
python
代码中的注释
- 单行注释 - 以#和空格开头的部分
- 多行注释 - 三个引号开头,三个引号结尾
变量和类型
- 整型:Python中可以处理任意大小的整数(Python 2.x中有int和long两种类型的整数,但这种区分对Python来说意义不大,因此在Python 3.x中整数只有int这一种了),而且支持二进制(如0b100,换算成十进制是4)、八进制(如0o100,换算成十进制是64)、十进制(100)和十六进制(0x100,换算成十进制是256)的表示法。
- 浮点型:浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,浮点数除了数学写法(如123.456)之外还支持科学计数法(如1.23456e2)。
- 字符串型:字符串是以单引号或双引号括起来的任意文本,比如'hello'和"hello",字符串还有原始字符串表示法、字节字符串表示法、Unicode字符串表示法,而且可以书写成多行的形式(用三个单引号或三个双引号开头,三个单引号或三个双引号结尾)。
- 布尔型:布尔值有True、False两种值(请注意大小写)
- 复数型:形如3+5j,跟数学上的复数表示一样,唯一不同的是虚部的i换成了j。
变量命名
- 硬性规则:
- 变量名由字母(广义的Unicode字符,不包括特殊字符)、数字和下划线构成,数字不能开头。
- 大小写敏感
- 不要跟关键字和系统保留字冲突。
- PEP 8要求:
- 用小写字母拼写,多个单词用下划线连接。
- 受保护的实例属性用单个下划线开头。
- 私有的实例属性用两个下划线开头。
变量的使用
下面通过几个例子来说明变量的类型和变量使用。
"""
使用变量保存数据并进行加减乘除运算
"""
a = 321
b = 12
print(a + b) # 333
print(a - b) # 309
print(a * b) # 3852
print(a / b) # 26.75
使用type函数对变量的类型进行检查。
"""
使用type()检查变量的类型
"""
a = 100
b = 12.345
c = 1 + 5j
d = 'hello, world'
e = True
print(type(a)) # <class 'int'>
print(type(b)) # <class 'float'>
print(type(c)) # <class 'complex'>
print(type(d)) # <class 'str'>
print(type(e)) # <class 'bool'>
使用Python中内置的函数对变量类型进行转换。
int():将一个数值或字符串转换成整数,可以指定进制。float():将一个字符串转换成浮点数。str():将指定的对象转换成字符串形式,可以指定编码。chr():将整数转换成该编码对应的字符串(一个字符)。ord():将字符串(一个字符)转换成对应的编码(整数)。
下面的代码通过键盘输入两个整数来实现对两个整数的算术运算。
"""
使用input()函数获取键盘输入(字符串)
使用int()函数将输入的字符串转换成整数
使用print()函数输出带占位符的字符串
"""
a = int(input('a = '))
b = int(input('b = '))
print('%d + %d = %d' % (a, b, a + b))
print('%d - %d = %d' % (a, b, a - b))
print('%d * %d = %d' % (a, b, a * b))
print('%d / %d = %f' % (a, b, a / b))
print('%d // %d = %d' % (a, b, a // b))
print('%d %% %d = %d' % (a, b, a % b))
print('%d ** %d = %d' % (a, b, a ** b))
说明:使用占位符语法,其中
%d是整数的占位符,%f是小数的占位符,%%表示百分号(因为百分号代表了占位符,所以带占位符的字符串中要表示百分号必须写成%%),字符串之后的%后面跟的变量值会替换掉占位符。
运算符
下表大致按优先级从高到低的顺序。
| 运算符 | 描述 |
|---|---|
[] [:] |
下标,切片 |
** |
指数 |
~ + - |
按位取反, 正负号 |
* / % // |
乘,除,模,整除 |
+ - |
加,减 |
>> << |
右移,左移 |
& |
按位与 |
^ | |
按位异或,按位或 |
<= < > >= |
小于等于,小于,大于,大于等于 |
== != |
等于,不等于 |
is is not |
身份运算符 |
in not in |
成员运算符 |
not or and |
逻辑运算符 |
= += -= *= /= %= //= **= &= ` |
= ^=` `>>=` `<<=` |
说明: 用括号来确保运算的执行顺序。
赋值运算符
"""
赋值运算符和复合赋值运算符
"""
a = 10
b = 3
a += b # 相当于:a = a + b
a *= a + 2 # 相当于:a = a * (a + 2)
print(a) # 算一下这里会输出什么
比较运算符和逻辑运算符
比较运算符也称为关系运算符,包括==、!=、<、>、<=、>=
逻辑运算符是and、or和not。
"""
比较运算符和逻辑运算符的使用
"""
flag0 = 1 == 1
flag1 = 3 > 2
flag2 = 2 < 1
flag3 = flag1 and flag2
flag4 = flag1 or flag2
flag5 = not (1 != 2)
print('flag0 =', flag0) # flag0 = True
print('flag1 =', flag1) # flag1 = True
print('flag2 =', flag2) # flag2 = False
print('flag3 =', flag3) # flag3 = False
print('flag4 =', flag4) # flag4 = True
print('flag5 =', flag5) # flag5 = False
说明:
,进行分隔,输出的内容之间默认以空格分开。
分支结构
if语句的使用
要构造分支结构使用if、elif和else关键字。
"""
用户身份验证
"""
username = input('请输入用户名: ')
password = input('请输入口令: ')
# 用户名是admin且密码是123456则身份验证成功否则身份验证失败
if username == 'admin' and password == '123456':
print('身份验证成功!')
else:
print('身份验证失败!')
通常使用4个空格
可以使用if...elif...else...结构或者嵌套的if...else...结构,
"""
3x - 5 (x > 1)
f(x) = x + 2 (-1 <= x <= 1)
5x + 3 (x < -1)
"""
x = float(input('x = '))
if x > 1:
y = 3 * x - 5
elif x >= -1:
y = x + 2
else:
y = 5 * x + 3
print('f(%.2f) = %.2f' % (x, y))
"""
分段函数求值(嵌套)
"""
x = float(input('x = '))
if x > 1:
y = 3 * x - 5
else:
if x >= -1:
y = x + 2
else:
y = 5 * x + 3
print('f(%.2f) = %.2f' % (x, y))
说明: 能使用扁平化的结构时就不要使用嵌套。
循环结构
循环结构就一种是for-in循环,一种是while循环。
for-in循环
知道循环执行的次数或者要对一个容器进行迭代,推荐使用for-in循环
"""
用for循环实现1~100求和
"""
sum = 0
for x in range(101):
sum += x
print(sum)
range的用法非常灵活,例子:
range(101):可以用来产生0到100范围的整数,需要注意的是取不到101。range(1, 101):可以用来产生1到100范围的整数,相当于前面是闭区间后面是开区间。range(1, 101, 2):可以用来产生1到100的奇数,其中2是步长,即每次数值递增的值。range(100, 0, -2):可以用来产生100到1的偶数,其中-2是步长,即每次数字递减的值。
知道了这一点,我们可以用下面的代码来实现1~100之间的偶数求和。
"""
用for循环实现1~100之间的偶数求和
"""
sum = 0
for x in range(2, 101, 2):
sum += x
print(sum)
"""
用for循环实现1~100之间的偶数求和
"""
sum = 0
for x in range(1, 101):
if x % 2 == 0:
sum += x
print(sum)
while循环
不知道具体循环次数的循环结构,推荐使用while循环。
"""
猜数字游戏
"""
import random
answer = random.randint(1, 100)
counter = 0
while True:
counter += 1
number = int(input('请输入: '))
if number < answer:
print('大一点')
elif number > answer:
print('小一点')
else:
print('恭喜你猜对了!')
break
print('你总共猜了%d次' % counter)
if counter > 7:
print('你的智商余额明显不足')
"""
输出乘法口诀表(九九表)
"""
for i in range(1, 10):
for j in range(1, i + 1):
print('%d*%d=%d' % (i, j, i * j), end='\t')
print()
定义函数
用def关键字来定义函数,和变量一样每个函数也有名字,而且命名规则跟变量的命名规则是一致的。在函数名后面的圆括号中放置传递给函数的参数,函数执行完成后通过return关键字来返回一个值
"""
输入M和N计算C(M,N)
"""
def fac(num):
"""求阶乘"""
result = 1
for n in range(1, num + 1):
result *= n
return result
m = int(input('m = '))
n = int(input('n = '))
# 当需要计算阶乘的时候不用再写循环求阶乘而是直接调用已经定义好的函数
print(fac(m) // fac(n) // fac(m - n))
说明: Python的
math模块中已经有一个名为factorial函数实现了阶乘运算
函数的参数
函数的参数可以有默认值,也支持使用可变参数
from random import randint
def roll_dice(n=2):
"""摇色子"""
total = 0
for _ in range(n):
total += randint(1, 6)
return total
def add(a=0, b=0, c=0):
"""三个数相加"""
return a + b + c
# 如果没有指定参数那么使用默认值摇两颗色子
print(roll_dice())
# 摇三颗色子
print(roll_dice(3))
print(add())
print(add(1))
print(add(1, 2))
print(add(1, 2, 3))
# 传递参数时可以不按照设定的顺序进行传递
print(add(c=50, a=100, b=200))
不确定参数个数,用可变参数
# 在参数名前面的*表示args是一个可变参数
def add(*args):
total = 0
for val in args:
total += val
return total
# 在调用add函数时可以传入0个或多个参数
print(add())
print(add(1))
print(add(1, 2))
print(add(1, 2, 3))
print(add(1, 3, 5, 7, 9))
用模块管理函数
每个文件就代表了一个模块(module),在不同的模块中可以有同名的函数,在使用函数的时候我们通过import关键字导入指定的模块就可以区分到底要使用的是哪个模块中的函数。
module1.py
def foo():
print('hello, world!')
module2.py
def foo():
print('goodbye, world!')
test.py
from module1 import foo
# 输出hello, world!
foo()
from module2 import foo
# 输出goodbye, world!
foo()
----------------------
import module1 as m1
import module2 as m2
m1.foo()
m2.foo()
-------------------------
# 覆盖问题!
from module1 import foo
from module2 import foo
# 输出goodbye, world!
foo()
--------------------------
from module2 import foo
from module1 import foo
# 输出hello, world!
foo()
-------------------------
import module3
# 导入module3时 不会执行模块中if条件成立时的代码 因为模块的名字是module3而不是__main__
module3.py
def foo():
pass
def bar():
pass
# __name__是一个隐含的变量它代表了模块的名字
# 只有被解释器直接执行的模块的名字才是__main__
if __name__ == '__main__':
print('call foo()')
foo()
print('call bar()')
bar()
变量的作用域
Python查找一个变量时会按照“局部作用域”、“嵌套作用域”、“全局作用域”和“内置作用域”的顺序进行搜索,所谓的“内置作用域”就是Python内置的那些标识符,我们之前用过的input、print、int等都属于内置作用域。
在foo函数中修改全局作用域中的a
def foo():
global a
a = 200
print(a) # 200
if __name__ == '__main__':
a = 100
foo()
print(a) # 200
使用global关键字来指示foo函数中的变量a来自于全局作用域,如果全局作用域中没有a,那么下面一行的代码就会定义变量a并将其置于全局作用域。若要函数内部的函数能够修改嵌套作用域中的变量,可以使用nonlocal关键字来指示变量来自于嵌套作用域
在实际开发中,尽量减少对全局变量的使用
Python代码按照下面的格式进行书写
def main():
# Todo: Add your code here
pass
if __name__ == '__main__':
main()
字符串和常用数据结构
s1 = 'hello, world!'
s2 = "hello, world!"
# 以三个双引号或单引号开头的字符串可以折行
s3 = """
hello,
world!
"""
print(s1, s2, s3, end='')
\n是表示换行;\t是表示制表符。所以如果想在字符串中表示'要写成\',同理想表示\要写成\\。
在\后面还可以跟一个八进制或者十六进制数来表示字符,例如\141和\x61都代表小写字母a,前者是八进制的表示法,后者是十六进制的表示法。也可以在\后面跟Unicode字符编码来表示字符,例如\u9a86\u660a代表的是中文“骆昊”。
如果不希望字符串中的\表示转义,我们可以通过在字符串的最前面加上字母r来加以说明
s1 = r'\'hello, world!\''
s2 = r'\n\\hello, world!\\\n'
print(s1, s2, end='')
使用+运算符来实现字符串的拼接,可以使用*运算符来重复一个字符串的内容,可以使用in和not in来判断一个字符串是否包含另外一个字符串(成员运算),我们也可以用[]和[:]运算符从字符串取出某个字符或某些字符(切片运算),
s1 = 'hello ' * 3
print(s1) # hello hello hello
s2 = 'world'
s1 += s2
print(s1) # hello hello hello world
print('ll' in s1) # True
print('good' in s1) # False
str2 = 'abc123456'
# 从字符串中取出指定位置的字符(下标运算)
print(str2[2]) # c
# 字符串切片(从指定的开始索引到指定的结束索引)
print(str2[2:5]) # c12
print(str2[2:]) # c123456
print(str2[2::2]) # c246
print(str2[::2]) # ac246
print(str2[::-1]) # 654321cba
print(str2[-3:-1]) # 45
在Python中,我们还可以通过一系列的方法来完成对字符串的处理,代码如下所示。
str1 = 'hello, world!'
# 通过内置函数len计算字符串的长度
print(len(str1)) # 13
# 获得字符串首字母大写的拷贝
print(str1.capitalize()) # Hello, world!
# 获得字符串每个单词首字母大写的拷贝
print(str1.title()) # Hello, World!
# 获得字符串变大写后的拷贝
print(str1.upper()) # HELLO, WORLD!
# 从字符串中查找子串所在位置
print(str1.find('or')) # 8
print(str1.find('shit')) # -1
# 与find类似但找不到子串时会引发异常
# print(str1.index('or'))
# print(str1.index('shit'))
# 检查字符串是否以指定的字符串开头
print(str1.startswith('He')) # False
print(str1.startswith('hel')) # True
# 检查字符串是否以指定的字符串结尾
print(str1.endswith('!')) # True
# 将字符串以指定的宽度居中并在两侧填充指定的字符
print(str1.center(50, '*'))
# 将字符串以指定的宽度靠右放置左侧填充指定的字符
print(str1.rjust(50, ' '))
str2 = 'abc123456'
# 检查字符串是否由数字构成
print(str2.isdigit()) # False
# 检查字符串是否以字母构成
print(str2.isalpha()) # False
# 检查字符串是否以数字和字母构成
print(str2.isalnum()) # True
str3 = ' jackfrued@126.com '
print(str3)
# 获得字符串修剪左右两侧空格之后的拷贝
print(str3.strip())
可以用下面的方式来格式化输出字符串。
a, b = 5, 10
print('%d * %d = %d' % (a, b, a * b))
也可以用字符串提供的方法来完成字符串的格式
a, b = 5, 10
print('{0} * {1} = {2}'.format(a, b, a * b))
Python 3.6以后,格式化字符串还有更为简洁的书写方式,就是在字符串前加上字母f
a, b = 5, 10
print(f'{a} * {b} = {a * b}')
列表
列表(list),是一种结构化的、非标量类型,它是值的有序序列,每个值都可以通过索引进行标识,定义列表可以将列表的元素放在[]中,多个元素用,进行分隔,可以使用for循环对列表元素进行遍历,也可以使用[]或[:]运算符取出列表中的一个或多个元素。
list1 = [1, 3, 5, 7, 100]
print(list1) # [1, 3, 5, 7, 100]
# 乘号表示列表元素的重复
list2 = ['hello'] * 3
print(list2) # ['hello', 'hello', 'hello']
# 计算列表长度(元素个数)
print(len(list1)) # 5
# 下标(索引)运算
print(list1[0]) # 1
print(list1[4]) # 100
# print(list1[5]) # IndexError: list index out of range
print(list1[-1]) # 100
print(list1[-3]) # 5
list1[2] = 300
print(list1) # [1, 3, 300, 7, 100]
# 通过循环用下标遍历列表元素
for index in range(len(list1)):
print(list1[index])
# 通过for循环遍历列表元素
for elem in list1:
print(elem)
# 通过enumerate函数处理列表之后再遍历可以同时获得元素索引和值
for index, elem in enumerate(list1):
print(index, elem)
#========================================================
list1 = [1, 3, 5, 7, 100]
# 添加元素
list1.append(200)
list1.insert(1, 400)
# 合并两个列表
# list1.extend([1000, 2000])
list1 += [1000, 2000]
print(list1) # [1, 400, 3, 5, 7, 100, 200, 1000, 2000]
print(len(list1)) # 9
# 先通过成员运算判断元素是否在列表中,如果存在就删除该元素
if 3 in list1:
list1.remove(3)
if 1234 in list1:
list1.remove(1234)
print(list1) # [1, 400, 5, 7, 100, 200, 1000, 2000]
# 从指定的位置删除元素
list1.pop(0)
list1.pop(len(list1) - 1)
print(list1) # [400, 5, 7, 100, 200, 1000]
# 清空列表元素
list1.clear()
print(list1) # []
列表通过切片操作可以实现对列表的复制或者将列表中的一部分取出来创建出新的列表
fruits = ['grape', 'apple', 'strawberry', 'waxberry']
fruits += ['pitaya', 'pear', 'mango']
# 列表切片
fruits2 = fruits[1:4]
print(fruits2) # apple strawberry waxberry
# 可以通过完整切片操作来复制列表
fruits3 = fruits[:]
print(fruits3) # ['grape', 'apple', 'strawberry', 'waxberry', 'pitaya', 'pear', 'mango']
fruits4 = fruits[-3:-1]
print(fruits4) # ['pitaya', 'pear']
# 可以通过反向切片操作来获得倒转后的列表的拷贝
fruits5 = fruits[::-1]
print(fruits5) # ['mango', 'pear', 'pitaya', 'waxberry', 'strawberry', 'apple', 'grape']
对列表的排序操作。
list1 = ['orange', 'apple', 'zoo', 'internationalization', 'blueberry']
list2 = sorted(list1)
# sorted函数返回列表排序后的拷贝不会修改传入的列表
# 函数的设计就应该像sorted函数一样尽可能不产生副作用
list3 = sorted(list1, reverse=True)
# 通过key关键字参数指定根据字符串长度进行排序而不是默认的字母表顺序
list4 = sorted(list1, key=len)
print(list1)
print(list2)
print(list3)
print(list4)
# 给列表对象发出排序消息直接在列表对象上进行排序
list1.sort(reverse=True)
print(list1)
生成式和生成器
用列表的生成式语法来创建列表
f = [x for x in range(1, 10)]
print(f)
f = [x + y for x in 'ABCDE' for y in '1234567']
print(f)
# 用列表的生成表达式语法创建列表容器
# 用这种语法创建列表之后元素已经准备就绪所以需要耗费较多的内存空间
f = [x ** 2 for x in range(1, 1000)]
print(sys.getsizeof(f)) # 查看对象占用内存的字节数
print(f)
# 请注意下面的代码创建的不是一个列表而是一个生成器对象
# 通过生成器可以获取到数据但它不占用额外的空间存储数据
# 每次需要数据的时候就通过内部的运算得到数据(需要花费额外的时间)
f = (x ** 2 for x in range(1, 1000))
print(sys.getsizeof(f)) # 相比生成式生成器不占用存储数据的空间
print(f)
for val in f:
print(val)
通过yield关键字将一个普通函数改造成生成器函数。下面的代码演示了如何实现一个生成斐波拉切数列的生成器。所谓斐波拉切数列可以通过下面递归的方法来进行定义:
def fib(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
yield a
def main():
for val in fib(20):
print(val)
if __name__ == '__main__':
main()
元组
元组与列表类似也是一种容器数据类型,可以用一个变量(对象)来存储多个数据,不同之处在于元组的元素不能修改,在前面的代码中我们已经不止一次使用过元组了。顾名思义,我们把多个元素组合到一起就形成了一个元组,所以它和列表一样可以保存多条数据。
# 定义元组
t = ('骆昊', 38, True, '四川成都')
print(t)
# 获取元组中的元素
print(t[0])
print(t[3])
# 遍历元组中的值
for member in t:
print(member)
# 重新给元组赋值
# t[0] = '王大锤' # TypeError
# 变量t重新引用了新的元组原来的元组将被垃圾回收
t = ('王大锤', 20, True, '云南昆明')
print(t)
# 将元组转换成列表
person = list(t)
print(person)
# 列表是可以修改它的元素的
person[0] = '李小龙'
person[1] = 25
print(person)
# 将列表转换成元组
fruits_list = ['apple', 'banana', 'orange']
fruits_tuple = tuple(fruits_list)
print(fruits_tuple)
为什么需要元组这样的类型呢?
- 元组中的元素是无法修改的,事实上我们在项目中尤其是多线程环境中可能更喜欢使用的是那些不变对象(一方面一个不变的对象要比可变的对象更加容易维护;另一方面可以方便的被共享访问)。所以结论就是:如果不需要对元素进行添加、删除、修改的时候,可以考虑使用元组,当然如果一个方法要返回多个值,使用元组也是不错的选择。
- 元组在创建时间和占用的空间上面都优于列表。我们可以使用sys模块的getsizeof函数来检查存储同样的元素的元组和列表各自占用了多少内存空间,这个很容易做到。我们也可以在ipython中使用魔法指令%timeit来分析创建同样内容的元组和列表所花费的时间
集合
Python中的集合跟数学上的集合是一致的,不允许有重复元素
创建和使用集合。
# 创建集合的字面量语法
set1 = {1, 2, 3, 3, 3, 2}
print(set1)
print('Length =', len(set1))
# 创建集合的构造器语法
set2 = set(range(1, 10))
set3 = set((1, 2, 3, 3, 2, 1))
print(set2, set3)
# 创建集合的推导式语法(推导式也可以用于推导集合)
set4 = {num for num in range(1, 100) if num % 3 == 0 or num % 5 == 0}
print(set4)
向集合添加和删除元素。
set1.add(4)
set1.add(5)
set2.update([11, 12])
set2.discard(5)
if 4 in set2:
set2.remove(4)
print(set1, set2)
print(set3.pop())
print(set3)
集合的成员、交集、并集、差集等运算。
# 集合的交集、并集、差集、对称差运算
print(set1 & set2)
# print(set1.intersection(set2))
print(set1 | set2)
# print(set1.union(set2))
print(set1 - set2)
# print(set1.difference(set2))
print(set1 ^ set2)
# print(set1.symmetric_difference(set2))
# 判断子集和超集
print(set2 <= set1)
# print(set2.issubset(set1))
print(set3 <= set1)
# print(set3.issubset(set1))
print(set1 >= set2)
# print(set1.issuperset(set2))
print(set1 >= set3)
# print(set1.issuperset(set3))
字典
字典是另一种可变容器模型,跟我们生活中使用的字典是一样的,字典的每个元素都是由一个键和一个值组成的“键值对”,键和值通过冒号分开。
# 创建字典的字面量语法
scores = {'骆昊': 95, '白元芳': 78, '狄仁杰': 82}
print(scores)
# 创建字典的构造器语法
items1 = dict(one=1, two=2, three=3, four=4)
# 通过zip函数将两个序列压成字典
items2 = dict(zip(['a', 'b', 'c'], '123'))
# 创建字典的推导式语法
items3 = {num: num ** 2 for num in range(1, 10)}
print(items1, items2, items3)
# 通过键可以获取字典中对应的值
print(scores['骆昊'])
print(scores['狄仁杰'])
# 对字典中所有键值对进行遍历
for key in scores:
print(f'{key}: {scores[key]}')
# 更新字典中的元素
scores['白元芳'] = 65
scores['诸葛王朗'] = 71
scores.update(冷面=67, 方启鹤=85)
print(scores)
if '武则天' in scores:
print(scores['武则天'])
print(scores.get('武则天'))
# get方法也是通过键获取对应的值但是可以设置默认值
print(scores.get('武则天', 60))
# 删除字典中的元素
print(scores.popitem())
print(scores.popitem())
print(scores.pop('骆昊', 100))
# 清空字典
scores.clear()
print(scores)
面向对象
"把一组数据结构和处理它们的方法组成对象(object),把相同行为的对象归纳为类(class),通过类的封装(encapsulation)隐藏内部细节,通过继承(inheritance)实现类的特化(specialization)和泛化(generalization),通过多态(polymorphism)实现基于对象类型的动态分派。
类和对象
简单的说,类是对象的蓝图和模板,而对象是类的实例。
定义类
用class关键字定义类
class Student(object):
# __init__是一个特殊方法用于在创建对象时进行初始化操作
# 通过这个方法我们可以为学生对象绑定name和age两个属性
def __init__(self, name, age):
self.name = name
self.age = age
def study(self, course_name):
print('%s正在学习%s.' % (self.name, course_name))
# PEP 8要求标识符的名字用全小写多个单词用下划线连接
# 但是部分程序员和公司更倾向于使用驼峰命名法(驼峰标识)
def watch_movie(self):
if self.age < 18:
print('%s只能观看《熊出没》.' % self.name)
else:
print('%s正在观看岛国爱情大电影.' % self.name)
创建和使用对象
当我们定义好一个类之后,可以通过下面的方式来创建对象并给对象发消息。
def main():
# 创建学生对象并指定姓名和年龄
stu1 = Student('骆昊', 38)
# 给对象发study消息
stu1.study('Python程序设计')
# 给对象发watch_av消息
stu1.watch_movie()
stu2 = Student('王大锤', 15)
stu2.study('思想品德')
stu2.watch_movie()
if __name__ == '__main__':
main()
访问可见性
属性和方法的访问权限只有两种,也就是公开的和私有的,如果希望属性是私有的,在给属性命名时可以用两个下划线作为开头
class Test:
def __init__(self, foo):
self.__foo = foo
def __bar(self):
print(self.__foo)
print('__bar')
def main():
test = Test('hello')
# AttributeError: 'Test' object has no attribute '__bar'
test.__bar()
# AttributeError: 'Test' object has no attribute '__foo'
print(test.__foo)
if __name__ == "__main__":
main()
如果你知道更换名字的规则仍然可以访问到它们
class Test:
def __init__(self, foo):
self.__foo = foo
def __bar(self):
print(self.__foo)
print('__bar')
def main():
test = Test('hello')
test._Test__bar()
print(test._Test__foo)
if __name__ == "__main__":
main()
Python程序员会遵循一种命名惯例就是让属性名以单下划线开头来表示属性是受保护的,这种做法并不是语法上的规则,单下划线开头的属性和方法外界仍然是可以访问的,所以更多的时候它是一种暗示或隐喻
面向对象的支柱
面向对象有三大支柱:封装、继承和多态。
@property装饰器
如果想访问属性可以通过属性的getter(访问器)和setter(修改器)方法进行对应的操作。以考虑使用@property包装器来包装getter和setter方法,使得对属性的访问既安全又方便
class Person(object):
def __init__(self, name, age):
self._name = name
self._age = age
# 访问器 - getter方法
@property
def name(self):
return self._name
# 访问器 - getter方法
@property
def age(self):
return self._age
# 修改器 - setter方法
@age.setter
def age(self, age):
self._age = age
def play(self):
if self._age <= 16:
print('%s正在玩飞行棋.' % self._name)
else:
print('%s正在玩斗地主.' % self._name)
def main():
person = Person('王大锤', 12)
person.play()
person.age = 22
person.play()
# person.name = '白元芳' # AttributeError: can't set attribute
if __name__ == '__main__':
main()
__slots__
如果需要限定自定义类型的对象只能绑定某些属性,可以通过在类中定义__slots__变量来进行限定。需要注意的是__slots__的限定只对当前类的对象生效,对子类并不起任何作用。
class Person(object):
# 限定Person对象只能绑定_name, _age和_gender属性
__slots__ = ('_name', '_age', '_gender')
def __init__(self, name, age):
self._name = name
self._age = age
@property
def name(self):
return self._name
@property
def age(self):
return self._age
@age.setter
def age(self, age):
self._age = age
def play(self):
if self._age <= 16:
print('%s正在玩飞行棋.' % self._name)
else:
print('%s正在玩斗地主.' % self._name)
def main():
person = Person('王大锤', 22)
person.play()
person._gender = '男'
# AttributeError: 'Person' object has no attribute '_is_gay'
# person._is_gay = True
静态方法和类方法
写在类中的方法并不需要都是对象方法,例如我们定义一个“三角形”类,通过传入三条边长来构造三角形,并提供计算周长和面积的方法,但是传入的三条边长未必能构造出三角形对象,因此我们可以先写一个方法来验证三条边长是否可以构成三角形,这个方法很显然就不是对象方法,可以使用静态方法来解决这类问题
from math import sqrt
class Triangle(object):
def __init__(self, a, b, c):
self._a = a
self._b = b
self._c = c
@staticmethod
def is_valid(a, b, c):
return a + b > c and b + c > a and a + c > b
def perimeter(self):
return self._a + self._b + self._c
def area(self):
half = self.perimeter() / 2
return sqrt(half * (half - self._a) *
(half - self._b) * (half - self._c))
def main():
a, b, c = 3, 4, 5
# 静态方法和类方法都是通过给类发消息来调用的
if Triangle.is_valid(a, b, c):
t = Triangle(a, b, c)
print(t.perimeter())
# 也可以通过给类发消息来调用对象方法但是要传入接收消息的对象作为参数
# print(Triangle.perimeter(t))
print(t.area())
# print(Triangle.area(t))
else:
print('无法构成三角形.')
if __name__ == '__main__':
main()
和静态方法比较类似,Python还可以在类中定义类方法,类方法的第一个参数约定名为cls,它代表的是当前类相关的信息的对象(类本身也是一个对象,有的地方也称之为类的元数据对象),通过这个参数我们可以获取和类相关的信息并且可以创建出类的对象
from time import time, localtime, sleep
class Clock(object):
"""数字时钟"""
def __init__(self, hour=0, minute=0, second=0):
self._hour = hour
self._minute = minute
self._second = second
@classmethod
def now(cls):
ctime = localtime(time())
return cls(ctime.tm_hour, ctime.tm_min, ctime.tm_sec)
def run(self):
"""走字"""
self._second += 1
if self._second == 60:
self._second = 0
self._minute += 1
if self._minute == 60:
self._minute = 0
self._hour += 1
if self._hour == 24:
self._hour = 0
def show(self):
"""显示时间"""
return '%02d:%02d:%02d' % \
(self._hour, self._minute, self._second)
def main():
# 通过类方法创建对象并获取系统时间
clock = Clock.now()
while True:
print(clock.show())
sleep(1)
clock.run()
if __name__ == '__main__':
main()
类之间的关系
类和类之间的关系有三种:is-a、has-a和use-a关系。
- is-a关系也叫继承或泛化,比如学生和人的关系、手机和电子产品的关系都属于继承关系。
- has-a关系通常称之为关联,比如部门和员工的关系,汽车和引擎的关系都属于关联关系;关联关系如果是整体和部分的关联,那么我们称之为聚合关系;如果整体进一步负责了部分的生命周期(整体和部分是不可分割的,同时同在也同时消亡),那么这种就是最强的关联关系,我们称之为合成关系。
- use-a关系通常称之为依赖,比如司机有一个驾驶的行为(方法),其中(的参数)使用到了汽车,那么司机和汽车的关系就是依赖关系。
我们可以使用一种叫做UML(统一建模语言)的东西来进行面向对象建模
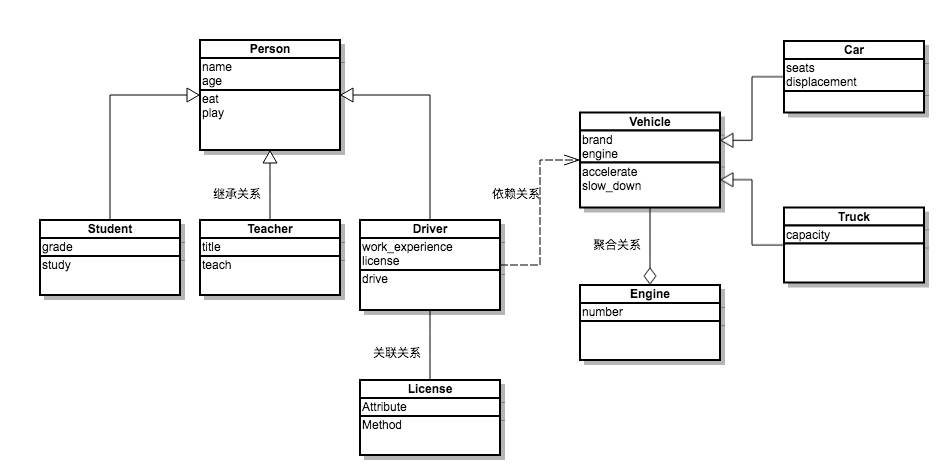
继承和多态
提供继承信息的我们称之为父类,也叫超类或基类;得到继承信息的我们称之为子类,也叫派生类或衍生类。子类除了继承父类提供的属性和方法,还可以定义自己特有的属性和方法,所以子类比父类拥有的更多的能力,在实际开发中,我们经常会用子类对象去替换掉一个父类对象,这是面向对象编程中一个常见的行为,对应的原则称之为里氏替换原则
class Person(object):
"""人"""
def __init__(self, name, age):
self._name = name
self._age = age
@property
def name(self):
return self._name
@property
def age(self):
return self._age
@age.setter
def age(self, age):
self._age = age
def play(self):
print('%s正在愉快的玩耍.' % self._name)
def watch_av(self):
if self._age >= 18:
print('%s正在观看爱情动作片.' % self._name)
else:
print('%s只能观看《熊出没》.' % self._name)
class Student(Person):
"""学生"""
def __init__(self, name, age, grade):
super().__init__(name, age)
self._grade = grade
@property
def grade(self):
return self._grade
@grade.setter
def grade(self, grade):
self._grade = grade
def study(self, course):
print('%s的%s正在学习%s.' % (self._grade, self._name, course))
class Teacher(Person):
"""老师"""
def __init__(self, name, age, title):
super().__init__(name, age)
self._title = title
@property
def title(self):
return self._title
@title.setter
def title(self, title):
self._title = title
def teach(self, course):
print('%s%s正在讲%s.' % (self._name, self._title, course))
def main():
stu = Student('王大锤', 15, '初三')
stu.study('数学')
stu.watch_av()
t = Teacher('骆昊', 38, '砖家')
t.teach('Python程序设计')
t.watch_av()
if __name__ == '__main__':
main()
子类在继承了父类的方法后,可以对父类已有的方法给出新的实现版本,这个动作称之为方法重写(override)。通过方法重写我们可以让父类的同一个行为在子类中拥有不同的实现版本,当我们调用这个经过子类重写的方法时,不同的子类对象会表现出不同的行为,这个就是多态(poly-morphism)。
from abc import ABCMeta, abstractmethod
class Pet(object, metaclass=ABCMeta):
"""宠物"""
def __init__(self, nickname):
self._nickname = nickname
@abstractmethod
def make_voice(self):
"""发出声音"""
pass
class Dog(Pet):
"""狗"""
def make_voice(self):
print('%s: 汪汪汪...' % self._nickname)
class Cat(Pet):
"""猫"""
def make_voice(self):
print('%s: 喵...喵...' % self._nickname)
def main():
pets = [Dog('旺财'), Cat('凯蒂'), Dog('大黄')]
for pet in pets:
pet.make_voice()
if __name__ == '__main__':
main()
我们将Pet类处理成了一个抽象类,所谓抽象类就是不能够创建对象的类,这种类的存在就是专门为了让其他类去继承它。Python从语法层面并没有像Java或C#那样提供对抽象类的支持,但是我们可以通过abc模块的ABCMeta元类和abstractmethod包装器来达到抽象类的效果,如果一个类中存在抽象方法那么这个类就不能够实例化(创建对象)。上面的代码中,Dog和Cat两个子类分别对Pet类中的make_voice抽象方法进行了重写并给出了不同的实现版本,当我们在main函数中调用该方法时,这个方法就表现出了多态行为(同样的方法做了不同的事情)。
文件和异常
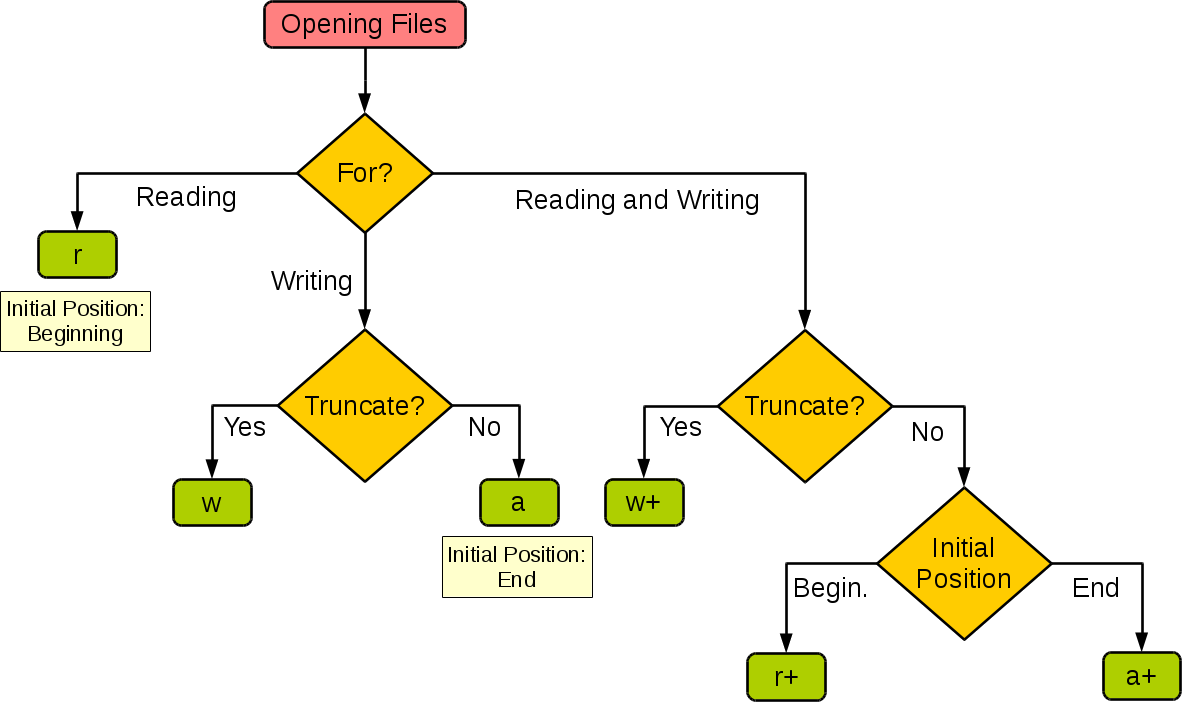
通过Python内置的open函数,我们可以指定文件名、操作模式、编码信息等来获得操作文件的对象,接下来就可以对文件进行读写操作了。这里所说的操作模式是指要打开什么样的文件(字符文件还是二进制文件)以及做什么样的操作(读、写还是追加),具体的如下表所示。
| 操作模式 | 具体含义 |
|---|---|
'r' |
读取 (默认) |
'w' |
写入(会先截断之前的内容) |
'x' |
写入,如果文件已经存在会产生异常 |
'a' |
追加,将内容写入到已有文件的末尾 |
'b' |
二进制模式 |
't' |
文本模式(默认) |
'+' |
更新(既可以读又可以写) |
下面这张图来自于菜鸟教程网站
读写文本文件
读取文本文件时,需要在使用open函数时指定好带路径的文件名(可以使用相对路径或绝对路径)并将文件模式设置为'r',然后通过encoding参数指定编码(如果不指定,默认值是None,那么在读取文件时使用的是操作系统默认的编码)
def main():
f = None
try:
f = open('致橡树.txt', 'r', encoding='utf-8')
print(f.read())
except FileNotFoundError:
print('无法打开指定的文件!')
except LookupError:
print('指定了未知的编码!')
except UnicodeDecodeError:
print('读取文件时解码错误!')
finally:
if f:
f.close()
if __name__ == '__main__':
main()
在Python中,我们可以将那些在运行时可能会出现状况的代码放在try代码块中,最后我们使用finally代码块来关闭打开的文件,释放掉程序中获取的外部资源,也可以使用上下文语法,通过with关键字指定文件对象的上下文环境并在离开上下文环境时自动释放文件资源
def main():
try:
with open('致橡树.txt', 'r', encoding='utf-8') as f:
print(f.read())
except FileNotFoundError:
print('无法打开指定的文件!')
except LookupError:
print('指定了未知的编码!')
except UnicodeDecodeError:
print('读取文件时解码错误!')
if __name__ == '__main__':
main()
还可以使用for-in循环逐行读取或者用readlines方法将文件按行读取到一个列表容器中
import time
def main():
# 一次性读取整个文件内容
with open('致橡树.txt', 'r', encoding='utf-8') as f:
print(f.read())
# 通过for-in循环逐行读取
with open('致橡树.txt', mode='r') as f:
for line in f:
print(line, end='')
time.sleep(0.5)
print()
# 读取文件按行读取到列表中
with open('致橡树.txt') as f:
lines = f.readlines()
print(lines)
if __name__ == '__main__':
main()
在使用open函数时指定好文件名并将文件模式设置为'w'即可写入。注意如果需要对文件内容进行追加式写入,应该将模式设置为'a'。如果要写入的文件不存在会自动创建文件而不是引发异常。下面的例子演示了如何将1-9999之间的素数分别写入三个文件中(1-99之间的素数保存在a.txt中,100-999之间的素数保存在b.txt中,1000-9999之间的素数保存在c.txt中)。
from math import sqrt
def is_prime(n):
"""判断素数的函数"""
assert n > 0
for factor in range(2, int(sqrt(n)) + 1):
if n % factor == 0:
return False
return True if n != 1 else False
def main():
filenames = ('a.txt', 'b.txt', 'c.txt')
fs_list = []
try:
for filename in filenames:
fs_list.append(open(filename, 'w', encoding='utf-8'))
for number in range(1, 10000):
if is_prime(number):
if number < 100:
fs_list[0].write(str(number) + '\n')
elif number < 1000:
fs_list[1].write(str(number) + '\n')
else:
fs_list[2].write(str(number) + '\n')
except IOError as ex:
print(ex)
print('写文件时发生错误!')
finally:
for fs in fs_list:
fs.close()
print('操作完成!')
if __name__ == '__main__':
main()
读写二进制文件
下面的代码实现了复制图片文件的功能。
def main():
try:
with open('guido.jpg', 'rb') as fs1:
data = fs1.read()
print(type(data)) # <class 'bytes'>
with open('吉多.jpg', 'wb') as fs2:
fs2.write(data)
except FileNotFoundError as e:
print('指定的文件无法打开.')
except IOError as e:
print('读写文件时出现错误.')
print('程序执行结束.')
if __name__ == '__main__':
main()
读写JSON文件
把一个列表或者一个字典中的数据保存到文件中,关于JSON的知识,更多的可以参考JSON的官方网站也可以了解到每种语言处理JSON数据格式可以使用的工具或三方库,
{
"name": "骆昊",
"age": 38,
"qq": 957658,
"friends": ["王大锤", "白元芳"],
"cars": [
{"brand": "BYD", "max_speed": 180},
{"brand": "Audi", "max_speed": 280},
]
}
JSON的数据类型和Python的数据类型是很容易找到对应关系
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | str |
| number (int / real) | int / float |
| true / false | True / False |
| null | None |
json模块就可以将字典或列表以JSON格式保存到文件中
import json
def main():
mydict = {
'name': '骆昊',
'age': 38,
'qq': 957658,
'friends': ['王大锤', '白元芳'],
'cars': [
{'brand': 'BYD', 'max_speed': 180},
{'brand': 'Audi', 'max_speed': 280},
{'brand': 'Benz', 'max_speed': 320}
]
}
try:
with open('data.json', 'w', encoding='utf-8') as fs:
json.dump(mydict, fs)
except IOError as e:
print(e)
print('保存数据完成!')
if __name__ == '__main__':
main()
json模块主要有四个比较重要的函数
dump- 将Python对象按照JSON格式序列化到文件中dumps- 将Python对象处理成JSON格式的字符串load- 将文件中的JSON数据反序列化成对象loads- 将字符串的内容反序列化成Python对象
目前绝大多数网络数据服务(或称之为网络API)都是基于HTTP协议提供JSON格式的数据,关于HTTP协议的相关知识,可以看看阮一峰老师的《HTTP协议入门》,如果想了解国内的网络数据服务,可以看看聚合数据和阿凡达数据等网站,国外的可以看看{API}Search网站。下面的例子演示了如何使用requests模块(封装得足够好的第三方网络访问模块)访问网络API获取国内新闻,如何通过json模块解析JSON数据并显示新闻标题,这个例子使用了天行数据提供的国内新闻数据接口,其中的APIKey需要自己到该网站申请。
import requests
import json
def main():
resp = requests.get('http://api.tianapi.com/guonei/?key=APIKey&num=10')
data_model = json.loads(resp.text)
for news in data_model['newslist']:
print(news['title'])
if __name__ == '__main__':
main()
正则表达式
可以阅读一篇博客叫《正则表达式30分钟入门教程》,读完这篇文章后对正则表达式中的一些基本符号进行的总结。
| 符号 | 解释 | 示例 | 说明 |
|---|---|---|---|
| . | 匹配任意字符 | b.t | 可以匹配bat / but / b#t / b1t等 |
| \w | 匹配字母/数字/下划线 | b\wt | 可以匹配bat / b1t / b_t等 但不能匹配b#t |
| \s | 匹配空白字符(包括\r、\n、\t等) | love\syou | 可以匹配love you |
| \d | 匹配数字 | \d\d | 可以匹配01 / 23 / 99等 |
| \b | 匹配单词的边界 | \bThe\b | |
| ^ | 匹配字符串的开始 | ^The | 可以匹配The开头的字符串 |
| $ | 匹配字符串的结束 | .exe$ | 可以匹配.exe结尾的字符串 |
| \W | 匹配非字母/数字/下划线 | b\Wt | 可以匹配b#t / b@t等 但不能匹配but / b1t / b_t等 |
| \S | 匹配非空白字符 | love\Syou | 可以匹配love#you等 但不能匹配love you |
| \D | 匹配非数字 | \d\D | 可以匹配9a / 3# / 0F等 |
| \B | 匹配非单词边界 | \Bio\B | |
| [] | 匹配来自字符集的任意单一字符 | [aeiou] | 可以匹配任一元音字母字符 |
| [^] | 匹配不在字符集中的任意单一字符 | [^aeiou] | 可以匹配任一非元音字母字符 |
| * | 匹配0次或多次 | \w* | |
| + | 匹配1次或多次 | \w+ | |
| ? | 匹配0次或1次 | \w? | |
| 匹配N次 | \w | ||
| 匹配至少M次 | \w | ||
| 匹配至少M次至多N次 | \w | ||
| | | 分支 | foo|bar | 可以匹配foo或者bar |
| (?#) | 注释 | ||
| (exp) | 匹配exp并捕获到自动命名的组中 | ||
| (?<name>exp) | 匹配exp并捕获到名为name的组中 | ||
| (?:exp) | 匹配exp但是不捕获匹配的文本 | ||
| (?=exp) | 匹配exp前面的位置 | \b\w+(?=ing) | 可以匹配I'm dancing中的danc |
| (?<=exp) | 匹配exp后面的位置 | (?<=\bdanc)\w+\b | 可以匹配I love dancing and reading中的第一个ing |
| (?!exp) | 匹配后面不是exp的位置 | ||
| (?<!exp) | 匹配前面不是exp的位置 | ||
| *? | 重复任意次,但尽可能少重复 | a.*b a.*?b |
将正则表达式应用于aabab,前者会匹配整个字符串aabab,后者会匹配aab和ab两个字符串 |
| +? | 重复1次或多次,但尽可能少重复 | ||
| ?? | 重复0次或1次,但尽可能少重复 | ||
| {M,N}? | 重复M到N次,但尽可能少重复 | ||
| {M,}? | 重复M次以上,但尽可能少重复 |
说明: 如果需要匹配的字符是正则表达式中的特殊字符,那么可以使用\进行转义处理,想匹配圆括号必须写成\(和\),否则圆括号被视为正则表达式中的分组。
Python对正则表达式的支持
re模块中的核心函数。
| 函数 | 说明 |
|---|---|
| compile(pattern, flags=0) | 编译正则表达式返回正则表达式对象 |
| match(pattern, string, flags=0) | 用正则表达式匹配字符串 成功返回匹配对象 否则返回None |
| search(pattern, string, flags=0) | 搜索字符串中第一次出现正则表达式的模式 成功返回匹配对象 否则返回None |
| split(pattern, string, maxsplit=0, flags=0) | 用正则表达式指定的模式分隔符拆分字符串 返回列表 |
| sub(pattern, repl, string, count=0, flags=0) | 用指定的字符串替换原字符串中与正则表达式匹配的模式 可以用count指定替换的次数 |
| fullmatch(pattern, string, flags=0) | match函数的完全匹配(从字符串开头到结尾)版本 |
| findall(pattern, string, flags=0) | 查找字符串所有与正则表达式匹配的模式 返回字符串的列表 |
| finditer(pattern, string, flags=0) | 查找字符串所有与正则表达式匹配的模式 返回一个迭代器 |
| purge() | 清除隐式编译的正则表达式的缓存 |
| re.I / re.IGNORECASE | 忽略大小写匹配标记 |
| re.M / re.MULTILINE | 多行匹配标记 |
说明: 上面提到的re模块中的这些函数,实际开发中也可以用正则表达式对象的方法替代对这些函数的使用,如果一个正则表达式需要重复的使用,那么先通过compile函数编译正则表达式并创建出正则表达式对象无疑是更为明智的选择。
下面我们通过一系列的例子来告诉大家在Python中如何使用正则表达式。
例子:验证输入用户名和QQ号是否有效并给出对应的提示信息。
"""
验证输入用户名和QQ号是否有效并给出对应的提示信息
要求:用户名必须由字母、数字或下划线构成且长度在6~20个字符之间,QQ号是5~12的数字且首位不能为0
"""
import re
def main():
username = input('请输入用户名: ')
qq = input('请输入QQ号: ')
# match函数的第一个参数是正则表达式字符串或正则表达式对象
# 第二个参数是要跟正则表达式做匹配的字符串对象
m1 = re.match(r'^[0-9a-zA-Z_]{6,20}$', username)
if not m1:
print('请输入有效的用户名.')
m2 = re.match(r'^[1-9]\d{4,11}$', qq)
if not m2:
print('请输入有效的QQ号.')
if m1 and m2:
print('你输入的信息是有效的!')
if __name__ == '__main__':
main()
提示: 上面在书写正则表达式时使用了“原始字符串”的写法(在字符串前面加上了r),所谓“原始字符串”就是字符串中的每个字符都是它原始的意义。因为正则表达式中有很多元字符和需要进行转义的地方,如果不使用原始字符串就需要将反斜杠写作\\,例如表示数字的\d得书写成\\d,这样不仅写起来不方便
进程和线程
概念
进程就是操作系统中执行的一个程序,操作系统以进程为单位分配存储空间,每个进程都有自己的地址空间、数据栈以及其他用于跟踪进程执行的辅助数据,进程可以通过fork或spawn的方式来创建新的进程来执行其他的任务,通过进程间通信机制(IPC,Inter-Process Communication)来实现数据共享,具体的方式包括管道、信号、套接字、共享内存区等。一个进程还可以拥有多个并发的执行线索,就是所谓的线程。
实现并发编程主要有3种方式:多进程、多线程、多进程+多线程。
多进程
Unix和Linux操作系统上提供了fork()系统调用来创建进程,调用fork()函数的是父进程,创建出的是子进程,子进程是父进程的一个拷贝,但是子进程拥有自己的PID。fork()函数非常特殊它会返回两次,父进程中可以通过fork()函数的返回值得到子进程的PID,而子进程中的返回值永远都是0。Python的os模块提供了fork()函数。由于Windows系统没有fork()调用,因此要实现跨平台的多进程编程,可以使用multiprocessing模块的Process类来创建子进程,而且该模块还提供了更高级的封装,例如批量启动进程的进程池(Pool)、用于进程间通信的队列(Queue)和管道(Pipe)等。
下面用一个下载文件的例子来说明使用多进程和不使用多进程到底有什么差别,先看看下面的代码。
from random import randint
from time import time, sleep
def download_task(filename):
print('开始下载%s...' % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))
def main():
start = time()
download_task('Python从入门到住院.pdf')
download_task('Peking Hot.avi')
end = time()
print('总共耗费了%.2f秒.' % (end - start))
if __name__ == '__main__':
main()
下面是运行程序得到的一次运行结果。
开始下载Python从入门到住院.pdf...
Python从入门到住院.pdf下载完成! 耗费了6秒
开始下载Peking Hot.avi...
Peking Hot.avi下载完成! 耗费了7秒
总共耗费了13.01秒.
接下来我们使用多进程的方式将两个下载任务放到不同的进程中,代码如下所示。
from multiprocessing import Process
from os import getpid
from random import randint
from time import time, sleep
def download_task(filename):
print('启动下载进程,进程号[%d].' % getpid())
print('开始下载%s...' % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))
def main():
start = time()
p1 = Process(target=download_task, args=('Python从入门到住院.pdf', ))
p1.start()
p2 = Process(target=download_task, args=('Peking Hot.avi', ))
p2.start()
p1.join()
p2.join()
end = time()
print('总共耗费了%.2f秒.' % (end - start))
if __name__ == '__main__':
main()
通过Process类创建了进程对象,通过target参数我们传入一个函数来表示进程启动后要执行的代码,后面的args是一个元组,它代表了传递给函数的参数。Process对象的start方法用来启动进程,而join方法表示等待进程执行结束。
启动下载进程,进程号[1530].
开始下载Python从入门到住院.pdf...
启动下载进程,进程号[1531].
开始下载Peking Hot.avi...
Peking Hot.avi下载完成! 耗费了7秒
Python从入门到住院.pdf下载完成! 耗费了10秒
总共耗费了10.01秒.
也可以使用subprocess模块中的类和函数来创建和启动子进程,然后通过管道来和子进程通信。我们启动两个进程,一个输出Ping,一个输出Pong,两个进程输出的Ping和Pong加起来一共10个。听起来很简单,但是这样写是错的。
from multiprocessing import Process
from time import sleep
counter = 0
def sub_task(string):
global counter
while counter < 10:
print(string, end='', flush=True)
counter += 1
sleep(0.01)
def main():
Process(target=sub_task, args=('Ping', )).start()
Process(target=sub_task, args=('Pong', )).start()
if __name__ == '__main__':
main()
看起来没毛病,但是最后的结果是Ping和Pong各输出了10个,当我们在程序中创建进程的时候,子进程复制了父进程及其所有的数据结构,每个子进程有自己独立的内存空间,这也就意味着两个子进程中各有一个counter变量,所以结果也就可想而知了。要解决这个问题比较简单的办法是使用multiprocessing模块中的Queue类,它是可以被多个进程共享的队列,底层是通过管道和信号量(semaphore)机制来实现的。
多线程
多线程开发我们推荐使用threading模块,该模块对多线程编程提供了更好的面向对象的封装。
from random import randint
from threading import Thread
from time import time, sleep
def download(filename):
print('开始下载%s...' % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))
def main():
start = time()
t1 = Thread(target=download, args=('Python从入门到住院.pdf',))
t1.start()
t2 = Thread(target=download, args=('Peking Hot.avi',))
t2.start()
t1.join()
t2.join()
end = time()
print('总共耗费了%.3f秒' % (end - start))
if __name__ == '__main__':
main()
我们可以直接使用threading模块的Thread类来创建线程,也可以通过继承Thread类的方式来创建自定义的线程类,然后再创建线程对象并启动线程。
from random import randint
from threading import Thread
from time import time, sleep
class DownloadTask(Thread):
def __init__(self, filename):
super().__init__()
self._filename = filename
def run(self):
print('开始下载%s...' % self._filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下载完成! 耗费了%d秒' % (self._filename, time_to_download))
def main():
start = time()
t1 = DownloadTask('Python从入门到住院.pdf')
t1.start()
t2 = DownloadTask('Peking Hot.avi')
t2.start()
t1.join()
t2.join()
end = time()
print('总共耗费了%.2f秒.' % (end - start))
if __name__ == '__main__':
main()
要实现多个线程间的通信相对简单,大家能想到的最直接的办法就是设置一个全局变量,多个线程共享这个全局变量即可。但是当多个线程共享同一个变量(我们通常称之为“资源”)的时候,很有可能产生不可控的结果从而导致程序失效甚至崩溃。如果一个资源被多个线程竞争使用,那么我们通常称之为“临界资源”,对“临界资源”的访问需要加上保护,否则资源会处于“混乱”的状态。下面的例子演示了100个线程向同一个银行账户转账(转入1元钱)的场景,在这个例子中,银行账户就是一个临界资源,在没有保护的情况下我们很有可能会得到错误的结果。
from time import sleep
from threading import Thread
class Account(object):
def __init__(self):
self._balance = 0
def deposit(self, money):
# 计算存款后的余额
new_balance = self._balance + money
# 模拟受理存款业务需要0.01秒的时间
sleep(0.01)
# 修改账户余额
self._balance = new_balance
@property
def balance(self):
return self._balance
class AddMoneyThread(Thread):
def __init__(self, account, money):
super().__init__()
self._account = account
self._money = money
def run(self):
self._account.deposit(self._money)
def main():
account = Account()
threads = []
# 创建100个存款的线程向同一个账户中存钱
for _ in range(100):
t = AddMoneyThread(account, 1)
threads.append(t)
t.start()
# 等所有存款的线程都执行完毕
for t in threads:
t.join()
print('账户余额为: ¥%d元' % account.balance)
if __name__ == '__main__':
main()
运行上面的程序,100个线程分别向账户中转入1元钱,结果居然远远小于100元。之所以出现这种情况是因为我们没有对银行账户这个“临界资源”加以保护,多个线程同时向账户中存钱时,会一起执行到new_balance = self._balance + money这行代码,多个线程得到的账户余额都是初始状态下的0,所以都是0上面做了+1的操作,因此得到了错误的结果。我们可以通过“锁”来保护“临界资源”,只有获得“锁”的线程才能访问“临界资源”,而其他没有得到“锁”的线程只能被阻塞起来,直到获得“锁”的线程释放了“锁”,其他线程才有机会获得“锁”,进而访问被保护的“临界资源”。
from time import sleep
from threading import Thread, Lock
class Account(object):
def __init__(self):
self._balance = 0
self._lock = Lock()
def deposit(self, money):
# 先获取锁才能执行后续的代码
self._lock.acquire()
try:
new_balance = self._balance + money
sleep(0.01)
self._balance = new_balance
finally:
# 在finally中执行释放锁的操作保证正常异常锁都能释放
self._lock.release()
@property
def balance(self):
return self._balance
class AddMoneyThread(Thread):
def __init__(self, account, money):
super().__init__()
self._account = account
self._money = money
def run(self):
self._account.deposit(self._money)
def main():
account = Account()
threads = []
for _ in range(100):
t = AddMoneyThread(account, 1)
threads.append(t)
t.start()
for t in threads:
t.join()
print('账户余额为: ¥%d元' % account.balance)
if __name__ == '__main__':
main()
Python的多线程并不能发挥CPU的多核特性。因为Python的解释器有一个“全局解释器锁”(GIL)的东西,任何线程执行前必须先获得GIL锁,然后每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行,这是一个历史遗留问题
多进程还是多线程
无论是多进程还是多线程,只要数量一多,效率肯定上不去。第二个考虑是任务的类型,可以把任务分为计算密集型和I/O密集型。计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如对视频进行编码解码或者格式转换等等,计算密集型任务由于主要消耗CPU资源,这类任务用Python这样的脚本语言去执行效率通常很低,最能胜任这类任务的是C语言。其他的涉及到网络、存储介质I/O的任务都可以视为I/O密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待I/O操作完成(因为I/O的速度远远低于CPU和内存的速度)。对于I/O密集型任务,如果启动多任务,就可以减少I/O等待时间从而让CPU高效率的运转。有一大类的任务都属于I/O密集型任务,这其中包括网络应用和Web应用。
单线程+异步I/O
现代操作系统对I/O操作的改进中最为重要的就是支持异步I/O。如果充分利用操作系统提供的异步I/O支持,就可以用单进程单线程模型来执行多任务,这种全新的模型称为事件驱动模型。Nginx就是支持异步I/O的Web服务器,它在单核CPU上采用单进程模型就可以高效地支持多任务。在多核CPU上,可以运行多个进程(数量与CPU核心数相同),充分利用多核CPU。用Node.js开发的服务器端程序也使用了这种工作模式。
在Python语言中,单线程+异步I/O的编程模型称为协程,有了协程的支持,就可以基于事件驱动编写高效的多任务程序。协程最大的优势就是极高的执行效率。协程的第二个优势就是不需要多线程的锁机制,因为只有一个线程,只需要判断状态就好了,所以执行效率比多线程高很多。如果想要充分利用CPU的多核特性,最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能
应用案例
例子:将耗时间的任务放到线程中以获得更好的用户体验。
如下所示的界面中,有“下载”和“关于”两个按钮,用休眠的方式模拟点击“下载”按钮会联网下载文件需要耗费10秒的时间,如果不使用“多线程”,当点击“下载”按钮后整个程序的其他部分都被这个耗时间的任务阻塞而无法执行了
import time
import tkinter
import tkinter.messagebox
def download():
# 模拟下载任务需要花费10秒钟时间
time.sleep(10)
tkinter.messagebox.showinfo('提示', '下载完成!')
def show_about():
tkinter.messagebox.showinfo('关于', '作者: 骆昊(v1.0)')
def main():
top = tkinter.Tk()
top.title('单线程')
top.geometry('200x150')
top.wm_attributes('-topmost', True)
panel = tkinter.Frame(top)
button1 = tkinter.Button(panel, text='下载', command=download)
button1.pack(side='left')
button2 = tkinter.Button(panel, text='关于', command=show_about)
button2.pack(side='right')
panel.pack(side='bottom')
tkinter.mainloop()
if __name__ == '__main__':
main()
如果使用多线程将耗时间的任务放到一个独立的线程中执行,这样就不会因为执行耗时间的任务而阻塞了主线程
import time
import tkinter
import tkinter.messagebox
from threading import Thread
def main():
class DownloadTaskHandler(Thread):
def run(self):
time.sleep(10)
tkinter.messagebox.showinfo('提示', '下载完成!')
# 启用下载按钮
button1.config(state=tkinter.NORMAL)
def download():
# 禁用下载按钮
button1.config(state=tkinter.DISABLED)
# 通过daemon参数将线程设置为守护线程(主程序退出就不再保留执行)
# 在线程中处理耗时间的下载任务
DownloadTaskHandler(daemon=True).start()
def show_about():
tkinter.messagebox.showinfo('关于', '作者: 骆昊(v1.0)')
top = tkinter.Tk()
top.title('单线程')
top.geometry('200x150')
top.wm_attributes('-topmost', 1)
panel = tkinter.Frame(top)
button1 = tkinter.Button(panel, text='下载', command=download)
button1.pack(side='left')
button2 = tkinter.Button(panel, text='关于', command=show_about)
button2.pack(side='right')
panel.pack(side='bottom')
tkinter.mainloop()
if __name__ == '__main__':
main()
网络编程入门
TCP/IP模型
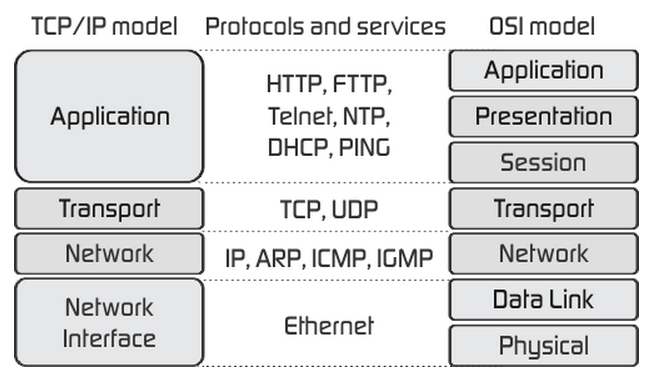
实现网络通信的基础是网络通信协议。协议的三要素是:语法、语义和时序。TCP/IP是一个四层模型,自底向上依次是:网络接口层、网络层、传输层和应用层
TCP全称传输控制协议,它是基于IP提供的寻址和路由服务而建立起来的负责实现端到端可靠传输的协议:
- 数据不传丢不传错(利用握手、校验和重传机制可以实现)。
- 流量控制(通过滑动窗口匹配数据发送者和接收者之间的传输速度)。
- 拥塞控制(通过RTT时间以及对滑动窗口的控制缓解网络拥堵)。
网络应用模式
- C/S模式和B/S模式。这里的C指的是Client(客户端),需要安装到某个宿主操作系统上的应用程序;而B指的是Browser(浏览器),通过C或B都可以实现对S(服务器)的访问。
- 去中心化的网络应用模式。所有应用的使用者既可以作为资源的提供者也可以作为资源的访问者。
基于HTTP协议的网络资源访问
HTTP(超文本传输协议)
HTTP是超文本传输协议(Hyper-Text Transfer Proctol)的简称,阮一峰老师的《HTTP 协议入门》,简单的说,通过HTTP我们可以获取网络上的(基于字符的)资源,开发中经常会用到的网络API就是基于HTTP来实现数据传输的。
JSON格式
JSON(JavaScript Object Notation)是一种轻量级的数据交换语言,该语言以易于让人阅读的文字(纯文本)为基础,用来传输由属性值或者序列性的值组成的数据对象。Python内置的json模块也提供了这方面的功能。
XML的例子:
<?xml version="1.0" encoding="UTF-8"?>
<message>
<from>Alice</from>
<to>Bob</to>
<content>Will you marry me?</content>
</message>
JSON的例子:
{
"from": "Alice",
"to": "Bob",
"content": "Will you marry me?"
}
requests库
requests是一个基于HTTP协议来使用网络的第三库,现一个访问网络数据接口并从中获取美女图片下载链接然后下载美女图片到本地的例子程序
先通过pip安装requests及其依赖库。
pip install requests
使用PyCharm作为开发工具,可以直接在代码中书写import requests,然后通过代码修复功能来自动下载安装requests。
from time import time
from threading import Thread
import requests
# 继承Thread类创建自定义的线程类
class DownloadHanlder(Thread):
def __init__(self, url):
super().__init__()
self.url = url
def run(self):
filename = self.url[self.url.rfind('/') + 1:]
resp = requests.get(self.url)
with open('/Users/Hao/' + filename, 'wb') as f:
f.write(resp.content)
def main():
# 通过requests模块的get函数获取网络资源
# 下面的代码中使用了天行数据接口提供的网络API
# 要使用该数据接口需要在天行数据的网站上注册
# 然后用自己的Key替换掉下面代码的中APIKey即可
resp = requests.get(
'http://api.tianapi.com/meinv/?key=APIKey&num=10')
# 将服务器返回的JSON格式的数据解析为字典
data_model = resp.json()
for mm_dict in data_model['newslist']:
url = mm_dict['picUrl']
# 通过多线程的方式实现图片下载
DownloadHanlder(url).start()
if __name__ == '__main__':
main()
基于传输层协议的套接字编程
套接字就是一套用C语言写成的应用程序开发库,主要用于实现进程间通信和网络编程,在网络应用开发中被广泛使用。在Python中也可以基于套接字来使用传输层提供的传输服务,并基于此开发自己的网络应用。实际开发中使用的套接字可以分为三类:流套接字(TCP套接字)、数据报套接字和原始套接字。
TCP套接字
TCP套接字就是使用TCP协议提供的传输服务来实现网络通信的编程接口。在Python中可以通过创建socket对象并指定type属性为SOCK_STREAM来使用TCP套接字。作为服务器端的程序,需要在创建套接字对象后将其绑定到指定的IP地址和端口上。端口的取值范围是0~65535,而1024以下的端口我们通常称之为“著名端口”(留给像FTP、HTTP、SMTP等“著名服务”使用的端口,有的地方也称之为“周知端口”)
下面的代码实现了一个提供时间日期的服务器。
from socket import socket, SOCK_STREAM, AF_INET
from datetime import datetime
def main():
# 1.创建套接字对象并指定使用哪种传输服务
# family=AF_INET - IPv4地址
# family=AF_INET6 - IPv6地址
# type=SOCK_STREAM - TCP套接字
# type=SOCK_DGRAM - UDP套接字
# type=SOCK_RAW - 原始套接字
server = socket(family=AF_INET, type=SOCK_STREAM)
# 2.绑定IP地址和端口(端口用于区分不同的服务)
# 同一时间在同一个端口上只能绑定一个服务否则报错
server.bind(('192.168.1.2', 6789))
# 3.开启监听 - 监听客户端连接到服务器
# 参数512可以理解为连接队列的大小
server.listen(512)
print('服务器启动开始监听...')
while True:
# 4.通过循环接收客户端的连接并作出相应的处理(提供服务)
# accept方法是一个阻塞方法如果没有客户端连接到服务器代码不会向下执行
# accept方法返回一个元组其中的第一个元素是客户端对象
# 第二个元素是连接到服务器的客户端的地址(由IP和端口两部分构成)
client, addr = server.accept()
print(str(addr) + '连接到了服务器.')
# 5.发送数据
client.send(str(datetime.now()).encode('utf-8'))
# 6.断开连接
client.close()
if __name__ == '__main__':
main()
运行服务器程序后我们可以通过Windows系统的telnet来访问该服务器
telnet 192.168.1.2 6789
通过Python的程序来实现TCP客户端的功能
from socket import socket
def main():
# 1.创建套接字对象默认使用IPv4和TCP协议
client = socket()
# 2.连接到服务器(需要指定IP地址和端口)
client.connect(('192.168.1.2', 6789))
# 3.从服务器接收数据
print(client.recv(1024).decode('utf-8'))
client.close()
if __name__ == '__main__':
main()
需要注意的是,上面的服务器并没有使用多线程或者异步I/O的处理方式,这也就意味着当服务器与一个客户端处于通信状态时,其他的客户端只能排队等待。下面我们来设计一个使用多线程技术处理多个用户请求的服务器,该服务器会向连接到服务器的客户端发送一张图片。
服务器端代码:
from socket import socket, SOCK_STREAM, AF_INET
from base64 import b64encode
from json import dumps
from threading import Thread
def main():
# 自定义线程类
class FileTransferHandler(Thread):
def __init__(self, cclient):
super().__init__()
self.cclient = cclient
def run(self):
my_dict = {}
my_dict['filename'] = 'guido.jpg'
# JSON是纯文本不能携带二进制数据
# 所以图片的二进制数据要处理成base64编码
my_dict['filedata'] = data
# 通过dumps函数将字典处理成JSON字符串
json_str = dumps(my_dict)
# 发送JSON字符串
self.cclient.send(json_str.encode('utf-8'))
self.cclient.close()
# 1.创建套接字对象并指定使用哪种传输服务
server = socket()
# 2.绑定IP地址和端口(区分不同的服务)
server.bind(('192.168.1.2', 5566))
# 3.开启监听 - 监听客户端连接到服务器
server.listen(512)
print('服务器启动开始监听...')
with open('guido.jpg', 'rb') as f:
# 将二进制数据处理成base64再解码成字符串
data = b64encode(f.read()).decode('utf-8')
while True:
client, addr = server.accept()
# 启动一个线程来处理客户端的请求
FileTransferHandler(client).start()
if __name__ == '__main__':
main()
客户端代码:
from socket import socket
from json import loads
from base64 import b64decode
def main():
client = socket()
client.connect(('192.168.1.2', 5566))
# 定义一个保存二进制数据的对象
in_data = bytes()
# 由于不知道服务器发送的数据有多大每次接收1024字节
data = client.recv(1024)
while data:
# 将收到的数据拼接起来
in_data += data
data = client.recv(1024)
# 将收到的二进制数据解码成JSON字符串并转换成字典
# loads函数的作用就是将JSON字符串转成字典对象
my_dict = loads(in_data.decode('utf-8'))
filename = my_dict['filename']
filedata = my_dict['filedata'].encode('utf-8')
with open('/Users/Hao/' + filename, 'wb') as f:
# 将base64格式的数据解码成二进制数据并写入文件
f.write(b64decode(filedata))
print('图片已保存.')
if __name__ == '__main__':
main()
在这个案例中,我们使用了JSON作为数据传输的格式(通过JSON格式对传输的数据进行了序列化和反序列化的操作),但是JSON并不能携带二进制数据,因此对图片的二进制数据进行了Base64编码的处理。Base64是一种用64个字符表示所有二进制数据的编码方式,通过将二进制数据每6位一组的方式重新组织,刚好可以使用0~9的数字、大小写字母以及“+”和“/”总共64个字符表示从000000到111111的64种状态。
说明: 上面的代码主要为了讲解网络编程的相关内容因此并没有对异常状况进行处理,行添加异常处理代码来增强程序的健壮性。
UDP套接字
TCP和UDP都是提供端到端传输服务的协议,二者的差别就如同打电话和发短信的区别,后者不对传输的可靠性和可达性做出任何承诺从而避免了TCP中握手和重传的开销,所以在强调性能和而不是数据完整性的场景中(例如传输网络音视频数据),UDP可能是更好的选择。可能大家会注意到一个现象,就是在观看网络视频时,有时会出现卡顿,有时会出现花屏,这无非就是部分数据传丢或传错造成的。
网络应用开发
发送电子邮件
就像我们可以用HTTP(超文本传输协议)来访问一个网站一样,发送邮件要使用SMTP(简单邮件传输协议),SMTP也是一个建立在TCP(传输控制协议)提供的可靠数据传输服务的基础上的应用级协议,它规定了邮件的发送者如何跟发送邮件的服务器进行通信的细节,而Python中的smtplib模块将这些操作简化成了几个简单的函数。
下面的代码演示了如何在Python发送邮件。
from smtplib import SMTP
from email.header import Header
from email.mime.text import MIMEText
def main():
# 请自行修改下面的邮件发送者和接收者
sender = 'abcdefg@126.com'
receivers = ['uvwxyz@qq.com', 'uvwxyz@126.com']
message = MIMEText('用Python发送邮件的示例代码.', 'plain', 'utf-8')
message['From'] = Header('王大锤', 'utf-8')
message['To'] = Header('骆昊', 'utf-8')
message['Subject'] = Header('示例代码实验邮件', 'utf-8')
smtper = SMTP('smtp.126.com')
# 请自行修改下面的登录口令
smtper.login(sender, 'secretpass')
smtper.sendmail(sender, receivers, message.as_string())
print('邮件发送完成!')
if __name__ == '__main__':
main()
如果要发送带有附件的邮件,那么可以按照下面的方式进行操作。
from smtplib import SMTP
from email.header import Header
from email.mime.text import MIMEText
from email.mime.image import MIMEImage
from email.mime.multipart import MIMEMultipart
import urllib
def main():
# 创建一个带附件的邮件消息对象
message = MIMEMultipart()
# 创建文本内容
text_content = MIMEText('附件中有本月数据请查收', 'plain', 'utf-8')
message['Subject'] = Header('本月数据', 'utf-8')
# 将文本内容添加到邮件消息对象中
message.attach(text_content)
# 读取文件并将文件作为附件添加到邮件消息对象中
with open('/Users/Hao/Desktop/hello.txt', 'rb') as f:
txt = MIMEText(f.read(), 'base64', 'utf-8')
txt['Content-Type'] = 'text/plain'
txt['Content-Disposition'] = 'attachment; filename=hello.txt'
message.attach(txt)
# 读取文件并将文件作为附件添加到邮件消息对象中
with open('/Users/Hao/Desktop/汇总数据.xlsx', 'rb') as f:
xls = MIMEText(f.read(), 'base64', 'utf-8')
xls['Content-Type'] = 'application/vnd.ms-excel'
xls['Content-Disposition'] = 'attachment; filename=month-data.xlsx'
message.attach(xls)
# 创建SMTP对象
smtper = SMTP('smtp.126.com')
# 开启安全连接
# smtper.starttls()
sender = 'abcdefg@126.com'
receivers = ['uvwxyz@qq.com']
# 登录到SMTP服务器
# 请注意此处不是使用密码而是邮件客户端授权码进行登录
# 对此有疑问的读者可以联系自己使用的邮件服务器客服
smtper.login(sender, 'secretpass')
# 发送邮件
smtper.sendmail(sender, receivers, message.as_string())
# 与邮件服务器断开连接
smtper.quit()
print('发送完成!')
if __name__ == '__main__':
main()
发送短信
发送短信也是项目中常见的功能,网站的注册码、验证码都是通过短信来发送给用户的。代码中我们使用了短信平台提供的API接口实现了发送短信的服务
import urllib.parse
import http.client
import json
def main():
host = "106.ihuyi.com"
sms_send_uri = "/webservice/sms.php?method=Submit"
# 下面的参数需要填入自己注册的账号和对应的密码
params = urllib.parse.urlencode({'account': '你自己的账号', 'password' : '你自己的密码', 'content': '您的验证码是:147258。请不要把验证码泄露给其他人。', 'mobile': '接收者的手机号', 'format':'json' })
print(params)
headers = {'Content-type': 'application/x-www-form-urlencoded', 'Accept': 'text/plain'}
conn = http.client.HTTPConnection(host, port=80, timeout=30)
conn.request('POST', sms_send_uri, params, headers)
response = conn.getresponse()
response_str = response.read()
jsonstr = response_str.decode('utf-8')
print(json.loads(jsonstr))
conn.close()
if __name__ == '__main__':
main()
图像和办公文档处理
操作图像
计算机图像相关知识
-
颜色。如果你有使用颜料画画的经历,那么一定知道混合红、黄、蓝三种颜料可以得到其他的颜色,事实上这三种颜色就是被我们称为美术三原色的东西,它们是不能再分解的基本颜色。在计算机中,我们可以将红、绿、蓝三种色光以不同的比例叠加来组合成其他的颜色,是色光三原色,一个颜色表示为一个RGB值或RGBA值(其中的A表示Alpha通道,它决定了透过这个图像的像素,也就是透明度)。
名称 RGBA值 名称 RGBA值 White (255, 255, 255, 255) Red (255, 0, 0, 255) Green (0, 255, 0, 255) Blue (0, 0, 255, 255) Gray (128, 128, 128, 255) Yellow (255, 255, 0, 255) Black (0, 0, 0, 255) Purple (128, 0, 128, 255) -
像素。对于一个由数字序列表示的图像来说,最小的单位就是图像上单一颜色的小方格,这些小方块都有一个明确的位置和被分配的色彩数值,而这些一小方格的颜色和位置决定了该图像最终呈现出来的样子,它们是不可分割的单位,称之为像素(pixel)。
用Pillow操作图像
Pillow是由从著名的Python图像处理库PIL发展出来的一个分支,通过Pillow可以实现图像压缩和图像处理等各种操作。
pip install pillow
Pillow中最为重要的是Image类
>>> from PIL import Image
>>>
>>> image = Image.open('./res/guido.jpg')
>>> image.format, image.size, image.mode
('JPEG', (500, 750), 'RGB')
>>> image.show()

-
剪裁图像
>>> image = Image.open('./res/guido.jpg') >>> rect = 80, 20, 310, 360 >>> image.crop(rect).show()
-
生成缩略图
>>> image = Image.open('./res/guido.jpg') >>> size = 128, 128 >>> image.thumbnail(size) >>> image.show()
-
缩放和黏贴图像
>>> image1 = Image.open('./res/luohao.png') >>> image2 = Image.open('./res/guido.jpg') >>> rect = 80, 20, 310, 360 >>> guido_head = image2.crop(rect) >>> width, height = guido_head.size >>> image1.paste(guido_head.resize((int(width / 1.5), int(height / 1.5))), (172, 40))
-
旋转和翻转
>>> image = Image.open('./res/guido.png') >>> image.rotate(180).show() >>> image.transpose(Image.FLIP_LEFT_RIGHT).show()

-
操作像素
>>> image = Image.open('./res/guido.jpg') >>> for x in range(80, 310): ... for y in range(20, 360): ... image.putpixel((x, y), (128, 128, 128)) ... >>> image.show()
-
滤镜效果
>>> from PIL import Image, ImageFilter >>> >>> image = Image.open('./res/guido.jpg') >>> image.filter(ImageFilter.CONTOUR).show()
处理Excel电子表格
Python的openpyxl模块让我们可以在Python程序中读取和修改Excel电子表格
import datetime
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
ws['A1'] = 42
ws.append([1, 2, 3])
ws['A2'] = datetime.datetime.now()
wb.save("sample.xlsx")
处理Word文档
利用python-docx模块,Python可以创建和修改Word文档
from docx import Document
from docx.shared import Inches
document = Document()
document.add_heading('Document Title', 0)
p = document.add_paragraph('A plain paragraph having some ')
p.add_run('bold').bold = True
p.add_run(' and some ')
p.add_run('italic.').italic = True
document.add_heading('Heading, level 1', level=1)
document.add_paragraph('Intense quote', style='Intense Quote')
document.add_paragraph(
'first item in unordered list', style='List Bullet'
)
document.add_paragraph(
'first item in ordered list', style='List Number'
)
document.add_picture('monty-truth.png', width=Inches(1.25))
records = (
(3, '101', 'Spam'),
(7, '422', 'Eggs'),
(4, '631', 'Spam, spam, eggs, and spam')
)
table = document.add_table(rows=1, cols=3)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'Qty'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
for qty, id, desc in records:
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc
document.add_page_break()
document.save('demo.docx')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号