
数据采集与融合技术第一次作业
作业①
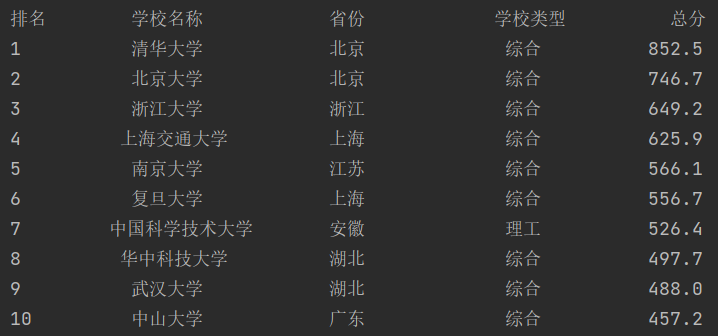
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息(前十位)。
输出要求:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2…… |
思路:
首先观察网站的HTML代码的特点,发现每个学校的信息都保存在一个<tbody>下,其中第一个<td>是排名,第二个<td>是学校,第三个<td>是省份,第四个<td>是学校类型,第五个<td>是总分,其中第二个<td>中还含有学校的英文名和学校层次,这里只取学校的中文名,分析代码发现中文名在<tbody>下的第一个<a>标签下。
所以首先提取这个页面的每个<tbody>内容,再将<tbody>中所需要的内容提取出来,存放在列表里,最后用format函数格式化输出前10个。
具体代码如下:
import urllib.request
from bs4 import BeautifulSoup
def gethtmlmsg(url): # 获取URL信息,输出内容
req = urllib.request.Request(url)
data = urllib.request.urlopen(req).read()
return data
# 提取信息
def result(ulist, html):
soup = BeautifulSoup(html, "lxml")
trs = soup.find('tbody').children#内容都在<tbody>下
for tr in trs:
a = tr('a') # 把a存为一个列表
td = tr('td') # 把td一个列表
'''
td0是排名,td1是学校,td2是省份,td3是学校类型,td4是总分
其中td1中还含有英文名和学校层次,所以只取a标签中的中文名
'''
ulist.append([td[0].text.strip(), a[0].string.strip(), td[2].text.strip(),
td[3].text.strip(), td[4].text.strip()])#获取标签中的文本内容,并去掉空格换行符等
#用format函数格式化输出
def myprint(ulist1, num):#num,输出几个
tformat = "{0:^10} {1:^10} {2:^10} {3:^10} {4:^10}"
print(tformat.format("排名", "学校名称", "省份", "学校类型", "总分"))
for i in range(num):
print(tformat.format(ulist1[i][0], ulist1[i][1], ulist1[i][2], ulist1[i][3], ulist1[i][4]))
ulist = [] #存放大学信息的列表
url = "https://www.shanghairanking.cn/rankings/bcur/2020"
html = gethtmlmsg(url)
result(ulist, html)
myprint(ulist, 10)#102102110饶雯捷
运行结果如下:
心得
- 一定要认真观察网页的HTML代码,分析哪些是有用的,不然就会多输出没用的东西
- 解析器的包中间还崩了一次,卸载重装就ok了。
作业②
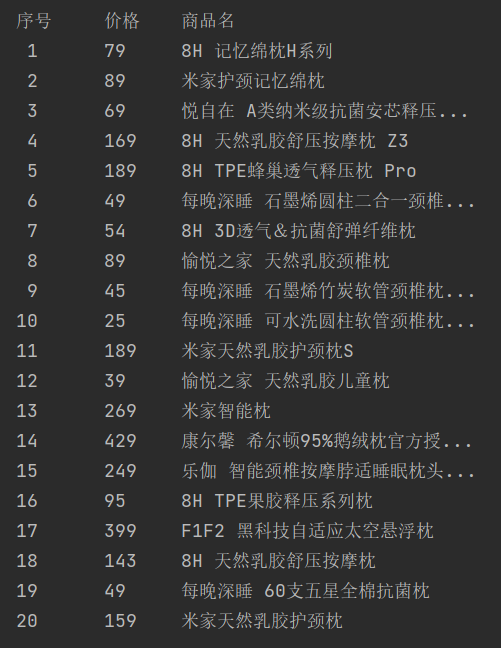
用urllib3.request和re库方法设计小米有品商品比价定向爬虫,爬取该商城以关键词“枕头”搜索页面的数据爬取该页面的商品名称和价格
输出要求:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65 | xxx |
| 2…… |
思路
因为有要求要用正则表达式,根据名称部分的HTML代码标签为<p class="pro-name" title="8H 记忆绵枕H系列">8H 记忆绵枕H系列</p>,把有变化的部分都挖掉,换成(.*?),价格部分的同理。最后同样用format方法格式化输出。
代码如下:
import urllib3
import re
#import requests
urllib3.disable_warnings()#禁用警告信息的输出
#这里是很长的headers信息
headers={
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36"
,"Cookie" : "youpindistinct_id=18ac34459571002-0ff15ba763d465-26031f51; mjclient=PC; Hm_lvt_025702dcecee57b18ed6fb366754c1b8=1695493151; b_auth=mijiayoupin; serviceToken=TneXwMVsx2cvSnqsVbzb0fOKTPkIeaCRDd4dPdn3wTxdxkQGEJLLMId7Hsl8iKFs6vjSTlo4sM1jp7yMKnBY8xkWfSX6Wrw1r1mn4BIXZAnLpF6yIqyaFTgcc6wvY+hTAFy4gZ+EEK4POXyfXZh9OQ==; cUserId=4JCkFNj1P40rXa4D2QjQpGXXbjc; exchangeToken=_7JD0FCFFsLUfI4P2lkd8dZWzcZEocGLgvgXWgMbhsLzMJLZOmTS8qptbClrX7nKYpc9nIkBiF3-lFqcd3DoHdiHsBzA46gX6SOyHBlm75YjN3Rwhl-CNVOiDp_f73wBRt7jXyyZzK4nIEBICimJVWXjagcVh6H4Qarx2ZhotDLLi7z34l_Zuvqvfi4zxhsubKl6MWFEkN8QywtPwy2ruoPD-fjoenm_aAlbF0ElK_SHl_zJctLkQuzAlH1LaK8BOPdrB3jTT9j7HZcbW2wP1g==; youpin_sessionid=18ac360f77f-0eb704a4ad3305-1fa9; Hm_lpvt_025702dcecee57b18ed6fb366754c1b8=1695495027Referer:https://account.xiaomi.com/fe/service/sns/bind/try?_new=true&expires_in=7200&state=7b227469636b6574223a22353435353836222c226170706964223a227778786d7a68222c2273636f7065223a22736e736170695f6c6f67696e222c2263616c6c6261636b223a22687474707325334125324625324673686f706170692e696f2e6d692e636f6d25324661707025324673686f70253246617574682533467369642533446d696f7473746f72652532366c6f676964253344313639353439343936332e3537353130343832392532367369676e2533446666326335333937336266653238373538613162626264386134326132353264253236666f6c6c6f77757025334468747470732532353341253235324625323532467777772e7869616f6d69796f7570696e2e636f6d253235324673656172636825323533466b6579776f72642532353344253235323545362532353235394525323532353935253235323545352532353235413425323532354234222c226c6f63616c65223a227a685f434e222c22736964223a226d696f7473746f7265227d&tsEnToken=S618o4e9mBWA%2FLgTHxx7CzOaCV%2FE7joq47uNwy2t7sLOI9wZ0MXitpqLPMGDfKbbHwuVDj%2BhBHU%2FwcfpCiHm0tayppapH2ih4IvsV1BxAwVGehvMYPLjlMmmlkyyrKdAHqmVaGoTb%2Bb3kwMIIPs%2FBgmB7UtWYD0SNV5FsU2zogMFQgP9TwR0GAdBbRR1aeFnibK1C795zgi5%2BDsy%2FG7lMuEm6Mi19mugYNpYjN1Oy0g%3D&sns_token_ph=7BD3596B630036C6&cUserId=4JCkFNj1P40rXa4D2QjQpGXXbjc&userId=2837957811&_locale=zh_CN"
}
keyword = "zhentou"
http = urllib3.PoolManager() # 创建连接池管理对象
# 构建搜索请求url
url = "https://www.xiaomiyoupin.com/search?keyword="+ keyword
#发送GET请求获取搜索结果页面
#response =requests.get(url,headers=headers)
#page_text = http.request('GET', url, headers=headers) # 发送GET请求
# 解析页面源码
#page_text = response.content.decode('utf-8')
#page_text=page_text.data.decode('utf-8')
with open('D:/AAAstudy/xiaomiyoupin.html', 'r',encoding='utf-8') as f:
page_text = f.read()
# 正则表达式匹配商品名称
name_pattern = '<p class="pro-name" title=".*?">(.*?)</p>'
# 正则表达式匹配商品价格
price_pattern = '<span class="m-num">(.*?)</span>'
name_list = re.findall(name_pattern, page_text)
price_list = re.findall(price_pattern, page_text)
# 输出限定个商品信息
tformat = "{0:^5} {1:^5} {2:<12}"
print(tformat.format("序号","价格","商品名"))
j=0
for i in range(len(price_list)):
j=j+1
print(tformat.format(j,price_list[i],name_list[i]))
一开始用urllib3的requests方法获取URL信息,在用正则表达式工具确定正则表达式是正确的情况下,输出的却是空列表。输出查看page_text内容,只有在浏览器上看到的其中一小部分,换request库获取url信息输出也是一样的,所以应该不是第一步获取信息方面的问题,怀疑小米有品的网站是动态页面,最后还是选择保存为本地的静态页面访问。
运行结果如下:
心得
- 设计爬虫前选择一个合适的商城真的很重要!有些网站做的很难爬,一开始是爬京东的,但是京东把名字分在了好几个标签中,价格的代码部分看起来很简单,真正爬起来就发现有坑,中间会穿插一些<i></i>的没内容的标签,导致输出的价钱一些是空的,一些价格和商品不匹配。用正则表达式真的很难爬,也是我水平还不够。
- (.*?)真的很好用,无脑替换,还能直接保存()中的内容,少了很多处理字符串的过程。
- 不 知道是不是外国公司的网站对爬虫比较友好还是太久没维护了,后面的作业选择爬了亚马逊的网站,真的很好爬,HTML结构很简洁明了,也没什么坑,泪目。
作业③
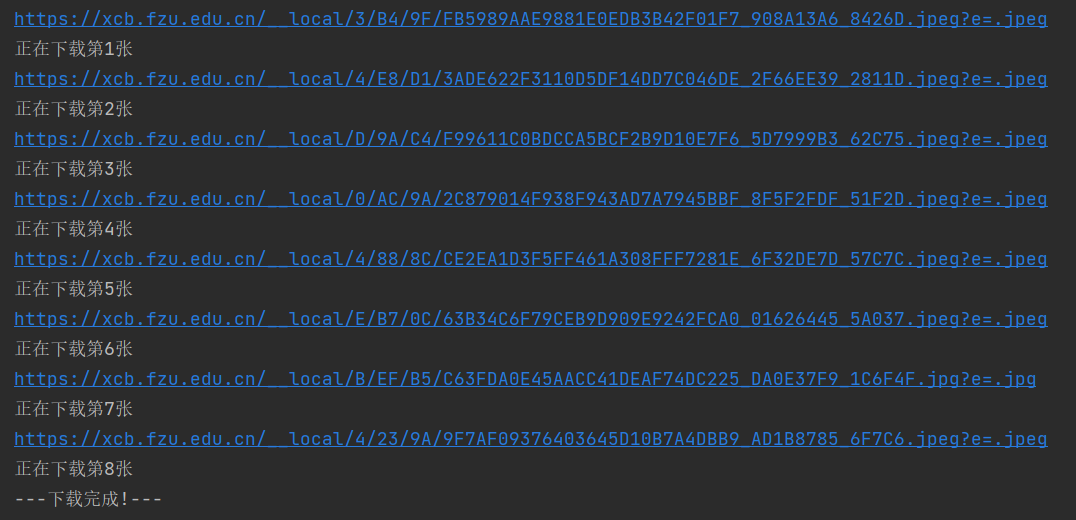
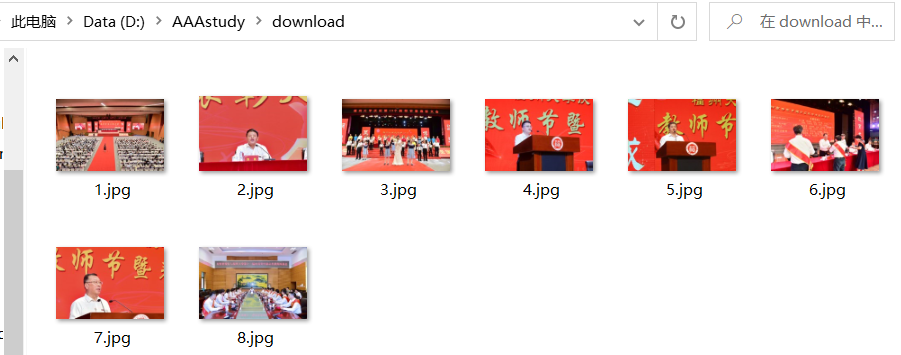
爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)的所有JPEG和JPG格式文件
输出要求:将网页内的所有JPEG和JPG文件保存在一个文件夹中。
思路
利用BeautifulSoup解析网页信息转换为文档树,用select方法利用CSS属性来选择<img>标签获取图片的下载路径,最后遍历这些路径下载图片到本地。
具体代码如下:
import urllib.request
from bs4 import BeautifulSoup
def getMoviesImg():
url='https://xcb.fzu.edu.cn/info/1071/4481.htm'
request = urllib.request.Request(url)#构造请求头
r=urllib.request.urlopen(request)#发送请求头
html=r.read().decode()
#解析网页
soup = BeautifulSoup(html,'lxml')
#获取所有的img标签
imgs = soup.select('img')#获取到网页中所有的 <img> 标签
x = 1
star_url='https://xcb.fzu.edu.cn'
for img in imgs:
# print(img["src"])通过 img["src"] 获取到每个 <img> 标签的 src 属性值
# 获取图片下载路径
imgurl = star_url+img["src"]
downloadname = 'D:/AAAstudy/download/%s.jpg'%x#下载到本地的地址,但是都保存为jpg格式了,怎么样保存原来的格式呢??
print(imgurl)
urllib.request.urlretrieve(imgurl , downloadname)
print(f"正在下载第{x}张")
x += 1
print('---下载完成!---')
getMoviesImg()
这里就有老师说的把所有图片都保存为了jpg格式的问题,等有时间再研究下怎么保留后缀。
运行结果如下:
控制台
本地文件夹
心得
- 用CSS属性来爬可以直接获得属性值!赞!
- 下载过程最好print一些东西,在机房运行的时候下载的慢,没什么动静自己都害怕,在宿舍下载速度还挺快的。
- 学校的网站比较简单,不用加headers也可以。
