引擎优化笔记1----重要
根据perf 工具可以看到目前引擎问题主要是:

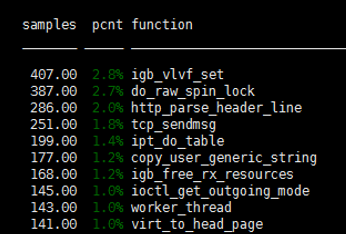
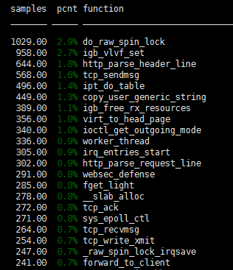
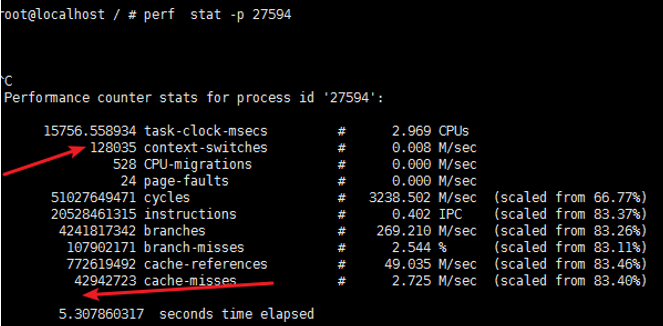
内核协议栈以及软中断问题;细分的话 就是 自旋锁、cache-misses、cs 进程上下文切换
1、应用层目前预计只能从数据结构优化; 比如使用haproxy的ebtree经行优化。但是 我们使用了fdtable ,所以无用。ebtree(见https://blog.csdn.net/xiefangjin/article/details/50932201)
2、内核协议栈方面:
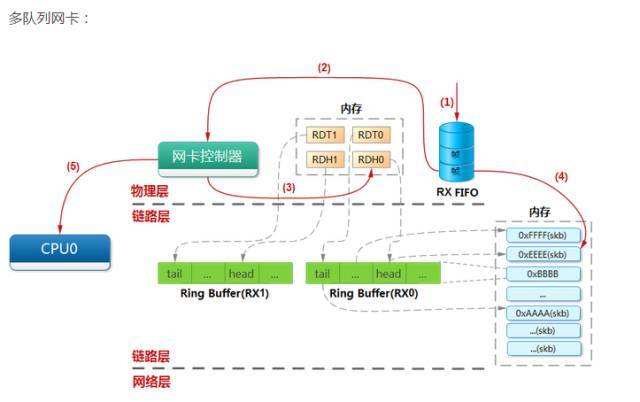
怎么优化测试呢??
1、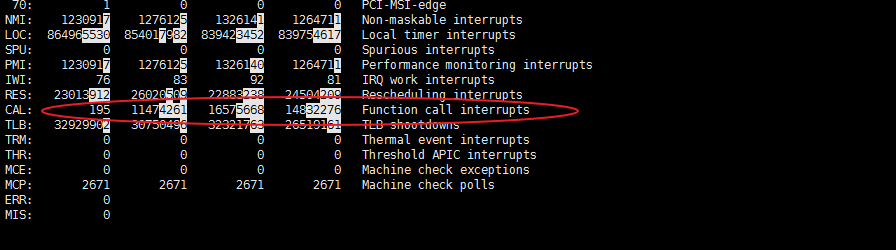
可以看到 function call interrupts 数据一直都在增高。
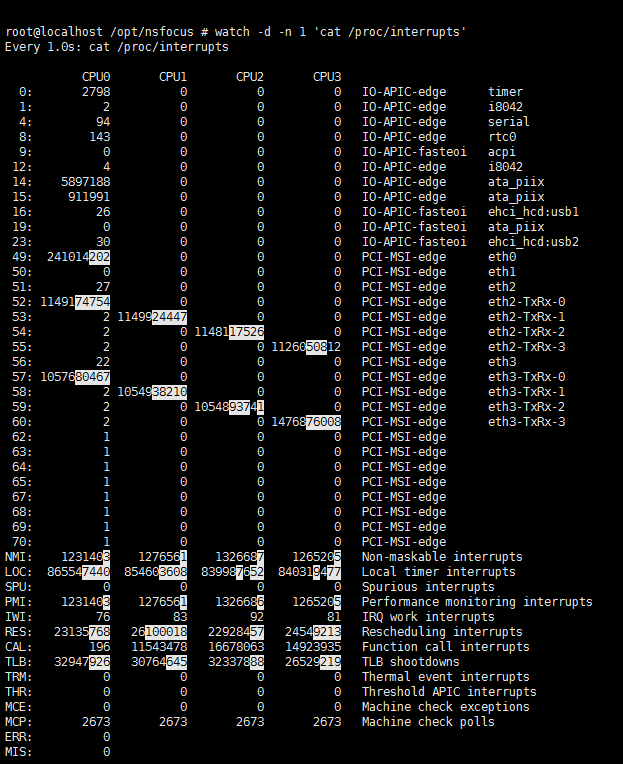
LOC-local timer interrupt:
SPU- spurious interrupt:
RES-Rescheduling interrupt:
- 重调度中断,这个终端类型表示,唤醒空闲的CPU来调度新的任务运行。这是多处理器系统中,调度器用来分散任务到不同CPU的机制,也称为处理期间中断
CAL-Function call interrupt:
TLB-TLB shootdowns:
对于接收数据调优:
1、中断合并(Interrupt coalescing)-中断合并会将多个中断事件放到一起,到达一定的阈值之后才向 CPU 发起中断请求;防止中断风暴,提升吞吐。减少中断数量能使吞吐更高,但延迟也变大,CPU 使用量下降;这个参数 为InterruptThrottleRate 部分网卡支持。
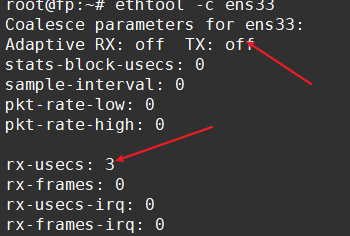
同时有的网卡支持“自适应 RX/TX 硬中断合并“ 见“adaptive-rx”参数
2、在多 CPU 的环境中,还有一个中断平衡的问题,比如,网卡中断会教给哪个 CPU 处理,这个参数控制哪些 CPU 可以绑定 IRQ 中断。其中的 {number} 是对应设备的中断编号,可以用下面的命令找出:cat /proc/interrupt
比如,一般 eth1 的 IRQ 编号是 17,所以控制 eth1 中断绑定的 /proc 文件名是 /proc/irq/17/smp_affinity。上面这个命令还可以看到某些中断对应的CPU处理的次数,缺省的时候肯定是不平衡的。
设置其值的方法很简单,smp_affinity 自身是一个位掩码(bitmask),特定的位对应特定的 CPU,这样,01 就意味着只有第一个 CPU 可以处理对应的中断,而 0f(0x1111)意味着四个 CPU 都会参与中断处理。
echo 1 > /proc/irq/8/smp_affinity ----//Set the IRQ affinity for IRQ 8 to CPU 0
使用自带的irqload_balance
3、网络数据处理
3.1一旦软中断代码判断出有 softirq 处于 pending 状态,就会开始处理,执行net_rx_action
net_rx_action 从包所在的内存开始处理,包是被设备通过 DMA 直接送到内存的。
函数遍历本 CPU 队列的 NAPI 变量列表,依次出队并操作之。
处理逻辑考虑任务量(work budget)和执行时间两个因素;也就是防止处理数据包过程耗光整个 CPU
budget 是该 CPU 的所有 NAPI 变量的总预算。这也是多队列网卡应该精心调整 IRQ Affinity 的原因。网卡数据包文到达时,触发硬件中断,处理硬中断的 CPU接下来会处理相应的软中断,进而执行上面包含 budget 的这段逻辑。
多网卡多队列可能会出现这样的情况:多个 NAPI 变量注册到同一个 CPU 上。每个 CPU 上的所有 NAPI 变量共享一份 budget。
如果没有足够的 CPU 来分散网卡硬中断,可以考虑增加 net_rx_action 允许每个 CPU处理更多包。增加 budget 可以增加 CPU 使用量
但是top的 si可能标高,可以减少延迟,毕竟数据处理更加及时
3.2 NAPI 以及设备驱动
- 如果驱动的
poll方法用完了它的全部 weight(默认 hardcode 64/300),那它不要更改 NAPI 状态。接下来 软中断net_rx_action来loop处理 - 如果驱动的
poll方法没有用完全部 weight,那它关闭 NAPI。下次有硬件中断触发,驱动的硬件处理函数调用napi_schedule时,NAPI 会被重新打开 - 这也就是 中断+LOOP
之前讲过:
netif_napi_add --驱动通知使用napi的机制,初始化响应参数,注册poll的回调函数 napi_schedule --驱动通知kernel开始调度napi的机制,稍后poll回调函数会被调用(本次sd也会加入list) napi_complete --驱动告诉内核其工作不饱满即中断不多,数据量不大,改变napi的状态机,后续将采用纯中断方式响应数据 net_rx_action --收包软中断,注册poll的回调函数会被其调用
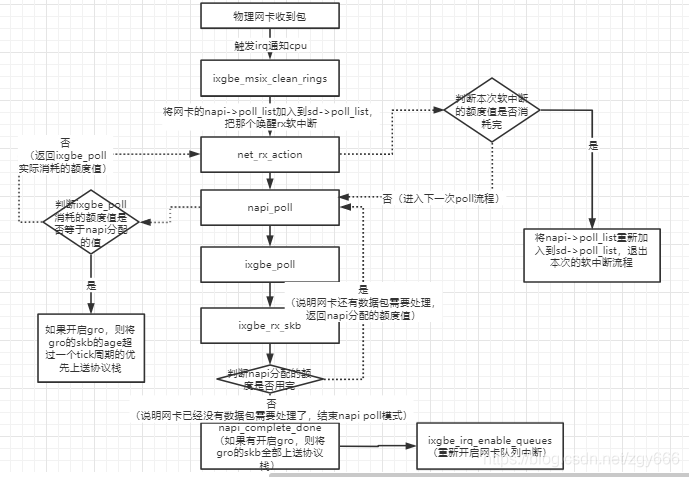
3.3 net_rx_action 退出循环:
- 这个 CPU 上注册的 poll 列表已经没有 NAPI 变量需要处理(
!list_empty(&sd->poll_list)) - 剩余的
budget <= 0 - 已经满足 2 个 jiffies 的时间限制
/* If softirq window is exhausted then punt. * Allow this to run for 2 jiffies since which will allow * an average latency of 1.5/HZ. */ if (unlikely(budget <= 0 || time_after_eq(jiffies, time_limit))) { sd->time_squeeze++;
time_squeeze 字段记录的是满足如下条件的次数:net_rx_action 有很多 work 要做但是 budget 用完了,或者 work 还没做完但时间限制到了。
调整 net_rx_action budget
net_rx_action budget 表示一个 CPU 单次轮询(poll)所允许的最大收包数量。单次 poll 收包时,所有注册到这个 CPU 的 NAPI 变量收包数量之和不能大于这个阈值。 调整:
sudo sysctl -w net.core.netdev_budget=600
如果要保证重启仍然生效,需要将这个配置写到/etc/sysctl.conf
网络处理的瓶颈体现之处
/** * ixgbe_poll - NAPI polling RX/TX cleanup routine * @napi: napi struct with our devices info in it * @budget: amount of work driver is allowed to do this pass, in packets * * This function will clean all queues associated with a q_vector. **/ int ixgbe_poll(struct napi_struct *napi, int budget) { struct ixgbe_q_vector *q_vector = container_of(napi, struct ixgbe_q_vector, napi); struct ixgbe_adapter *adapter = q_vector->adapter; struct ixgbe_ring *ring; int per_ring_budget; bool clean_complete = true; ixgbe_for_each_ring(ring, q_vector->tx) clean_complete &= ixgbe_clean_tx_irq(q_vector, ring); /* attempt to distribute budget to each queue fairly, but don't allow * the budget to go below 1 because we'll exit polling */ if (q_vector->rx.count > 1) per_ring_budget = max(budget/q_vector->rx.count, 1); else per_ring_budget = budget; ixgbe_for_each_ring(ring, q_vector->rx) clean_complete &= ixgbe_clean_rx_irq(q_vector, ring, per_ring_budget); /* If all work not completed, return budget and keep polling */ if (!clean_complete) return budget; /* all work done, exit the polling mode */ napi_complete(napi); if (adapter->rx_itr_setting == 1) ixgbe_set_itr(q_vector); if (!test_bit(__IXGBE_DOWN, &adapter->state)) ixgbe_irq_enable_queues(adapter, ((u64)1 << q_vector->v_idx)); return 0; }
- 然后执行
igb_clean_rx/tx_irq,---收发包具体看前面讲的驱动哪一章 - 然后执行
clean_complete,判断是否仍然有 work 可以做。如果有,就返回 budget(回忆,这里是 hardcode 64)。在之前我们已经看到,net_rx_action会将这个 NAPI变量移动到 poll 列表的末尾 - 如果所有
work都已经完成,驱动通过调用napi_complete关闭 NAPI,并通过调用igb_ring_irq_enable重新进入可中断状态。下次中断到来的时候回重新打开 NAPI
igb_clean_rx_irq:主要处理如下:
- 分配额外的 buffer 用于接收数据,因为已经用过的 buffer 被 clean out 了。一次分配
IGB_RX_BUFFER_WRITE (16)个。 - 从 RX 队列取一个 buffer,保存到一个
skb类型的变量中 - 判断这个 buffer 是不是一个包的最后一个 buffer。如果是,继续处理;如果不是,继续从 buffer 列表中拿出下一个 buffer,加到 skb。当数据帧的大小比一个 buffer 大的时候,会出现这种情况
- 验证数据的 layout 和头信息是正确的
- 更新
skb->len,表示这个包已经处理的字节数 - 设置
skb的 hash, checksum, timestamp, VLAN id, protocol 字段。hash,checksum,timestamp,VLAN ID 信息是硬件提供的,如果硬件报告 checksum error,csum_error统计就会增加。如果 checksum 通过了,数据是 UDP 或者 TCP 数据,skb就会被标记成CHECKSUM_UNNECESSARY - 构建的 skb 经
napi_gro_receive()进入协议栈 - 更新处理过的包的统计信息
- 循环直至处理的包数量达到 budget
- 循环结束的时候,这个函数设置收包的数量和字节数统计信息
3.4 监控网络数据处理
/proc/net/softnet_stat
static int softnet_seq_show(struct seq_file *seq, void *v) { struct softnet_data *sd = v; unsigned int flow_limit_count = 0; #ifdef CONFIG_NET_FLOW_LIMIT struct sd_flow_limit *fl; rcu_read_lock(); fl = rcu_dereference(sd->flow_limit); if (fl) flow_limit_count = fl->count; rcu_read_unlock(); #endif seq_printf(seq, "%08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x\n", sd->processed, sd->dropped, sd->time_squeeze, 0, 0, 0, 0, 0, /* was fastroute */ sd->cpu_collision, /* was cpu_collision */ sd->received_rps, flow_limit_count); return 0; }

- 每一行代表一个
struct softnet_data变量。因为每个 CPU 只有一个该变量,所以每行
其实代表一个 CPU - 每列用空格隔开,数值用 16 进制表示
- 第一列
sd->processed,是处理的网络帧的数量。如果你使用了 ethernet bonding,
那这个值会大于总的网络帧的数量,因为 ethernet bonding 驱动有时会触发网络数据被
重新处理(re-processed) - 第二列,
sd->dropped,是因为处理不过来而 drop 的网络帧数量。后面会展开这一话题 - 第三列,
sd->time_squeeze,前面介绍过了,由于 budget 或 time limit 用完而退出net_rx_action循环的次数 - 接下来的 5 列全是 0
- 第九列,
sd->cpu_collision,是为了发送包而获取锁的时候有冲突的次数 - 第十列,
sd->received_rps,是这个 CPU 被其他 CPU 唤醒去收包的次数 - 最后一列,
flow_limit_count,是达到 flow limit 的次数。flow limit 是 RPS 的特性
- 第一列
所以主要是要有合理的 budget
GRO(Generic Receive Offloading)
Large Receive Offloading (LRO) 是一个硬件优化,GRO 是 LRO 的一种软件实现。
两种方案的主要思想都是:通过合并“足够类似”的包来减少传送给网络栈的包数,这有助于减少 CPU 的使用量。例如,考虑大文件传输的场景,包的数量非常多,大部分包都是一段文件数据。相比于每次都将小包送到网络栈,可以将收到的小包合并成一个很大的包再送到网络栈。这可以使得协议层只需要处理一个 header,而将包含大量数据的整个大包送到用户程序。
这类优化方式的缺点就是:信息丢失。如果一个包有一些重要的 option 或者 flag,那将这个包的数据合并到其他包时,这些信息就会丢失。这也是为什么大部分人不使用或不推荐使用LRO 的原因。
LRO 的实现,一般来说,对合并包的规则非常宽松。GRO 是 LRO 的软件实现,但是对于包合并的规则更严苛。
tcpdump 的抓包点(捕获包的 tap)在整个栈的更后面一些,在GRO 之后,可能抓到非常大的包
RPS (Receive Packet Steering)
RPS (Receive Packet Steering,接收包控制,接收包引导)是 RSS 的一种软件实现
RPS 并不会减少 CPU 处理硬件中断和 NAPI poll(软中断最重要的一部分)的时间,但是可以在 packet 到达内存后,将 packet 分到其他 CPU,从其他 CPU 进入协议栈。
但是分发cpu的时候可能导致cpu 间中断变高,可能性能会下降;
RPS 的工作原理是对个 packet 做 hash,决定哪个 CPU 处理。然后 packet 放到每个 CPU独占的接收后备队列(backlog)等待处理。
这个 CPU 会触发一个进程间中断(IPI,Inter-processor Interrupt)向对端 CPU。如果当时对端 CPU 没有在处理 backlog 队列收包,这个进程间中断会触发它开始从 backlog 收包。
/proc/net/softnet_stat 其中有一列是记录 softnet_data变量(也即这个 CPU)收到了多少 IPI(received_rps 列)。
同时cat /proc/interrupts 里面的CAL 就是;
::----打开 RPS 之后,原来不需要处理软中断(softirq)的 CPU 这时也会参与处理。因此相 应 CPU 的 NET_RX 数量,以及 si 或 sitime 占比都会相应增加
RPS需要使用CONFIG_RPS kconfig符号编译的内核(SMP默认情况下处于启用状态)。即使在编译到内核,RPS仍保持禁用状态,直到显式配置RPS。可以使用sysfs文件条目为每个接收队列配置RPS可能会将流量转发到的CPU列表:
/sys/class/net/<dev>/queues/rx-<n>/rps_cpus
RFS (Receive Flow Steering)
RFS(Receive flow steering)和 RPS 配合使用。RPS 试图在 CPU 之间平衡收包,但是没考虑 数据的本地性问题,如何最大化 CPU 缓存的命中率。RFS 将属于相同 flow 的包送到相同的 CPU 进行处理,可以提高缓存命中率。
RPS仅基于散列来引导数据包,从而通常可以提供良好的负载分配,但它并未考虑应用程序的局部性。这是通过接收流控制(RFS)来完成的。RFS的目标是通过将数据包在内核中的处理引导到使用该数据包的应用程序线程对应的CPU来提高数据缓存的命中率。RFS依靠RPS相同的机制将数据包排队到另一个CPU的待办事项中,并唤醒该CPU。
在RFS中,数据包不通过其哈希值直接转发,而是将哈希用作流查找表的索引。该表将流映射到正在处理这些流的CPU。流哈希-用于计算此表中的索引。每个条目中记录的CPU是最后处理该流程的CPU。如果某个条目没有有效的CPU,则直接使用RPS引导映射到该条目的数据包。多个表条目可能指向同一CPU。确实,在具有许多流和少量CPU的情况下,单个应用程序线程很有可能使用许多不同的流散列来处理流;rps_sock_flow_table是一个全局流表,其中包含流所需的 CPU:当前正在用户空间中处理流的CPU。每个表值都是一个CPU索引,在调用recvmsg和sendmsg(特别是inet_recvmsg(),inet_sendmsg(),inet_sendpage()和tcp_splice_read())期间将对其进行更新
RFS配置
仅当启用了kconfig符号CONFIG_RPS时,RFS才可用(默认情况下,SMP处于启用状态)。除非明确配置,否则该功能将保持禁用状态。全局流表中的条目数是通过以下方式设置的:
/proc/sys/net/core/rps_sock_flow_entries
通过以下方式设置每个队列流表中的条目数:
/sys/class/net/<dev>/queues/rx-<n>/rps_flow_cnt
对于RPS/RFS 的调优
1、RPS 在不同 CPU 之间分发 packet,但是,如果一个 flow 特别大,会出现单个 CPU 被打爆,而其他 CPU 无事可做(饥饿)的状态。因此引入了 flow limit 特性,放到一个 backlog 队列的属
于同一个 flow 的包的数量不能超过一个阈值。这可以保证即使有一个很大的 flow 在大量收包,小 flow 也能得到及时的处理。
if(qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen))
由于 input_pkt_queue 打满或 flow limit 导致的丢包可以在/proc/net/softnet_stat 里面的 dropped 列计数看到体现出来
所以可以 增大 netdev_max_backlog来 Adjusting netdev_max_backlog to prevent drops
2、net.core.dev_weight 决定了 backlog poll loop 可以消耗的整体 budget
3、Enabling flow limits and tuning flow limit hash table size
通过设置 net.core.flow_limit_table_len的值
打开 flow limit 功能的方式是,在/proc/sys/net/core/flow_limit_cpu_bitmap 中指定一个 bitmap
再就打开或关闭 IP 协议的 early demux 选项,据说可以提高吞吐
再就是Socket receive queue memory
4、打时间戳 (timestamping)--测试收包处理延时
root@fp:~# ethtool -T ens33 Time stamping parameters for ens33: Capabilities: software-transmit (SOF_TIMESTAMPING_TX_SOFTWARE) software-receive (SOF_TIMESTAMPING_RX_SOFTWARE) software-system-clock (SOF_TIMESTAMPING_SOFTWARE) PTP Hardware Clock: none Hardware Transmit Timestamp Modes: none Hardware Receive Filter Modes: none
可以查看网卡是否支持硬件打时间戳
5、Socket 低延迟选项:busy polling
6、SO_INCOMING_CPU 使用 getsockopt 带 SO_INCOMING_CPU 选项,可以判断当前哪个 CPU 在处理这个 socket 的网络包。你的应用程序可以据此将 socket 交给在期望的 CPU 上运行的线程,增加数据本地性(data locality)和 CPU 缓存命中率;在内核邮件里面有个example
看下 软中断debug数据:

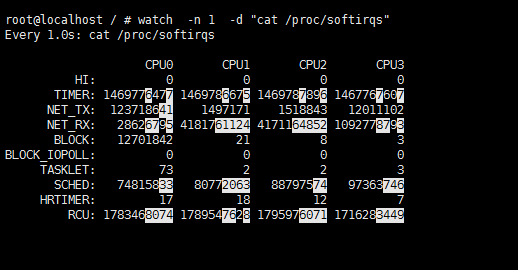
TIMER(定时中断),NET_RX(网络接收),SCHED(内核调度),RCU(RCU锁)等都在变化,而NET_RX TIMER变化最多
sar -n DEV 1
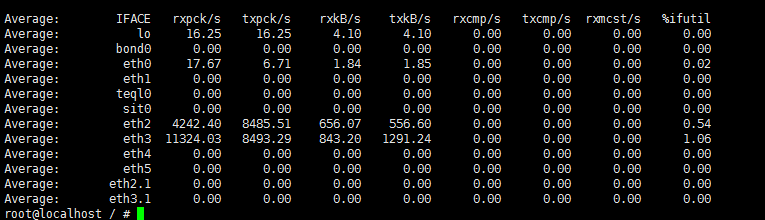
eth2每秒接收的数据帧为4242,而发送的有8485,但是接收总大小才656KB,发送数据为556KB
656*1024/4242=158字节 报文大小还行 没有都是 tcp的syn ack 报文 这些报文小于64
也就是在跑转发 ;此时只能tcpdump看了
控制TCP三次握手参数
- SYN_SENT状态
net.ipv4.tcp_syn_retries
- SYN_RCVD状态
net.ipv4.tcp_max_syn_backlog SYN_RCVD状态连接的个数
net.ipv4.tcp_synack_retries 被动建立连接的时候发送SYN/ACK重试的次数
流程是SYN分组收到的数据插入到tcp_max_syn_backlog的队列并发送回复 ACK分组收到数据从tcp_max_syn_backlog的队列中取出放入ACCEPT队列 server 从ACCEPT队列获取套接字 如果应用程序请求过慢,就会导致accept队列满 net.core.somaxconnACCEPT队列
建立TCP连接的优化
应对SYN攻击
net.core.netdev_max_backlog接收自网卡但是没有被内核协议栈处理的报文队列长度
net.ipv4.tcp_max_syn_backlog SYN_RCVD状态连接的个数
net.ipv4.tcp_abort_on_overflow 超出处理能力对新来的SYN包直接返回RST并丢弃连接
当SYN队列满了,新的SYN不进入队列,而是计算出cookie以SYN+ACK回复返回client,正常client发送报文的时候,server根据报文中的cookie恢复连接,
但是cookies会占用序列号空间(32位),会使扩充窗口或者时间戳失效
文件句柄上限
操作系统全局 :fs.file-max,可以用sysctl -a | grep file-max查看,使用是file-nr
用户级别 :/etc/security/limits.conf的nofile
参考来自:http://arthurchiao.art/blog/monitoring-network-stack/
记得弄清楚:
netdev_budget :表示一个 CPU 单次轮询(poll)所允许的最大收包数量。单次 poll 收包时,所有注册到这个 CPU 的 NAPI 变量收包数量之和不能大于这个阈值;在 net_rx_action 使用;
同时每个sd对用的napi_struct 有自己的weight;以ixgb_poll 为例
netif_napi_add(adapter->netdev, &q_vector->napi, ixgbe_poll, 64); void netif_napi_add(struct net_device *dev, struct napi_struct *napi, int (*poll)(struct napi_struct *, int), int weight) { INIT_LIST_HEAD(&napi->poll_list); hrtimer_init(&napi->timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL_PINNED); napi->timer.function = napi_watchdog; napi->gro_count = 0; napi->gro_list = NULL; napi->skb = NULL; napi->poll = poll; if (weight > NAPI_POLL_WEIGHT) pr_err_once("netif_napi_add() called with weight %d on device %s\n", weight, dev->name); napi->weight = weight; list_add(&napi->dev_list, &dev->napi_list); napi->dev = dev; #ifdef CONFIG_NETPOLL spin_lock_init(&napi->poll_lock); napi->poll_owner = -1; #endif set_bit(NAPI_STATE_SCHED, &napi->state); }
dev_weight:process_backlog 中会使用此作为 weight计算处理:
backlog 队列:
NAPI poller每个 CPU 都有一个 backlog queue,其加入到 NAPI 变量的方式和驱动差不多,都是注册一个 poll 方法,在软中断的上下文中处理包。此外,还提供了一个 weight,这也和驱动类似 。注册发生在网络系统初始化的时候, net/core/dev.c的 net_dev_init 函数:
sd->backlog.poll = process_backlog; sd->backlog.weight = weight_p; sd->backlog.gro_list = NULL; sd->backlog.gro_count = 0;
backlog NAPI 变量和设备驱动 NAPI 变量的不同之处在于,它的 weight 是可以调节的,而设备驱动是 hardcode 64
netdev_max_backlog:由于enqueue_to_backlog 被调用的地方很少。在基于 RPS 处理包的地方,以及 netif_rx,会 调用到它。大部分驱动都不应该使用 netif_rx,而应该是用 netif_receive_skb。如果 你没用到 RPS,你的驱动也没有使用 netif_rx,那增大 backlog 并不会带来益处,因为它 根本没被用到。也就是如果你使用了 RPS,或者你的驱动调用了 netif_rx,那增加 netdev_max_backlog 可以改 善在 enqueue_to_backlog 里的丢包;调用了 netif_receive_skb,而且你没用 RPS,那增大 netdev_max_backlog 并不会带来任何性能提升,因为没有数据包会被送到 input_pkt_queue
也就是:如果使用了 RPS,或者驱动调用了 netif_rx,那增加 netdev_max_backlog 可以改善在 enqueue_to_backlog 里的丢包
backlog 处理逻辑和设备驱动的 poll 函数类似,都是在软中断(softirq)的上下文 中执行,因此受整体 budget 和处理时间的限制
涉及到NAPI 和非NAPI的区别,如果上述不清楚可以看这篇文章:链路层收包
 浙公网安备 33010602011771号
浙公网安备 33010602011771号