重看 mb volatile atomic
在单处理器情况下,每条指令的执行都是原子性的,但在多处理器情况下,只有那些单独的读操作或写操作才是原子性的。
so原子操作----->原子的操作指的就是在执行过程中不会被别的代码所中断的操作。
为了弥补这一缺点,x86提供了附加的lock前缀,使带lock前缀的读修改写指令也能原子性执行。带lock前缀的指令在操作时会锁住总线,使自身的执行即使在多处理器间也是原子性执行的。xchg指令不带lock前缀也是原子性执行,也就是说xchg执行时默认会锁内存总线。原子性操作是线程间同步的基础,linux专门定义了一种只进行原子操作的类型atomic_t,并提供相关的原子读写调用API
/** * atomic_inc - increment atomic variable * @v: pointer of type atomic_t * * Atomically increments @v by 1. */ static inline void atomic_inc(atomic_t *v) { asm volatile(LOCK_PREFIX "incl %0" : "+m" (v->counter)); } /** * atomic_dec - decrement atomic variable * @v: pointer of type atomic_t * * Atomically decrements @v by 1. */ static inline void atomic_dec(atomic_t *v) { asm volatile(LOCK_PREFIX "decl %0" : "+m" (v->counter)); }
带lock前缀的指令执行时才与cache有一点关系
缓存一致性,就是在多处理器系统中,每个cpu都有自己的L1 cache。很可能两个不同cpu的L1 cache中缓存的是同一片内存的内容,如果一个cpu更改了自己被缓存的内容,它要保证另一个cpu读这块数据时也要读到这个最新的。怎么保证??所以才有这个东西-----
barrier的定义:
#define barrier() __asm__ __volatile__("": : :"memory") 内存的变量值都改变了,之前存在寄存器里的变量副本无效---__volatitle____volatitle__是防止编译器移动该指令的位置或者把它优化掉。"memory",是提示编译器该指令对内存修改,防止使用某个寄存器中已经load 的内存的值
但是多核环境中内存的可见性和CPU执行顺序不能通过volatile来保障,而是依赖于CPU内存屏障
#ifdef CONFIG_SMP #define smp_mb() mb() #else #define smp_mb() barrier() #endif
#ifdef CONFIG_X86_32 /* * Some non-Intel clones support out of order store. wmb() ceases to be a * nop for these. */ #define mb() alternative("lock; addl $0,0(%%esp)", "mfence", X86_FEATURE_XMM2) #define rmb() alternative("lock; addl $0,0(%%esp)", "lfence", X86_FEATURE_XMM2) #define wmb() alternative("lock; addl $0,0(%%esp)", "sfence", X86_FEATURE_XMM) #else #define mb() asm volatile("mfence":::"memory") #define rmb() asm volatile("lfence":::"memory") #define wmb() asm volatile("sfence" ::: "memory") #endif
64位x86,肯定有mfence、lfence和sfence三条指令,而32位的x86系统则不一定,所以需要进一步查看cpu是否支持这三条新的指令,不行则用加锁的方式来增加内存屏障。
SFENCE,LFENCE,MFENCE指令提供了高效的方式来保证读写内存的排序,这种操作发生在产生弱排序数据的程序和读取这个数据的程序之间。
SFENCE——串行化发生在SFENCE指令之前的写操作但是不影响读操作。
LFENCE——串行化发生在SFENCE指令之前的读操作但是不影响写操作。
MFENCE——串行化发生在MFENCE指令之前的读写操作。
sfence:在sfence指令前的写操作当必须在sfence指令后的写操作前完成。
lfence:在lfence指令前的读操作当必须在lfence指令后的读操作前完成。
mfence:在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成。
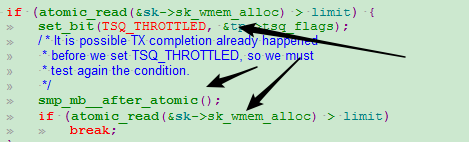
PS:对于那些不提供内存屏障语义的原子操作来说,为了保证其本身不被重排序,还需要显式的在其前面或后面使用内存屏障。Linux内核提供了两个函数,分别是smp_mb__before_atomic()用于原子操作函数的前面,和smp_mb__after_atomic()用于原子操作函数的后面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号