linux 网络编程 基础
网络编程基础
大端小端:
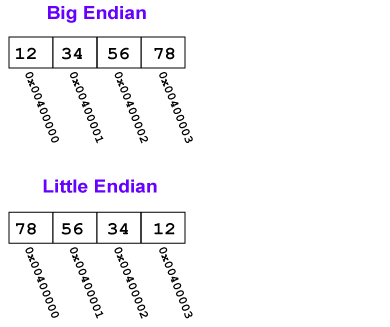
字节序,顾名思义,指字节在内存中存储的顺序。比如一个int32_t类型的数值占用4个字节,这4个字节在内存中的排列顺序就是字节序。字节序有两种:
(1)小端字节序(Little endinan),数值低位存储在内存的低地址,高位存储在内存的高地址;
(2)大端字节序(Big endian),数值高位存储在内存的低地址,低位存储在内存的高地址。
网络字节顺序采用big endian排序方式。
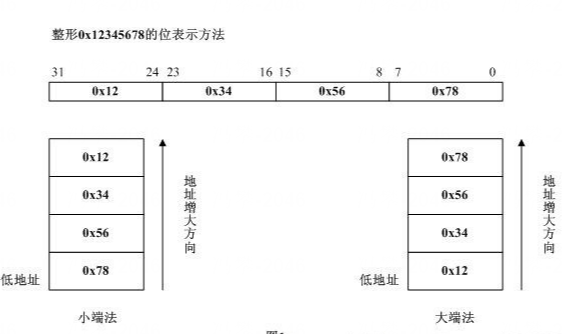
A load word or store word instruction uses only one memory address. The lowest address of the four bytes is used for the address of a block of four contiguous bytes.
How is a 32-bit pattern held in the four bytes of memory? There are 32 bits in the four bytes and 32 bits in the pattern, but a choice has to be made about which byte of memory gets what part of the pattern. There are two ways that computers commonly do this:
Big Endian Byte Order: The most significant byte (the "big end") of the data is placed at the byte with the lowest address. The rest of the data is placed in order in the next three bytes in memory.
Little Endian Byte Order: The least significant byte (the "little end") of the data is placed at the byte with the lowest address. The rest of the data is placed in order in the next three bytes in memory.
In these definitions, the data, a 32-bit pattern, is regarded as a 32-bit unsigned integer. The "most significant" byte is the one for the largest powers of two: 231, ..., 224. The "least significant" byte is the one for the smallest powers of two: 27, ..., 20.
For example, say that the 32-bit pattern 0x12345678 is at address 0x00400000. The most significant byte is 0x12; the least significant is 0x78. Here are the two byte orders:
Within a byte the order of the bits is the same for all computers (no matter how the bytes themselves are arranged).
- 套接字编程需要指定套接字地址作为参数,不同的协议族有不同的地址结构,比如以太网其结构为sockaddr_in。
- 通用套接字:
struct sockaddr { sa_family_t sa_family; /* address family, AF_xxx 16Bytes */ char sa_data[14]; /* 14 bytes of protocol address */ }; -
实际使用的套接字结构
- 以bind函数为例:
bind(int sockfd, //套接字文件描述符
struct sockaddr *uaddr,//套接字结构地址
int addr_len)//套接字地址结构长度
使用struct sockaddr 为通用结构体,在以太网中,一般使用结构 sockaddr_in
/* Structure describing an Internet (IP) socket address. */
#define __SOCK_SIZE__ 16 /* sizeof(struct sockaddr) */ struct sockaddr_in { __kernel_sa_family_t sin_family; /* Address family */ __be16 sin_port; /* Port number */ struct in_addr sin_addr; /* Internet address */ /* Pad to size of `struct sockaddr'. */ unsigned char __pad[__SOCK_SIZE__ - sizeof ( short int ) - sizeof (unsigned short int ) - sizeof ( struct in_addr)]; };
- 结构 sockaddr 和结构 sockaddr_in的关

第二章:TCP网络编程流程
tcp网络编程主要采取C/S模式,即客户端(C)、服务器(S)模式
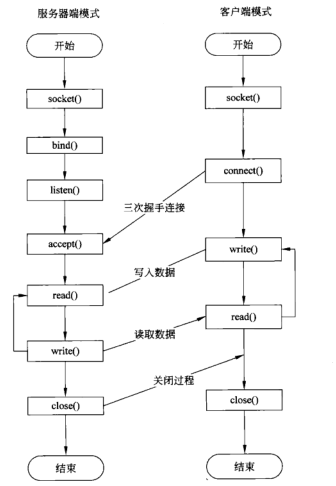
- 创建网路套接字接口函数socket
int socket (int family, int type, int protocol)
int family
- AF_UNIX : Sockets for interprocess communication in the local computer.
- AF_INET : Sockets of the TCP/IP protocol family based on the Internet Protocol Version 4
- AF_INET6 : TCP/IP protocol family based on the new Internet Protocol, Version 6.
- AF_IPX : IPX protocol family.

int type
- SOCK_STREAM (stream socket) specifies a stream-oriented, reliable, in-order full duplex connection between two sockets.
- SOCK_DGRAM (datagram socket) specifies a connectionless, unreliable datagram service, where packets may be transported out of order.
- SOCK_RAW (raw socket).

int protocol
- TCP is always selected for the SOCK_STREAM socket type, and UDP is always used as the transport protocol for SOCK_DGRAM


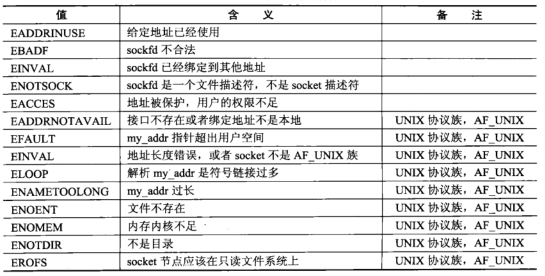
int bind(int sockfd, struct sockaddr *uaddr, socketlen_t uaddrlen)
- sockfd为 socket()函数创建返回的fd
- uaddr 指向一个包含了ip地址 端口等信息
- uaddrlen 是sockaddr的长度
- bind 可以指定Ip地址或者端口 可以都指定

int listen(int sockfd, int backlog)
- sockf为socket创建成功返回的fd
- backlog 表示在accept 函数处理之前在等待队列中允许最多的客户端个数

int accept(int sockfd, struct sockaddr *addr, socketlen_t * addrlen)
- accept 函数可以得到成功连接客户端的ip地址、端口信息和协议族等信息
- accpet返回值是新连接客户端套接字的描述符
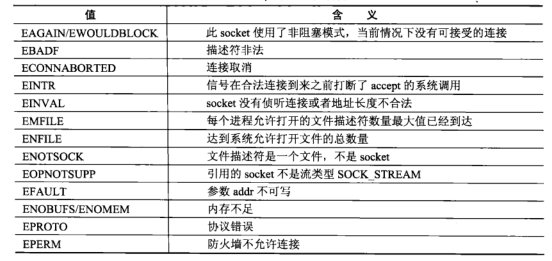
数据的IO和复用
常用的数据I/O函数有recv/send() readv/writev recvmsg/sendmsg
int recv(int sockfd, void *buf, size_t len, int flag)
- recv 函数的参数flag用于设置接收数据的方式
- recv函数返回成功接收到的字节数,错误时返回-1

int send(int sockfd, const void *buf, size_t len, int flags)
- send函数成功发送的字节数,发生错误是返回-1
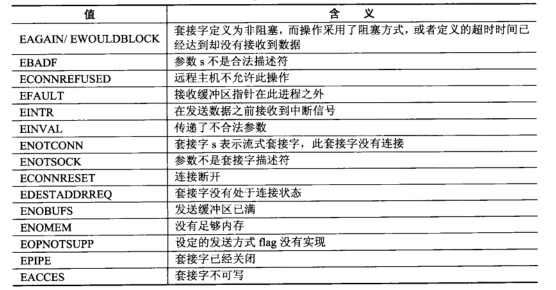
int recvmsg (int sockfd, struct msghdr *msg, int flags)
- recvmsg 表示从sockd 中接收数据放在缓冲区,其操作方式由flags指定
- 其返回值表示成功接收到的字节数,-1时表示发生错误
- 当对端使用正常方式关闭连接时,返回值为0,如调用close

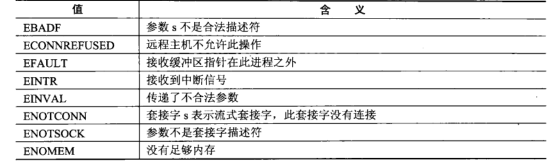
- flags含义:
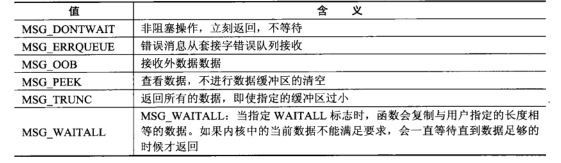
I/O模型
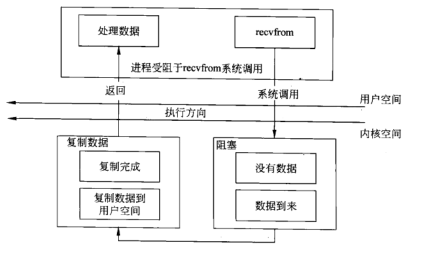
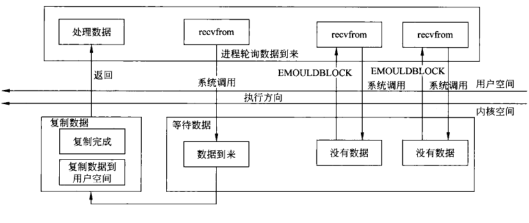
I/O复用

select函数简介
int select(int maxfdp1, fd_set *readset, fd_set *writeset, fd_set *exceptset, const struct timeval *timeout);
- maxfdp1:指定待测试的描述符个数,它的值是待测试的最大描述符加1
- readset、writeset、exceptset:指定让内核测试读、写、异常条件的描述符
- timeout:最长等待时间
- timeout参数的三种可能:
a.设为空指针:永远等待下去,仅在有描述符就绪时才返回
b.正常设置timeout,在不超过timeout设置的时间内,在有描述符就绪时返回
c.将timeout.tv_sec和timeout.tv_usec都设为0:检查描述符后立即返回(轮询)

非阻塞I/O
-
非阻塞connect 以及非阻塞accept
- 以及调用select 的非阻塞I/O
进程间通信
- Unix域协议
管道

#include <unistd.h>
int pipe(int pipefd[2]);
成功调用 pipe 函数之后,可以对写入端描述符 pipefd[1] 调用 write ,向管道里面写入数据,比如
write(pipefd[1],wbuf,count);
一旦向管道的写入端写入数据后,就可以对读取端描述符 pipefd[0] 调用 read
管道有如下三条性质:
· 只有当所有的写入端描述符都已关闭,且管道中的数据都被读出,对读取端描述符调用 read 函数
才会返回 0 (即读到 EOF 标志)。
· 如果所有读取端描述符都已关闭,此时进程再次往管道里面写入数据,写操作会失败, errno 被设
置为 EPIPE ,同时内核会向写入进程发送一个 SIGPIPE 的信号。
· 当所有的读取端和写入端都关闭后,管道才能被销毁
这种管道因为没有实体文件与之关联,适用于有亲缘关系的任意两个进程之间通信
命名管道 FIFO
命名管道就是为了解决无名管道的这个问题而引入的。 FIFO 与管道类似,最大的差别就是有实体
文件与之关联。由于存在实体文件,不相关的没有亲缘关系的进程也可以通过使用 FIFO 来实现进程之
间的通信;
从外表看,我是一个 FIFO 文件,有文件名,任何进程通过文件名都可以打开我
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);
一旦 FIFO 文件创建好了,就可以把它用于进程间的通信了。一般的文件操作函数如 open 、 read 、 write 、 close 、 unlink 等都可以用在 FIFO 文件
上; 对 FIFO 文件推荐的使用方法是,两个进程一个以只读模式( O_RDONLY )打开 FIFO 文件,另一个以只写模式( O_WRONLY )打开 FIFO 文
件。这样负责写入的进程写入 FIFO 的内容就可以被负责读取的进程读到,从而达到通信的目的
System V 消息队列 信号量 共享内存
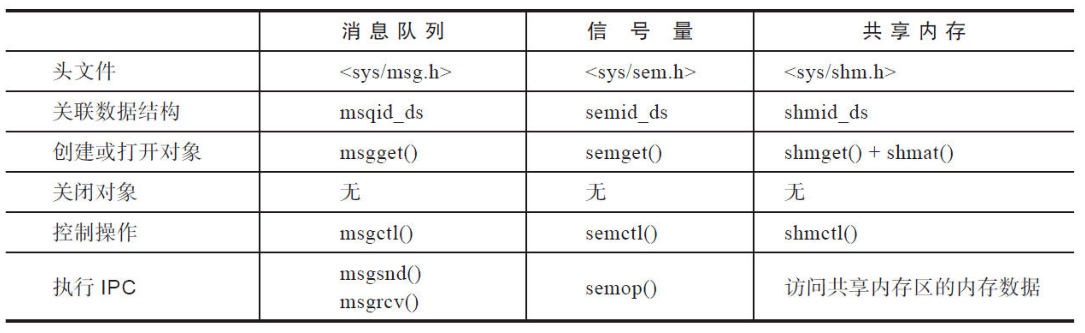
管道和 FIFO 都是字节流的模型,这种模型不存在记录边界,如果从管道里面读出 100
个字节,你无法确认这 100 个字节是单次写入的 100 字节,还是分 10 次每次 10 字节写入的,你也无法知
晓这 100 个字节是几个消息。管道或 FIFO 里的数据如何解读,完全取决于写入进程和读取进程之间的约
定;System V 消息队列是优于管道和 FIFO 的。原因是消息队列机
制中,双方是通过消息来通信的,无需花费精力从字节流中解析出完整的消息;
System V 消息队列比管道或 FIFO 优越的第二个地方在于每条消息都有 type 字段,消息的读取进程可
以通过 type 字段来选择自己感兴趣的消息,也可以根据 type 字段来实现按消息的优先级进行读取,而不
一定要按照消息生成的顺序来依次读取
一般来说,信号量是和某种预先定义的资源相关联的。信号量元素的值,表示与之关联的资源的个数
一旦将信号量和某种资源关联起来,就起到了同步使用某种资源的功效
共享内存是所有 IPC 手段中最快的一种。它之所以快是因为共享内存一旦映射到进程的地址空间,
进程之间数据的传递就不须要涉及内核了。
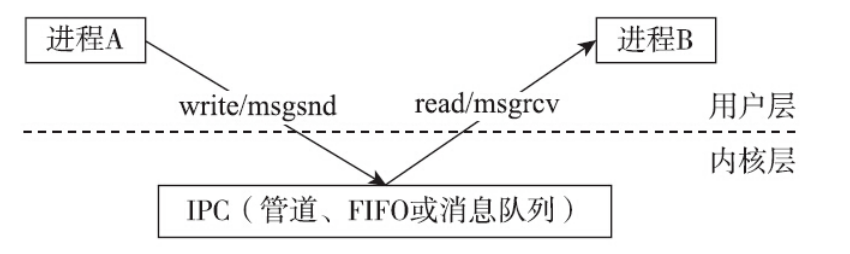
回顾一下前面已经讨论过的管道、 FIFO 和消息队列,任意两个进程之间想要交换信息,都必须通
过内核,内核在其中发挥了中转站的作用:
· 发送信息的一方,通过系统调用( write 或 msgsnd )将信息从用户层拷贝到内核层,由内核暂存这
部分信息。
· 提取信息的一方,通过系统调用( read 或 msgrcv )将信息从内核层提取到应用层
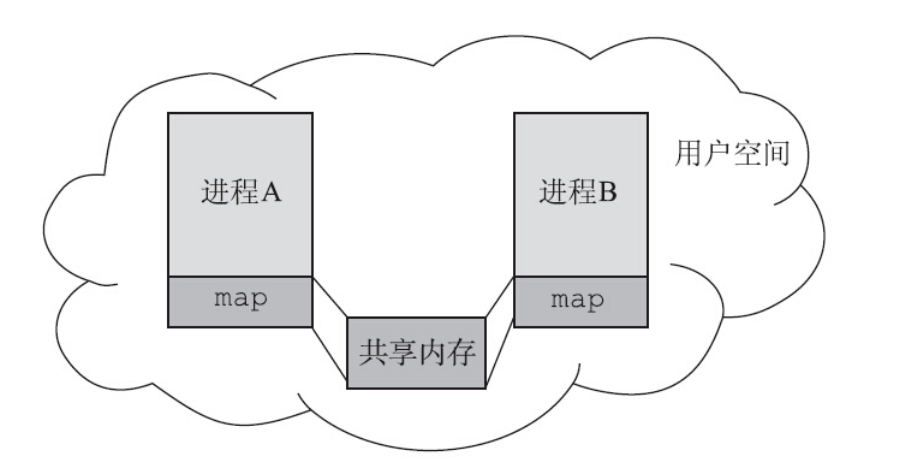
经验:
- epoll 或者 select 处理事件时,可读事件时,read返回值-1,如果errno不为EAGAIN,可以认为失败,并关闭fd。read返回0,说明对方断开连接,此时也需要关闭fd。如果链路断了,如拔掉网线,需要是用keepalive来触发可写事件
- 本地UDP发送过快也是会丢包的。非阻塞情况下的unix domain socket哪怕是STREAM的也是会丢包的
- 使用unix socket通信相比于本地udp通信减少了校验和的计算。使用阻塞函数时,unix domain socket可以保证不丢包不乱序,但是当发送缓冲区满了的话则会阻塞。使用非阻塞操作时经测试会丢包
- 使用setsockopt设置发送缓冲时,SO_RCVBUF和SO_SNDBUF的最大值受系统设置限制,可以使用SO_RCVBUFFORCE和SO_SNDBUFFORCE来无视系统设置
- SIGPIPE信号,网络编程时一定要处理该信号。同样一般要设置的还有SO_REUSEADDR。当客户端close连接时,若server继续发送数据,会收到RST,继续写就会SIGPIPE
- 网络编程对事件进行封装,提供注册回调函数,在可读、可写时进行函数调用。一般用法,针对非阻塞情况,初始化时将可读事件注册,需要写的时候先写,写不下去的时候(errno=EAGAIN)再挂上可写事件,只要发送缓冲区还有空间,就是可写的
- 基于事件的编程框架,需要记录最后一次成功read或write的时间,如果idletime大于阈值,直接close
-
服务器编程可以设置最大的fd个数,然后一次性申请FileEvent数组,之后由fd到事件查询代价O(1)
针对非阻塞socket,connect返回EINPROGRESS时需要将fd加到可写事件监视集合中,当select()或者poll()返回可写事件时,需要用getsockopt去读SOL_SOCKET层面的SO_ERROR选项,SO_ERROR为0表示连接成功,否则为连接失败
epoll ET模式的处理方式。读:只要可读就一直读,一直读到返回0,或者error = EAGAIN。写:只要可写就一直写,知道数据发送完,或者errno = EAGAIN
socket read缓冲区最大值TCP可查看”/proc/sys/net/ipv4/tcp_rmem”, udp 65536
实现定时器时通常办法是select/poll/epoll接口,精度毫秒级;还有就是新增的系统调用timerfd_create 把时间变成了一个文件描述符,该“文件”在定时器超时的那一刻变得可读,高于poll的精度
在主动关闭连接时,可以先shutdown(fd, SHUT_WR)关闭写端,等对方close时再关闭读端。这样子的好处是如果对方已经发送了一些数据,这些数据不会漏收。这就要求对端在read返回0之后关闭连接或者shutdown写端
网络编程一种比较好的模型是“one loop per thread”,如果事件库不是线程安全的,则需要使用pipe或者
socketpair通知,子线程接受到通知(fd可读)后处理,kernel 2.6.22加入了eventfd,是更好的通知方法
TCP Nagle算法和TCP Delayed Ack机制可能会导致网络延时(Linux 40ms, Windows 200ms),最容易产生问题的就是"Write-Write-Read”这种模型,发送端的Nagle算法和接收端的Delayed Ack会导致一直等到接收端delayed ack超时后数据才发送出去
accept返回EMFILE,进程描述符用完了,无法创建新的socket,也无法close连接,会导致不断通知该可读事件,程序busy loop,cpu 100%,解决方法是事先准备一个nullfd=open(“/dev/null”),close该fd,accept,close socket,然后再nullfd=open(“/dev/null”),缺点是该方法线程不安全,多线程accept可能导致nullfd用于新socket创建,然后又处于busy loop中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号