设置正确的 enctype 属性,或是在 <input> 和 <button> 元素中设置 enctype 属性来选择的。常见的两种方式是application/x-www-form-urlencoded和multipart/form-data。
-
application/x-www-form-urlencoded:-
数据被编码成以
'&'分隔的键值对; -
以
'='分隔键和值; -
字符用url编码方式进行编码;
-
-
multipart/form-data:- 将提交的数据分成一块一块的,在
Content-Type后面有一个boundary字段来分隔请求体的每一块参数; - 对于文件上传,需要使用
multipart/form-data。
- 将提交的数据分成一块一块的,在
使用POST时,请求报文如下:
POST / HTTP/1.1
Host: foo.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 13
say=Hi&to=MomPOST /test.html HTTP/1.1
Host: example.org
Content-Type: multipart/form-data;boundary="boundary"
--boundary
Content-Disposition: form-data; name="field1"
value1
--boundary
Content-Disposition: form-data; name="field2"; filename="example.txt"
value2对于服务器,响应报文主体里的内容包括文本、图片、音频等
常见的媒体格式类型如下:
- text/html : HTML格式
- text/plain :纯文本格式
- text/xml : XML格式
- image/gif :gif图片格式
- image/jpeg :jpg图片格式
- image/png:png图片格式
以application开头的媒体格式类型:
- application/xhtml+xml :XHTML格式
- application/xml: XML数据格式
- application/atom+xml :Atom XML聚合格式
- application/json: JSON数据格式
- application/pdf:pdf格式
- application/msword : Word文档格式
- application/octet-stream : 二进制流数据(如常见的文件下载)
HTTP1.1在提升传输速率方面提供了两种方式,可以内容编码对数据进行压缩传输;也可以将数据分割分块传输。
当有报文主体时,在首部字段Content-Encoding里可以加上本次对主体的编码方式。当然,这需要另一方的Accept-Encoding字段里有可接受的编码方式。
Content-Encoding 列出了对当前报文主体应用的任何编码类型,以及编码的顺序。它让接收者知道需要以何种顺序解码该实体消息。Content-Encoding 主要用于在不丢失原媒体类型内容的情况下压缩消息数据,常用的几种编码方式有:gzip, compress, deflate, br。
gzip
表示采用 Lempel-Ziv coding(LZ77)压缩算法,以及 32 位 CRC 校验的编码方式。这个编码方式最初由 UNIX 平台上的 gzip 程序采用。出于兼容性的考虑,HTTP/1.1 标准提议支持这种编码方式的服务器应该识别作为别名的
x-gzip指令。compress
采用 Lempel-Ziv-Welch(LZW)压缩算法。这个名称来自 UNIX 系统的 compress 程序,该程序实现了前述算法。与其同名程序已经在大部分 UNIX 发行版中消失一样,这种内容编码方式已经被大部分浏览器弃用,部分因为专利问题(这项专利在 2003 年到期)。
deflate
采用 zlib 结构(在 RFC 1950 中规定),和 deflate 压缩算法(在 RFC 1951 中规定)。
br
表示采用 Brotli 算法的编码方式。
identity
用于指代自身(例如:未经过压缩和修改)。除非特别指明,这个标记始终可以被接受。
在
Accept-Encoding中,还会出现:✳️
表示匹配其他任意未在该请求头字段中列出的编码方式。假如该请求头字段不存在的话,这个值是默认值。它并不代表任意算法都支持,而仅仅表示算法之间无优先次序。
;q=(qvalues weighting)值代表优先顺序,又称为权重。
Transfer-Encoding 消息首部指明了将报文数据安全传递给用户所采用的编码形式。HTTP1.1的传输编码方式仅对块传输编码有效,即chunked。
chunked
数据以一系列分块的形式进行发送。 Content-Length首部在这种情况下不被发送。在每一个分块的开头需要添加当前分块的长度,以十六进制的形式表示,后面紧跟着 ‘\r\n’ ,之后是分块本身,后面也是’\r\n’ 。终止块是一个常规的分块,不同之处在于其长度为 0。终止块后面是一个挂载(trailer),由一系列(或者为空)的实体消息首部构成。
Trailer
响应首部,允许发送方在分块发送的消息后面添加额外的元信息,这些元信息可能是随着消息主体的发送动态生成的,比如消息的完整性校验,消息的数字签名,或者消息经过处理之后的最终状态等。
分块传输编码响应体示例
HTTP/1.1 200 OK Content-Type: text/plain Transfer-Encoding: chunked Trailer: Expires 7\r\n Mozilla\r\n 9\r\n Developer\r\n 7\r\n Network\r\n 0\r\n Expires: Wed, 21 Oct 2015 07:28:00 GMT\r\n \r\n
服务器
介绍跨域问题、缓存服务器以及服务器代理。
跨域
浏览器具有同源策略,它规定了默认情况下,前端的AJAX请求只能发给同源的URL。
- 同源指的是协议、域名和端口相同。
- img、script、link、iframe、video、audio 等标签不受同源策略的约束。
解决跨域问题需要服务端在响应头里返回允许跨域的标记,比如Access-Control-Allow-Origin告知浏览器这是一个允许跨域的请求。
通常,跨域产生是前端的请求行中的Origin里会给出这个请求是从哪一个链接过来的,在响应头Access-Control-Allow-Origin中加入对应的链接,表示允许该请求跨域。
缓存
HTTP协议是无状态的,每一次响应过程都是独立的,如果需要记录一些数据,需要使用到缓存。缓存目前使用的有两种方式:Cookie-Session和Token。
Cookie-Session
Cookie:服务器以响应头的形式返回cookie,客户端(浏览器)会存储cookie数据到本地磁盘;
Session:在服务端存储数据。
流程:
- 客户端发送登录信息;
- 为客户端设定一个sessionID,并且存储一些用户的信息。返回响应,响应头
Set-Cookie中会带有sessionID、domain、path。 - 客户端将sessionID存在本地,在下一次请求中,请求头里
Cookie字段会携带sessionID; - 服务器校验cookie,返回数据。

缺点:
- 服务端需要存储 Session,并且由于 Session 需要经常快速查找,通常存储在内存或内存数据库 中,同时在线⽤用户较多时需要占⽤用⼤大量量的服务器器资源。
- 当需要扩展时,创建 Session 的服务器器可能不不是验证 Session 的服务器器,所以还需要将所有Session 单独存储并共享。
- 由于客户端使⽤用 Cookie 存储 SessionID,在跨域场景下需要进⾏行行兼容性处理理,同时这种⽅方式也难以防范 CSRF 攻击。
Token
服务端不需要存储用户鉴权的信息,鉴权信息被加密到Token中。避免共享SessionID

JWT(JSON Web Token)是为了在网络应⽤环境间传递声明而执行的一种基于JSON的开放标准。它是一种基于 Token 的会话管理的规则, 涵盖 Token 需要包含的标准内容和 Token 的⽣成过程。
JWT由.分隔成3部分:头部、负载和签名,三部分的内容分别单独经过Base64编码。
- 头部:为json格式,存储了使用的加密算法和Token类型,例如:
{
"alg": "HS256",
"typ": "JWT"
}- 负载:为json格式,由官方规定了7个字段可以定义:
iss (issuer):签发⼈人
exp (expiration time):过期时间
sub (subject):主题
aud (audience):受众
nbf (Not Before):⽣生效时间
iat (Issued At):签发时间
jti (JWT ID):编号- 签名:对前两部分的签名。首先需要由服务器生成一个密钥;然后使用头部里指定的算法加密。
Refresh Token
Token可以分为有效期较短的Access Token和有效期长的Refresh Token。当Access Token过期后,使用Refresh Token请求新的Access Token即可。

为什么需要Refresh Token?
- 安全性:请求中都带有Access Token,使用频率高,安全性较低;Refresh Token使用频率小,安全性较高。
- 速度:通过加密Refresh Token,不加密Access Token来提高请求访问速度。
服务器代理
服务器代理分为正向和反向。正向为代理客户端,反向为服务器。
正向代理需要客户端手动配置代理服务器IP,在发送请求时,会发送到代理服务器,然后再从代理服务器获得响应:
- 隐藏客户端身份
- 绕过防火墙(突破访问限制)
- Internet访问控制
- 数据过滤

 浙公网安备 33010602011771号
浙公网安备 33010602011771号