聊一聊 tcp拥塞控制 九 fack
FACK 重传
FACK全称Forward Acknowledgment 算法,论文地址在这里(PDF)Forward Acknowledgement: Refining TCP Congestion Control
SACK是使用了TCP扩展字段Ack了有哪些数据收到,哪些数据没有收到,他比Fast Retransmit的3 个duplicated acks好处在于,前者只知道有包丢了,不知道是一个还是多个,而SACK可以准确的知道有哪些包丢了。 所以,SACK可以让发送端这边在重传过程中,把那些丢掉的包重传,而不是一个一个的传,但这样的一来,如果重传的包数据比较多的话,又会导致本来就很忙的网络就更忙了。所以,FACK用来做重传过程中的拥塞流控
- 这个算法会把SACK中最大的Sequence Number 保存在snd.fack这个变量中,snd.fack的更新由ack决定,如果网络一切安好则和snd.una一样(snd.una就是还没有收到ack的地方,也就是前面sliding window里的category #2的第一个地方)
- 然后定义一个awnd = snd.nxt – snd.fack(snd.nxt指向发送端sliding window中正在要被发送的地方——前面sliding windows图示的category#3第一个位置),这样awnd的意思就是在网络上的数据。(所谓awnd意为:actual quantity of data outstanding in the network)
- 如果需要重传(包括在cwnd内允许传输的段)数据,那么,awnd = snd.nxt – snd.fack + retran_data,也就是说,awnd是传出去的数据 + 重传的数据。
- 然后触发Fast Recovery 的条件是: ( ( snd.fack – snd.una ) > (3*MSS) ) || (dupacks == 3) ) 。这样一来,就不需要等到3个duplicated acks才重传,而是只要sack中的最大的一个数据和ack的数据比较长了(3个MSS),那就触发重传。在整个重传过程中cwnd不变。直到当第一次丢包的snd.nxt<=snd.una(也就是重传的数据都被确认了),然后进来拥塞避免机制——cwnd线性上涨。
比如当使能FACK的时候,实际上我们可以通过一个SACK块信息来推测丢包情况进而触发快速重传。比如server端依次发出P1(0-9)、P2(10-19)、P3(20-29)、P4(30-39)、P5(40-49),假设client端正常收到了P1包并回复了ACK确认包,P2、P3、P4则由于网络拥塞等原因丢失,client在收到P5时候回复一个Ack=10的确认包,并携带P5有SACK块信息(40-50),这样server在收到P1的确认包和P5的dup ACK时候,就可以根据dup ACK中的SACK信息得知client端收到了P1报文和P5报文,计算出P1和P5两个数据包中间间隔了3个数据包,达到了dup ACK门限(默认为3),进而推测出P2报文丢失。
FACK 它拥有标准 SACK 算法的一切性质,除此之外,它假设网络不会使数据包乱序,因此收到最大的被 SACK 的数据包之前,FACK 均认为是丢失的。FACK 模式下,重传时机为 被 SACKed 的包数 + 空洞数 > dupthresh 同时dupack == dupthresh(3) 默认。
如下图所示,设 dupthresh = 3,FACKed_count = 12,从 unACKed 包开始的 FACKed_count
dupthresh 个数据包,即 9 个包会被标记为 LOST。 也就是 段的数量为(snd.fack – snd.una-sacked)

拥塞窗口状态
记分板状态如下,红色表示该数据包丢失.
FACK Design Goals
The requisite network state information can be obtained with accurate knowledge about the forward most data held by the receiver. By forward-most, we mean the correctly-received data with the highest sequence number. This is the origin of the name "forward acknowledgement."The goal of the FACK algorithm is to perform precise congestion control during recovery by keeping an accurate estimate of the amount of data outstanding in the network.
FACK Algorithm
When a SACK block is received which acknowledges data with a higher sequence number than the current value of snd.fack, snd.fack is updated to reflect the highest sequence number known to have been received plus one. The FACK algorithm uses the additional information provided by the SACK option to keep an explicit measure of the total number of bytes of data outstanding in the network. In contrast, Reno and Reno + SACK both attempt to estimate this by assuming that each duplicate ACK received represents
one segment which has left the network. The FACK algorithm is able to do this in a staightforward way by introducing two new state variables, snd.fack and retran_data.
TCP's estimate of the amount of data outstanding in the network during recovery is given by:
awind = snd.nxt - snd.fack + retran_data
Triggering Recovery
Reno invokes Fast Recovery by counting duplicate acknowledgements:
if ( dupacks == 3 ) { ... }
This algorithm causes an unnecessary delay if several segments are lost prior to receiving three duplicate acknowledgements. In the FACK version, the cwnd adjustment and retransmission are also triggered when the receiver reports that the reassembley queue is longer than 3 segments:
if ( ( snd.fack - snd.una ) > (3*MSS) ) || (dupacks == 3) ) { ... }
wireshark示例 转载自https://www.cnblogs.com/lshs/p/6038562.html
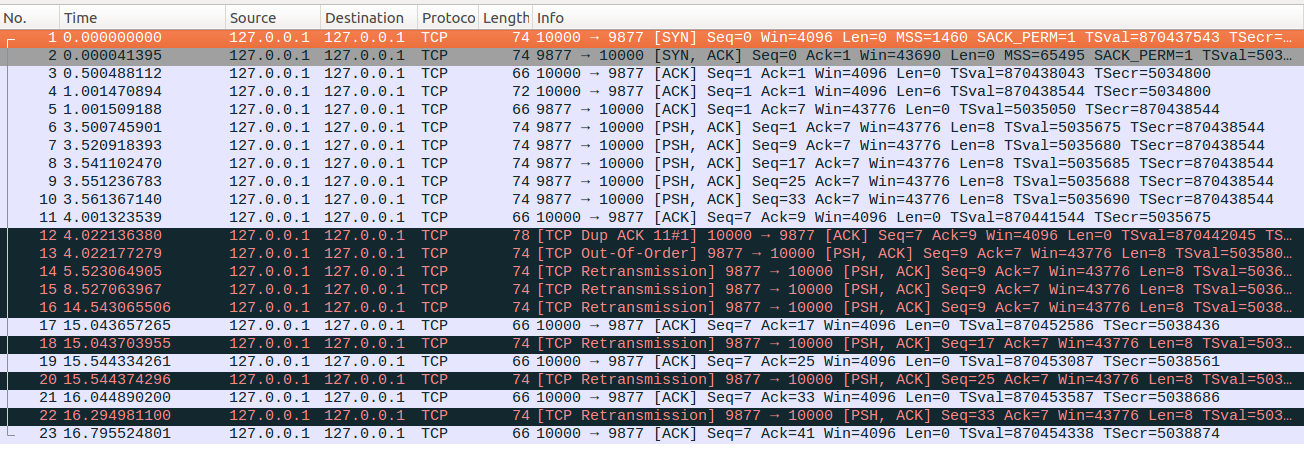
tcp_early_retrans=0,tcp_retrans_collapse=0,tcp_discard_on_port =9877,tcp_sack=1,tcp_fack=1
-
server端依次发送No6-No10五个数据包
-
client收到No6后回复一个不带有SACK选项的ACK确认包(No11),server端正常接收到这个ACK确认包
-
接着client模拟No7-No9数据包丢包,在收到No10乱序包的时候,回复一个dup ACK,其中包含SACK信息(33-41),
-
server端收到这个dup ACK后推测处client端已经收到No6和No10报文,中间间隔的报文个数为3个,达到dup ACK门限,进而触发快速重传。
-
client继续模拟丢包,接着server端RTO超时,进行指数回退过程。
-
直到No16重传后,client开始回复不带有SACK选项的ACK(partial ACK),但是因为ack number并没有落在33-40之间,此时linux并不会确认发生了SACK reneging。这个ACK触发快速重传(No18)。受限与拥塞控制,这个时候只能发送一个重传包,发送完这个重传报文后根据收到的ACK更新拥塞窗口,拥塞窗口自增1,因此此时可以发送一个新的数据包,但是因为缓存中没有新的待发送数据因此并没有新数据包传出。
-
接收client回复No19的ACK确认包(partial ACK),这个ACK报文虽然不带有SACK选项,但是linux同样不会确认发生了SACK reneging,server端根据这个partial ACK触发快速重传,在上一步中拥塞窗口已经自增了1,因此实际上快速重传可以重传两个TCP报文但是因为重传完No20后,只剩下一个报文待重传,而这个报文之前又被SACK过,因此快速重传不会重传这个报文
-
接着client回复不带有SACK选项的No21确认包,Ack=33,注意之前触发FACK快速重传的时候反馈的SACK块信息是(33-41)告诉server端收到了No10数据包,而这个新回复的No21确认包又告诉server没有收到No10确认包。此时就是发生了SACK reneging。在这个ACK确认包触发快速重传时候,就会检测是否发生了SACK seneging,如果发生SACK reneging,linux会初始化一个RTO定时器,定时器的定时时间为RTT/2。快速重传时候检测到了SACK seneging就会直接退出。
-
接着上一步的RTO定时器超时,触发了No22的RTO超时重传,client回复对应的ACK确认包,整个传输过程结束。
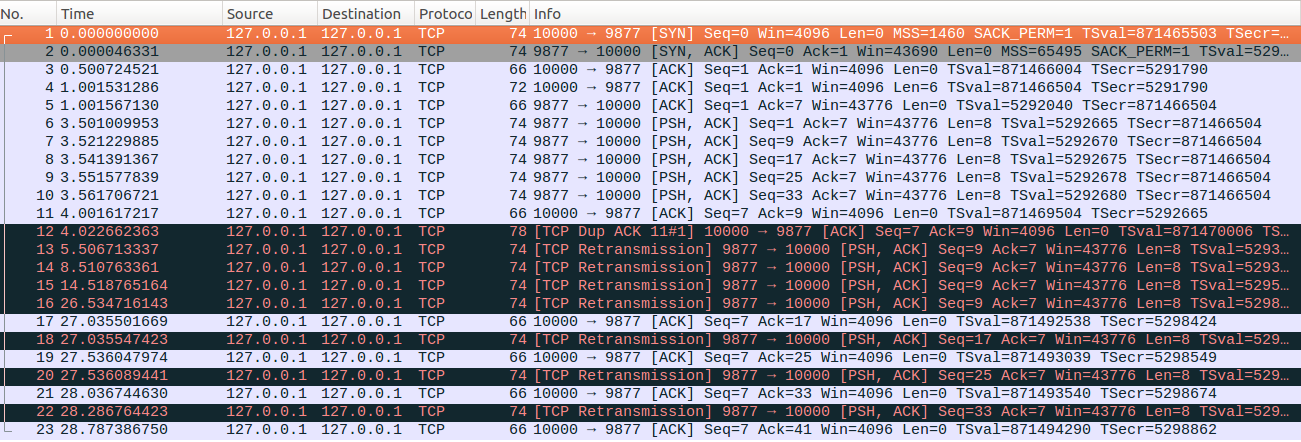
tcp_early_retrans=0,tcp_retrans_collapse=0,tcp_discard_on_port =9877,tcp_sack=1,tcp_fack=0;这里我们关闭FACK功能,其他设置不变重新进行类似上面的测试
可以看到这个示例与上面示例的主要差异就是No12的dup ACK虽然同样反馈了No10的SACK信息,但是并没有触发快速重传。其他内容与上面示例基本一致不再重复介绍。
tcp_early_retrans=0,tcp_retrans_collapse=0,tcp_discard_on_port =9877,tcp_sack=1,tcp_fack=1;低于dup ACK门限
示例和示例1不同的地方在于No12的dup ACK确认包携带的SACK信息为(25-33),也就是通过SACK确认了No9报文,No9与No6报文之间间隔了2个报文没有达到dup ACK的门限,因此并不会触发快速重传。注意server端在收到No19确认包时候触发了快速重传流程,但是快速重传前检测到SACK seneging,重启了RTO定时器并退出快速重传。
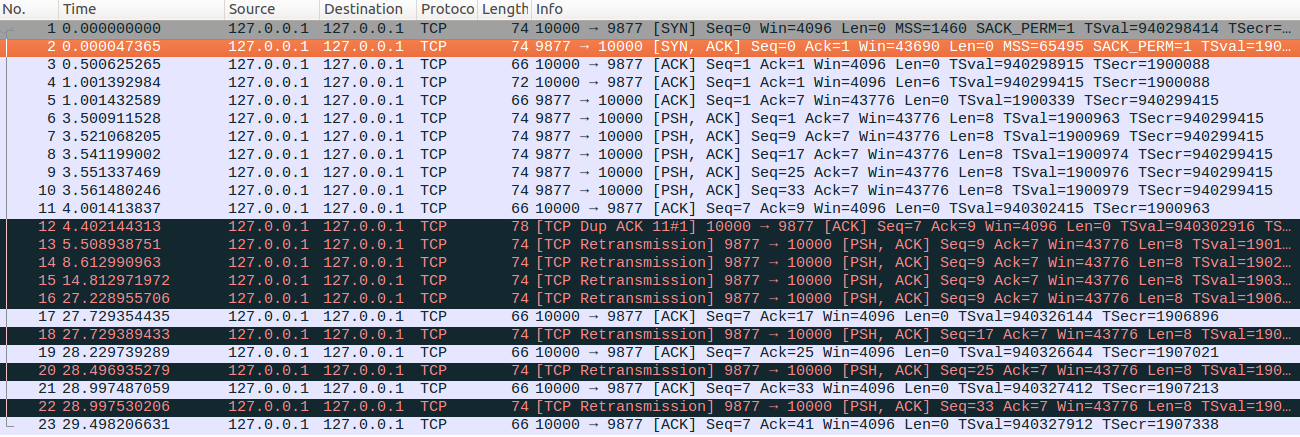
rtt大约为500ms 包No20 和包No19 相差 RTT/2 时间,因为定时器的定时时间为RTT/2后再重传
No6 1---8 ----ACk
No7 9---16
No8 17---24
No9 25---32--------sack
No10 33---40

 浙公网安备 33010602011771号
浙公网安备 33010602011771号